
基于标记信息级联传播树特征的谣言检测新方法
2018-08-23 03:06:32蔡国永毕梦莹刘建兴
计算机工程与科学 2018年8期
蔡国永,毕梦莹,刘建兴
(桂林电子科技大学广西可信软件重点实验室,广西 桂林 541004)
1 引言
推特Twitter(http://www.twitter.com/.)和新浪微博Sinaweibo(http://www.weibo.com/.)是两种典型的社交网络平台,它们允许用户发布小于140个字符的短消息并将信息传递给他们的粉丝,这些短消息支持添加图片、视频等多媒体数据。粉丝们带评论或不带评论的转发行为促进了这些消息在社交网络中的传播。由于消息没有经过把关,社交网络容易成为谣言传播的温床。不少事实证明,网络谣言会引起严重的公众恐慌和社会动荡,如2013年4月23日,推特上的一条关于美国总统奥巴马在白宫爆炸中受伤的消息导致道琼斯指数在几分钟内下跌140个点。由于谣言的危害性,学者们开始关注社交网络中谣言的自动检测问题。
谣言识别通常被视为二分类问题,基于统计方法进行特征检测是提高分类器性能的关键,目前社交网络谣言检测研究中,已设计的检测特征主要分为5类:(1)基于内容的特征,即依据微博文本,考虑文本内容统计特征,例如文本长度、标点符号、是否包含短链接、标签、表情符号或词性标注等简单特征[1,2],以及情感分数、词向量等深层语义特征,如文献[3]发现,用神经网络语言模型生成微博的文本向量表示有助于谣言检测。(2)基于用户的特征,包括用户注册的时间、地点、用户性别、年龄、用户名、头像、是否认证、关注数、粉丝数、描述、主页、已发微博数等[4,5],也有基于用户行为特征的相关研究[6]。(3)基于传播结构的特征,指的是消息传播树结构或用户朋友的网络结构,比如节点个数、根节点的度[1,5,7]、用户传播类型[8,9]、标记传播树[10]等。(4)基于时间的特征,即关注消息的发布时间并将其与源微博发布时间或用户注册时间相比较[5]。一些模型用时间来检测群体响应中量的突增或周期的突增[11]。一些研究[8,11]利用时间来计算传染病模型中各用户类型之间的变化率。一些研究[1]用时间作为衰减因子来度量响应中情感强度。(5)基于群体响应的特征,即大众对于一个事件的观点或态度[12 - 15],如文献[13]根据谣言帖会存在或多或少的相关质疑帖,基于寻找质疑短语、聚类不包含质疑短语的帖子,并通过计算包含真实消息的可能性将聚簇分类,进而判定是否为谣言。除上述5大类特征外,还有一些其它上下文特征,如发布消息的客户端类型、发布消息的地点等。
现有的谣言检测研究中,关注的谣言判别特征集中于微博消息的扁平特征,如消息构成特征、消息发布者特征、转发特征等,这些特征虽然有助于谣言检测,但过于简单化,因为它没有考察消息传播的内部时态结构和传播用户反应特点。如果谣言检测时不仅考察消息描述的内容、消息的表达方式,而且还考察被哪些人转发并做出了何种响应,这将能够更为准确地判断微博消息是否是谣言。
针对上述问题,本文在文献[10]的基础上提出一种改进的标记信息级联传播树CA-LPT(Labeled CAscad Propagation Tree),并在此模型下定义一种新的意见领袖影响力动态度量方法,然后提出20个特征(其中10个为新特征),并用随机通路图核和RBF(Radial Basis Function)核构成的混合核构造支持向量机SVM(Support Vector Machine)分类器,进行微博谣言检测,并通过实验验证谣言检测的性能。
2 谣言检测特征构造
根据文献[10],一棵传播树T=〈V,E〉,V中的每个节点m表示微博上的一条文本消息。文本消息m与发布用户u的元数据〈s,l,f,w,b,k,v〉相关联,其中用户元数据包括:性别s、关注数l、粉丝数f、微博数w、互关数b、注册时间k、是否认证v。传播树的根节点称为“源微博”,传播树中所有其它节点被称为“转发微博”,可以是转发评论源微博,也可以是转发评论其它转发微博。如果m2是对m1的转发评论,则从m1到m2有一条定向边。当一个微博用户的粉丝数(followers)与关注数(friends)满足约束条件followers/friends>α,且followers≥1000时,称此用户为意见领袖。如果节点微博来自意见领袖,则将节点标注为p,否则标注为n。标注好节点类型的消息传播树称为标记传播树LPT(Labeled Propagation Tree)。
基于Twitter的研究表明:在信息传播过程中,用户影响力与其粉丝数量呈弱相关[16 - 18]关系。微博中存在一些用户尤其是造谣者,通过增加粉丝数量来增大其影响力,然而这些粉丝大多是活跃度极低的僵尸粉丝,他们不评论不转发甚至不登录,不具有任何传播信息的能力,因此粉丝数量大只是用户具有影响力的必要非充分条件。此外,微博中的绝大多数用户属于消极的信息消费者[19],他们倾向于浏览来自其他用户的消息却很少发布或转发消息。能否调动这些消极用户分享信息的积极性,才是衡量用户影响力大小的关键因素。因此,在衡量用户的影响力时需要更加强调用户影响其粉丝传播信息的能力,而非仅仅注重其将信息传播给其受众的能力。另外,用户的影响力会随时间和主题的变化而发生变化,文献[20]从用户影响力和活跃度两方面建立意见领袖影响力体系,发现只有极少的用户能够同时成为不同主题的意见领袖。
由此可见,LPT模型中定义的意见领袖度量并不恰当,标记的信息也不能充分反映传播的动态性,需要进一步改进。
2.1 标记信息级联传播树模型
针对LPT存在的问题,将消息传播的级联模型[19]引入LPT中。将用户转发或发布消息的时间ti作为节点的一个属性保留在标记传播树中,即把节点标记扩展为(ui,ti),从而允许分析消息传播的动态过程。在此基础上重新定义意见领袖度量公式,意见领袖集合按公式(1)计算。这里意见领袖定义为在消息传播过程中短时间内能够引起其粉丝大量转发的用户,具有较大出度的节点。
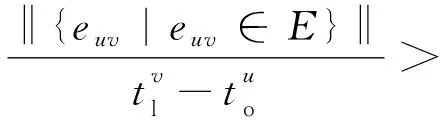
(1)

除此之外,本文在LPT的有向边上标记转发微博的情感值,即用rj=(δ(a),δ(d),δ(s))标注从mi到mj的边ej,其中a是mj的赞成分数,表示赞成或同意;d是mj的质疑分数,表示质疑或反对;s是mj的平均情感分数。δ(x)是时间衰减函数,即δ(x)=2-μtx,其中t是源微博与mj之间的时间差,μ是取0~1的参数。一个用户转发评论越快,说明情感越强烈。
通过上述改造的LPT称为标记信息级联传播树模型(CA-LPT),标记完整的CA-LPT模型示例如图1所示。

Figure 1 Labeled cascade propagation tree (CA-LPT)图1 标记信息级联传播树CA-LPT模型
2.2 谣言检测特征设计
在CA-LPT模型的基础上,本文提取20个特征来建立特征向量,如表1所示,其中的谣言库、可疑用户库、质疑惊讶反对情感分数等10个是新设计的特征(表1中用粗体显示),其余10个特征是以往研究中被证实为有效的特征。下面对这些特征分别说明。

Table 1 Description of 20 features
2.2.1 谣言库特征
通过分析收集的2016年03月01日~2016年05月03日微博不实信息举报处理大厅公布的437条谣言,发现谣言涉及28个话题,有4个话题只包含一条相关谣言微博,剩下的24个话题均有至少2条谣言微博与之相关;有14%的谣言只发布了一次,近86%的谣言被发布两次以上。统计结果表明,谣言发布的重复率非常高,即相同话题甚至相同内容的谣言会由不同用户多次发布,而且过期谣言会被重新发布。因此,可建立一个谣言库,比较未知微博文本与谣言库中谣言文本的相似度,如果能够找到一条谣言库中的谣言与此微博内容相似,则此微博有很大可能是谣言。本文实验中谣言相似度值基于Jaccard相似性公式计算。
2.2.2 可疑用户库特征
收集2014年04月01日~2016年05月03日微博不实信息举报处理大厅公布的共2 601条谣言,统计分析显示:这些谣言共涉及2 031个用户,也就是说存在一些用户发布了不止1条谣言;如果把发布了1条谣言的用户称为次可疑用户,把发布了至少2条谣言的用户称为超可疑用户,那么统计结果显示2 031个可疑用户中13%发布谣言超过2条,属于超可疑用户;超可疑用户中近一半都发布谣言超过3条,有的甚至发布了10条以上的谣言;近1/3的谣言是由这些少量超可疑用户发布的。因此,建立一个可疑用户库来判断用户的可信度,若发布未知微博的用户存在于可疑用户库中,返回true;反之返回false,将返回的布尔值赋值给给定微博的可疑用户库匹配这个特征。
2.2.3 质疑惊讶反对率和平均情感分数
已有研究证明,通过判断一条微博的群体响应(转发和评论)属积极情感还是消极情感在一定程度上可以区分谣言与非谣言,然而并不能达到很好的效果。因为一条微博的群体响应情感往往同微博本身的情感息息相关。例如,一条具有消极情感的非谣言微博叙述的是一条令人痛心的社会新闻,其群体响应大都包含“难过”“可怜”“[泪]”等消极情感;一条具有积极情感的谣言微博描述了一则振奋人心的奇闻异事,其群体响应大都包含“骄傲”“碉堡”“[给力]”等积极情感。因此,根据一条微博的群体响应是积极情感还是消极情感判断其是否是谣言是不完全准确的,积极情感不一定是赞成或同意,消极情感不一定是质疑或反对,应该将情感更具体细化到赞成、质疑、惊讶、反对等能明确表达个人主张的观点上。
本文通过3步计算一条微博群体响应的情感值:
(1)根据Hownet情感分析词典中的正负面评价词和正负面情感词提取表达质疑、惊讶、否定观点的情感词,分别建立质疑情感词典、惊讶情感词典和反对情感词典,还包括新浪微博中表达上述情感的共482个表情符号;
(2)将未知微博下的每条转发进行分词、去除停用词等文本预处理;
(3)分别计算群体响应的质疑率(即Ndoubt/N)、惊讶率(即Nsurprise/N)、反对率(即Noppose/N)。其中,N*是包含情感词典中的质疑词惊讶词反对词的转发微博数量,N是所有转发数量。

2.2.4 传播树深度
谣言微博通常起始于个人或团体,而真实微博会由很多无关个体发起或证明。造谣团体之间的联结是很紧密的,团体成员之间通过互转发达到增大转发量、扩大影响力的目的,同时这会造成传播结构的深度过大;而正常微博的转发用户之间由于通常是无关个体,传播结构深度不会很大,影响力比较大的新闻事件比如王菲离婚微博发布几小时后转发最深仅达到13层。所以,深度过大的微博一般不是正常微博。
2.2.5 意见领袖质量
根据知微平台(http://www.zhiweidata.com/#a)分析,计算新浪微博2015年影响力最高的100个事件,并综合账号影响力、风云榜排名得出1 886个微博意见领袖,统计用户的身份分布发现:其中86%是名人认证用户,10%是达人用户,仅4%是普通用户。一般参与谣言转发的用户的质量都不高,尤其是雇佣僵尸粉、水军帮转谣言的,意见领袖的质量也不高,因此可以用所有挖掘出的意见领袖的加V比例(即Vkol/Nkol)来度量一条微博的意见领袖质量,其中Vkol表示一条微博中挖掘出的经过认证的意见领袖数量,Nkol表示挖掘出的所有意见领袖数。
3 基于混合核函数的SVM谣言分类器
支持向量机SVM分类算法在解决小样本、非线性及高维模式识别中表现出良好性能,并能够推广应用到函数拟合等其他机器学习问题中,本文选择SVM分类算法用于微博谣言的检测。传统SVM分类器基于简单的扁平特征向量,但是实际中很多数据都是结构化的。由于这个原因,常常需要合并混合结构(比如树和图)作为SVM的核。通过将异构数据的不同特征分量分别输入对应的核函数进行映射,使数据在新的特征空间中得到更好的表达,能显著提高分类正确率。本文采用加权求和核,即式(2)来混合随机通路图核与RBF核:

(2)

本文用{Xi,yi}表示源微博mi,Xi有20维,yi是类标签。RBF核定义如式(3)所示:

(3)
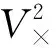
由直积图G×可以得到对应的邻接矩阵A×,定义A×中的元素[A×](u,u′),(v,v′)=l:
(4)
其中,核函数k度量边e(u,v)和e(u′,v′)之间的相似度的方法,由式(5)给出:
k((u,u′),(v,v′))=
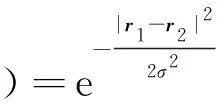
(5)
其中,r1是边e(u,v)的标签向量,r2是e(u′,v′)的标签向量,σ为常数,e表示自然常数。
给定邻接矩阵A×和权重参数λ≥0,定义标记信息级联传播树T和T′上的随机通路核为:
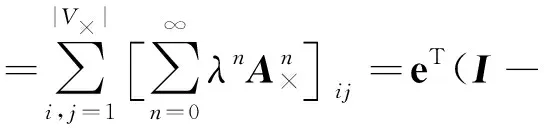
(6)
其中,e表示单位向量,I表示单位矩阵。
此外,每个源微博mi对应一棵传播树Ti,为了规范化式(6)中两棵传播树的核函数,将K×(T,T′)除以nn′,其中n和n′分别是T和T′的节点数:
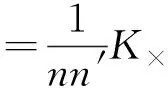
(7)
因此,结合式(3)和式(7),最终微博mi和mj的核函数定义为:
K(mi,mj)=βKG(Ti,Tj)+(1-β)KR(Xi,Xj)
(8)
其中,0<β<1,β决定随机通路图核与特征向量核相比的传播权重。实验中基于式(8)训练SVM分类器。
4 实验与分析
为得到合适的训练集,收集了2015年04月10日~2016年05月03日微博不实信息举报处理大厅(SinaWeibo.(2015).Weibo-Misinformation-Declaration [Online].Available:http://service.account.weibo.com/?type=5&status=0)和官方辟谣账号@微博辟谣(SinaWeibo.(2015).@Weibopiyao [Online].Available:http://www.weibo.com/weibopiyao?from=myfollow_all)公布的共9 834条谣言。由于要考察谣言的传播结构,而且谣言的一个必要条件是必须有足够的传播量,因此保留那些转发至少100次的谣言,共694条组成谣言集。在真实世界中,新浪微博中的谣言数量远远小于正常微博数量,为了避免不平衡数据集达到过高准确率的假象,需要建立一个谣言数与非谣言数大致相等的数据集。随机选取3 000个没有被证明是谣言的微博以及它们的转发微博,手动过滤转发量小于100的微博,组成1 099条正常微博集。通过新浪微博提供的API抓取这1 793条微博及其所有转微博,每条微博或者转发微博都包含它们的作者信息(性别、粉丝数、关注数、微博数等)、时间戳、客户端等。表2为数据集的基本概况。
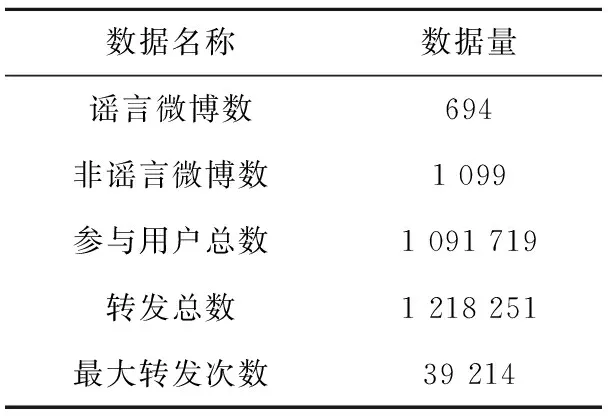
Table 2 Overview of dataset
由于新浪微博提供的API抓取的数据特征稀疏且高度冗余,需要对爬取的原始微博数据进行预处理。对于建立RBF核的20个静态特征,直接从原始数据表中提取所需的低阶特征,或间接提取计算高阶特征所需的低阶特征;对于建立随机通路图核的传播特征,提取转发微博的父mid、子mid、转发时间戳等特征构建标记消息级联传播树模型,计算传播树之间的相似度。直积图最大生成43 498个节点,邻接矩阵43 498维,用稀疏矩阵存储,要求有足够计算资源的硬件支持。本文实验基于20内核CPU,128 GB内存的服务器,采用SVM开源软件LibSVM的Java软件包,并结合WEKA数据挖掘平台,实现分类器的训练和测试。实验基于十折交叉验证,用传统的准确率Precision、召回率Recall和F-score来评价本文提出的方法和新特征的有效性。
4.1 CA-LPT模型的有效性
为了验证改进模型CA-LPT的有效性,用不同的特征子集来训练SVM分类器。实验结果如图2和图3所示,图中R表示谣言,N表示非谣言,*+O表示模型*下的图核与以往研究的静态特征构成的特征子集;*+O+N表示模型*下的图核与以往研究的静态特征加上10个新特征构成的特征集。

Figure 2 Comparison between LPT and CA-LPT on rumor debunking图2 LPT模型与CA-LPT模型谣言识别比较

Figure 3 Comparison between LPT and CA-LPT on non-rumor debunking图3 LPT模型与CA-LPT模型非谣言识别比较
图2和图3的结果说明,CA-LPT模型结合新提出的特征子集相比仅考虑粉丝数和关注数等静态特征的LPT模型确实提升了谣言识别的效果。
本文还与一些经典的谣言检测算法进行了对比:利用Liang等[6]提出的9个基于用户行为的新特征和其中7个本文也用到的经典特征训练第一个SVM分类器;利用Castillo等[5]提出的15个特征训练第二个SVM分类器;利用Yang等[22]提出的全部20个特征训练第三个SVM分类器。结果如表3所示。表3结果表明,本文的基于CA-LPT方法性能更优。

Table 3 Performance comparison among different algorithms
4.2 新特征的有效性
为了验证新提特征的有效性,用老的特征集结合不同的新特征子集训练无图核SVM分类器,结果如图4所示,其中“(-)*”表示除特征*外的特征子集。

Figure 4 Efficiency comparison among new features图4 新特征有效性对比
很明显,谣言库匹配特征、可疑用户匹配特征对谣言的识别起到很大作用,传播树结构的最大深度和意见领袖加V比例对识别也有所帮助。然而,群体响应中的质疑惊讶反对情感特征的重要性并未达到预期效果,原因可能是质疑惊讶反对的情感词汇数量有限,情感词典不够完善,对每条微博下群体响应内容中的这些情感词未完全识别,导致情感分数非常稀疏,因此可以考虑进一步完善和自动扩展情感词典等知识库来改进。
4.3 检测方法的时间性能
由于微博数据集规模庞大,算法的时间性能也是一个重要的评价指标。本实验随机选取1 793条微博中的60%作为训练集,其余717条微博作为测试集。算法主体分3步运行:
Step1根据用户影响力度量方法寻找消息传播过程中的意见领袖用户并在消息传播树中标记;
Step2生成消息传播树之间的直积图以及对应的邻接矩阵;
Step3根据邻接矩阵计算消息传播树之间的随机通路图核。
其中Step 2需要生成717×1076=771492个直积图及其对应的邻接矩阵,Step 3的矩阵逆运算复杂度大且邻接矩阵最大达到43 498维,因此时间开销较大。LPT模型与CA-LPT模型的算法运行时间对比如表4所示。

Table 4 Time performance comparisonbetween CA-LPT and LPT
分析表4的实验结果,由于CA-LPT模型在挖掘意见领袖的过程中做了改进,不再只考虑用户的粉丝数和关注数,需要挖掘用户发布微博或转发的时间戳和节点的总出度,导致Step 1程序运行时间略大于LPT算法;CA-LPT模型赋予意见领袖更严格的条件,减少了大量LPT中挖掘的意见领袖数量,合并了大量的非P节点,从而可以大幅缩小传播树的规模,最终减小直积图以及对应的邻接矩阵的维度,这对于提高计算消息传播树之间的随机通路图核的效率也有很大帮助,因此Step 2、Step 3的运行时间均有大幅缩短。
5 结束语
本文将消息传播的级联模型引入LPT模型中,提出改进的标记信息级联传播树模型CA-LPT:计算单位时间内用户驱动其粉丝进行转发的数量来动态度量用户影响力,而非仅仅考虑用户的粉丝数和关注数等静态特征。真实微博数据集上的实验结果表明,基于CA-LPT模型比基于LPT模型设计的特征可以获得更高的谣言识别准确率。实验也表明,谣言库匹配特征、可疑用户库匹配特征以及群体响应中的质疑、惊讶、反对等情感特征能够显著提高谣言识别的效果。然而,真实的社交媒体平台中谣言微博的数量远远小于正常微博的数量(通常达到1∶9甚至更少),用处理平衡数据集的理论和方法来处理非平衡数据集显然不适用,因此考虑谣言检测中的数据分布不平衡问题、提高算法对少数谣言的识别性能将是下一步待解决的问题。
猜你喜欢
黄河之声(2022年6期)2022-08-26 06:46:04
音乐教育与创作(2022年4期)2022-04-26 02:40:50
环球时报(2022-04-13)2022-04-13 17:16:04
中国盐业(2018年17期)2018-12-23 02:16:56
电子测试(2018年1期)2018-04-18 11:52:35
中学生英语(2016年13期)2016-12-01 07:04:24
民间文化论坛(2016年2期)2016-12-01 05:41:46
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
学生天地(2016年32期)2016-04-16 05:16:19
