
基于CNN与双向LSTM的中文文本蕴含识别方法
2018-08-17 07:10谭咏梅刘姝雯吕学强
中文信息学报 2018年7期
谭咏梅,刘姝雯,吕学强
(1. 北京邮电大学 计算机学院,北京 100876;2. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引言
文本蕴含识别(recognizing textual entailment,RTE)是指给定文本T(Text)与假设H(Hypothesis),识别出T是否蕴含H。换言之,当一个人阅读T之后,推断出H是否为真[1],对深入理解文本语义具有重要作用。其中,中文文本蕴含识别是指识别出中文句对(T-H对)之间是否存在蕴含关系。
文本蕴含识别是自然语言处理领域一项具有挑战性的任务,可以应用到多项信息获取技术中。例如,信息检索中可以使用文本蕴含技术生成与检索词语相关的候选信息,问答系统中可以使用文本蕴含来生成候选答案或者对候选答案进行筛选排序,文本摘要中可以使用文本蕴含技术辅助精简文本[2]。
目前,中文文本蕴含大多采用机器学习的方法,通过人工提取大量特征构造分类器进行识别,这些方法需要依赖于特征工程以及大量的自然语言处理(natural language processing, NLP)工具(例如词性标注、命名实体识别、指代消解等)。当前,深度学习与传统方法相结合的方法在NLP问题上取得了一定的成果,例如LSTM和CRF相结合的方法在分词、命名实体识别等序列标注问题上已经得到应用[3-4]。本文将深度学习与传统方法结合,提出一种基于CNN与双向LSTM的中文文本蕴含识别方法,首先使用卷积神经网络(convolutional neural network,CNN)与双向长短时记忆网络(bidirectional long short-term memory,BiLSTM)自动提取相关特征,避免人工筛选大量特征以及NLP工具造成的错误累计问题,然后使用全连接层进行分类得到初步的识别结果,最后使用语义规则进行修正,得到最终的蕴含识别结果。该方法在2014年RITE-VAL评测数据集上MacroF1结果为61.74%,超过评测中最好的成绩61.51%[5],表明该方法对于中文文本蕴含识别是有效的。
1 文本蕴含
日本国立情报学研究所(national institute of information,NII)组织的NTCIR(NII test collection for IR systems)于2011年开始举办中文文本蕴含识别(recognizing inference in text,RITE)方面的评测任务[6]。截止到目前,国内外已经成功举办了三次中文文本蕴含识别的评测。2011年NTCIR-9提出了RITE任务[7],2013年NTCIR-10提出了RITE-2任务[8],2014年NTCIR-11提出了RITE-VAL任务[9]。
对于中文文本蕴含识别任务,学者们已经提出了许多种方法,包括基于规则的方法[10]、基于相似度的方法[11]、基于对齐的方法[12]、基于机器学习的方法[5]、基于深度神经网络的方法[13]等。
基于规则的方法需要由人工编写若干中文文本蕴含关系的规则,当满足某一规则时,给出是否蕴含的结论。基于规则的方法的优点是直观、识别准确、易于理解;缺点是规则的编写需要花费大量的人力与时间,由于中文表述的多样性以及背景知识的缺乏,规则并不能涵盖全部的语言现象。
基于相似度的方法认为“相似即蕴含”,文本对之间的相似度越高,它们之间存在蕴含关系的可能性越大。在实验中会根据训练数据设定一个阈值,测试时,如果文本对的相似度高于阈值则判定为“蕴含”,否则认为“不蕴含”。基于相似度的方法的优点是实现相对简单,可以判断在词汇层面是否具有蕴含关系;缺点是强行假设“相似即蕴含”,导致大量相似但并不蕴含的文本对被错误识别[2],也不能深入理解句法、语义关系。
基于对齐的方法是在基于相似度的方法上演化出来的[2],找出文本对之间的相似部分并通过对齐技术进行对齐,然后根据对齐的程度识别是否蕴含。基于对齐的方法的优点是直观;缺点是不够灵活,对具有复杂对齐方式的文本蕴含关系识别效果不佳。
基于机器学习的方法通过人工已标注好的数据提取大量的词汇特征、句法特征、语义特征等,然后构造分类器(如SVM,LR等)进行分类。基于机器学习的方法的优点是适用于样本数据量小的情况,减少了规则的使用;缺点是需要人工提取大量特征,不仅耗时耗力,而且分类效果严重依赖提取的特征,并且在提取特征的时候需要使用大量自然语言处理工具,也会引入新的错误。
随着深度神经网络技术在图像、语音等领域的成功应用,基于深度神经网络的方法在文本蕴含识别中的应用研究也逐渐增多。例如,王宝鑫将注意力机制应用在卷积神经网络模型中,来对英文文本蕴含识别进行研究[13]。深度神经网络方法和传统方法相比,有如下几个特点。
(1) 减少甚至避免人工参与。传统方法需要大量的人工抽取特征,深度神经网络可以避免传统机器学习方法中的人工抽取特征工作。
(2) 减少错误累计。传统方法需要词性标注、命名实体识别等NLP工具,而使用多种NLP工具时容易导致错误累计问题,深度神经网络的方法可以在一定程度上减少错误累计。
(3) 模型调整。方便传统方法的可塑性较深度神经网络方法低,如果用传统方法解决问题,改进成本巨大,调整模型时可能需要对代码进行大量改动。而深度神经网络的方法只需要调整参数,就可以调整模型,具有很强的灵活性和成长性。
(4) 训练成本稍高。虽然深度神经网络方法较传统方法的训练成本高,但是当前高速发展的硬件性能可以支撑深度神经网络的训练。
2 基于CNN与双向LSTM的中文文本蕴含识别方法
本文方法首先对文本进行预处理,之后将句子映射到向量表示,再使用CNN与双向LSTM分别对文本进行编码,提取相关特征,然后使用全连接层进行分类,得到初步的识别结果,最后使用语义规则对网络识别结果进行处理,得到最终的蕴含识别结果,其系统架构如图1所示。
图1 基于CNN与双向LSTM的中文文本蕴含识别系统架构图
2.1 预处理
(1) 文本与假设分开
由于语料中的文本T与假设H是成对保存的,本文系统需要对T和H分别构建子网络,所以首先将T和H分开,以便于网络的构建。
(2) 统一数字
由于文本中对于数字的表示方法不一致,需要将文本中的数字格式进行统一,全部以阿拉伯数字的形式表示[14]。如: “二百一十七”转化为“217”,“百分之七十五”转化为“0.75”。
(3) 中文分词
中文没有空格等形式的天然分隔符,因此需要进行分词处理。本文使用结巴分词*https: //pypi.python.org/pypi/jieba/进行中文分词。
例如,对句子“拉力赛是采用公共或者私人道路,使用改装过的或者是特别制造的汽车进行的比赛。”进行中文分词后,得到如下结果:
“拉力赛 是 采用 公共 或者 私人 道路 , 使用 改装 过 的 或者是 特别 制造 的 汽车 进行 的 比赛 。”
(4) 拼音转换
由于实验数据的稀疏性以及汉字数量庞大,本文首先使用pinyin*https: //pypi.python.org/pypi/xpinyin/将中文转换成拼音表示,以减小词典大小,同时减少未登录词(out of vocabulary,OOV)出现的数量。
例如,对句子“拉力赛是采用公共或者私人道路,使用改装过的或者是特别制造的汽车进行的比赛。”进行汉字转拼音后,得到如下结果:
“la li sai shi cai yong gong gong huo zhe si ren dao lu , shi yong gai zhuang guo de huo zhe shi te bie zhi zao de qi che jin xing de bi sai 。”
2.2 网络结构
2.2.1 嵌入层
嵌入层将预处理得到的结果以向量的形式表示,将句子映射到低维向量表示,每一列对应一个字,表示成n×l的矩阵形式(n表示嵌入的向量维度,l表示句子长度)。嵌入层通过将文本转化为计算机能够处理的数字向量形式,便于之后的网络提取特征。
2.2.2 卷积层
1962年,Hubel和Wiesel通过对猫的视觉皮层细胞的研究,提出了感受野的概念[15]。1998年,LeCun Yann提出了基于CNN的文字识别系统LeNet-5[16],并被用于银行手写数字识别。
CNN主要有卷积和池化两种操作。卷积参考了局部感受野的思想,每个隐藏层节点只连接到某个足够小局部的输入点上,而不是全连接到每个输入点上,同时同一层中某些神经元之间的连接权重是共享的,从而大大减少需要训练的权值参数。卷积操作可以在避免传统机器学习方法人工提取大量特征的情况下,提取出句子的词汇特征、语义特征等信息。
如图1中所示,卷积层使用多个n×h的滤波器(或称卷积核;n为嵌入向量的维度,h为滤波器的窗口大小)与嵌入层的输出结果进行卷积操作,通过使用不同窗口大小的滤波器可以让网络自动提取出句子的不同特征。再将每一个滤波器与句子卷积得到的结果连接起来,得到卷积层的输出,计算如式(1)所示[17]。
mi=f(w·xi: i+h-1+b)
(1)
其中,mi表示卷积操作得到的第i个特征,f表示非线性函数,w表示一个滤波器的权重,它通过与一个窗口大小为h的输入特征x进行卷积操作得到一个新的特征,xi可以看作输入x的第i个输入,b为偏置。
将上述得到的所有特征连接起来就得到了卷积层的输出特征图M,如式(2)所示[17]。
M=[m1,m2,…,ml-h+1]
(2)
其中,l表示输入长度。
2.2.3 池化层
池化类似于一种“压缩”方法,在每次卷积过后,通过一个下采样过程来减小规模,简化从卷积层输出的信息。本文使用最大池化[18]的方法,对卷积层输出的每个向量取最大值,提取出最重要的特征信息,再连接成一个向量,得到池化层的输出。最大池化的方法能使用网络自动提取到句子中最有用的特征。
计算如式(3)所示[17]。
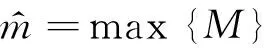
(3)
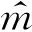
将上述得到的所有最大池化结果连接起来就得到了池化层的输出z,如式(4)所示[17]。
(4)
其中,k为滤波器个数。
2.2.4 BiLSTM层
LSTM(long short-term memory,长短时记忆网络)由Hochreiter等人于1997年提出[19],通过设置输入门、遗忘门、输出门,避免了循环神经网络(recurrent neural network,RNN)在隐藏层梯度计算时由于链式法则造成的梯度消失(梯度趋近于零)和梯度爆炸(梯度趋近于无穷)问题[20]。
Graves等人于2005年提出的BiLSTM[21]通过向前和向后分别训练一个LSTM,能做到同时保留“过去”与“未来”的文本信息。
由于LSTM只能保留“过去”的信息,即只能正向提取句子中的词汇、语义信息,而BiLSTM能在访问“过去”的信息的同时,访问“未来”的信息,即能从正向、反向两个方向提取句子中的词汇、语义信息,得到更丰富、更深入的信息,对于中文文本蕴含识别任务是非常有益的。
BiLSTM层对嵌入层的输出进行操作,以保留句子在“过去”以及“未来”的长期依赖信息,然后将这些信息连接起来,作为本层的输出。BiLSTM层的使用避免了传统机器学习方法需要人工提取大量特征的工作。
假设在t时刻的输入向量为xt,前一时刻的输出为ht-1,前一时刻的隐藏状态为ct-1,则当前时刻的状态ct和输出ht如式(5)、式(6)所示。
其中,当前时刻的输入X由输入向量xt与前一时刻的输出ht-1组成,如式(7)所示,w为权重,b为偏置,g、s分别表示状态的输入和输出的激活函数,it、ft、ot分别表示输入门i、遗忘门f、输出门o在t时刻的激活值,如式(8)~式(10)所示。σ表示三个门的激活函数。
2.2.5 全连接层
全连接层为三层的全连接结构: 输入层为T与H的池化层与BiLSTM层输出的连接Z,一个隐藏层,输出层使用softmax函数得到网络的识别结果。
计算如式(11)所示。
y=softmax(wfull·Z+bfull)
(11)
其中,y为网络识别结果,wfull为全连接层的权重,bfull为全连接层的偏置。
2.3 修正模块
修正模块使用外部资源编写语义规则对网络输出结果进行修正,得到最终的蕴含结果。外部资源包括近义词表、反义词表、否定词表。
基于王志浩[14]的工作,本文使用网络爬虫从近义词网站和反义词网站获取到近义词表与反义词表。
否定词表包含表示否定意义的词语,包括“不”“无”“非”“没”“未”“禁”等。
由于中文知识库资源有限,本文应用词表并结合规则的方法对网络输出结果进行修正,四条规则如下[14]:
规则1如果文本T和假设H的分词结果中存在近义词对,那么蕴含识别结果为“Y”,例如,
T1: “火地群岛,是南美洲最南端的岛屿群,由主岛大火地岛及周边小岛组成。”
H1: “火地群岛,是南美洲最南端的岛屿群,由主岛大火地岛及附近小岛组成。”
“周边”和“附近”是近义词,因此文本T1和假设H1存在蕴含关系,蕴含识别结果为“Y”。
规则2如果文本T和假设H的分词结果中存在反义词对,那么蕴含识别结果为“N”,例如,
T2: “阿巴多自 2003年接任琉森音乐节音乐总监后,成立了琉森节日管弦乐团(lucerne festival orchestra, LFO)。”
H2: “阿巴多自 2003年接任琉森音乐节音乐总监后,解散了琉森节日管弦乐团(lucerne festival orchestra, LFO)。”
“成立”和“解散”是反义词,因此文本T2和假设H2不存在蕴含关系,蕴含识别结果为“N”。
规则3如果文本T和假设H的差集(H中有而T中没有)中存在否定词,那么蕴含识别结果为“N”,例如,
T3: “中国移动具有互联网国际联网单位经营权和国际出入口局业务经营权。”
H3: “中国移动不具备互联网国际联网单位经营权和国际出入口局业务经营权。”
文本T3与假设H3的差集为“不、备”,“不”是否定词,因此文本T3和假设H3不存在蕴含关系,蕴含识别结果为“N”。
规则4如果经过统一数字预处理的文本T和假设H中存在不同的数字,那么蕴含识别结果为“N”,例如,
T4: “火地群岛总面积73753平方公里。”
H4: “火地群岛总面积37753平方公里。”
文本T4中的数字为“73 753”,而假设H4中的数字为“37 753”,两者不同,因此文本T4和假设H4不存在蕴含关系,蕴含识别结果为“N”。
3 实验
3.1 实验数据与评价指标
本文使用NTCIR-11的RITE-VAL评测任务的简体中文文本蕴含语料进行实验[8],测试数据共1 200对,训练数据通过收集往届数据扩充到1 976对,实验数据统计如表1所示。

表1 实验数据统计
评价指标为macro-F1和准确率(Accuracy),其计算如式(12)、式(13)所示[8]。
其中,C是分类的集合(Y和N);Prec.c和Rec.c分别是c类的准确率和召回率,计算如式(14)、式(15)所示[8]。
其中,Ncorrect表示正确识别蕴含关系的句对数,Nall表示总句对数,Npredicted表示预测结果中识别为c类的总句对数,Ntarget表示正确结果中应该识别为c类的总句对数。
3.2 参数设置
本文方法的参数设置参考Yoon Kim[17]的工作,如表2所示。
其中,所有的词向量都是随机初始化,并随着网络在训练过程中进行调整。使用窗口大小(h)分别为3、4、5的卷积核各100个。

表2 参数设置
3.3 实验结果及分析
针对2.2节的网络结构部分,为了对比分析不同网络结构的性能,本文设计实现了如下七种网络:
(1) CNN: 仅使用CNN对句子进行特征提取,使用全连接层根据提取到的特征进行分类;
(2) LSTM: 仅使用LSTM对句子进行特征提取,使用全连接层根据提取到的特征进行分类;
(3) BiLSTM: 仅使用BiLSTM对句子进行特征提取,使用全连接层根据提取到的特征进行分类;
(4) LSTM-CNN-series: 将LSTM提取到的信息传入CNN,使用全连接层根据CNN的输出进行分类;
(5) BiLSTM-CNN-series: 将BiLSTM提取到的信息传入CNN,使用全连接层根据CNN的输出进行分类;
(6) CNN-LSTM-parallel: 分别使用CNN和LSTM提取特征,使用全连接层根据提取到的特征进行分类;
(7) CNN-BiLSTM-parallel: 分别使用CNN和BiLSTM提取特征,使用全连接层根据提取到的特征进行分类。
本文对上述构造的七种网络进行实验,实验结果如表3所示。

表3 不同网络的实验结果比较
从表3中可以得到如下结论:
(1) 四种融合方式的实验结果均优于单一网络的实验结果,表明融合方式可以综合考虑单一网络各自的优点,提高中文文本蕴含识别方法的性能;
(2) parallel方法相对series方法,实验结果更好,表明使用两种网络分别对句子进行特征提取所获得的信息,要多于或优于将一种网络对句子提取到的特征传入另一种网络的方法;
(3) 分别对比BiLSTM与LSTM,BiLSTM-CNN-series与LSTM-CNN-series,CNN-BiLSTM-parallel与CNN-LSTM-parallel的实验结果,发现针对中文文本蕴含识别任务,BiLSTM要优于LSTM,因为使用BiLSTM可以保留文本中的“过去”与“未来”长期依赖信息,LSTM只能保留文本中的“过去”的长期依赖信息,而上文与下文信息均对中文文本蕴含识别具有重要作用。
同时与RITE-VAL评测的前三名方法进行比较,实验结果如表4所示,其中BUPT[5]、NWNU[22]、III&CYUT[23]为RITE-VAL前三名的评测结果。

表4 本文方法与评测方法的结果比较
表4的实验结果表明,本文提出的CNN-BiLSTM-parallel方法的实验结果已经超过RITE-VAL评测的前三名,表明该方法对于中文文本蕴含识别任务是有效的。其中,BUPT使用了中文分词、词性标注、命名实体识别、指代消解等四种NLP工具,人工提取了23个特征;NWNU使用了中文分词、词性标注、命名实体识别等三种NLP工具,人工提取了七个特征;III&CYUT人工提取了10个特征,人工编写了11条规则。而本文方法只使用了中文分词一种NLP工具,仅编写了四条规则,NLP工具的使用数量以及人工参与的工作量远远少于RITE-VAL评测前三名的参赛队伍,表明本文方法在一定程度上避免了人工筛选大量特征的工作,以及使用多种NLP工具造成的错误累计问题,同时提高了中文文本蕴含识别方法的性能。
最后,对比分析了本文方法与只使用CNN方法、只使用BiLSTM方法,以及BUPT方法的Y类和N类F1值,结果如表5所示。

表5 Y类与N类结果比较
从表5中可以得到如下结论:
(1) CNN的N类F1值远远高于Y类F1值,是由于CNN更关注于局部的特征,更偏向于关注文本对中不同的部分,如下例所示:
T5: “《罪与罚》是俄国文学家杜斯妥也夫斯基的长篇小说作品,出版于1866年。”
H5: “《罪与罚》是俄国科学家杜斯妥也夫斯基的长篇小说作品,出版于1866年。”
其中,“文学家”与“科学家”不对应,因此得出这两句话不具有蕴含关系。
(2) BiLSTM的Y类F1值远远高于N类F1值,是由于BiLSTM更关注于上下文的长期依赖信息,更偏向于识别并保存文本对中的相关信息,由于语料中T与H的文字重复比较高,所以BiLSTM网络易将N类误分为Y类,如下例所示:
T6: “中国移动具有互联网国际联网单位经营权和国际出入口局业务经营权。”
H6: “中国移动涉足网络业务。”
从T6的长句中可以得到“中国移动具有互联网国际联网单位经营权”的信息,进一步可以得到“中国移动有互联网业务”,与H6句意思一致,得出这两句话具有蕴含关系。
(3) CNN-BiLSTM-parallel的Y类F1值与N类F1值之间的差距较CNN和BiLSTM缩小了很多,表明融合两种网络起到了促进作用,但仍然是N类F1值较高,可能是因为CNN提取到的特征在其中起的作用更大。
(4) CNN-BiLSTM-parallel的Y类F1值与N类F1值之间的差距与BUPT相比,缩小了很多,表明本文方法对于两类蕴含关系的识别较为均衡,而BUPT方法严重倾向于Y类的识别。
通过分析实验结果,发现有如下几类情况易识别错误:
(1) 缺乏相关领域知识型
T7: “1981年6月6日,美国疾病控制与预防中心通报全球首宗爱滋病感染案例。”
H7: “1981年6月6日,美国疾病控制与预防中心通报全球首宗后天免疫缺乏症候群感染案例。”
由于缺乏“后天免疫缺乏症候群”的俗称是“爱滋病”的知识,导致蕴含关系识别错误。
(2) 逻辑推理型
T8: “1989年英伦航空92号班机空难,机上118名乘客中的39人当场死亡,8人于稍后时间亦过世;而机上的8名机员则全部生还。”
H8: “1989年英伦航空92号班机空难,机上126人仅79人生还。”
T8中的信息需要经过计算推理才能识别出与H8句具有蕴含关系,即从T8的信息中得到班机上一共有118+8=126人,生还118-39-8+8=79人,因此蕴含关系应识别为蕴含。
推理是文本蕴含识别中的一种重要语言现象,在RITE-VAL评测任务的1 200对测试集中,推理类型的子数据集有184对,占比最高,达15%[8],本文针对推理类型子数据集进行了实验,实验结果如表6所示。
从表6中可以看出,本文方法在推理类型子数据集上效果仍是较好的。

表6 在推理类型子数据集上的实验结果
续表

中文文本蕴含识别方法AccuracyBiLSTM-CNN-series52.72CNN-LSTM-parallel53.80CNN-BiLSTM-parallel57.07
4 结论
中文文本蕴含识别任务旨在判定中文句对之间是否存在蕴含关系,对信息检索、问答系统、文本摘要等任务具有重要意义。本文提出了一种基于CNN与双向LSTM的中文文本蕴含识别方法,该方法首先将句子映射到向量空间,然后使用CNN与双向LSTM对句子进行编码,自动提取相关特征,再使用全连接层进行分类,得到初步的识别结果,最后使用语义规则对网络识别结果进行修正,得到最终的蕴含识别结果。本文方法避免了人工筛选大量特征的工作以及NLP工具造成的错误累计问题,在2014年RITE-VAL评测任务数据集上的macro-F1结果为61.74%,当时评测第一名为61.51%[5],表明本文方法对于中文文本蕴含识别是有效的。
另一方面,本文的方法对于缺乏相关领域知识和逻辑推理型蕴含识别效果不佳。未来可以在相关领域知识与逻辑推理问题上进行改进,例如从大规模的文本中获取丰富的相关领域知识,解决由于相关领域知识的缺乏而导致蕴含关系识别错误,使用深度学习的方法解决逻辑推理问题。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
云南教育·小学教师(2022年4期)2022-05-17
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
艺术评论(2020年3期)2020-02-06
电子制作(2019年13期)2020-01-14
制造技术与机床(2019年10期)2019-10-26
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
电子制作(2018年18期)2018-11-14
