
异构分布式计算环境下一种新型表调度算法
2018-08-17 00:26:46李云洋
计算机工程 2018年8期
李云洋, ,
(1.南京理工大学 自动化学院,南京 210094; 2.中航工业西安飞行自动控制研究所,西安 710065)
0 概述
随着网络技术的飞速发展和在实际工程系统中的广泛应用,越来越多不同处理能力的单个处理器通过网络互联而组成了异构分布式计算环境,如网络化嵌入式系统[1]。在处理大规模任务时,分布式计算系统通常将任务分解为若干相互依赖的子任务并进行处理,而任务调度是实现高效异构分布式计算的关键技术。由于大规模复杂多约束任务调度问题是NP-hard问题[2],往往难以获得最优解,尤其在分布式异构计算环境中,由于各任务在异构处理器上执行特性不同,对复杂任务调度问题提出了挑战,因此研究并设计低复杂度、高性能的任务调度算法具有重要的理论意义和工程应用前景。
静态任务调度算法主要包括基于启发式和基于随机搜索的算法,其中启发式调度主要有表调度算法、基于分簇的调度算法和基于复制的调度算法[3-4]。表调度由于简单易行,并且具有较高的调度效率和较低的时间复杂度,因此受到广泛关注,其主要代表性算法有DLS[5]、HEFT[6]、CPOP[6]等。文献[6]提出2种低复杂度的表调度算法HEFT和CPOP,但HEFT算法在处理器分配阶段仅根据本任务完成时间最短的策略分配处理器,而未考虑对后继任务完成时间的影响。文献[7-8]提出2种基于复制策略的调度算法,减少了任务完成时间,但算法执行时间复杂度较高且容易造成处理器资源浪费。文献[9-10]分别提出2种基于分簇策略的调度算法,基于分簇的算法能够有效利用处理器资源而提高任务并行计算执行效率,但在减少通信开销上不如基于任务复制的算法,并且时间复杂度也高于表调度算法。在处理多任务调度问题时,随机搜索算法及应用也得到研究。文献[11-13]提出3种基于遗传算法的任务调度算法,文献[14]提出基于模拟退火的调度算法。此外,文献[15-16]还提出基于禁忌搜索的调度算法。遗传算法由于能够缩短任务完成时间而应用广泛,但其程序运行时间远比启发式调度算法时间长,因此,对实时性要求高的系统仅适用于离线静态调度场合。
HEFT表调度算法未考虑其直接后驱任务完成时间的影响。针对该不足,本文提出一种新型表调度算法IFEFT。通过计算任务最早完成时间,以及该任务与出口任务之间的最大通信开销,并采用两者乘积越小越优先的策略,进行处理器任务分配。
1 问题描述
用户请求应用可分解为若干相互依赖的任务,通过有向无环图(Direct Acyclic Graph,DAG)描述。一般DAG图由二元组G=(V,E)表示,其中,V表示DAG图的节点集合,即任务集合V={v1,v2,…,vn},n=|V|表示任务总数,E是DAG图有向边,每个边连接2个任务,E={ei,j|ei,j=〈vi,vj〉,ei,j∈V×V},如果ei,j∈E,表示任务vi和vj之间有依赖关系,vj必须在vi完成后才能开始处理。图1为一个表示任务节点以及边权重的标准DAG图。
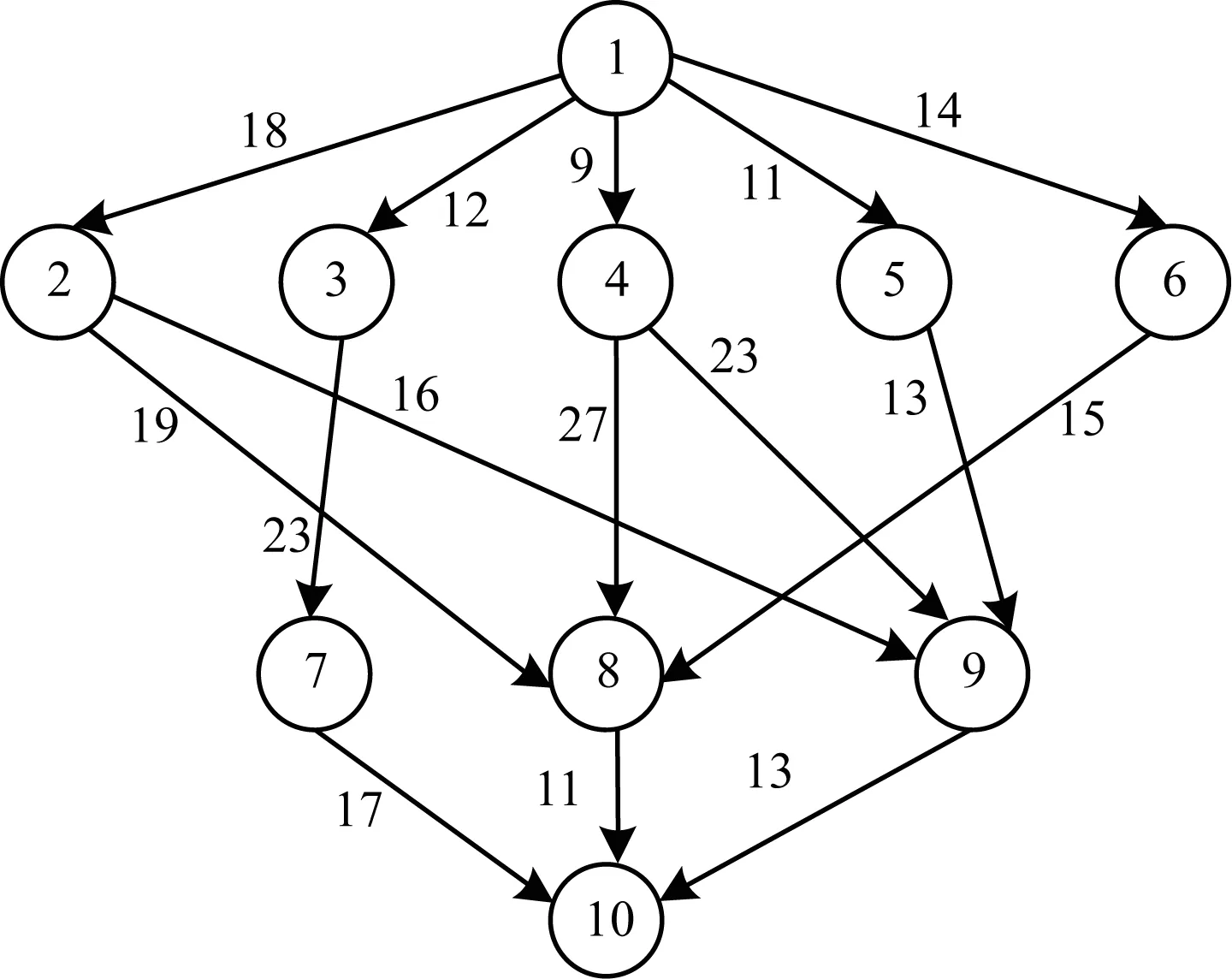
图1 DAG图
若异构计算环境下处理器之间通过同构网络互联,即任意2个处理器之间的通信速率相同,则DAG图中每条边对应一个通信开销,用ci,j描述任务vi和任务vj在不同处理器上处理所需要的通信开销,C={ci,j|ei,j∈E,ci,j>0}表示整个DAG图的通信开销集合。设异构处理器集合为P={p1,p2,…,pm},m=|P|为处理器总数,用wi,j表示任务vi在处理器pj上的计算开销(时间),那么W=[wi,j]n×m即是任务集合在处理器上计算开销矩阵。表1列出了图1中10个任务在处理器p1~p3上的计算开销。
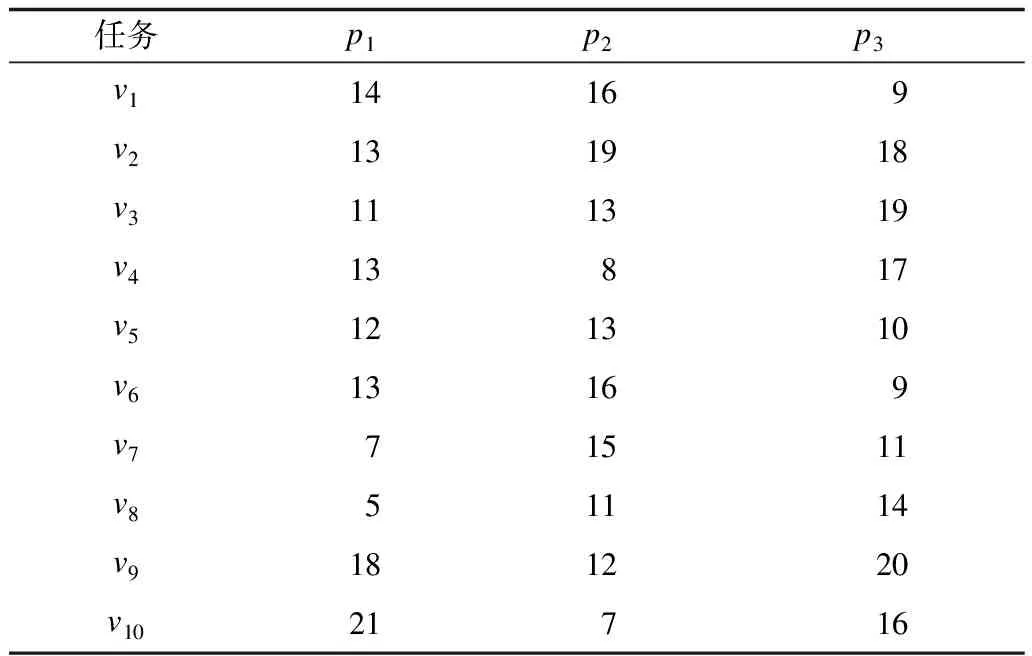
表1 图1中10个任务在3个处理器上的计算开销
定义任务vi的前驱和后继任务集合分别为:
Vpred(vi)={vj|vj∈V,ej,i∈E}
(1)
Vsucc(vi)={vj|vj∈V,ei,j∈E}
(2)
令入口任务为ventry,出口任务为vexit,那么Vpred(ventry)=0,Vsucc(vexit)=0。令TEST(vi,pj)和TEFT(vi,pj)分别表示任务vi在处理器pj的最早执行开始时间和最早执行完成时间,则对于入口任务ventry,有:
TEST(ventry,pj)=0
(3)
对于DAG图中的其他任务,从入口任务开始,采用递归的方法分别计算最早执行开始时间(Earliest Start Time,EST)和最早执行完成时间(Earliest Finish Time,EFT)。为计算任务vi的最早执行完成时间,其所有的直接前驱任务都应已被调度成功。最早执行开始时间和最早执行完成时间的计算公式如下:
TEST(vi,pj)=
(4)
TEFT(vi,pj)=wi,j+TEST(vi,pj)
(5)
其中,Tavail[j]表示处理器pj准备好执行任务的最早时间。
当任务vi调度到处理器pj后,其在处理器pj上的最早完成执行时间就等于实际完成时间TAFT(vi)。而当DAG图中全部任务都被调度执行后,整个应用的执行时间就是出口任务vexit的实际完成时间,即:
Tmakespan=max{TAFT(vexit)}
(6)
2 IFEFT调度算法
本文提出的IFEFT表调度算法包括2个阶段:任务优先级排序和处理器分配。
2.1 任务优先级排序
IFEFT算法首先建立任务的优先级队列,然后根据队列顺序对任务逐个进行调度,在任务优先级排序阶段,令wDLC(vi)表示任务vi与其直接前驱任务vm之间的最大通信开销,wULC(vi)表示任务vi与其直接后驱任务vn之间的最大通信开销,wLC(vi,pj)表示vi与vm和vn之间的最大通信开销以及vi在pj上的计算开销三者之间和的最大值,wALC(vi)表示任务vi在不同处理器上计算的wLC(vi,pj)的平均值。分别定义如下:
wDLC(vi)=max{ci,m}
(7)
wULC(vi)=max{ci,n}
(8)
wULC(vi)+wi,j}
(9)
每个任务在不同处理器上计算开销不同,因此,为了更精确,每个任务在不同处理器上都应该有一个wLC值。首先通过式(9)计算在不同处理器上执行的上行权重,然后根据式(10)求其平均值,最后对权重、优先级由高降低进行排序。根据式(9)和式(10)计算公式可得:任何一个前驱任务的上行权重必大于其所有后继任务的上行权重,从而保证任务之间的约束关系。IFEFT算法描述如下:
1.计算队列中每个任务的开销LC(vi, pi)和平均开销ALC(vi),并将任务按ALC(vi)降序排列;
2.While 队列中有任务未被调度do
3.选择ALC(vi)最大的任务vr;
4.计算最短完成时间EFT(vr, pj)与通信开销LD(vr, pj);
5.分派vr到EFT(vr, pj)与LD(vr, pj)乘积最小的处理器上;
6.标记vr为被调度任务;
7.End while
2.2 处理器选择
当任务调度的优先级队列顺序确定后,由式(4)和式(5)计算任务在每个处理器上的最早开始时间和完成时间。目前已有很多算法在处理器分配阶段都是根据EFT大小来选择处理器的,只考虑了直接前驱任务和本身任务完成时间,而未考虑其对直接后驱任务完成时间的影响。一个任务如果其EFT值小但链路距离(Link Distance,LD)很大,并不能取得很好的调度效果,因为DAG图的拓扑结构及通信开销也会影响任务完成时间。为了获得更好的调度效果,本文提出兼顾直接前驱任务和直接后驱任务对其完成时间长短影响的设计思想。在处理器分配阶段,令wLD表示任务vi与出口任务之间最大通信开销,IEFT作为处理器选择标准,结合“向上看”和“向下看”的原则,即采用最早完成时间EFT和最大通信开销LD乘积最小的原则,定义:
wLD(vi,pj)={wLC(vi,pj)-wi,j}
(11)
IEFT(vi,pj)=min{TEFT(vi,pj)×wLD(vi,pj)}
(12)
采用本文IFEFT算法对图1和表1所示的任务调度模型进行调度,并与HEFT、DLS、CPOP算法进行比较,如图2所示。可以看出,本文IFEFT算法的任务完成时间最短。
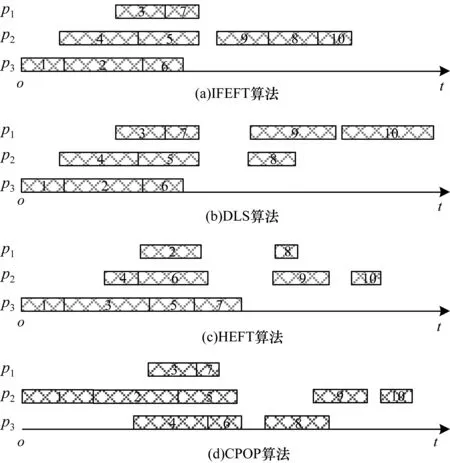
图2 4种表调度算法结果的甘特图
3 实验与结果分析
3.1 参数及比较指标
本文利用4种算法在相同的DAG图上产生的调度结果进行分析和比较,描述DAG图的参数有任务节点个数n、处理器个数m、任务在处理器上的平均计算花费wACC和通信计算比RCCR,即平均通信时间和平均计算时间之比。
调度算法采用调度长度比(Scheduling Length Ratio,SLR)和加速比作为评价指标。SLR表示算法实际执行时间与关键路径任务执行时间的最小值之比,调度算法产生的SLR越小,说明算法越高效。SLR的计算公式为:
其中,CPmin表示所有待处理的任务在处理器上执行时间最短的集合。加速比表示在一个处理器上串行执行DAG图时所有任务使用的最小时间与其实际执行时间的比值,调度算法产生的加速比越大,说明算法越高效。加速比计算公式为:
3.2 随机任务实验与结果对比
本文通过3组不同的实验对比IFEFT、HEFT、DLS、CPOP 4种算法的性能。
实验1设置n=20,m={2,4,6,8,16,32},wACC=40,RCCR=0.8,shape={0.4,0.5,0.6,0.7}进行100次实验,即随机生成100个DAG图测试不同处理器个数对算法性能的影响,得到的平均SLR和平均加速比如图3所示。实验数据显示,IFEFT的平均SLR分别比HEFT、DLS和CPOP算法小5.32%、15.23%和13.30%,平均加速比分别比HEFT、DLS和CPOP算法大3.04%、5.83%和4.79%,表明IFEFT算法的平均SLR和平均加速度2项性能指标都优于其他3种算法。
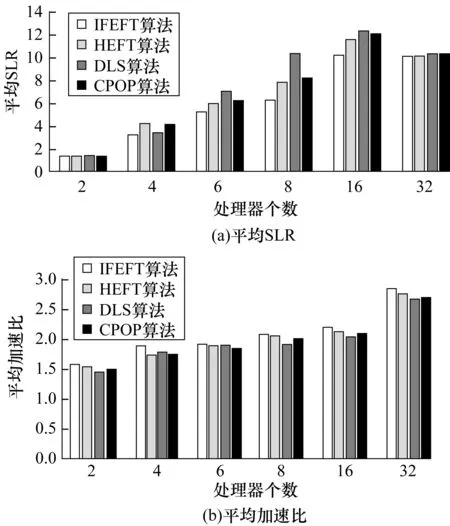
图3 处理器个数对各算法性能的影响
实验2设置n=20,m=8,wCCR={0.2,0.4,0.8,1,2,4,6},shape={0.4,0.5,0.6,0.7},wACC=40,进行100次实验,即随机生成100个DAG图测试不同通信计算比,即通信时间与计算时间之比对算法性能的影响,获得的平均SLR和平均加速比如图4所示。实验结果显示,IFEFT算法获得的平均SLR分别比HEFT、DLS和CPOP算法小5.91%、12.34%和9.57%,平均加速比分别比HEFT、DLS和CPOP算法大0.96%、5.83%和3.16%,表明IFEFT算法的平均SLR和平均加速比2项性能指标均优于其他3种算法。
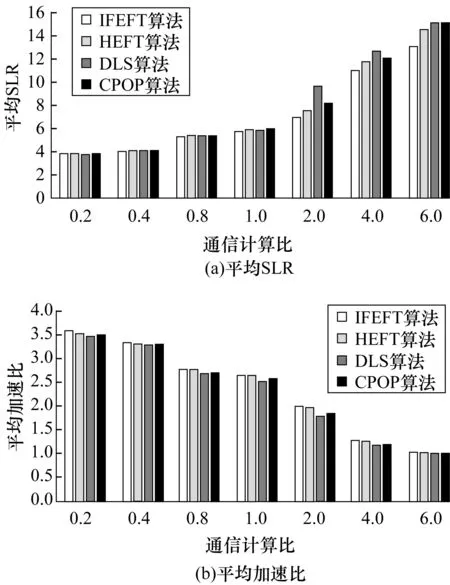
图4 通信计算比对各算法性能的影响
实验3设置n={10,20,30,40,50},m=8,RCCR=0.8,shape={0.4,0.5,0.6,0.7},wACC=40,进行100次实验,即随机生成100个DAG图测试任务个数对算法性能的影响,获得的平均SLR和平均加速比如图5所示。实验数据显示,IFEFT的平均SLR分别比HEFT、DLS和CPOP算法小7.03%、11.26%和9.66%,平均加速比分别比HEFT、DLS和CPOP算法大1.73%、7.11%和5.59%,表明IFEFT的平均SLR和平均加速比2项性能指标都优于其他3种算法。

图5 任务个数对各算法性能的影响
4 结束语
本文提出一种新型表调度算法IFEFT。在处理器分配阶段,该算法兼顾了任务对其直接前驱任务和直接后驱任务完成时间的影响。实验结果表明,与DLS、HEFT和CPOP算法相比,IFEFT算法可有效缩短任务完成时间,提高平均加速比。下一步将研究异构分布式计算环境下的任务动态调度策略,以及非理想异构分布式环境下兼顾计算效率与整体可靠性的调度算法。
猜你喜欢
制造技术与机床(2019年4期)2019-04-04 12:22:06
测控技术(2018年7期)2018-12-09 08:58:00
材料科学与工程学报(2016年1期)2017-01-15 13:33:52
软件导刊(2016年11期)2016-12-22 21:47:07
科学与财富(2016年15期)2016-11-24 13:30:27
系统工程与电子技术(2016年2期)2016-04-16 05:16:58
当代化工研究(2016年7期)2016-03-20 16:21:54
信息通信技术(2015年6期)2015-12-26 01:16:54
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:45
电源技术(2015年9期)2015-06-05 09:36:06
