
基于Hadoop的中医症状群分类应用
2018-07-25 11:23石艳敏张守宾朱习军
计算机应用与软件 2018年7期
石艳敏 张守宾 朱习军
(青岛科技大学信息科学技术学院 山东 青岛 266061)
0 引 言
通过“四诊”信息中医学可以发现人体生理和病理的变化,故采用中医辨证原理来诊断病症,然后对症下药,治愈疾病[1]。作为患者的外在表现,症状是识别疾病的重要航标,也是诊断证型的重要依据。因此,对症状正确分类(辩证过程)是治愈疾病的重要环节,也是确保疗效的前提。为获取更高的分类精确度,以及提高算法的效率,本文采用分类算法实现对某种证型的判定,即基于KNN算法在Hadoop平台下分布式计算实现对多组症状群的分类。挖掘出症状-证型间的内在联系,即症状群所属的证型类别,从而分析出症状与证型之间的密切关系[2]。
1 Hadoop平台
Hadoop[3]是Apache基金会所开发的一个开源的分布式系统软件框架。该框架具备的高可靠性、高扩展性、高容错性和低成本等特点使其成为当前运用最广泛的云平台框架。其核心组件包括:分布式文件系统[4](HDFS)、分布式计算框架[5](MapReduce)和资源管理系统YARN等,该框架通过组建集群的方式实现对大规模数据集的高速计算和存储。目前已在谷歌、亚马逊、Facebook、Yahoob百度等多个大型网站上得到应用。能够稳定解决海量数据的存储、计算分析以及资源的管理调度等问题,是当前该领域炙手可热的开发和运行处理大规模数据的软件平台,这对日益庞大的中医病案数据来说,是一个新的发展契机。
MapReduce 编程模型[6]是一个基于分布式计算模式的软件结构。分布式计算过程可简化抽象为两个函数:Map函数和Reduce函数。首先由JobTracker负责将大规模任务分解;然后,Map函数执行分解后的小任务并得到中间结果;最后,由Reduce函数执行汇总得到最终结果。其MapReduce编程模型的处理流程主要分为以下几个阶段,如图1所示。
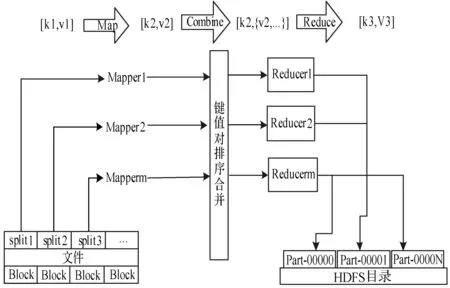
图1 Mapreduce模型计算过程
(1) 分块分配阶段:MapReduce模型将待处理数据集切分为固定大小的片Splits,其大小默认为64 MB,每个Split创建一个map任务,这里可以根据具体数据情况,设置切片大小,创建更多的map任务个数。
(2) Map阶段:Map函数继承Mapper类,读取属于自己的数据片Split,并将其映射成键值对
(3) 将Map任务产生的中间结果周期性地写入磁盘之前,将对这些键值对进行二次排序,首先根据数据所属的partition(partition是分割map每个节点的结果)分组,相同key的value放到一个集合中,然后每个partition中再按key排序。如果设定了Combiner,则将key相同的数据收集到一个List中,得到
(4) Reduce阶段:用户定义Reduce函数继承于Reducer类,通过与对应的数据节点通信,获取数据并整合排序。再经过Reduce函数自定义操作,将输入的中间键值转化为新的键值对
2 KNN算法
KNN(K-Nearest Neighbor)分类算法[7]是比较经典的机器学习算法之一,它由Cover和Hart在1968年提出。主要应用对一些未知事物的分类,基于距离准则来判断未知事物所属的类别。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,故KNN方法较其他方法对于类别域重叠较多或交叉的待分样本集更为适合[8]。
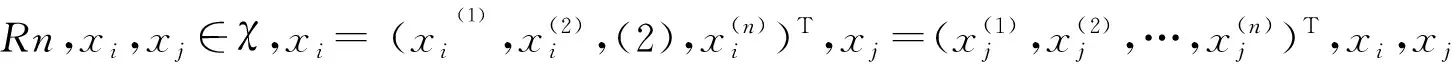
当p分别等于1、2、∞时,度量函数分别为曼哈顿距离、欧式距离和切比雪夫距离。
3 KNN算法并行化设计
KNN算法串行实现的时间复杂度为O(nm),n、m分别表示样本总数和属性数目。因此该算法的计算量随n、m的增大以n×m形式增长。但每个待分类样本都可以独立进行KNN分类,因此可以基于Hadoop平台中MapReduce模型并行化计算求解高复杂度问题[9]。在Hadoop分布式计算平台上实现KNN算法,首先是worker节点将训练集和测试集从HDFS文件系统下载到本地节点,启动Map计算过程,并根据所选择的度量距离公式计算测试样本与训练样本的距离。最后将中间计算结果送到Reduce节点规约生成最终结果。
任务中将训练集和预测集读取到内存中进行切分处理,计算测试样本与训练样本的距离;在Combine和Reduce进行排序和统计的工作。
3.1 Mapper的设计
Mapper主要包括三个函数:setup()、map()、cleanup()。首先调用内置Split函数读取样本片并转换成特定格式文件,之后遍历计算测试样本与每个训练样本的度量距离,存放在context集合形成键值对映射。主要流程为:
(1) 初始化数组List1
(2) 根据所选度量函数计算每个测试样本与本节点中训练样本的距离值。
(3) 输出数据
3.2 Combiner的设计
Combiner相当于一次本地的Reduce操作,它在Map函数输出的集合中取出键值,进行筛选和排序:对每一个测试样本所对应的向量集合,按照度量距离选取K个最近邻样本作为Reduce节点的输入,从而节约Reduce节点的计算和通信开销。具体流程为:首先将Map节点的键值对存入ArryList集合,然后按value增序排序,最后每个测试样本根据设定的K选取K条记录传给Reduce节点。Combiner需要输入/输出的格式都是即
3.3 Reducer的设计
Reducer主要任务是进行规约获取K个近邻,计算多数近邻样本的类别,并赋予测试样本。模型中执行shuffle操作,即:将不同Map节点上同一测试样本的数据送到一个节点上执行排序、分类以及输出操作。输入数据
并行的KNN分类算法流程如图2所示。
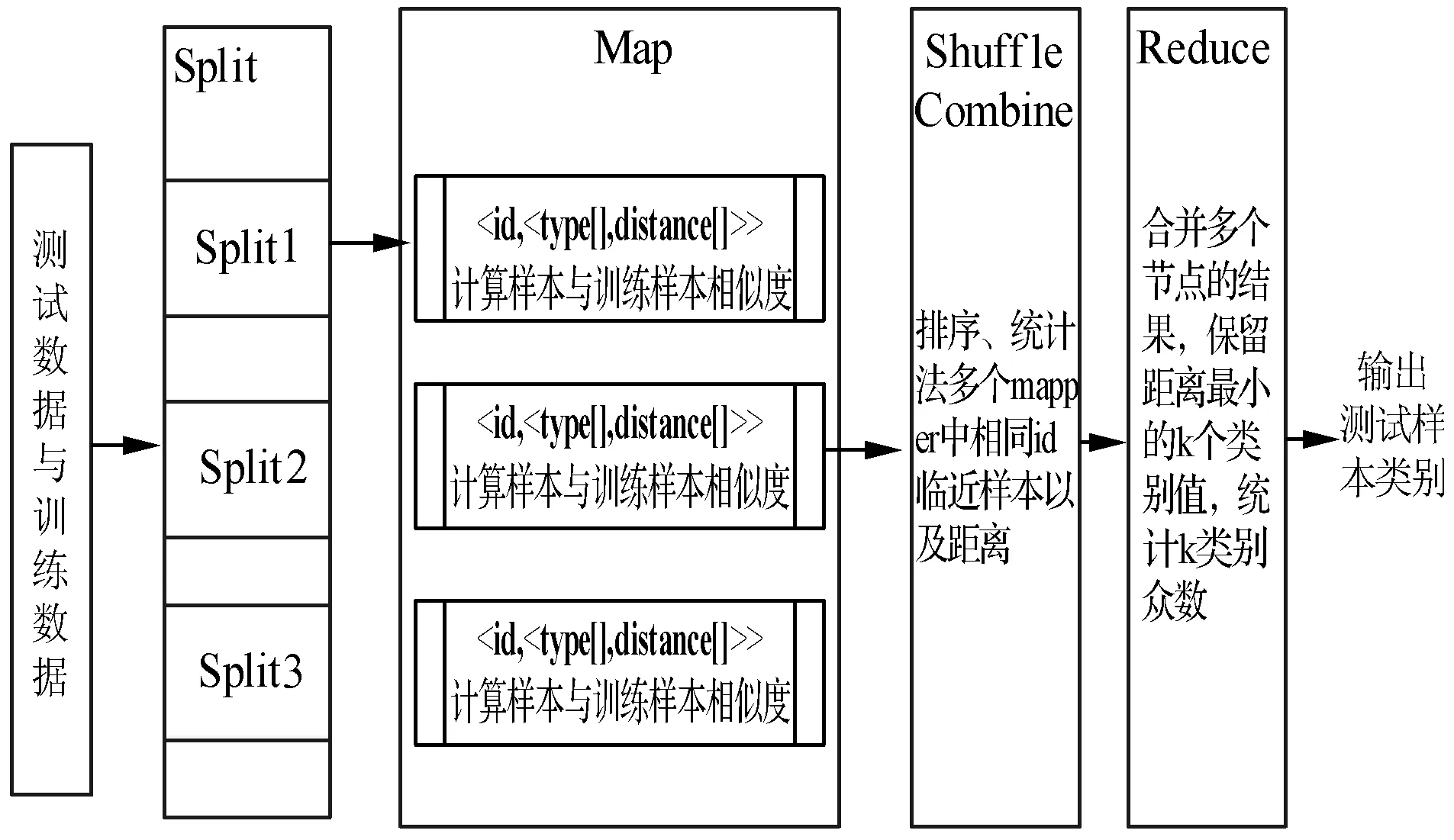
图2 KNN算法Mapreduce并行化原理
4 基于Hadoop的中医症状群分类应用
本文选择中医哮喘病病案[10]作为研究对象,所使用的证型及对应的症状群是根据历史病案数据经关联分析算法及名医总结提取而来,主要证型有寒哮证、热哮证、肾虚热哮证、肾虚寒哮证、肺脾气虚证五类证型。证型及其对应的症状群如表1所示。
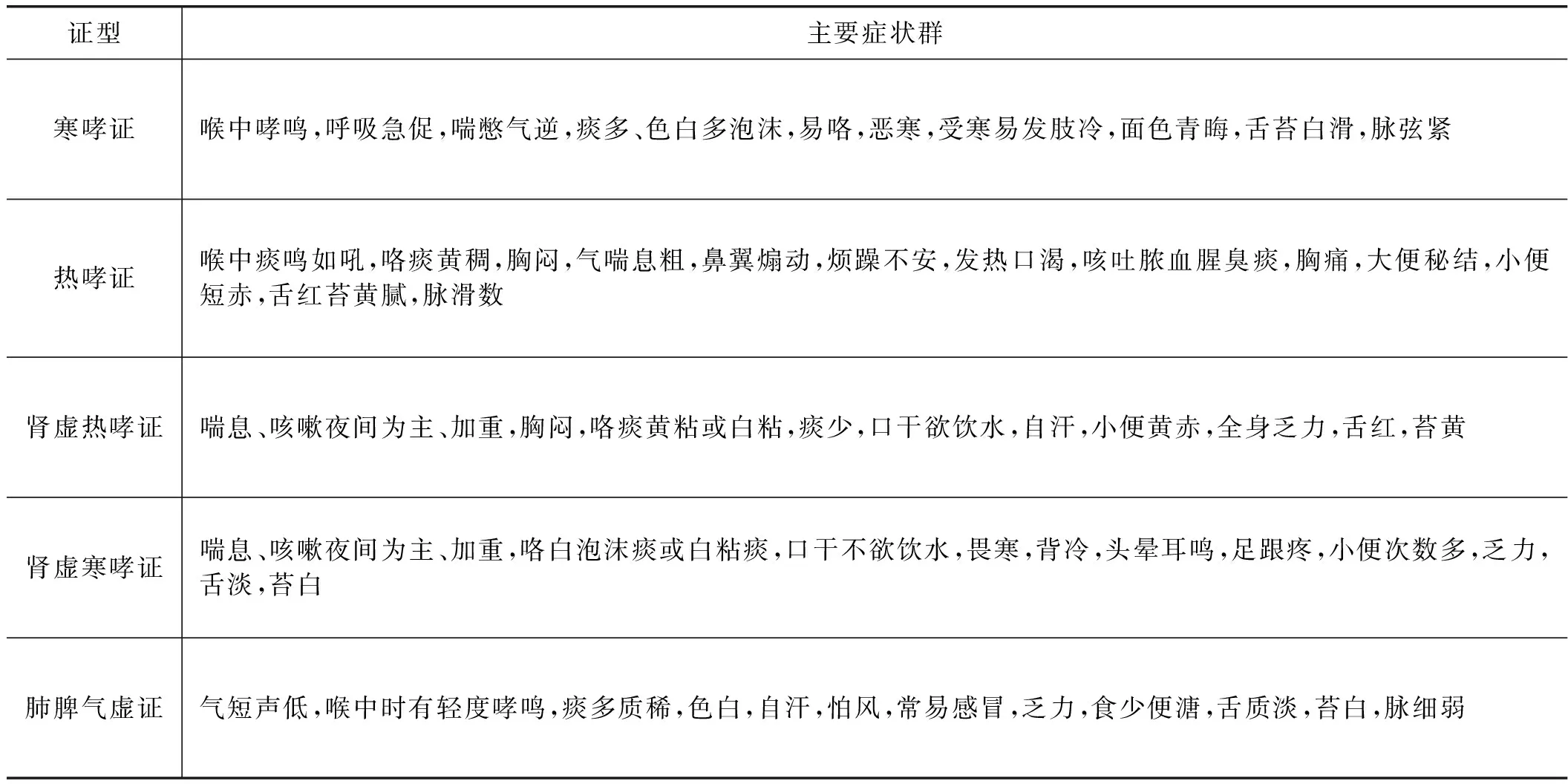
表1 不同证型及对应症状群
由于中医病案的特性,症状描述客观度不强,因此在处理样本数据时首先将症状进行数据量化[11]。本文选取“咳嗽”、“呼吸”、“咯痰”、“胸闷”、“喘息”、“气急”、“哮鸣音”、“舌质”、“苔色”、“厚薄”、“舌滑腻”、“脉位”、“流畅度”、“紫绀”、“小便”、“口干”,以及“寒热”17个症状属性进行表述,并对应“风哮证”、“热哮证”、“寒哮证”、“肾虚寒哮证”以及“肾虚热哮证”5个证型。量化准则为:1) 若病案中不涉及对应的症状,则该症状默认为“正常”或“无”;2) 涉及该症状而无描述轻重时默认为“中”。症状所对应的中医描述及其量化取值,如表2所示。
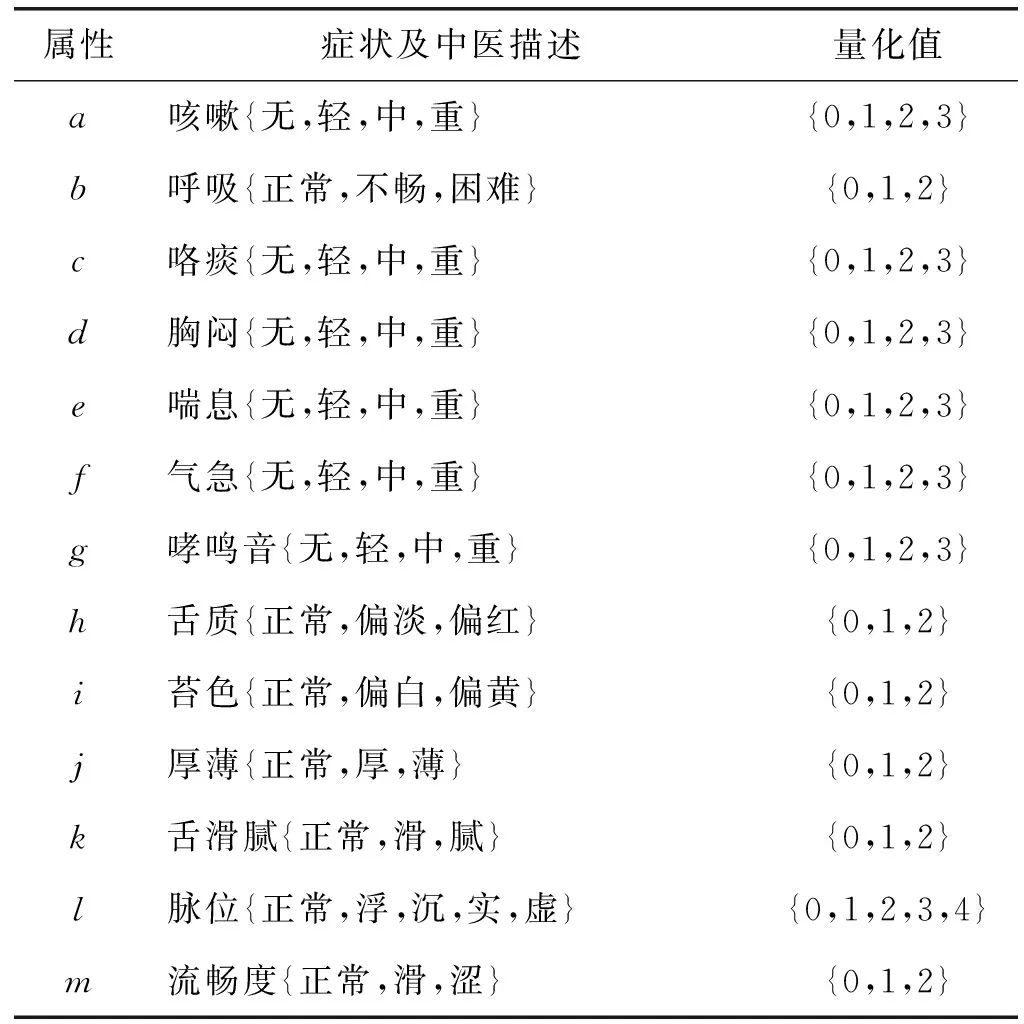
表2 症状量化表

续表2
本文将KNN算法基于Hadoop平台应用于中医哮喘病症状群的分类预测中。所采用的训练数据集是根据10 662例哮喘病中医病案整理而来。详细证型数据如表3所示。

表3 样本数据统计
部分量化的病案数据如图3所示。

图3 部分病案数据
KNN算法是一种基于懒操作的算法,因此只有在输入测试数据进行预测计算时,才会处理训练数据。例输入量化测试样本:[1,2,2,0,2,1,3,0,1,0,1,1,0,0,0,0,0],输出预测种类为W。即对应中医症状群:微咳痰多、呼吸急促、喘憋气逆、喉中哮鸣如水击声、易咯、面色青晦、舌苔白滑、脉弦浮紧。输出预测证型为:寒哮证。结合证型中的总结的症状表现,可以确定其判断正确。为验证MapReduce编程模型的性能,选取病案中的一半作为测试用例,即5 331条作为预测病案。则KNN算法在Hadoop平台运行5 331次,所得准确率为98.12%,其建模耗时相比于单一传统分类算法以及集成学习算法均有较大提升。
5 结 语
本文将KNN分类算法布局到Hadoop平台,依据MapReduce编程模型实现分布计算,从而在保证分类准确的前提下较大提高了分类建模时间。该平台不仅可以满足大数据量的分类计算,而且改善建模时间与数据量成正比的困境。通过中医症状群分类应用,验证了KNN分类算法在Hadoop平台的可行性,为后续应用于更大数据量法分类预测奠定了基础。
猜你喜欢
基层中医药(2022年6期)2022-10-24
江西中医药大学学报(2022年2期)2022-04-27
首都食品与医药(2020年13期)2020-12-25
电脑爱好者(2020年18期)2020-09-26
中西医结合心血管病杂志(电子版)(2020年5期)2020-05-16
科技与创新(2019年13期)2019-11-29
电脑爱好者(2017年9期)2017-06-01
云南中医中药杂志(2014年11期)2014-12-31
办公室业务(2014年10期)2014-02-27
网络与信息(2009年9期)2009-10-30
