
基于生存簇识别和预测的生存态势感知模型
2018-07-19 07:13:42赵国生邵子豪任孟其
电子科技大学学报 2018年4期
赵国生,邵子豪,王 健,任孟其
(1.哈尔滨师范大学计算机科学与信息工程学院 哈尔滨 150025;2.哈尔滨理工大学计算机科学与技术学院 哈尔滨 150080)
可生存系统是一种高性能的认知逻辑网络,如今已发展为各国各界信息安全领域的核心问题。它可以满足不同应用的各种需求,还可以通过感知系统的内、外部环境变化,实时动态地调整总体的网络系统配置,使其性能达到最优。在可生存系统研究中,对其生存态势的研究是最为关键的。然而,现实中的系统现状是无论如何防御入侵总会发生,无论如何检测,系统总会受到不同程度的破坏,所以系统的失效在所难免。在有限的时间里更好保证系统的良好生存态势并利用当前生存态势预测将来的生存态势,已成为亟待解决的问题。
可生存系统生存态势的研究,由参照文献[1]的定义可知,主要分为对3R(resistance, recognition,recovery)属性的研究。现有大部分文献都将研究的主要精力投入到对生存态势的可恢复性与可抵抗性方面或对可生存进行概括性的研究,如从服务生存性角度定义系统生存性[2]、通过事物与数据的实时特性定义完整性与可用性等生存性指标[3]、针对网络系统可生存性中的故障修复和网络防故障技术来描述RSCN可生存性能[4]以及将可抵抗性概念应用到优化城市中救护车定位中,最大限度地保证病人的安全,提高救护车的救援质量[5]等。但在可识别性方面国内外研究文献数量较少,大部分是基于网络安全状况和云计算环境。文献[6]对云计算中的态势识别进行研究,提出了一种监视运行中的虚拟机的数据中心层的新方法,并在实验中验证了该方法的可行性;文献[7]对云计算环境中的识别技术进行了总结,并对各种入侵检测技术在云环境下的检测能力进行了全面的分析;文献[8]在构建可生存系统认知参考模型中,提出了一种用模糊关系矩阵进行生存属性分类的方法,通过最终实验可判断在可生存系统存在异常攻击时,哪些属性是处于重要主导地位,以此为生存系统的更好设计与实现提供重要参考;文献[9]从生存性的自主识别性入手,提出自主识别单元,侧重研究可识别性检测参数定义、自主识别模式以及阈值可变方式,提出一种可识别性监测机制以此提高自主认知能力和服务承载能力。对可识别性的研究,通常应包含识别当前态势和对可生存系统生存态势在将来一段时间内发展趋势的预测。
综上,本文将事前识别与事后预测相结合,从生存态势的角度研究了可生存系统,提出了一种基于生存簇识别和预测的生存态势感知模型。
1 模型描述
本文模型研究了可生存系统的生存态势,对生存态势数据生成的生存簇进行了事前识别与事后预测。首先,使用改进的Ward方法[10],生成生存簇并进行识别,实现对当前可生存系统生存态势的可识别能力;其次,构建自回归移动平均模型(ARIMA)[11],将态势数据进行预测,并使用分步模糊信息粒化方法[12]对残差数据进行处理,提高预测准确度。最终实现了可生存系统生存态势的感知。
2 生存态势的事前识别
Ward聚类的主要思想:采取正确聚类时,同类间的数据离差平方和会尽可能的小,成功聚类后可将相似服务等级的生存簇聚集在一起。
2.1 生存簇的聚类
在生存态势生存簇的形成中,需将每个态势数据看成一类,每减小一类,选择S增加最小的两类进行合并,直至所有样本归为所需数量的类。已知n个态势数据分成k类总的类内离差平方和计算方法为:
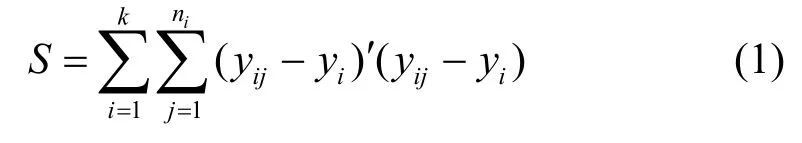
使用Ward聚类后,会生成不同大小的生存簇,由于数据中存在关键性数据与不合理数据,考虑到搜索成本与时间问题,成功识别不合理数据十分重要。因此,对现有Ward聚类方法进行改进,引入消错方法[13]进行决策,实现可生存系统生存态势的事前识别。
2.2 改进的Ward聚类法
消错方法是从错误损失的角度看待问题,通过降低错误的损失,达到更好的数据识别效果。
在多属性决策问题中,假设m个态势数据表示为n个属性为决策矩阵为ai在di下的测量值为xij。识别步骤如下:
1)计算态势数据错误值t:
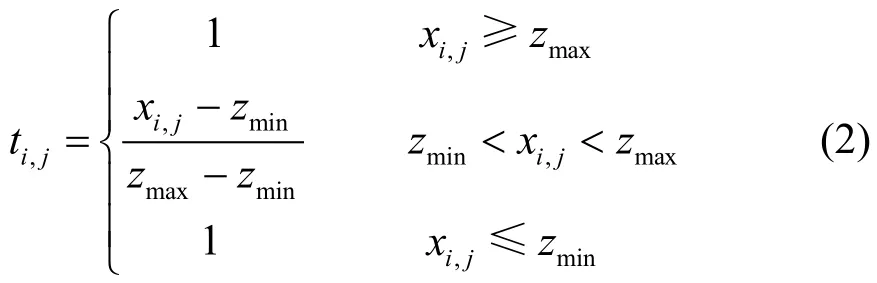
2)计算ai最大错误值并判断合理性,其中时为不合理数据,表示为:

3)计算可行数据错误损失值,表示为:
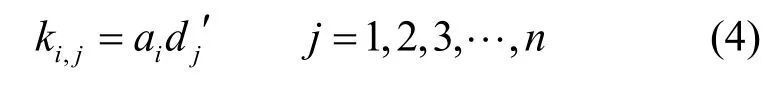
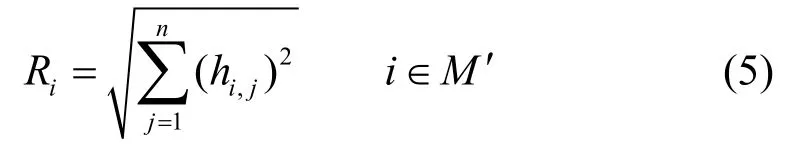
3 生存态势的事后预测
对可生存系统生存态势数据只进行事前识别是不够的,还需建立模型便于对可生存系统生存态势进行预测,由此引入ARIMA模型。
3.1 事后预测模型的选择与构建
ARIMA模型是以数学模型的方式描述预测对象根据时间的发展形成的随机序列。在可用性方面文献[14]认证了该模型的可行性。
3.2 事后预测结果的残差修正
使用模糊信息粒化与SVR模型对ARIMA模型中的残差数据进行处理。模糊信息粒化包括:窗口划分和模糊化。为计算方便本文选用三角型模糊粒子,隶属公式为:
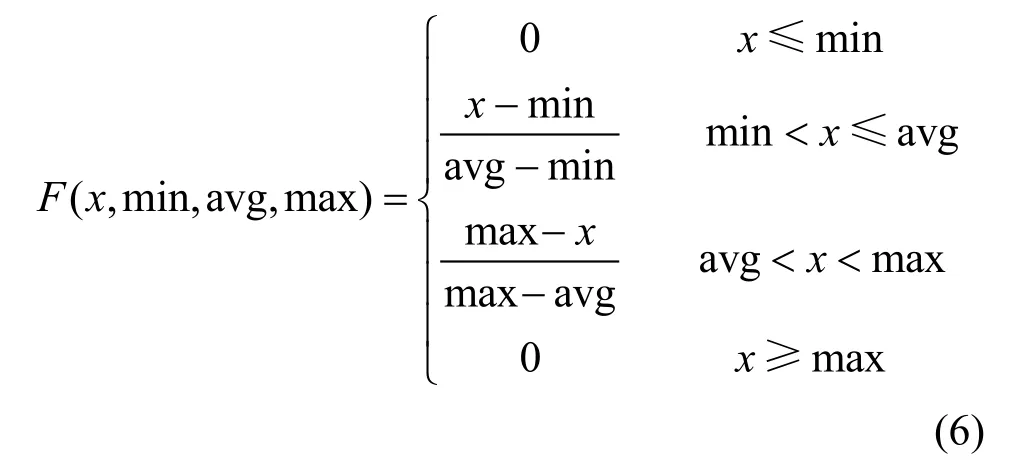
式中,x为输入的时间序列;min、avg、max分别表示相应生存态势数据变化的最小值、平均值、最大值。对于已知训练样本数集在高维特征空间中构造最优决策函数:
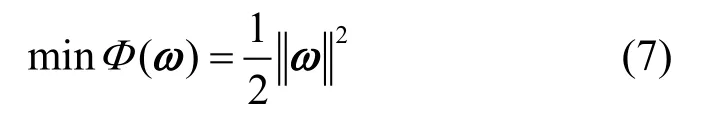
式中,ω为权重矢量。设b为偏差值,它们满足以下约束条件:
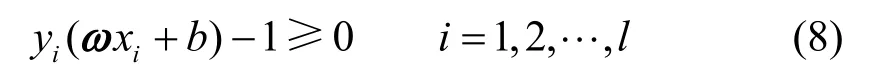
将该方法用于回归问题上,还需引入损失函数来保持重要属性,构建公式为:
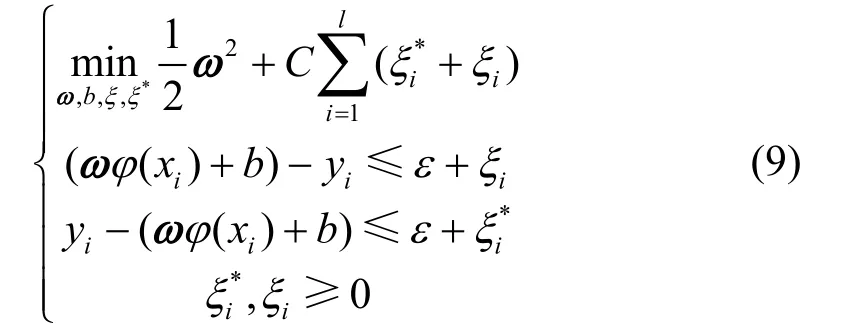
3.3 事后预测的实现步骤
4 仿真实验
4.1 生存态势的事前识别算例
4.1.1 指标选取
对可生存系统生存态势识别指标的选取,本文参考文献[15]建立的指标体系原则,选取了3个主要因素,即完整性、使用性和感知性。这3个因素又分为6个性能指标,分别为数据复用率、检验强度、信道利用率、信道延迟、信道吞吐率和感知率。
4.1.2 Ward方法算例实现
在实验中,假设网络系统服务中提供5种级别的服务A1(最高)、A2、A3、A4、A5(最低),初始数据表如表1所示。
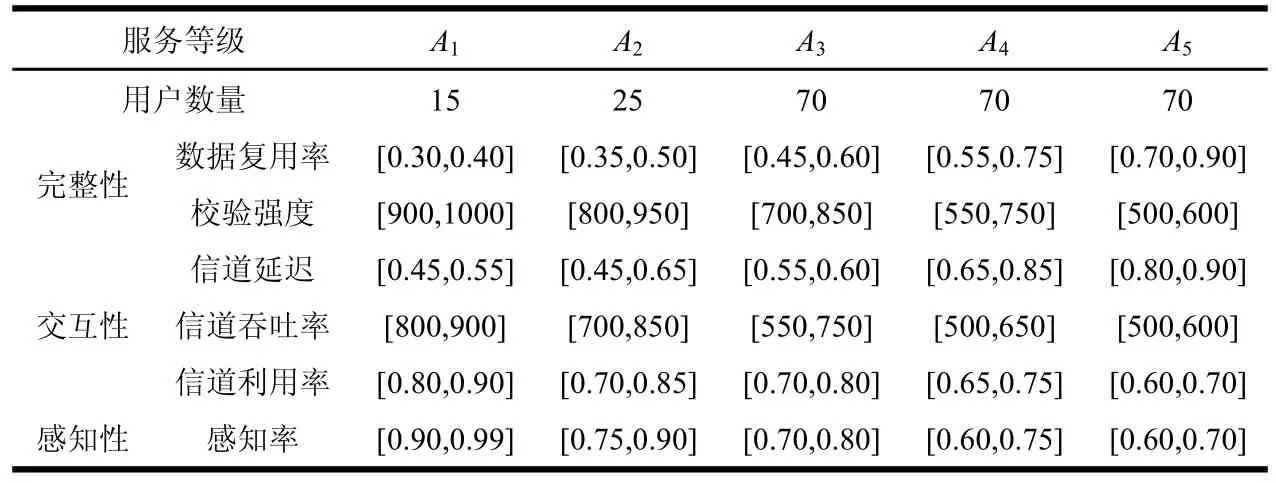
表1 初始数据表
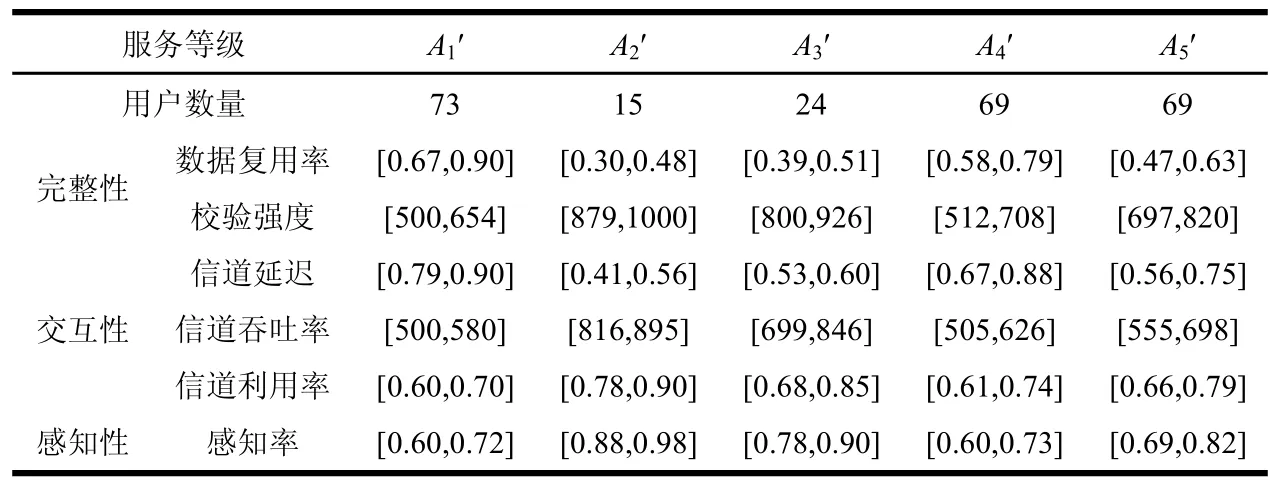
表2 用户聚类
由表1规定当前系统内,不同服务级别的各项生存性能指标会有不同。随机抽取250位正常用户数据,其中A1级别用户15位,A2级别用户25位,A3、A4和A5级别用户各70位。
通过式(1)计算离差平方和并使用SPSS19.0软件进行聚类,将产生的Ward聚类规定簇数量为5类。经统计产生的新服务等级用户数据聚类如表2所示,聚类方法的原理图如图1所示。
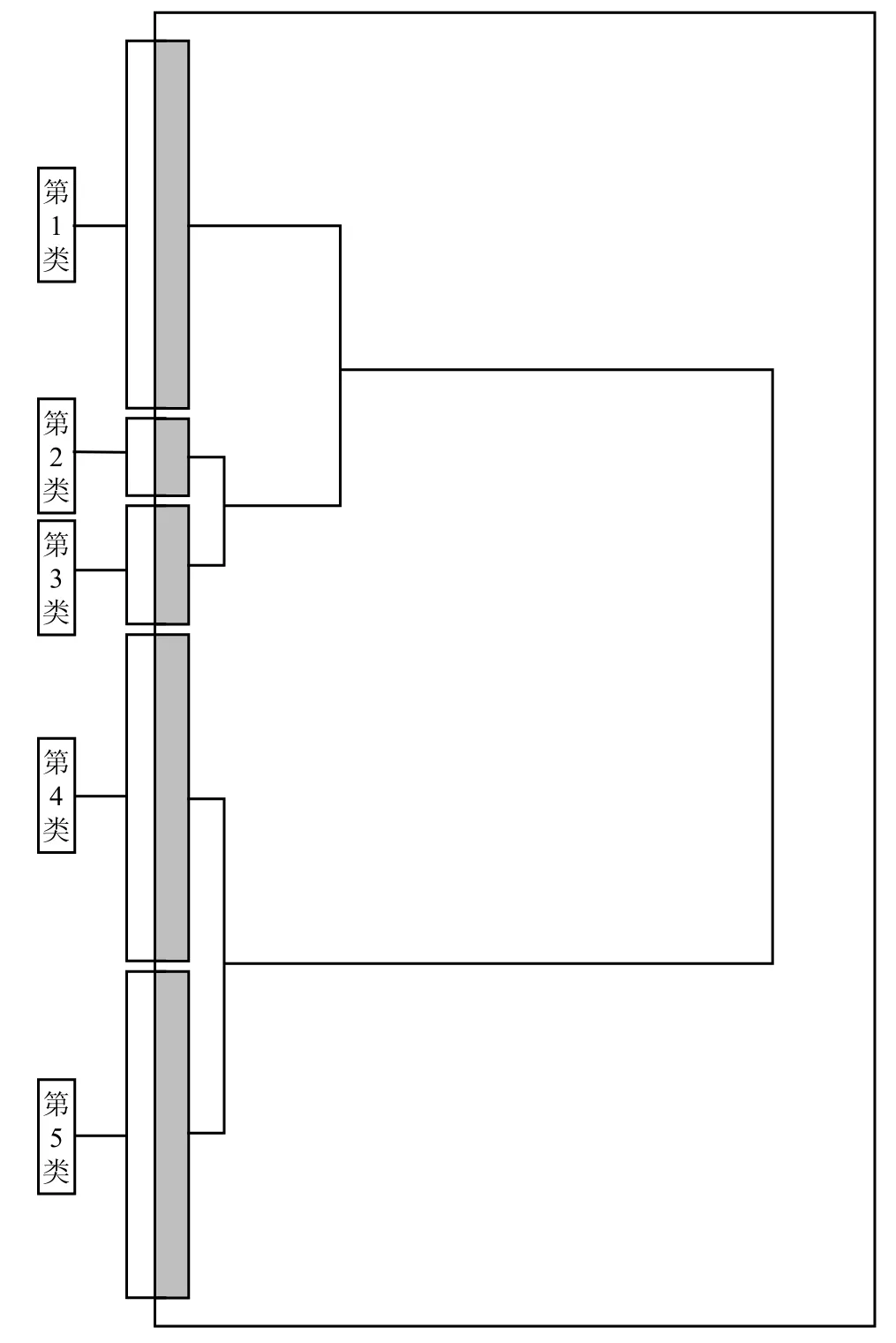
图1 Ward聚类原理图
图1 中表示的聚类种类为5类,通过SPSS19.0软件,将其数据根据特性自动聚类到这5类中。
4.1.3 数据识别
随机抽取6组用户数据,每一级服务范围内抽样数量都为1,并抽取1名非法用户进行计算。判断态势数据可行性并排序,数据如表3所示。表中,QA1、QA2、QA3、QA4、QA5、QA6分别为数据复用率、校验强度、信道吞吐率、信道延迟、信道利用率和感知率。
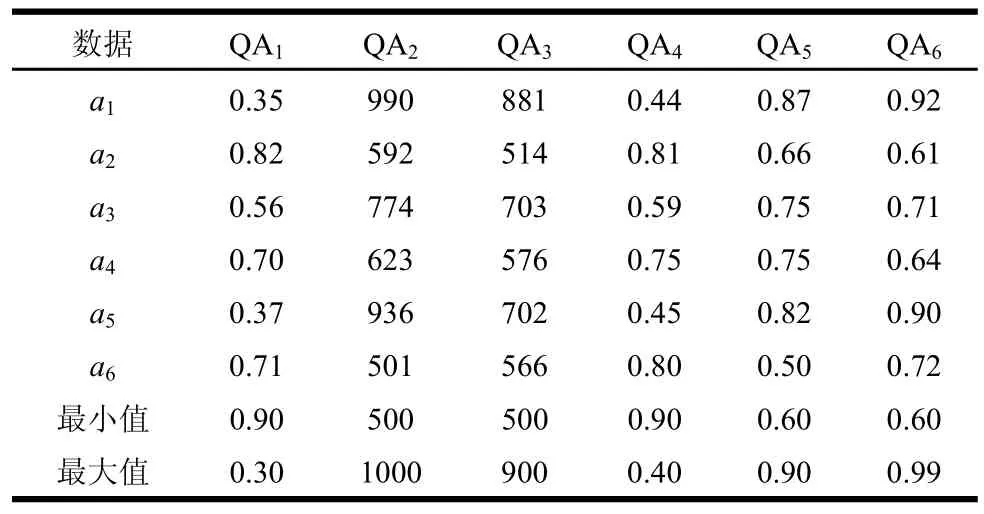
表3 决策矩阵
根据式(2)~式(4)和环比评分(DARE)法求得各数据极限损失值为得出数据a1、a2、a3、a4、为可行数据,a6为错误数据。利用式(5)和文献[16]的方法求得各属性的错误极限损失值和损失序列分别为0.007,0.039}、a2{0.225,0.122,0.116,0.148,0.056,0.214}、a3{0.113,0.068,0.059,0.068,0.035,0.158}、0.019,0.059,0.018,0.019,0.051}。根据式(5)求得离心距为R1=0.048、R2=0.387、R3=0.227、R4=0.329、可知用户数据性能排序为a1、a5、a3、且a6为非法用户。
为进一步说明本方法的可行性,采用两种常见的传统决策方法,即理想点法和加权平均法对这组数据进行排序,排序结果如表4所示。

表4 决策方法对比
综上,结合了消错方法的Ward聚类法,成功将生存态势数据聚类为5种服务等级的生存簇并对不合理数据进行识别。从计算的过程、复杂性与结果看,本文提出的消错决策方法无需计算权重且计算复杂度低;从排序结果看,传统决策方法只能实现数据的排序,缺少验证合理数据的能力,本文通过计算极限损失值成功识别部分错误数据,提高了对数据的准确处理能力及响应时间,排序结果也与传统决策方法基本一致。
4.2 ARIMA模型
4.2.1 ARIMA建模
在高生存性网络服务系统中,系统响应服务次数越多,意味着系统服务生存态势越好。但由于高级别服务用户数量是有限的,其相应的服务次数也是有限的,大部分用户请求服务都集中于中间级别,想要快速、较准确地预测服务生存态势,可通过对A3与A4级别用户请求服务次数进行预测,完成对可生存系统生存态势的事后预测。
现选取用户数据进行分析与预测。计算从1月1日-1月30日这30天服务等级为A3和A4级别的用户请求服务次数,建立模型如图2a所示,采集的数据序列图符合随机性分布,经观察为非平稳时间序列,进行一阶差分后如图2b所示。
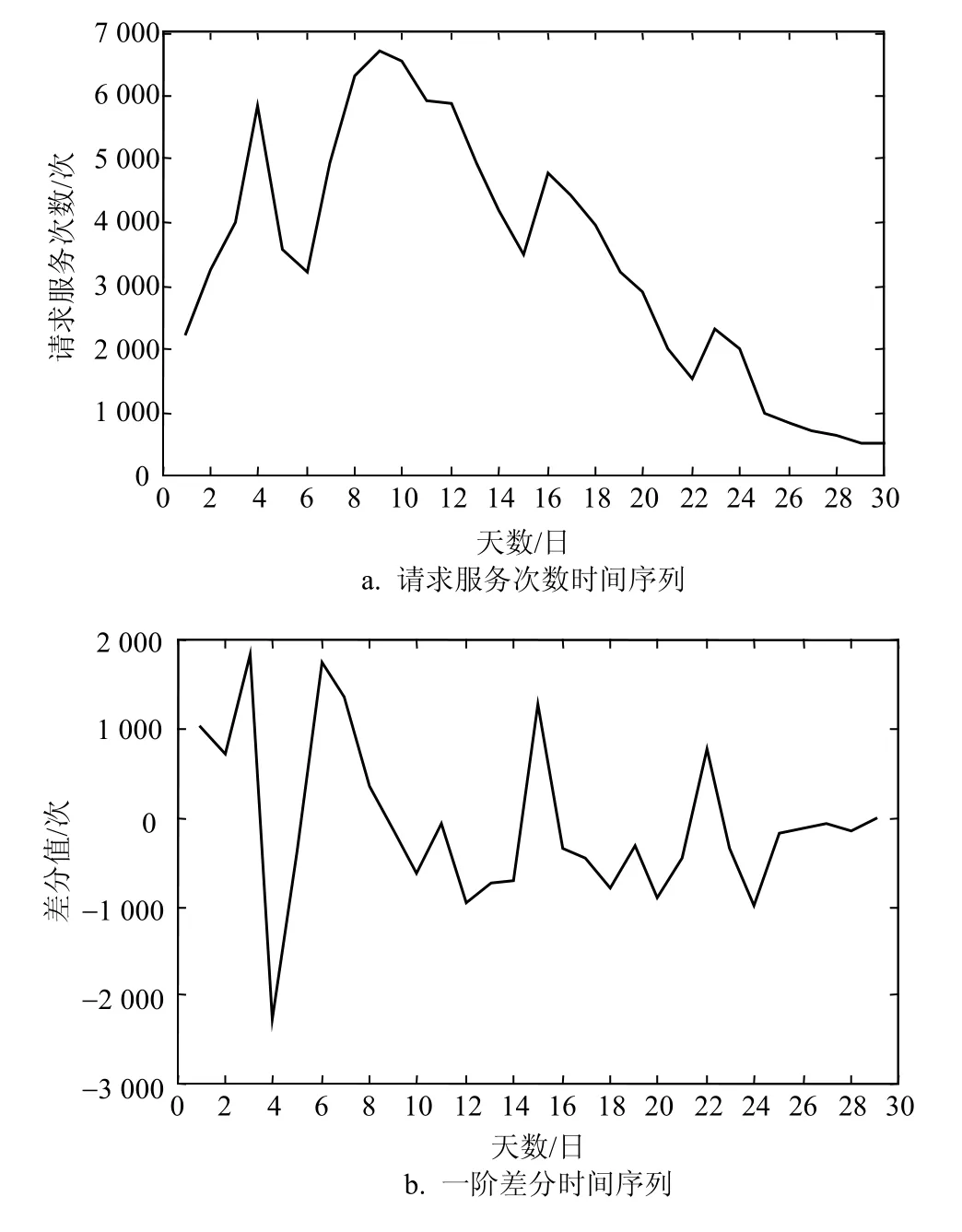
图2 ARIMA模型校验
自相关系数和偏自相关系数如表5所示,规定标签数最大为12。选取ARIMA(0,1,0)为最优预测模型,模型预测结果如图3所示。
图3中,实线表示实际A3与A4级别用户请求服务次数,虚线表示ARIMA(0,1,0)模型预测的用户请求的服务次数,总体上来说模型的预测结果与实际情形实现初步拟合,但存在一定的延迟且精准度有待提升。
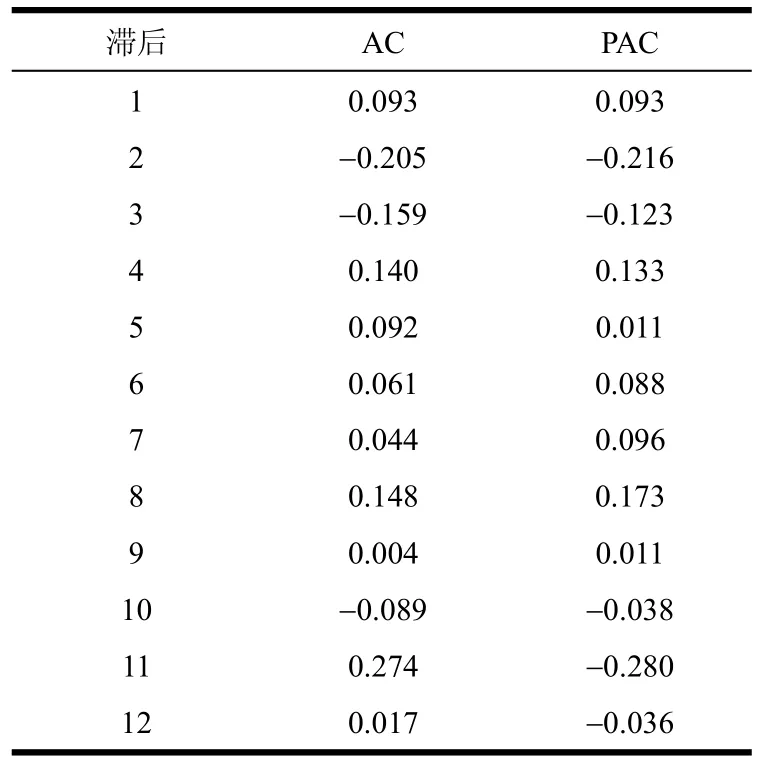
表5 自相关系数和偏自相关系数
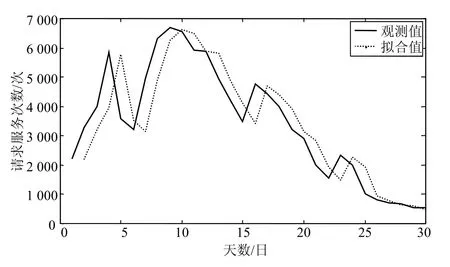
图3 ARIMA(0,1,0)模型预测结果
4.2.2 信息粒化SVR建模
由于ARIMA模型预测数据存在误差,现将1月1日-1月30日30天内产生的30个数据与实际数据之间的误差值作为训练集,以1月31-2月2日作为预测集,每3天为一个信息粒化窗口,数据模糊粒化为Low、Medium、High3个参数,如图4所示。其中Low、Medium和High分别描述的是服务等级为A3和A4级别的用户请求服务次数的最小、平均和最大变化数。
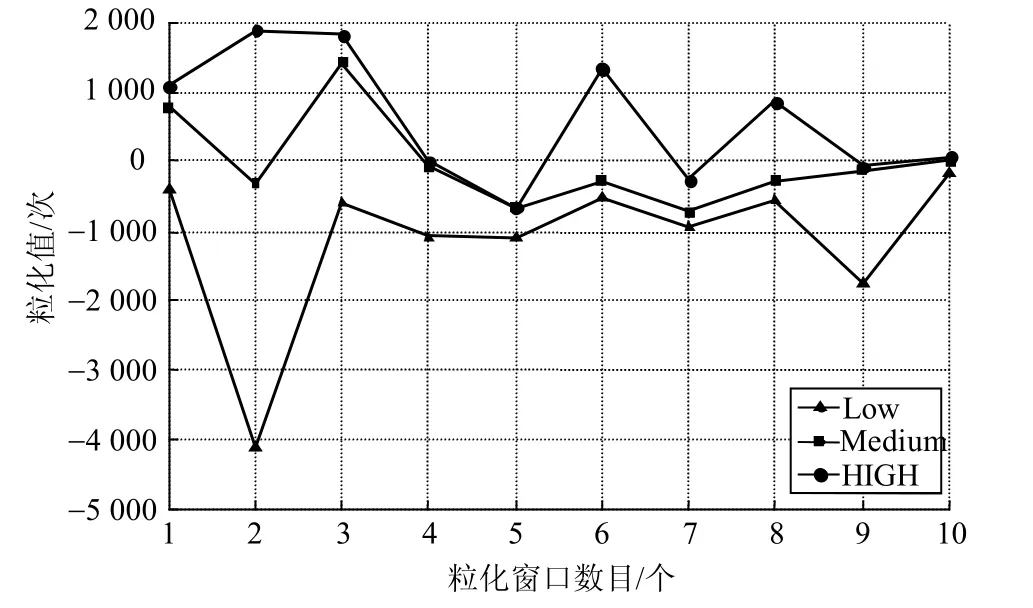
图4 粒化结果
将模糊信息粒子数据集作为输入变量构建SVR模型。对模糊信息粒子及窗口化残差进行预测,数据进行归一化处理,利用GS算法进行参数寻优,分别在Low、Medium、High下获取规范化参数与核参数为Low:c=38.1,g=38.1;Medium:c=32,g=16;High:c=32,g=1,测试集输出结果如图5所示。
由图5可知,SVR模型总体残差预测准确率较高,对于Low参数预测结果较为准确,High参数的预测结果较差。但对于窗口化残差值相差很大时如2、3窗口时,模型中Low、Medium两个参数预测值存在很大误差,主要是因为SVR模型中通过前一个窗口的模糊信息粒子完成对后一窗口数据的预测,所以当用户请求服务次数波动很大时预测准确度会下降。因此,SVR模型对事后残差数据的预测是可行的,但也存在不足。
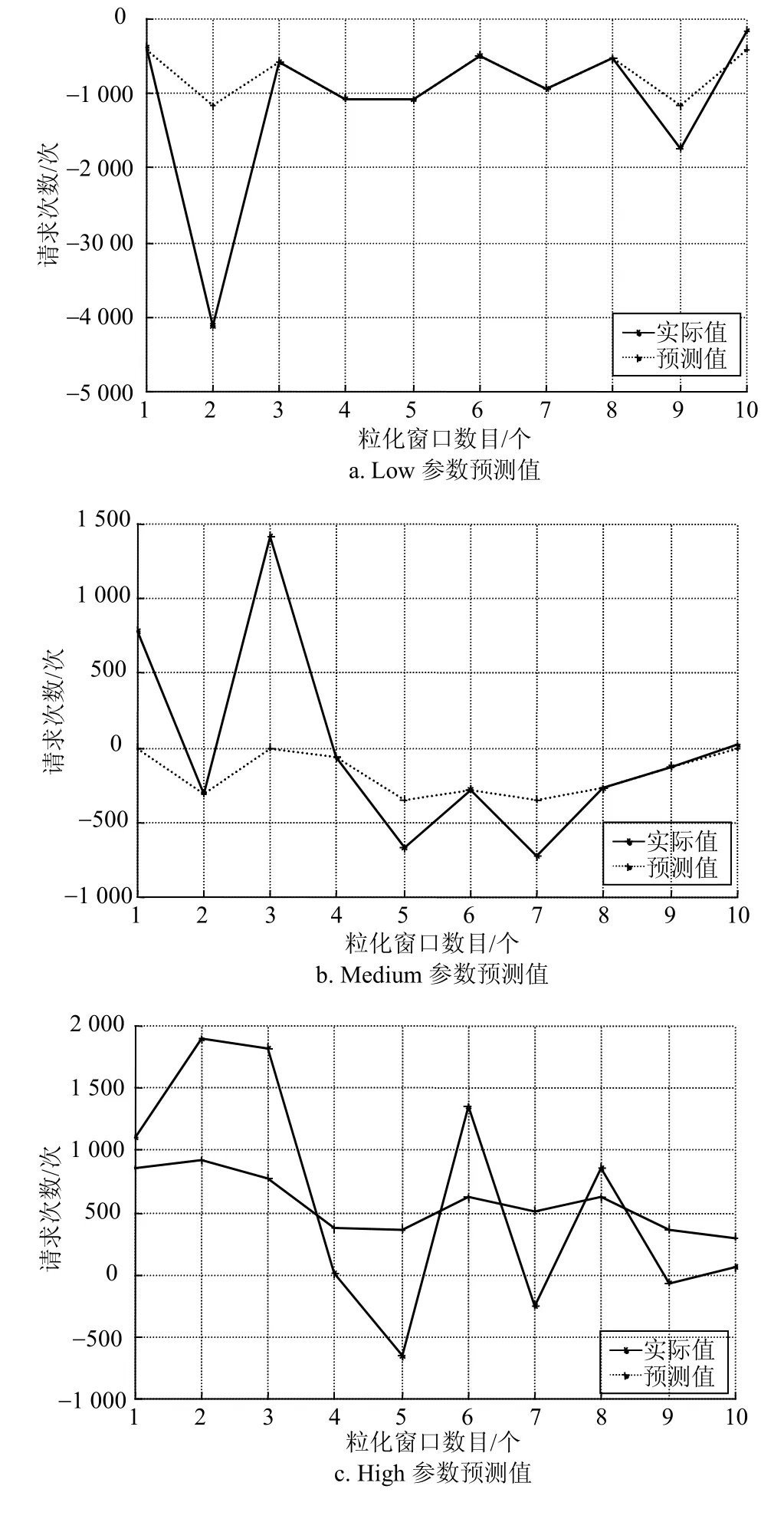
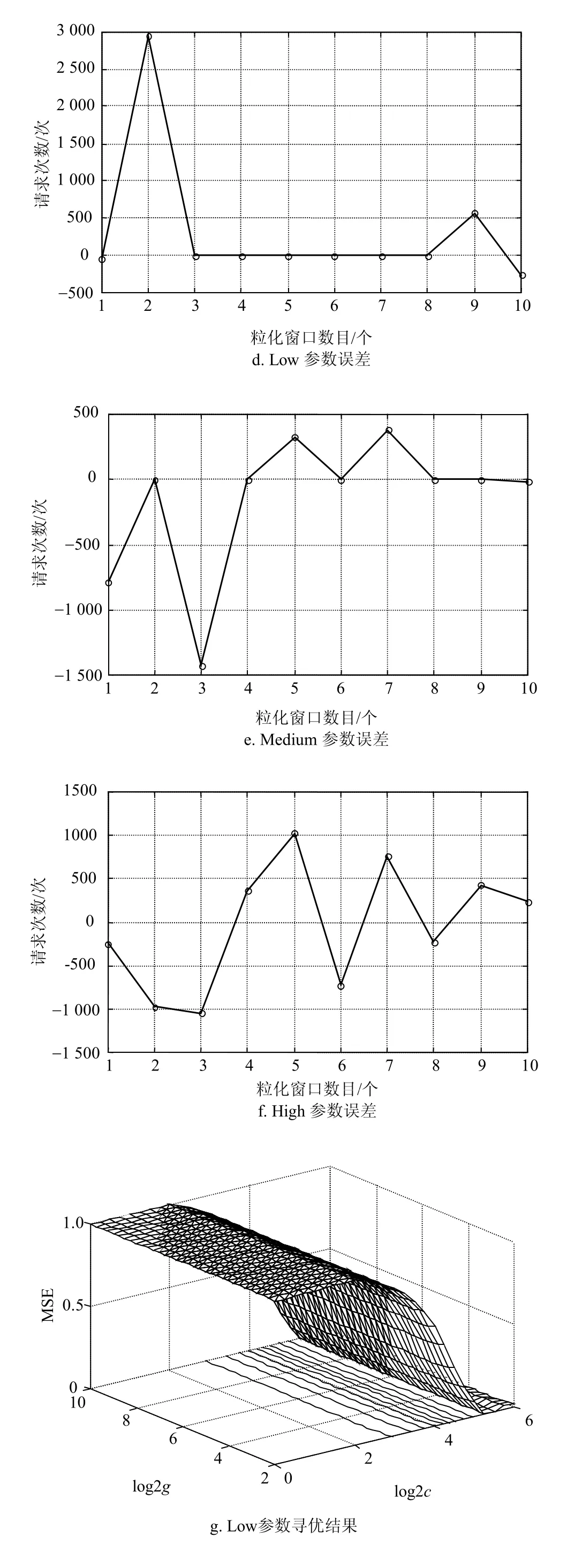
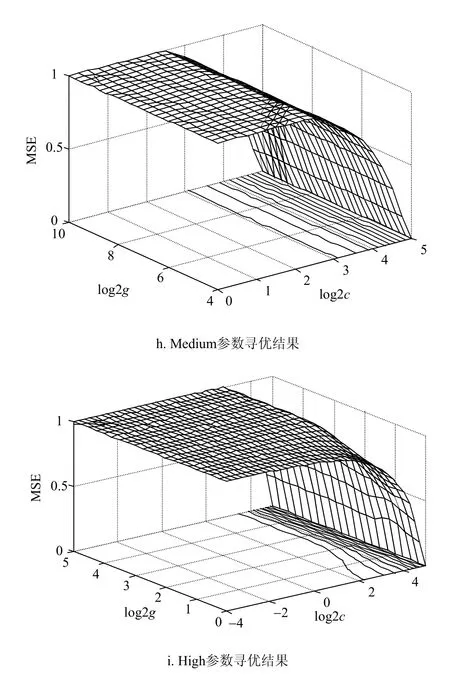
图5 Low、Medium和High参数预测结果、误差和Low、Medium和High参数的网格寻优结果
4.2.3 ARIMA建模和信息粒化SVR组合
将ARIMA模型预测值和SVR残差预测值合并,预测未来3天的用户请求服务次数,如表6所示。
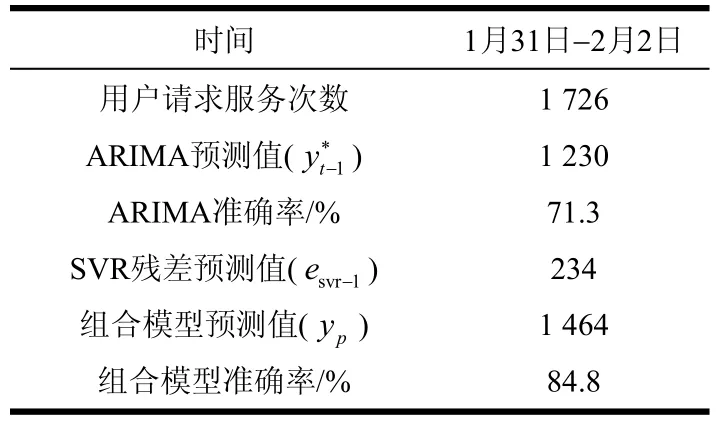
表6 组合模型预测结果
由实验结果可知,ARIMA模型预测1月31日-2月2日服务等级为A3和A4级别的用户请求服务次数分别为469、410、351与实际用户请求服务次数665、574、487有差距,但增减趋势一致,SVR模型对事后预测的残差数据进行修正,残差修正后总体预测准确度提升13.5%,但组合模型的准确率达到84.8%。
综上,ARIMA模型与SVR模型结合可对服务等级为A3和A4级的用户请求服务次数进行预测,通过图2可发现随着时间的推移,在相同时间段内,用户每天的请求服务次数总体呈下降趋势,表明系统的总体服务生存态势在下降,通过该方法,完成对可生存系统生存态势的事后预测。
5 结束语
本文提出一种基于生存簇识别和预测的生存态势感知模型,侧重研究了生存态势数据合法性判断和系统服务生存性的预测等。在仿真实验中对网络系统中服务数据与请求服务次数进行性能仿真,实验结果显示模型可以实现对可生存系统生存态势的事前识别和预测生存态势。但该模型存在相应的不足,首先,事前识别中缺乏对外部攻击的识别,识别真实场景准确率有待提高;其次,事前识别中只识别出合理性数据,但对合理性数据所属级别并不能较好的识别;最后,预测模型的精确度有待提高并存在一定的延迟,尤其是在面对数据波动较大的数据源时,局部精准度表现较差。在后续可生存系统生存态势的自感知的研究中,将会考虑构建一种更好的识别模型和更准确的预测模型。
本文的研究工作得到了哈尔滨市科技创新人才研究专项资金(2016RAQXJ036)的资助,在此表示感谢!
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
商用汽车(2021年4期)2021-10-13 07:16:02
数学物理学报(2020年6期)2021-01-14 01:00:14
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
汽车与安全(2020年1期)2020-05-14 13:27:19
中国外汇(2019年19期)2019-11-26 00:57:36
自动化学报(2019年6期)2019-07-23 01:18:32
中国化肥信息(2019年5期)2019-06-25 00:52:28
中学生数理化·中考版(2017年12期)2017-04-18 12:55:03
