
基于随机森林的工控企业网络安全智能故障诊断研究
2018-08-24 11:15:08杨冬英
现代计算机 2018年21期
杨冬英
(山西大学商务学院,太原 030031)
0 引言
通常,工控企业由于自动化程度不高,导致生产过程中产生的数据很难实时传送到用户端,导致用户端也很难及时将控制命令传达给设备端,结果导致工控企业的生产效率比较低。近年来,随着计算机网络渗入到各行各业,尤其是生产领域,许多工控企业网络逐渐向智能化发展,生产过程中相关数据的采集、设备的监控与故障诊断与处理等,都可以集中整合到自动化网络信息系统中,从而实现了生产过程的全自动化监控和管理。
目前,计算机网络由于具有可靠性、实时性等特点,同时还可以兼容现场控制总线技术,被广泛应用到工控企业网络中。传统的工控网络一般都属于专用网络,计算机通过与PLC卡件的连接获取实时数据,并将数据传输给操作人员进行分析、控制,同时操作人员也将命令传送给现场终端设备。当故障发生时,操作人员无法通过计算机网络实时了解现场设备故障情况以及生产状况,导致工作效率比较低。如何有效、快速、安全地诊断出工控企业网络中的故障,保证工控企业能够正常生产运行,是目前工控企业网络亟需解决的核心问题。
本文主要分析在现有故障诊断方法的基础上,结合工控企业实际特点,提出了一种精确度加权随机森林算法((Accuracy Weighted Random Forest,AWRF)。该算法根据每棵决策树的分类能力来设定其相对应的权重,很大程度上解决了数据不均衡带来的问题。该算法比较其他算法具有更高的分类效率,更加适合工控企业网络环境。通过与其他相关算法做对比实验,可以证明该算法的可靠性、有效性还是比较高。
1 工控企业网络特点
组成工控系统的设备类型主要包括工业生产控制设备、工业网络通信设备、工业主机设备、工业生产信息系统、工业网络安全设备五类设备。工业网络安全设备主要包括工业防火墙、工业网闸、主机安全防护设备等。工业生产控制设备主要包括可逻辑编程控制器(PLC)、分布式控制系统(DCS)、远程中端设备(RTU)、数控机床、工业机器人、智能仪表等。工业网络通信设备包括工业交换机、工业路由器、串口服务器等。工业主机设备主要包括工业主机、组态软件&数据采集与监控系统(SCADA)软件、工业数据库等。工业生产信息系统主要包括制造执行系(MES)、ERP管理系统、工业云等。
近年来人们对工控企业网络智能化故障诊断技术进行了深入研究,文献[1]提出了远程机械故障诊断和服务系统,将其应用于远程控制智能诊断中,使诊断实现远程智能控制。但是文献[2]提出了基于神经网络诊断方法,将其应用于电机伺服阀的故障诊断中,使故障诊断速度得到加速。文献[3]提出了基于Web远程故障服务系统,使诊断实现实时性,文献[4]提出了基于IE浏览器的数控故障诊断系统,使诊断得到了网络化。文献[4]提出了专家系统诊断方法,使诊断实现了系统化。文献[5]利用贝叶斯网络的概率原理,根据设备间的故障传播关系建立了系统模型,找出了可能出现的故障的主要原因,大大提升了故障定位的精度,并将该算法应用于复杂的飞机自动增压系统的故障诊断中,具有一定的应用价值。
上述方法都对工控企业网络故障诊断提出了相应对策及建议,但是,都没有涉及到非平衡数据,非平衡数据对分类结果会造成巨大影响,目前,处理非平衡数据问题的方法主要有两种:一种是改进算法,使它可以采集并分析非平衡的数据;二是处理非平衡数据,目前,对非平衡数据的处理普遍采用向上或向下采样法、SMOTE算法、SUV算法,向上采样法会导致出现重复数据,虽然该方法可以使少类样本数据达到要求的数量,但并不是样本自然生成的数据,无法完整地描述少类样本数据的特征。向下采样法会损害数据,特别是在少类样本量比较少的情况下,甚至无法完成训练。为此,本文提出了一种精确度加权随机森林算法(AWRF),加入了决策树投票权重的概念,优化了决策树的投票能力,为工控企业网络的故障诊断提供了科学合理的决策思路。
2 加权随机森林算法
2.1 随机森林算法
随机森林算法的优点有:
(1)有很强的通用性,可以适用与各种环境,主要用于聚类分析,进行数据异常检测和数据透视等;
(2)不需要对样本数据进行大量修剪,和决策树算法对比,不易出现过拟合现象;
(3)异常值、噪声数据等灵敏度不强,能保持比较高的精确度;
(4)可以对高维数据进行处理,具有并行性、可扩展性,尤其鲁棒性比较强;
(5)对于数据维数比较多的情况,可以自动生成重要的特征属性,还可以作为降维方法使用。
2.2 加权随机森林算法原理
随机森林在构建的每棵决策树时的分类能力大多数不同,有些部分决策树的分类效果比较好,有些部分的决策树的分类效果比较差。基于上述原因,本文提出了根据随机森林中每棵决策树分类能力大小来设定其相对应的权重。精确度加权随机森林模型(AWRF)的核心原理是将要训练的样本数据分为两个部分,一部分样本数据作为传统随机森林模型的训练样本,并对样本中所有的决策树都进行训练。另一部分剩余样本数据作为预测试样本,当这部分决策树样本数据结束训练之后,再对所有决策树样本数据进行测试,并计算分类样本的正确率。
其中:
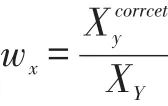
把P作为随机森林中训练样本所对应的决策树的权重,随机森林中的每棵决策树再进行投票时都要和其相对应的权重进行乘积运算。其对应的输出模型表示如下:
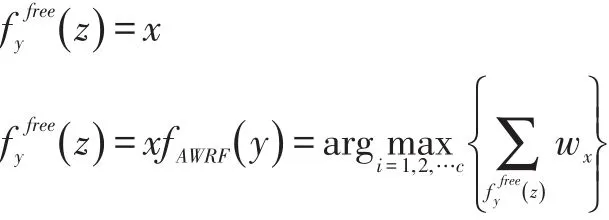
其中,z表示加权随机森林中的待测样本数量,c表示整个随机森林中所有的类别数目,x为c类中的其中一类样本数量。
2.3 加权随机森林算法过程
(1)从所有训练样本中取出一部分数据作为预测试样本,作为选取每棵决策树的权值的依据。在进行权值计算时,有可能会出现不公平的投票现象。为了保证投票的公平性,所有的决策树一般都采用固定的预测试样本进行计算。上述方法一般在训练样本比较多的情况下使用。
(2)由于每次使用的训练样本不同,导致留下的预测试样本也可能不相同。为了便于优化权值,后续的实验中可以用预测试样本率来代替预测试样本数。其中,预测试样本率等于预测试样本数占总训练样本数的比率。
由于加权随机森林算法(AWRF)是根据预测试样本进行权值计算,所以不需要再额外考虑公平性。每个决策树的权值可以用随机森林中的每棵决策树和预测试样本分类的正确率来代替。这样可以大大简化了随机森林算法的计算复杂性,同时也加快了程序的运行。
3 实例验证
根据工业和信息化部办公厅关于开展工业控制系统信息安全检查工作的通知,企业针对自身企业的实际情况完成系统信息安全自查,本次调查以企业工控系统构成为核心,围绕网络运行状态进行全面调查。系统安全状态主要包括安全软件选择与管理情况、配置和补丁管理情况、边界安全防护情况、物理和环境安全防护情况、身份证情况、远程访问安全情况、安全监测情况、资产安全情况、数据安全情况、供应链管理情况10个方面。
实验数据选取2016年280家企业实际调查数据作为实验数据,指标体系完全按照调查回来的数据设计,企业的安全等级采用“好差”二级体系,评估总分大于60,方差小于30的认定为“好”,其他为“差”。在实际应用中好与差应由专家来定,实验认为总分较高,小差较小的企业在安全措施方面做的比较多,而且每一方面都比较均衡,所以应该是做的比较好的。实验数据设置了标签值“1”和“0”,分别表示“好”和“差”,按照75%,25%的比例划分为训练集与测试集,使用加权随机森林算法训练的准确率模型在95%以上。结果如图1所示。

图1 训练样本结果图
实验结果表明在现有数据环境下加权随机森林算法(AWRF)更具有优势,分类的准确率比较高,结果比较令人满意。同时表明使用加权随机森林算法(AWRF)进行安全评估是可行的,可以实现对企业工控系统安全状态的评估。从速度和精度上看,加权随机森林算法(AWRF)训练时长明显要远远低于随机森林算法。
4 结语
根据工控企业网络的特点,提出了加权随机森林算法(AWRF)的故障诊断方法,该算法可以简化随机森林算法的计算复杂度,加快了程序运行,进而提高了故障诊断的效率,同时加权随机森林算法(AWRF)大大降低了工控企业网络故障诊断的错误率。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国设备工程(2017年8期)2017-05-10 07:49:17
中国设备工程(2017年7期)2017-04-10 08:08:54
信息安全与通信保密(2016年3期)2016-08-23 01:23:38
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
自动化学报(2016年5期)2016-04-16 03:38:47
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
