
Logistic回归会计舞弊识别模型与会计舞弊指数比较研究
2018-07-23 12:00:26闫世刚
东北师大学报(哲学社会科学版) 2018年4期
李 清,闫世刚
(吉林大学 商学院,吉林 长春 130012)
一、引 言
其实识别会计舞弊最简单最有效的方法就是仔细地查账,但对于普通投资者或利益相关者而言,既无查账的权力也无查账的能力,聘请会计师审计也存在合谋作弊的风险或者不符合成本效益原则,因此构建Logistic回归会计舞弊识别模型或者构建会计舞弊指数进行发布预警,对于防止掉入舞弊公司陷阱、选择正确的投资策略就有着巨大的作用。同样是进行舞弊识别,但是两种方法的原理、构建基础迥异,具有各自的优缺点,本文就上述问题进行了探讨。
本文贡献如下:第一,通过对Logistic回归原理的分析,归纳出了Logistic舞弊识别模型的构建基础、识别准确率低的原因以及其他优缺点。第二,归纳出了会计舞弊指数的构建基础和优缺点。第三,为监管机构或咨询公司开发舞弊识别模型或舞弊指数模型提供了极具价值的经验和方法借鉴,弥补了两种模型比较研究方法论的缺口,将舞弊识别这一复杂问题的研究向前推进了一大步。第四,丰富了舞弊识别研究的文献。
二、文献综述
会计舞弊识别研究主要集中在以下几方面:(1)舞弊动因的三角形理论。该理论认为舞弊的动因来自于压力、机会和借口[1]15-51。具体到我国资本市场,舞弊动因主要包括:欺诈上市、财务困境、退市压力、配股、偷税、虚构利润牟取最大化个人报酬等。(2)舞弊识别指标体系的构建。途径主要有问卷调查[2]323-333[3]54-53、财务报告分析[4]4-9、通过舞弊动因理论选择舞弊动因的替代变量作为指标体系[5]53-81[6]91-96、抑或是努力穷尽各种特征变量通过数据挖掘模型筛选出显著的财务或公司治理指标[7]38-46[8]351-356[9]440-451。但尚无公认统一有效的指标体系。(3)舞弊识别模型构建。主要有Logistic回归[10]179-191[11]75-80[12]84-90、人工神经网络[13]169-184、决策树和贝叶斯信念网络[14]995-1003、案例推理[15]84-89等。普遍存在的问题是:建模样本少,没有使用大样本来验证准确率。(4)舞弊指数构建。李清等[16]36-44使用制造业样本数据和30个财务指标探讨了会计舞弊指数的构建方法。(5)舞弊防范治理。Treadway Committee[17]34认为应通过高层管理理念、控制活动、监督审计来进行舞弊的防范治理。
综上可见,Logistic舞弊识别模型与会计舞弊指数比较研究尚属空白,各自的构建基础、优缺点尚有待探讨。
三、Logistic回归会计舞弊识别模型的原理、构建基础和优缺点
(一)Logistic回归原理
Logistic回归使用Sigmoid函数f(x)=1/(1+e-x),采用最大似然估计法进行模型参数估计[18]6-17。函数值在0-1之间变化如同舞弊发生的概率值。

图1 Sigmoid函数
设舞弊公司用1表示、非舞弊公司用0表示,从总体中随机抽取n个样本公司,观测值标注为y1,…,yn,即取值为1或0。设pi=P(yi=1|xi1,xi2,…,xik)是给定k个自变量xi1,xi2,…,xik的条件下第i个公司发生舞弊(yi=1)的条件概率,于是,Logistic模型将有下列形式:
pi=P(yi=1|xi1,xi2,…,xik)
i=1,2,…,n
(1)
等价于
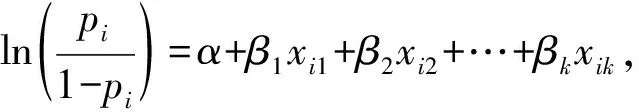
i=1,2,…,n
(2)
式中α,β1,β2,…,βk是k+1个待估计的回归系数,n为样本公司数。
而在同样条件下即给定k个自变量xi1,xi2,…,xik的条件下第i个公司为非舞弊公司(yi=0)的条件概率为P(yi=0|xi1,xi2,…,xik)=1-pi。因此,得到一个观测值的概率为:

(3)
(3)式称为0—1分布。因为n次观测相互独立,所以联合概率即似然函数为n个概率的乘积:
(4)
最大似然估计就是只求出一组系数α和βj(j=1,2,…,k),而使得n个样本其各自的自变量xi1,xi2,…,xik与系数的乘积和恰好与其观测值yi=1或0对应上(如表1所示)同时成立的概率最大,这个过程是通过对似然函数求偏导数实现的,为了简化计算通常是对似然函数的对数求偏导数,因为二者是等价的,ln[L(α,βj)]是L(α,βj)的单调函数,使ln[L(α,βj)]取得最大值的α和βj同样使L(α,βj)取得最大值。ln[L(α,βj)]分别对α和βj求偏导数并令它们等于0,得到似然方程为:
(5)
(6)
解这k+1个联立方程,就能求得系数α和β1,β2,…,βk的值,解方程是通过计算数学专业研究的数值计算方法例如牛顿-拉夫森迭代方法并通过计算机迭代实现的。
最后,通过公式(1)计算出公司舞弊的概率,确定最佳的概率分割值如0.5,当pi>0.5时判为舞弊公司,pi≤0.5时判为非舞弊公司。当舞弊和非舞弊公司样本数为1:1时,通常概率分割值取0.5;如果样本数不是1∶1,则分割值可以通过围绕0.5上下变动试算确定,以便使得舞弊和非舞弊识别总准确率更高、同时舞弊识别准确率和非舞弊识别准确率又不至于差得太多。调整概率分割值不影响系数。
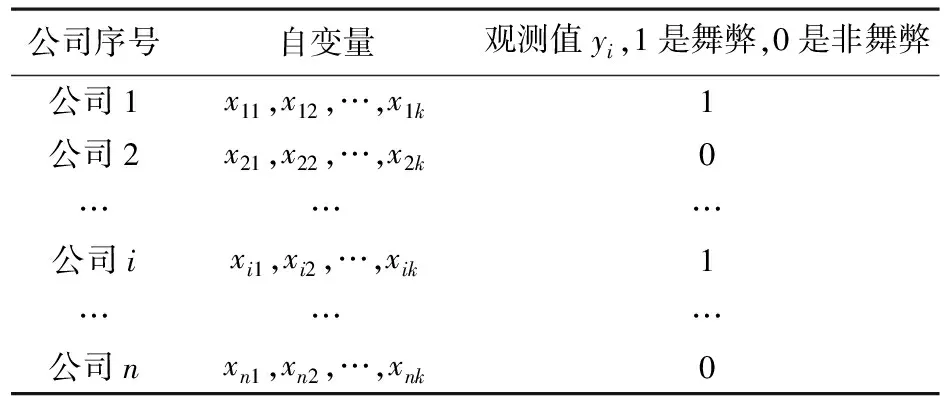
表1 自变量与观测值对应表
(二)Logistic舞弊识别模型的构建基础
从Logistic模型系数求解过程可以看出,0和1必须是确定的,即模型构建的基础是:舞弊和非舞弊公司都是确定的,是典型的0和1二分类问题。舞弊公司受到证监会处罚是确定的,但非舞弊公司由于舞弊的隐匿性或者几年后才被发现甚至永远未被发现而难以确定,一旦无法严格区分舞弊与否,则模型构建的基础将不存在。这就是目前已有的Logistic模型存在的最大问题。
(三)Logistic舞弊识别模型的优点
(1)对样本分布无要求。尽管样本服从多元正态分布能够提高模型稳定性和功效。
(2)对自变量类型无要求。自变量可以是虚拟变量、连续变量或者是二者乘积的交互变量。
(3)易用性。模型结构简单,易使用。
(4)易交叉验证。容易使用留一法、保持方法、K折交叉验证等方法进行模型的交叉验证以评估模型的准确率。
(5)用途广。除了舞弊与非舞弊的分类识别外,还可以进行舞弊与自变量的相关性研究。
(6)成本低。由于统计软件的普及应用使得建模成本低。
(7)普及性。Logistic回归模型是构建会计舞弊识别使用最多最普及的模型。
(四)Logistic舞弊识别模型的缺点
(1)非舞弊公司不确定。舞弊和非舞弊公司必须是确定的,而实际上若非仔细地查账则建模时所选的非舞弊公司未必就没有舞弊行为。
(2)舞弊识别指标选择困难。从已有的文献看,大多是努力穷尽各种可能的舞弊特征指标,然后通过数据挖掘方法筛选出显著的财务或公司治理指标,用以探测高估资产和虚增收入、低估负债和费用等形式的舞弊。例如,普遍选取股权结构、董事会结构、财务困境、负债率、周转率、增长率、公司规模,以及与现金、应收账款、存货等相关的其他指标,首先对指标进行均值差异检验,筛选出差异显著的指标,然后再使用向前逐步选择或向后逐步剔除方法,筛选出显著的指标组合。由于不同的研究者建模时使用的样本公司不同,不同的样本公司隐含的舞弊手段可能不同,经常会出现同一个指标在A模型中与舞弊显著相关,但在B模型中却不显著的情况,指标的显著只对有限样本有效,因此目前尚无公认统一有效包治百病的指标体系。
(3)舞弊点难以判断。由于是根据多个指标的加权和导致的概率超过分割值来判为舞弊,是指标的组合与舞弊发生概率的对应关系,因此不能直观地看出是与哪个指标或与哪几个指标相关的舞弊发生。另外,如果选用的是资产负债率(总负债/总资产)、资产收益率(净利润/总资产)这样与舞弊手段无直接关联的指标,情况就更糟了,因为最多只能说明负债越多或者利润越少公司舞弊的概率越大,具体进行了怎样的舞弊不得而知。
(4)识别准确率偏低。一是因为建模时不能穷尽样本和指标,建立的模型只能识别与自变量xi1,xi2,…,xik相关的舞弊,由于模型中不含有其他指标,因此与其他指标相关的舞弊难以识别,也就是说企业有几百个明细会计科目都存在舞弊风险,但模型只能识别出部分科目的舞弊。二是因为单个指标的值较小可能意味着没有这种舞弊发生,但是多个小的指标值与系数的乘积和就可能导致舞弊概率超过分割值,从而导致误判为舞弊。三是因为10万元的舞弊可能被识别出来,而几个1万元的舞弊累加后由于舞弊概率没有超过分割值就识别不出来。四是过度拟合样本泛化能力差,如果迭代次数控制不好可能导致模型过度拟合样本,对新的公司进行舞弊识别时反而不准。
(5)高估识别准确率。大多数模型使用舞弊和非舞弊1:1配对样本建模,而不是真实情况的比例配对,高估了识别准确率。目前已有的Logistic模型给出的较高识别准确率因没有大样本验证,可信性大打折扣,如果Logistic模型真的达到了90%—95%这样很高的准确率,那么舞弊识别的老大难问题不就解决了吗?
(6)分割点选择困难。概率分割点选取不同时造成舞弊识别率和非舞弊识别率上下摇摆,高低难以均衡,难以抉择。
(7)多重共线性难以解决。如果一个自变量能够用其他自变量进行线性解释,即用一个自变量做因变量、用其余的自变量做自变量进行线性回归,如果拟合优度R2较大,就说明存在多重共线性。Logistic回归对多重共线性敏感,自变量之间的多重共线性将导致回归系数的标准误的膨胀,从而导致自变量显著性检验的Wald统计量变小、显著性水平Sig值变大,变量的显著性下降甚至不显著,或是变量系数的正负号的改变,以至于难以解释自变量与因变量的相关性。由于每个会计科目都可能舞弊,因此理论上模型应该包含更多的自变量,但矛盾的是自变量越多,多重共线性就会越严重,解决多重共线性的办法通常包括:删除变量,用主成分合成新的变量,对于交叉变量进行中心化处理,增加样本等,而这些方法往往由于恰恰是理论上需要的变量不能删除、合成的新变量难以解释其会计涵义、舞弊样本有限等原因难以实现。
(8)需要关注样本量。Logistic模型应关注样本量,当样本量小于100时回归结果风险较大,大于500时回归结果比较可靠。目前普遍存在的问题恰恰是:建模样本少,通常只有几十个舞弊样本,以及几十个配对样本。
(9)需要判定模型结构。需要关注也许logit并不一定就是自变量的线性组合还可能是非线性组合函数。
四、会计舞弊指数构建方法、构建基础和优缺点
(一)会计舞弊指数构建方法
会计舞弊指数,是指根据会计舞弊手段选择舞弊指标,根据每个指标值偏离阈值的程度打分,累加后作为舞弊指数。
1.舞弊指标体系构建
参照文献以及根据舞弊手段自行设计,共得到30个舞弊识别指标[16]36-44,包括应收账款周转指数、存货周转指数等。由于舞弊手段多是直接粉饰会计科目和账表数字,从而带来财务指标的异常变动,故只选择了财务指标作为舞弊指标以便能更为灵敏地识别出舞弊。
2.舞弊指标阈值的确定
阈值是判别会计舞弊与否的门槛,由于30个指标均为正向指标、数值越大舞弊程度越高,因此有一个指标值超过阈值就判为舞弊。采用多数原则法确定阈值[19]43-45,该方法假设多数公司(如75%)在该指标上没有舞弊,即把各个公司按该指标值降序排列,将前25%的公司视为有舞弊发生,其余视为没有舞弊发生,第25%那个公司的值定为阈值。阈值还有其他计算方法:最小值+(最大值-最小值)×0.75,以上均称为0.75法则,也可以使用0.618黄金分割法则。
为了研究不同的阈值确定比例对公司指数排序的影响,分别计算了四种方案进行对比探讨,即分别将前10%、25%、38.2%、50%的公司视为有舞弊发生,如表2所示。例如将前25%的公司视为舞弊时,即将28(公司总数)×25%=7家公司视为舞弊公司,7家公司再分成三等份分别赋给3分、2分、1分,其余公司赋0分,第7家公司的值1.203 240即为应收账款周转指数的阈值。

表2 四种计算方案阈值的确定和赋值方法
3.会计舞弊指数构建
(1)样本选取。随机选取了C40仪器仪表制造业公司作为研究对象,共计28家企业,进行2016年的阈值和舞弊指数计算。
(2)舞弊指数构建和预警。将每个公司的30个指标得分累加,即得到了该公司的会计舞弊指数,最高为94分,0分表示没有舞弊发生,也就是说尽管舞弊指数的构建基础是假设每个公司都有舞弊的可能性,但计算的结果是许多公司舞弊指数为0并没有舞弊发生,说明了指数计算方法的科学性,不存在“有罪推定”的逻辑起点上的缺陷。将各个公司指数排序发布即可进行预警。如表3所示共计算了四种方案进行排序对比,即将前10%、25%、38.2%、50%的公司设为舞弊公司所分别得到的指数,其中“吉艾科技”舞弊指数最高。
(3)指数的Spearman秩相关检验。将四种计算方案所得指数进行等级相关分析,秩相关系数计算公式为[20]121-123:
(7)


表3 四种计算方案得到的会计舞弊指数排序对比
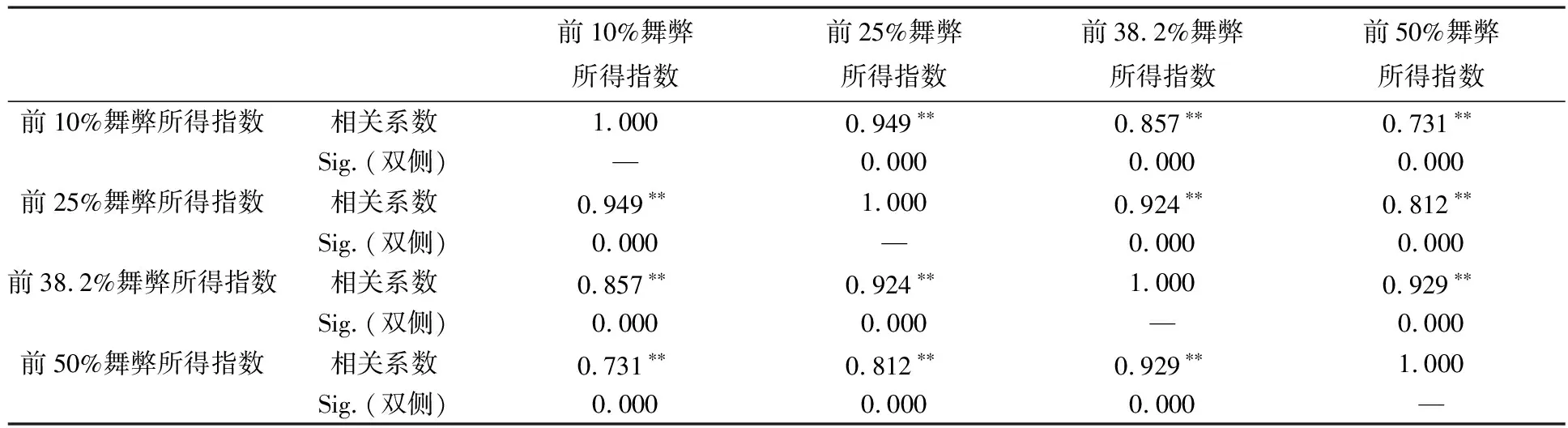
表4 指数Spearman秩相关系数
注:**在1%的水平上显著相关。
(二)会计舞弊指数的构建基础
会计舞弊指数的构建基础是:假设每个公司都有舞弊的可能性,无须事先知道公司舞弊与否的更多信息。当非舞弊公司难以判定时,Logistic模型的构建基础将不存在,此时更适合于构建会计舞弊指数。
(三)会计舞弊指数的优点
(1)事先无须知道更多信息。构建舞弊指数时,事先无须知道公司舞弊与否的信息,因为每个公司在压力、机会和借口面前均存在舞弊风险,避免了非舞弊公司难以判断的窘境。
(2)“或”的思想。摒弃了Logistic模型在计算舞弊概率时对指标进行加总的“与”的老思路,而是采用单指标打分“或”的新方法,30个指标中只要有某个指标超过阈值就是舞弊,指数模型更符合客观实际。
(3)舞弊点直观。由于组成舞弊指数的各个指标有明确的含义是探测哪个会计科目舞弊的,又采用的是单指标打分方法,每个指标的得分一目了然,舞弊点和舞弊程度得分便直观地显现出来。进行会计科目舞弊预警、把阈值做成标准值发布都是未来重要的研究内容。
(4)无须关注多重共线性。可能发生舞弊,因此可以选择大量的舞弊识别指标构建指数,用以识别各种手段各个科目的舞弊,而不存在多重共线性问题。
(5)灵敏度高。会计舞弊指数是连续的,克服了只把公司进行舞弊与否的二分类而造成的分类粗、误判多、研究缺乏精细化的缺点,指数具有连续、灵敏、精细化刻画舞弊程度的优点。
(6)直观易用。会计舞弊指数既是舞弊程度、内部控制有效与否的直观反映,也是会计师、投资者、银行规避审计风险、投资风险、信贷风险的简单易用的决策工具。
(7)构建可操作性强。舞弊指标主要包括根据舞弊手段选择的财务指标,这使得舞弊指数构建具有可操作性、模型识别舞弊更灵敏。
(8)挖掘舞弊动因理论层面高。将公司治理或内部控制等指标不作为指数的组成部分,而是作为舞弊三角形理论的具体动因,是舞弊指数大小的影响因素,通过线性回归模型实证检验后可以根据显著的影响因素提出舞弊治理建议,以便站在更高的理论层面上挖掘舞弊产生的动因。
(四)会计舞弊指数的缺点
(1)舞弊指标体系选取困难。当然,Logistic模型同样存在指标选择难的问题。
(2)舞弊指标阈值确定困难。
五、结 论
Logistic模型的构建基础是舞弊和非舞弊公司都是确定的,当非舞弊公司难以判断时,就会造成分类模型的构建基础不复存在。同时,由于舞弊手段多种多样,表现为规律性不强,规律性不强就难以建模,建立的模型也不准确,所以构建会计舞弊指数便是很好的替代。舞弊指数的构建基础是假设每个公司都有舞弊的可能性,而无须事先知道舞弊与否的更多信息。指数具有精细化刻画舞弊程度的优点。
发布舞弊指数排名是对舞弊公司的警示和震慑,有助于提高资本市场的信息披露质量。
猜你喜欢
活力(2021年6期)2021-08-05 07:24:28
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
制造技术与机床(2019年9期)2019-09-10 07:36:54
经济技术协作信息(2018年11期)2019-01-14 03:07:10
西南交通大学学报(2018年6期)2018-12-18 02:22:28
中国交通信息化(2018年5期)2018-08-21 03:37:40
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
