
基于MapReduce和BP神经网络的数据融合研究
2018-07-31 11:42刘晓淞
长春工程学院学报(自然科学版) 2018年2期
刘 倩,刘晓淞,孙 静,李 时
(1.滁州职业技术学院机电工程系,安徽 滁州 239000; 2.国网滁州供电公司营销部,安徽 滁州 239000)
0 引言
智能电网大数据是支撑智能电网的关键,在发电、输电、变电、配电、用电等环节中都存在电网大数据的产生、数据采集、数据存储及数据分析,其中包含着大数据的巨大价值,应保证全方位的信息数据采集、无阻塞信息通信和高能效的数据处理分析,为此,智能电网大数据融合方法研究已经成为当前的研究热点之一。
近年来,随着研究的不断深入,研究人员提出了多种智能电网大数据融合方法,概括而言可以分成以下两类:1)文献[1-2]从电力数据分析的角度,从数据存储、数据处理等方面阐述了智能电网的大数据特征,并指出面临的数据挑战问题;2)文献[3-5]从电力数据处理的角度,从数据需求、预测模型以及电网侧采集、数据处理方法等方面进行了研究。上述两种方面的方法都处于初级阶段,如今及往后的电力流和信息流必然会达到双向统一,所以在电力的各个环节高效的信息数据采集以及通信、数据分析处理必须得到保证。已有的研究都普遍存在计算量和通信量较大的问题,为此,本文提出了一种基于互信息、MapReduce和BP神经网络的融合处理算法,以期进一步降低智能电网庞大的电力数据计算量和通信量。
1 数据融合
数据融合就是将信息源处的数据进行关联,得到精准的估计处理的过程,包含数据融合层次:数据层、特征层、决策层,数据融合的方法:支持向量机、BP神经网络等方法。本文提出基于互信息和BP神经网络的融合处理算法处理智能电网大数据。
2 互信息和BP神经网络描述
2.1 互信息描述
互信息是一种用来度量两个随机变量的统计依赖性的方法,它不仅能处理线性变量,还能处理非线性变量,广泛应用于特征数据的提取和选择。它是一种描述变量不确定性和复杂性的度量,互信息算法对变量的选择过程就是筛选出强相关变量的过程。
互信息理论通常可以由两个变量的联合概念密度或者信息熵来表示,互信息越大,两个变量之间的相似度越大。
图1中U和V代表两组变量,H(U)和H(V)是变量U和V的边缘熵,H(U,V)为两个变量的联合熵,H(U|V)为两者的条件熵,I(U,V)为其信息熵,设已知的随机变量W,则变量U和V关于W的信息熵为:
(1)
式中:PU,V,W为联合概念分布;P为条件概率分布。
互信息的变量选择算法流程:
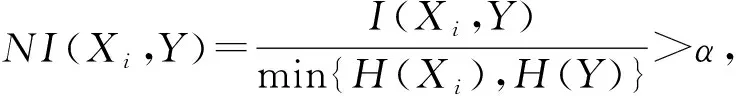
2)保留强相关变量,去除弱相关变量。
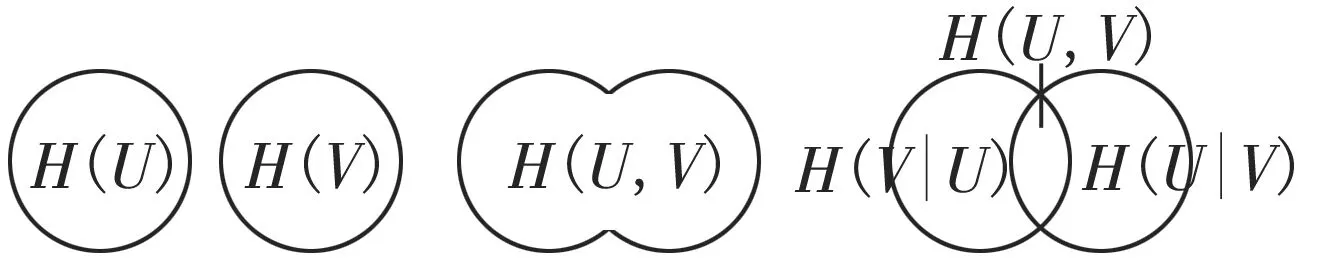
图1 互信息与信息熵之间的关系示意图
2.2 基于MapReduce模型的BP神经网络描述
MapReduce是由谷歌提出的一种用于海量数据集的分布式计算和并行计算的编程模型,Map可以对一些独立数据进行操作,其操作结果保存在一个新的列表里;Reduce是对Map创建的新列表进行合并、归纳总结。本文把BP网络算法和MapReduce
进行综合,该方法在处理大数据时能快速收敛、精度高。其算法如下:
1)按上文算法计算输入的条件属性与决策属性的互信息,将其矩阵化处理,形成一层输入层,完成变量的特征选择提取过程。
2)对数据源分成多个Map任务,设定阈值进行BP网络训练,训练结果写入硬盘。
3)Reduce执行Reduce函数,重复计算直至结束,将Reduce任务的输出合并得到融合结果。
3 实验分析
3.1 实验数据
实验数据采用滁州天长市变化的气象条件下,2017年9月风机的监测数据,大小为1 G,其中选取12个状态参数(见表1)作为输入属性值对风机发电功率进行预测分析。

表1 风机12个属性值对应的状态值
根据上文变量之间互信息之间的算法得出本实验各变量之间的互信息,根据其相关性大小排列,采用其数据状态参数如图2所示,输入属性值选为X1、X3、X4、X9、X10、X11、X12。
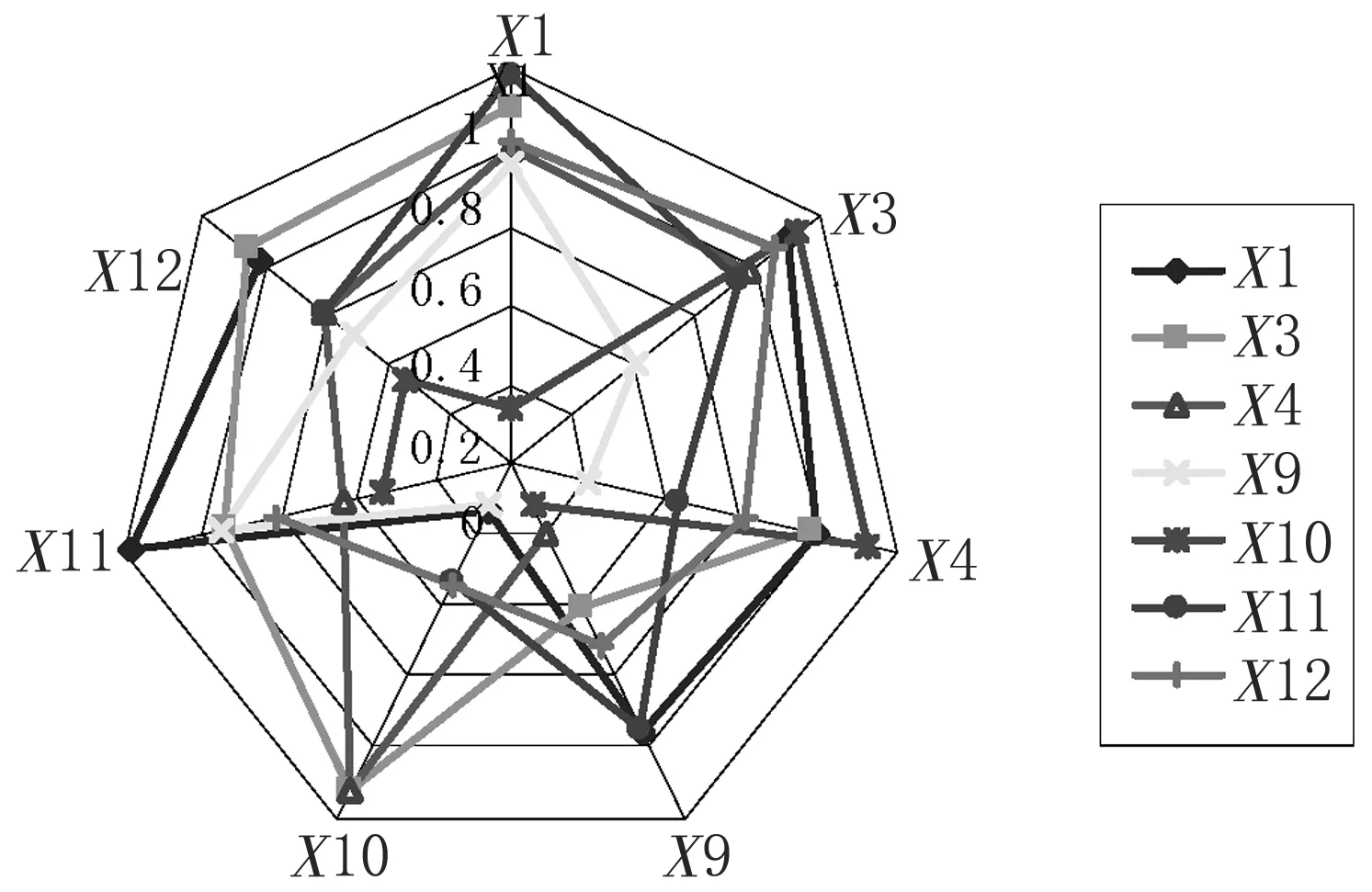
图2 数据特征值的互信息
3.2 仿真过程及分析
滁州某市5台风机的监测数据,通过互信息算法选取12个输入状态参数的相关性,选取Xi作为预测模型的输入值,针对不同的预测模型,得出风电场在20 h之内输出功率的预测结果如图3所示。
分析图3中曲线,点划线为风电场实际输出功率值,虚线为采用BP神经网络算法得到的预测值,实线为本文算法得出的功率预测值,从图中可以看出采用互信息算法进行输入状态参数筛选之后,本文模型预测出的功率和实际功率最接近,说明采用互信息算法能对变量进行很好的优化,基于MapReduce和BP神经网络相结合在保留原有特征信息的同时将冗余的大数据进行筛选提取,达到了数据融合的目的。
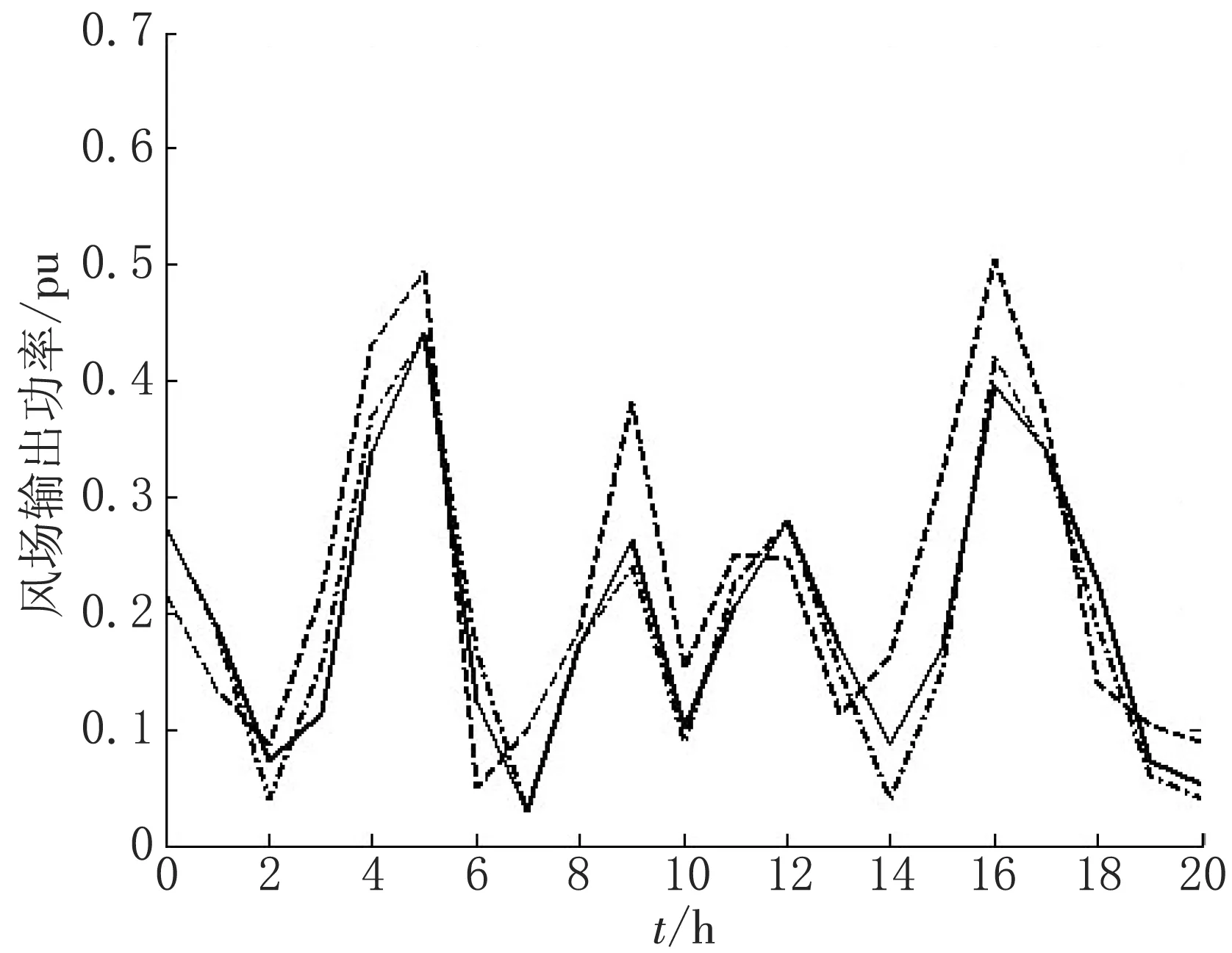
图3 采用不同预测算法模型进行功率预测的结果
图4从预测误差的角度来进行实验对比研究,误差评价标准采用均方根误差、平均绝对百分误差和t检验。
图4中点划线为本文算法的误差值,实线为BP神经网络模型的误差值。从图4可以看出,本文采用的算法的绝对误差远小于传统算法的预测误差值,而且绝对误差的波动值较小。若将模型的预测数据量进行扩大,由之前的1 G扩大到12 G、24 G、120 G,通过实验预测分析,对比预测时间,结果见表2。
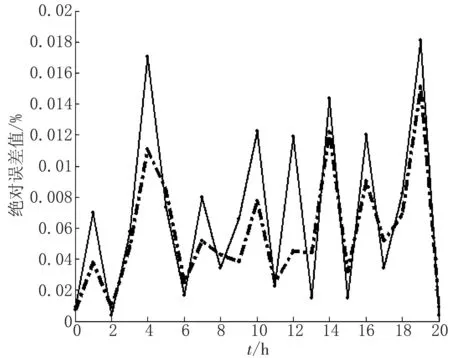
图4 不同预测算法模型进行功率预测的误差对比

单位:s
分析表2得知,在较小的输入状态参数的情况下,本算法的数据处理缩短的时间和效率的增加不显著,但是在大数据状态参数的情况下,本文算法处理数据的时间大幅下降,比BP算法处理时间节省约1/3,效率提高约3倍,分析表明本文算法在减少数据规模,去除数据冗余上效果明显,满足电网数据融合的需要。
4 结语
本文对电力系统的大数据融合及风机发电功率预测进行了介绍,建立了大数据特征参数处理、提取、筛选方法和功率预测的模型。基于本文的性能评价体系对本文预测算法进行试验分析,实验结果表明通过互信息、MapReduce和BP神经网络算法进行数据融合处理,在大数据的情况下较明显地提高了模型效率和预测精度。
猜你喜欢
南京工程学院学报(自然科学版)(2022年2期)2022-08-16
土木建筑与环境工程(2022年4期)2022-05-14
农业工程(2021年6期)2021-07-29
电子制作(2019年19期)2019-11-23
实验流体力学(2018年6期)2018-02-13
重型机械(2016年1期)2016-03-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
大连工业大学学报(2015年4期)2015-12-11
电测与仪表(2015年9期)2015-04-09
