
基于多指标与卷积神经网络的化工产品需求预测
2018-08-17 03:04吴学华马晓华娄海川韩晓春侯卫锋
自动化仪表 2018年8期
吴学华,马晓华,娄海川,韩晓春,丁 杰,侯卫锋
(浙江中控软件技术有限公司,浙江 杭州 310053)
0 引言
随着现代化工产品的个性化定制需求越来越普遍、产品牌号越来越精细,准确预测企业的产品需求显得尤为重要。
产品的市场需求预测可以简化为对时间序列的预测。因此,简单的趋势外推法,包括移动平均法[1]、指数平滑法[2]、趋势预测法[3],常被应用于具有简单增长或降低的时间序列分析。但是简单的趋势外推法无法抓住外部环境的季节性、周期性波动和其他影响要素。近年来,分解预测方法较为流行。该方法将时间序列分解成长期趋势因素、季节变动因素、循环变动因素和不规则变动因素,并对除不规则变动因素以外的其他因素进行建模,从而对时间序列进行预测[4-5]。此外,在统计学中,自回归(autoregression,AR)模型、自回归滑动平均(auto-regressive moving average,ARMA)模型、自回归积分滑动平均(autoregressive integrated moving average,ARIMA)模型则更为常见,常被用于市场分析和预测[6-7]。最近,新的机器学习方法也常被用于复杂时间序列的分析和预测。利用自适应差分进化算法优化反向传播(back propagation,BP)神经网络,对多维时间序列进行预测,其精度优于传统的神经网络和ARIMA方法;利用循环神经网络(recurrent neural network,RNN)在口语序列和书面语序列之间进行分析和建模,达到了良好的转换和预测效果[8-9]。综上所述,对于简单或者复杂的时间序列,需要利用不同的建模方法进行分析和预测。
本文利用加权变异系数和帕累托分类两种指标,结合卷积神经网络(convolutional neural network,CNN),对某化工企业7大类共202种具体规格的产品进行了分析建模和预测,较好地实现了产品类别的划分;在考虑产品关联性的同时,减小了高低不确定性产品之间预测的影响;通过与传统ARMA模型和乘法分解预测模型的仿真对比,在大类产品的预测精度上取得了较好的效果。
1 变异系数与帕累托分类
1.1 变异系数
变异系数(coefficient of variation,COV)[10]又称离散系数,是概率论和统计学中对于一组数据离散程度的归一化量度。其表达式为:
(1)
式中:σ为该组数据的标准差;μ为该组数据的均值。
设该组数据为X=[x1,x2,…,xn-1,xn]。变异系数是衡量数据中各观测值变异程度的统计量。当进行两组或多组变量序列值的变异程度比较时,如果度量单位和(或)平均数相同,可以直接利用标准差来比较;如果单位和(或)平均数不同,则不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。变异系数可以消除单位和(或)平均数不同对两个或多个资料变异程度比较的影响。在进行数据统计分析时,如果变异系数大于1.5,则要考虑该数据可能存在异常值,这表明该序列的可预测性较差。
1.2 帕累托分类
帕累托分类[11]又称ABC分类。该分析方法是由意大利经济学家维尔弗雷多·帕累托首创的。1879年,帕累托在研究个人收入的分布状态时,发现少数人的收入占全部人收入的大部分,而多数人的收入却只占一小部分。他将这一关系用图表示,这就是著名的帕累托图。该分析方法的核心思想是在决定一个事物的众多因素中分清主次,识别出少数的、但对事物起决定作用的关键因素和多数的、但对事物影响较少的次要因素。
设存在产品1~10,其销售量为P=[p1,p2,…,p10]。将产品按销售量进行降序排列,并计算每一种产品销售量占总销售量的比率和累计比率。累计比率在0%~60%的为最重要的A类产品;累计比率在60%~85%的为次重要的B类产品;累计比率在85%~100%的为不重要产品。以此为依据,将产品进行帕累托分类。
2 卷积神经网络
卷积神经网络是由Y·Lecun[12]于1998年提出的、基于局部卷积和反向传播算法且不同于全连接神经网络结构的一种手写数字图像识别模型。该模型包括1个输入层,2个卷积层,2个降采样层,2个全连接层,1个输出层。这种结构的卷积神经网络对当时手写字体的识别率在95%以上,达到了商用级别。该结构的主要思想是利用不同的卷积核对输入图像的局部进行特征提取,再利用降采样层降低特征的维度,最后连接一个全连接神经网络,从而达到对手写数字的准确识别。而除了对图像进行识别以外,更多的改进卷积神经网络能够对语音、文本等各种复杂的数据进行处理和建模。
3 产品需求预测模型
基于卷积神经网络的需求预测基本框架如图1所示。

图1 基于卷积神经网络的需求预测基本框架
①为了准确地对产品每月的市场需求量进行预测,首先对产品的每月销量进行变异系数计算。在此采用k段滑动窗口法,并对历史数据窗口进行权重衰减,即时间越远的时间段权重越小,从而使得近时间段的趋势得到更好的利用。设某种产品n个月内的月销量为S=[st1,st2,…,stn],k段滑动窗口的权重分别为w1,w2,…,wk,则该产品的加权变异系数可以定义为:
Cv=w1×Cv1+…+wk×Cvk
(2)
(3)
(4)
式中:σn为第n个滑动窗口的标准差;μn为第n个滑动窗口的均值。
②对产品进行帕累托分类,将多种产品进行销售量的降序排列。这里仅进行AB分类,即高数量与低数量的分类,并将产品的累计百分比划分阈值定为70%。
③对划分好的4大类产品(高需求量高不确定性、高需求量低不确定性、低需求量高不确定性、低需求量低不确定性),分别构建针对多时序数据的卷积神经网络。由于卷积神经网络的建模能力较强,对月销售量以天为单位进行分解建模。设4大类产品中的某一类共有m种具体产品,以前n天的订单需求量为整个神经网络模型的输入X,以后k天的订单需求量为整个神经网络模型的输出Y,则X、Y可以表示为:
(5)
(6)
式中:xnm为前第n天、第m种产品的日需求量;ykm为后第k天、第m种产品的日需求量。
设一维时序卷积核为K=[k1,k2,…,km]∈Rm。其中:ki=[ki1,…,kiL]T,L为卷积核长度。设滑动步长为1,则对输入X进行卷积操作,可以表示为:
cnm=K×[xnm,…,x(n+L)m]T
(7)
采用最大池化(Maxpooling)降采样的方法。设降采样间隔为2,则降采样操作可以表示为:
(8)
式中:f为激活函数。
通常采用sigmond函数,经过多层卷积和降采样操作后,直接与输出层相连,并通过误差反向传播算法[13]更新网络权重,主要更新内容为卷积核的参数调整。
4 试验仿真
本文收集了某化工企业2015年1月至2017年11月,这35个月的7大类共202种具体产品的需求订单数据,以月为单位进行COV分析和帕累托分类。其中:COV阈值为1.5,帕累托分类阈值为60%。由此得到的化工产品分类如表1所示。
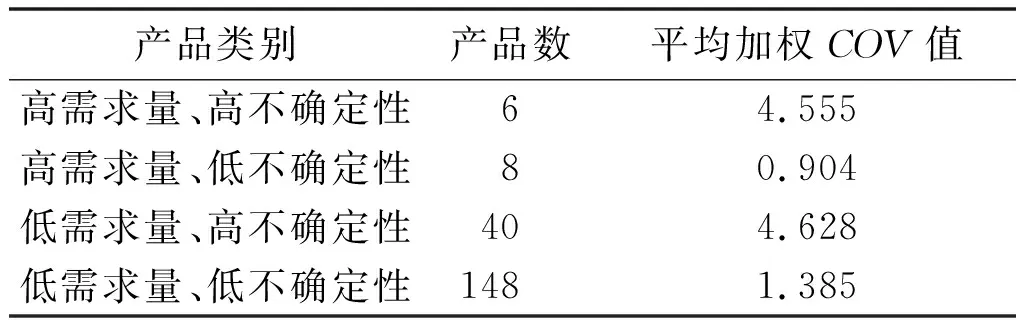
表1 化工产品分类表
根据以上产品划分,从ERP数据库中提取了这些产品在2017年的10月、11月这2个月的订单数据作为测试数据,其余33个月的数据作为训练数据,将月数据分解为天数据,模型的输入为m天、输出为n天。对每一类数据,首先进行标准化处理:
(9)
利用深度学习库Keras[14]进行卷积神经网络的序贯模型构建。由于卷积神经网络模型的构建具有试验性质,即需要人为确定的超参数较多,因此,本文采用多组超参数进行对比试验。以长输入常卷积常池化卷积神经网络(long input normal convolution normal pooling-convolution neural network,LNN-CNN)为例,在本文中,其具体结构为“输入长度为k×20的时间序列-k×3的卷积核-k×2 的最大池化层-k×3的卷积核-k×3的卷积核-输出为长度为k×5的时间序列”,缩写为I30-C3-P2-C5-P2-O5。其中,k为卷积核的宽度,即该大类产品的数量。
假设模型输入的序列长度为m,预测输出的长度为n,而实际需要在月维度上进行预测对比。因此,采用动态递推预测,即当需要预测未来(n+1)~2n天的数据时,则采用的模型输入为先前预测的n天数据和前(m-n)天数据,从而递推预测未来一个月该大类产品的总销售量。经过模型训练,并与ARMA和乘法分解预测法进行对比:ARMA模型中自回归项阶数(AR阶数)和滑动平均项阶数(MA阶数)分别在范围中进行测试,并根据赤池信息量准则(akaike information criterion,AIC)[15],取AIC值最小的阶数组合为ARMA模型的最终参数。而卷积神经网络的结构采用了4种结构:LNN-CNN,本文中具体结构为I30-C3-P2-C5-P2-O5;
长输入多卷积常池化神经网络(long input multi-convolution normal pooling-convolution neural network,LMN-CNN)模型,本文中具体结构为I30-C3-C3-MP2-C2-C2-MP2-O5;2种短输入不定层卷积神经网络模型(stochastic layer-convolution neural network,SL-CNN),本文中其结构1为I20-C3-MP2-C3-C3-O5,结构2为I20-C3-C3-MP2-C4-O5。误差评价函数取平均百分比准确率:
(10)
测试数据中,每大类产品的平均百分比误差如表2所示。

表2 不同模型的预测结果对比
由以上对比结果可以看出:基于一维时序的多产品卷积神经网络模型,在高(低)需求量、低不确定性的产品类别上,与其他两种算法模型相比,并没有较大的优势。尤其是在高需求量、低不确定性的产品类别上,由于该类产品季节性较为明显,因此乘法分解预测模型能较好地抓住产品的季节性分量,从而得到较为准确的预测。而在高(低)需求量、高不确定性的两类产品下,LMN-CNN模型的预测精度较高,两个月平均准确率分别高于另外两类模型7.75%和8.29%;而与同样的CNN模型相比,两个月平均准确率分别高于另外3种结构模型2.12%、4.02%和5.05%,多卷积层模型通过多次卷积变换,抓住了不确定性高的时间序列波动模式,从而能更有效地进行预测。从总体平均预测效果看,LMN-CNN模型两个月平均预测准确率为89.22%,对于不同类型数据的预测稳定性普遍较高,特别适用于工业领域多牌号产品的整体预测。
5 结束语
本文针对某化工企业的产品体系,提出了一种基于多指标结合卷积神经网络的需求预测框架。首先,利用COV分析和帕累托分类对7大类共202种具体规格的产品进行划分;然后,对月需求订单进行日分解,并利用4个卷积神经网络分别对4大类产品进行合并预测;最后,对不同类型的模型以及不同结构的同类型模型进行对比。测试结果表明,相较于传统的统计时间序列预测法和时间序列分解预测法,LMN-CNN模型对不确定性较高的产品的预测效果较为明显。该结果验证了该模型的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学大王·中高年级(2021年6期)2021-09-27
成都信息工程大学学报(2021年1期)2021-07-22
当代水产(2020年2期)2020-03-17
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津经济(2016年10期)2016-12-29
湖北工业职业技术学院学报(2009年1期)2009-04-07
