
顺滑如丝 解密英伟达慢动作视频技术
2018-08-23 17:24技术宅
电脑爱好者 2018年15期
技术宅


慢动作 没你想象的那么简单
相信大家在各种影视作品中都看到过慢动作特效,比如在刚刚结束的世界杯上就有许多球员进球、射门、身体接触的慢动作回放,通过VAR逐帧回看这些慢动作可以清晰看到一瞬间发生的事情(图1)。
对于电影里的慢动作特效,实际上是借助设备进行高速摄影,比如拍摄速度达到50帧/秒、100帧/秒甚至更高,然后在回放时仍然选择24帧/秒常规速度播放,这就相当于把实际1秒钟拍摄的图像用2秒多到4秒多的时间回放,从而实现慢动作效果。
当然对于普通用户来说,我们没有高速摄影设备,怎么能实现慢动作效果呢?英伟达近日推出了基于cuDNN加速的PyTorch深度学习框架实现任意视频慢动作的技术,通过这个人工智能框架,结合NVIDIA Tesla V100 GPU强大的处理能力,它可以将任意一段视频拉长,从而实现类似电影特效里的慢动作(图2)。
视频拉长的背后——人工智能慢动作技术
通过上面的介绍我们知道,常规的慢动作是将高速摄影的视频低速播放而实现。那么对于普通的视频(已经是低速摄影成品了),英伟达又是怎样实现慢动作效果的呢?
慢动作的核心是将原来的视频拉长而实现慢速效果,但是如果将普通的视频直接使用低速效果播放,实际效果则会变得卡顿,帧与帧之间动作变得不连贯。因此将普通的视频拉长后还要实现平滑的慢动作效果,此时就需要对视频物体进行定位和补帧。
比如一段汽车漂移的视频,如果要实现漂移的慢动作演示,我们首先需要对视频中的汽车进行准确定位,比如精确定位汽车每一秒的漂移位置,这样才可以对汽车后续整个漂移动作进行全程的展示(图3)。

因为原来的视频本身就是低速摄影拍摄的,现在将视频拉长后,为了让拉长的视频不出现卡顿(掉帧),就需要进行精确的补帧,使得视频拉长后播放仍然非常顺滑(图4)。
这样通过视频定位和补帧,英伟达的人工智能框架技术就实现了将任意视频慢动作化。那么这样的效果是怎样实现的呢?
英伟达的这项技术是借助NVIDIA Tesla V100 GPU强大的视频处理能力+人工智能学习框架实现的。英伟达搭建好人工智能学习框架后,把预先准备的约1.1万段视频素材作为数据源,提供给人工智能进行学习,让它从这些视频素材中学习定位和补帧。比如上述跳舞视频,人工智能技术可以对视频中的舞者进行定位,并且可以对舞者每一帧动作进行学习,知道下一帧的人物是怎样的状态显示。这样通过一定的算法和学习模型,并且经过人工智能的深度学习和自我学习,这个人工智能框架就可以对其他视频进行同样的定位和分解,用完美的定位和补帧技术,实现将普通视频慢动作化(图5)。


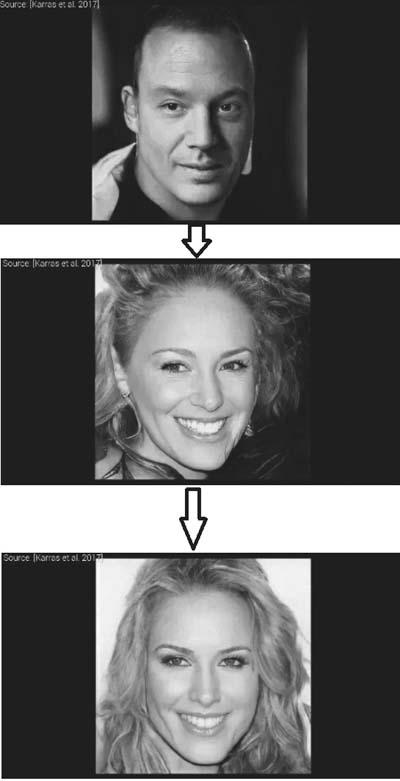
当然不仅仅是视频慢动作,借助新的训练方式,人工智能还可以从已有的图像中生成新的图像,甚至可以利用不同的人像生成新的肖像。就像影片中的换脸特效一样,英伟达的人工智能框架可以精准地实现人物从一个人脸无缝转换到另一个人脸的特效(图6)。
慢动作 带给我们更多乐趣
通过上面的展示,我们见识了英伟达人工智能框架在视频处理方面的强大功能。这个技术的出现可以给我们的生活带来很多乐趣。
随着手机的普及,我們使用手机来拍摄短视频,对于那些稍纵即逝的画面,我们总想看清楚整个过程。比如喜欢跳广场舞的老妈,对于队友、教练的快舞节奏总是看不清楚整个动作,现在只要使用手机拍摄,然后借助英伟达这个技术转换,舞者再快的动作都可以变慢,让老妈仔细看清楚每个舞蹈的动作。
英伟达的变脸技术则可以让我们在手机上制作出更多的搞笑视频,比如将舍友变成可爱的猫咪,然后通过微信、朋友圈和好友共享。当然这些技术也可以让我们的视频处理变得更为简单,比如剪辑钢琴老师弹琴的动作,方便我们学习指法;剪辑球员射门的视频,让我们细细欣赏漂亮的射门!
猜你喜欢
数学小灵通(1-2年级)(2023年8期)2023-08-24
数学物理学报(2020年3期)2020-07-27
体育风尚(2019年1期)2019-09-10
数学大王·趣味逻辑(2018年12期)2018-01-10
法大研究生(2017年1期)2017-04-10
文苑·感悟(2016年1期)2016-01-06
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
中国传媒科技(2013年4期)2013-08-15
体育科技(2011年4期)2011-01-02
