
基于深度卷积神经网络的街景门牌号识别方法
2018-08-01 01:10:00韩鹏承胡西川
现代计算机 2018年20期
韩鹏承,胡西川
(上海海事大学信息工程学院,上海 201306)
0 引言
现如今在计算机视觉领域中已经取得了很多的研究成果,例如像光学字符识别(OCR)[1]从扫描文档中提取文本信息已经取得了成功。但与此不同的是对于自然场景中的字符识别问题,由于像街景门牌号这样的自然场景中的字符拥有复杂的图像背景和各种各样的噪声,通过人工提取特征的方法无法达到很好的效果,这就导致对此类字符的识别存在着挑战。直到以卷积神经网络(Convoluted Neural Network,CNN)[2]为代表的深度学习兴起才给这个难题带来了突破性的进展。
20世纪90年代,由LeCun[3]等人发表了论文,确立了CNN的现代结构,并设计出了经典的LeNet-5网络结构用来识别手写数字,取得了很好的效果,这个成果也首次展示出卷积神经网络在实际应用中的潜力和价值。由于当时可用于研究的样本数据很少以及计算机性能不足,使得CNN的发展进程很缓慢。直到现在,大数据时代背景下,可用于研究的数据集得到了很大的扩展;CNN网络经过多年的发展,它的结构得到了不断的改进和完善网络的性能进一步提高;现代计算机性能与之前相比有了很大幅度的进步,并提出利用GPU加速神经网络的训练和识别[4],与CPU相比GPU在单位面积/单位功耗上拥有更高的计算能力和吞吐带宽,因此通过GPU训练网络可以大大提高效率并且GPU强大的计算能力可以使网络在更大的数据集训练提高精度。多方面的原因使得卷积神经网络得到了发展。2012年Alex Krizhevsky等人发布了AlexNet网络结构[5],该网络是具有八层结构的深度卷积网络,并用它在当年的ImageNet图像分类竞赛中取得了第一名的成绩。除此之外,近年来还推出了很多比较有名的CNN 结 构 有 VGGNet[6]、GoogleNet[7]和 ResNet[8]。 将CNN应用在文本识别、图像分类、情感识别、目标检测等多个领域都取得了很多的研究成果。
传统的图像识别方法需要人工提取特征,由于人工提取特征的局限性,这种方法往往无法达到实际中对精度的要求。CNN是一种多层的网络结,它通过从大量的数据中逐层学习和提取特征,自主地完成对数据的抽象。相比人工提取的特征使用CNN自动提取的特征进行识别可以达到更好的效果,且特征提取的过程变得更加简洁有效。因此,越来越多的研究人员将CNN运用在字符识别上。如QIang Guo构造出了CNN-HMM混合模型[9],对街景门牌号的(Street View House Number,SVHN)数据集的识别率为81.07%。王强等人将主成分分析法(Principal Componets Analysis,PCA)和 CNN相结合[10],利用快速 PCA和 CNN对SVHN数据集的识别率为95.10%,这在识别效果上得到了很大的提高,但是需要花费很大的时间代价,该方法需要的训练时间约为1周。Ma Miao[11]等人构造的改进LeNet-5在SVHN数据集上经过7个小时的训练识别率达到90.35%,时间大大缩短但是识别率不高。
针对存在的不足,提出的基于深度卷积神经网络的识别方法在网络的结构上做出了改进,加深了网络的深度增加了网络的卷积层数和卷积核的数量并优化网络结构;对图像进行预处理,将原始图像灰度化来弱化图像背景颜色、光照条件等无关的特征,突出重要的特征。改进后该网络在SVHN数据集上可以达到94.58%的识别率,训练时间约为13小时。
1 深度卷积网络设计
1.1 卷积神经网络
卷积神经网络是一种局部感知和权值共享的网络结构,本质上就是指它相比较其他网络会产生更少的可调参数,降低了学习复杂度;并且卷积神经网络对图像的平移、倾斜、缩放或其他形式的形变具有高度不变性,说明了卷积神经网络具有优良的特性。
卷积神经网络的典型结构如图1所示,该网络由输人层、卷积层、池化层、全连接层及输出层组成。输入层是整个网络的起点,网络的输入是二维的图像;卷积层的作用是提取特征;池化层对输入的特征图尺寸进行压缩使特征图变小,降低网络计算复杂度,并且进行特征压缩提取主要特征;全连接层学习全局特征,将前面得到的局部特征整合到一起输出给分类器;最后的输出层是整个网络的输出。

图1 典型卷积网络结构
1.2 卷积网络的设计
网络结构基于AlexNet进行改进,共有7个卷积层。网络的输入是32×32的图片,输出是每个门牌号字符对应的分类。第一层卷积层的卷积核大小为5×5,卷积步长为2,卷积核数量为64个,使用ReLU作为非线性激活函数,然后使用 BN(Batch Normalization)[12]进行归一化处理,最后连接了一个Max pooling层,大小为2×2,步长为1。第二层卷积层卷积核的大小为3x3,卷积步长为1,该层共有128个卷积核,随后采用和第一层同样的策略。第三层使用大小为3×3的卷积核,步长为1,共有256个卷积核,随后采用同上的策略。第四层卷积核大小为3×3,步长为1,共有384个卷积核,后面也是采用同上的策略。从第五个卷积层开始连续堆叠了三个卷积层,卷积核大小都是3×3,步长为1,前两个各有256个卷积核,最后一层有192个卷积核,之后使用ReLU作为激活函数,然后使用BN进行归一化处理,最后连接一个窗口大小为2×2,步长为1的Max pooling层。此后连接3个全连接层,前两个全连接层神经元的个数为1024,利用BN对结果进行归一化,并采用Dropout策略来忽略一定量的神经元,可以明显地减少过拟合现象,比例设置为0.2。最后一个全连接层神经元个数设置为10,也就是字符识别后的分类,连接Softmax分类器进行分类。
1.3 激活函数
如果不使用激励函数,神经网络的每层都只是做线性变换,但是线性模型的表达能力不足无法处理复杂的非线性问题,所以通过激励函数引入非线性因素可以提高模型的表达能力。经常用到的激活函数有sigmoid、tanh、和ReLU,他们各自的公式如下。其中ReLU函数要比sigmoid和tanh等函数具有更快的收敛速度,能节省大量的训练时间。
sigmoid函数:

tanh函数:

ReLU函数:

1.4 BN归一化
随着深度学习的发展,随机梯度下降成了训练深度网络的主流方法。但是该方法存在不足,大量参数的设置需要人为的去完成,例如网络的初始权重和bias、网络的学习率、权重变化系数、Dropout比例等。这些参数对网络的性能有很大的影响,而调节这些参数需要花费很多的时间。BN的出现使得这些调参变得不再那么重要。BN可以将卷积层输出的数据归一化为0均值和单位方差,如下式:

其中k为一个训练批次中包含的样本个数,但是仅仅使用这样的处理方式,对前一层网络的输出数据归一化后再送入下一层网络,会使得前一层网络所学习到的特征分布遭到破坏。于是提出了一个很好的方案:变换重构,引入了可学习参数γ、β如下式所示:

其中,每个神经元xk都会有一对参数γ、β。当时就可以恢复前一层网络所学到的特征。所以引入可学习重构参数,可以让原始网络学习到的特征分布不被破坏。
此外,对于BN的位置也做了相应的调整,此前很多的文献都是将其放在了激活函数的前面,但在该方法中将BN放在了激活函数的后面。本文采用的是ReLU 激活函数,即 ReLU=max(Wx+b,0),这么做的原因是因为初始的W是从标准高斯分布中采样得到的,而W中元素的数量远大于x,Wx+b每维的均值本身就接近0、方差接近1,所以在Wx+b后使用BN归一化处理能得到更稳定的结果。
2 实验
2.1 实验所用的数据集
SVHN数据集包含训练集,测试集,额外集3个子集。其中训练集包含了73257张数字图像,测试集包含26032张数字图像,额外集由531131张数字图像组成。该数据集被分为10类,每一个类别代表一个数字,例如字符“1”类别标签是 1,以此类推字符“9”的类别标签是9,在这个数据集中字符“0”的类别标签是“10”。实验采用的是SVHN Formate2格式的数据,将原始的图像都归一化为大小为32x32的彩色图像并将多个字符划分为单个的字符进行识别。实验中对数据的label进行了调整,使得字符“0”的类别标签为“0”。部分数据集如图2所示。
2.2 数据处理
对原始的彩色图像进行灰度化处理来舍去图像背景颜色、光照条件等无用的特征,采用加权平均值法。根据人眼对RGB三个分量的敏感程度的不同,给这三个分量赋予不同的权值进行加权平均。一般采用的公式如下:
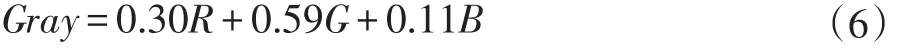
式中的Gray代表处理后的图像,RGB为三个不同的分量,前面的系数代表每个分量占有不同的比重。事实上这样的处理方式,计算机在计算的时候已经可以很快了,但是为了进一步提高效率,本文采用的公式如下:
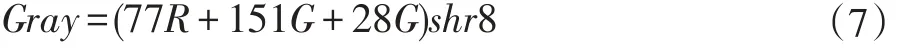
采用(7)方法要比(6)快近3/4。

图2 SVHN部分数据集
2.3 实验过程和结果
实验环境为:GPU为NVIDIA GTX 960M,显存2G;64位Microsoft Windows 10操作系统;使用TensorFlow开源库,Python编程语言。实验过程分为训练和测试两个阶段。在进行网络训练之前,针对SVHN数据的特点进行灰度化预处理舍去颜色、光照等无用信息,使网络更容易提取到重要的特征,之后用预处理后的数据作为卷积网络的输入进行训练,得出模型,最后将用于测试的数据进行相同的预处理之后进行测试进行分类,统计正确识别率。具体过程如图3所示:
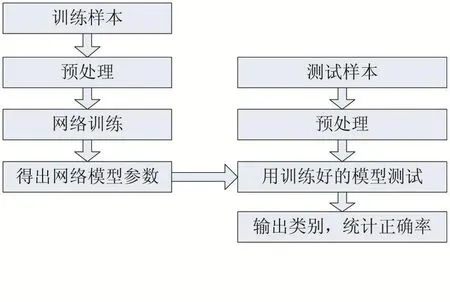
图3 实验流程图
实验中 epoch设置为 100,学习率为0.01,每个batch的大小设置为50。得出平均的正确识别率为94.58%。在实验过程中epoch如果设置的太小,网络得不到充分的训练导致最终模型的识别正确率不高;如果设置的太大这无疑会增加训练的时间且模型的识别率也不会有所提高。另一个重要的参数是网络的学习率,如果学习率太大在训练过程中lost值会一直大幅度的震荡,随着迭代次数增加loss也不会减小;如果太小lost就找不到很好的下降方向,在整个训练过程中基本不变,网络无法收敛。图4是当epoch为100、学习率为0.01、batch大小为50时损失函数变化情况,可以看出在经过训练后得到了很好的收敛,收敛的速度也是很快的;图5则是对应的识别正确率变化情况。

图4 网络损失函数
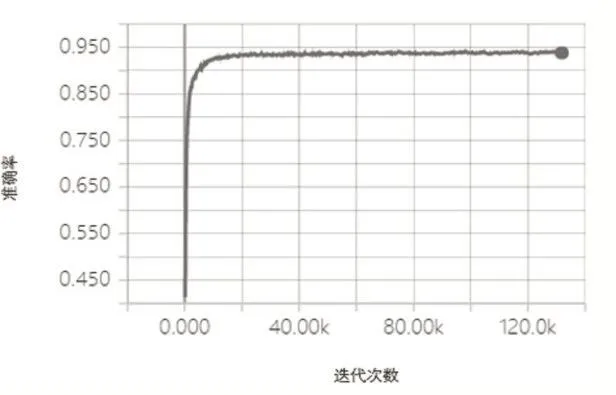
图5网络的准确率
图6 给出了本文方法在验证集上的实验结果的归一化混淆矩阵,以便于能够更清楚地观察到每类图像被正确分类的比例和被错分到其他各个类别的比例。验证集来源于从测试集中随机抽取的10000张图片。其中混淆矩阵中的纵轴表示图像的实际类别标签,横轴则表示图像经过卷积网络预测的类别标签,第i行j列的值表示第i类图像被分为第j类图像的比例,混淆矩阵对角线上的值代表每类图像正确分类的个数所占的比例。表1则给出了基于不同方法的平均分类准确率的比较。
由表1的结果可以看出,本文的方法的分类准确率与除去PCA-CNN方法之外的其他方法相比有明显的提高。PCA-CNN方法的分类准确率略高,但是PCA过程计算量很大导致整个网络训练时间大约为1周,本文提出的算法经过13小时的训练就可以达到94.58%准确率,所需要的时间代价要小得多。
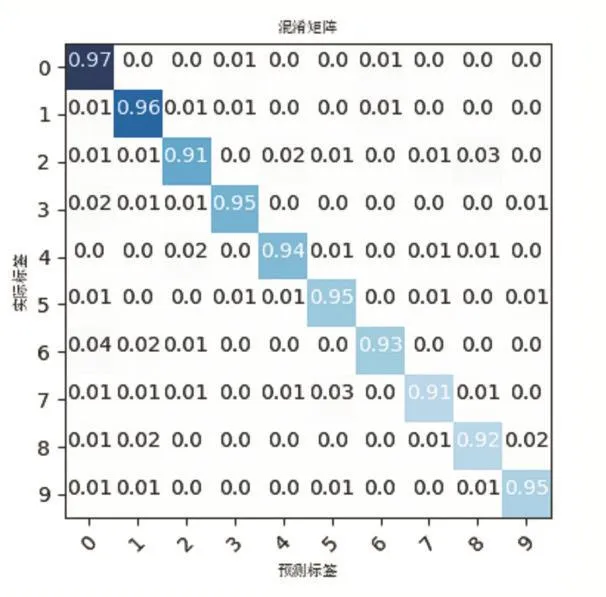
图6 模型分类结果的混淆矩阵
3 结语
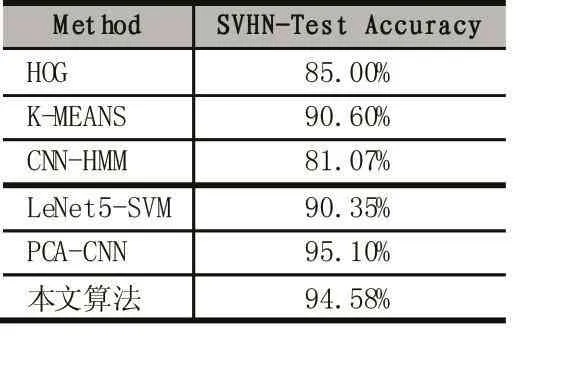
表1 不同方法的分类结果比较
针对自然背景下的门牌号的识别问题,提出了一种基于深度卷积网络的自动识别方法。对原始的图像数据做了灰度化处理,舍去了颜色、光照等无用的特征,之后将数据输入给卷积网络让它自己在不断的学习过程中提取深层次的图像特征。网络在经过近13小时的训练平均识别率可以达到94.58%,具有训练时间短识别率高的特点。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年11期)2019-07-04 00:34:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国交通信息化(2016年2期)2016-06-06 07:28:02
河北科技大学学报(2015年5期)2015-03-11 16:16:37
电测与仪表(2014年2期)2014-04-04 09:04:00
