
基于Hadoop环境BP改进算法的脉象识别应用研究
2018-07-12 07:31盛雅兰王珍佘侃侃
中国中医药信息杂志 2018年3期
盛雅兰 王珍 佘侃侃

摘要:目的 分析脉象识别误差大小的影响因素,提高对海量脉诊数据的处理速度,探索减小脉象主观识别误差的方法。方法 运用基于Hadoop环境的MapReduce分布式计算方法改进BP算法,采用改进的BP算法对脉诊样本数据进行自学习,从而减小拟和误差。将中医电子脉诊仪采集的脉诊数据作为神经网络输入层,采用动量-学习率自适应调整快速BP算法对神经网络进行训练。结果 在训练集(75%)768 M共35 890条数据中,单机模式正确预测29 150条,正确率为81.22%;MapRedece并行改进的BP算法模式正确预测35 841条,正确率为99.86%。结论 与传统BP算法相比,基于Hadoop环境的MapReduce分布式计算方法改进的BP算法模型拟合度误差更小,精确度更高。
关键词:Hadoop;MapReduce;BP算法;脉象识别
DOI:10.3969/j.issn.1005-5304.2018.03.023
中图分类号:R2-05;R241.1 文献标识码:A 文章编号:1005-5304(2018)03-0102-05
Abstract: Objective To analyze the factors of errors in the pulse recognition; To improve the speed of processing massive data; To explore the method of reducing the subjective errors in pulse recognition. Methods BP algorithm based on distributed MapReduce in Hadoop environment was optimized. Optimized BP algorithm was used to self-learn pulse-sequence data to reduce fitting errors. The pulse-counting data collected by TCM electronic pulse diagnosis instrument were used as input layer of neural network. Momentum-learning rate adaptive fast BP algorithm was adopted to train neural network. Results In the training set (75%) of 768 M, a total of 35 890 data were collected, and 29 150 items were correctly predicted in stand-alone mode, with the correct rate of 81.22%. MapRedece parallel improved BP algorithm model correctly predicted 35 841 items, with the correct rate of 99.86%. Conclusion Compared with traditional BP algorithm, BP algorithm based on distributed MapReduce in Hadoop environment has smaller fitting errors, with higher accuracy.
Keywords: Hadoop; MapReduce; BP algorithm; pulse recognition
脈诊为中医四诊之一,是辨证论治必不可少的客观依据。传统的诊脉主要通过触觉和压觉,并结合主观判断,故难以形成统一、规范的标准。因此,将中医脉象识别与电子信息技术相结合,对中医脉诊标准化具有重要意义。为提高脉象识别的准确率和可靠性,本研究将基于Hadoop环境优化的BP神经网络算法应用到脉象识别中。
随着信息化社会的飞速发展,有研究价值的数据达到了海量级别,而传统BP神经网络的训练环境是单机串行的处理数据集,在处理海量数据集时有较大局限性,如耗时长、运行内存不足导致训练中途停止等[1]。为解决传统BP神经网络训练方法存在的问题,采用并行方式是较优选择,如新兴的云计算[2]平台Hadoop技术为一项非常适合的技术。本研究在开源云计算平台Hadoop[3]环境的基础上,探索基于算法权值改进的BP神经网络MapReduce[4]并行实现方法,其中包括HDFS的文件处理系统[5-6]并行实现方法及研究提出的结合单样本训练特点的BP神经网络批量训练方法。
1 Hadoop环境下的BP神经网络算法设计
1.1 Hadoop架构
Hadoop是目前应用最广泛的开源分布式云计算技术,Hadoop以HDFS和MapReduce为核心,向用户提供了底层系统透明的分布式基础架构[7]。其中,HDFS的容错性、可靠性极高,允许用户将Hadoop平台部署在低廉的硬件设施上,形成分布式系统,提高读写速度、扩大存储容量。
MapReduce分布式计算框架由一个统筹控制所有节点的主节点(Job Tracker)和分布于子机器上的从节点(Task Tracker)群一并组成。主节点负责对从节点的资源、任务分配以及子节点的生命监控。从节点执行主节点分配的任务,并实时向主节点报告任务执行情况和本身的运行状态。MapReduce作为分布式计算的主要运行框架,旨在将大量的数据计算细分到各从节点上,在计算完成后对数据进行统一的约减操作,得到最终的有效数据。
在MapReduce过程中,Job Tracker将任务分解为多个子任务,分配给Hadoop环境下空闲的机器进行Map过程,Map过程将完成对数据的大部分的处理,并将结果以键值对(key,value)的方式返回。Reduce的工作是将Map运算的结果进行汇总,运行模型见图1。即使使用者无编程经验,仅需将Job Tracker的工作信息配置好,Map函数和Reduce函数会分别完成任务处理及结果收集。
1.2 BP神经网络
BP神经网络是一种典型的多层前向网络,由输入层、隐含层和输出层组成。一个3层的BP神经网络可完成由任意N维到M维的映射[8]。BP神经网络模型为多层感知机结构,其中不仅包含输入和输出节点,而且还有一层或者多层隐层。标准BP神经网络拓扑图见图2。
输入层有M个神经元,即输入矢量为X={X1,X2,…,XM},输入矢量的每个分量分别为归一化的脉象信号特征值,输入层的传递函数选用比例系数为1的线性函数。隐含层有L个神经元,采用(0,1)型Sigmoid函数[9]作为激活函数,节点的输出总被约束在(0,1)取值区间内。输出层有N个神经元,其传递函数选用比例系数为k的线性函数,输出值为Y={Y1,Y2,…,YN}。
由于BP算法模型的误差收敛速度是由快变慢的,最后几乎趋于平稳,极易陷入局部极小值,在误差的收敛时间上呈几何倍数上升。在实际建立模型过程中发现,当误差达到这个极值点时,程序运行的时间性能陷入瓶颈,普通PC端难以承受这种计算量,程序时间消耗过于庞大。
1.3 Hadoop环境下BP算法设计
为解决收敛时误差达到某个极值点所造成的时间消耗过大的问题,本研究采用Hadoop环境下的MapReduce的链式[10]计算模式。Hadoop提供了专门的链式ChainMapper和ChainReducer来处理链式任务,ChainMapper允许一个Map任务中添加多个Map的子任务,ChainReducer可以在Reducer执行之后,在加入多个Map的子任务。其中,ChainReducer专门提供了一个setReducer()方法来设置整个作业唯一的Reducer[11]。
实现BP算法的MapReduce化具体步骤如下:
①数据划分:将存放在HDFS中的数据样本分为训练集和测试集2部分,并将训练集分解成块,分布到DataNode机器上进行MapReduce计算。
②Map处理:Map函数在接收训练集数据块后,根据神经网络的结构生成期望输出及输入变量读入在HDFS上的神经网络权值记录,并通过这些权值构造神经网络,对提取的数据进行训练。神经网络收敛后,获取新的网络权值作为Map的输出。伪代码如下:
Map ()
{
IF第一次map处理THEN
随机初始化权重
使用训练集训练
Else
使用训练集训练
更新权值
}
③数据聚合:在把经过Map处理过的数据传递给Reduce前,MapReduce机制会将每个节点上神经网络的所有权值归为1个权值组,聚合所有节点上的权值组,传入Reduce进行下一步运算。
④Reduce处理:Reduce函数接收到权值组后,使用HDFS中的标准值对其进行输出测试,并对结果进行误差精度分析和排序,选择误差精度最高的1/6置于下一次的MapReduce循环当中。伪代码如下:
Reduce ()
{
使用测试集测试神经网络的误差
while (误差不在规定范围内)
{
取误差较小的1/6组
将权重返回给map过程迭代训练
}
神经网络训练完成
保存计算结果
}
实现BP算法的MapReduce化的流程图见图3。
2 Hadoop环境BP算法脉象识别
2.1 实验环境
采用7台普通台式机,单机配置为:CPU型号Intel? Core? i5-7400;CPU最高频率3.50 GHz;CPU缓存6 Mb;内存8 G,DDR4;硬盘1 TB。Hadoop集群配置为:1台设置为主节点,配置JobTracjerhe和NameNode,其余6台设置为从节点,配置TaskTracker和DataNode。Hadoop集群主要软件的安装版本为JDK1.8,Hadoop2.7.3。
2.2 實验数据
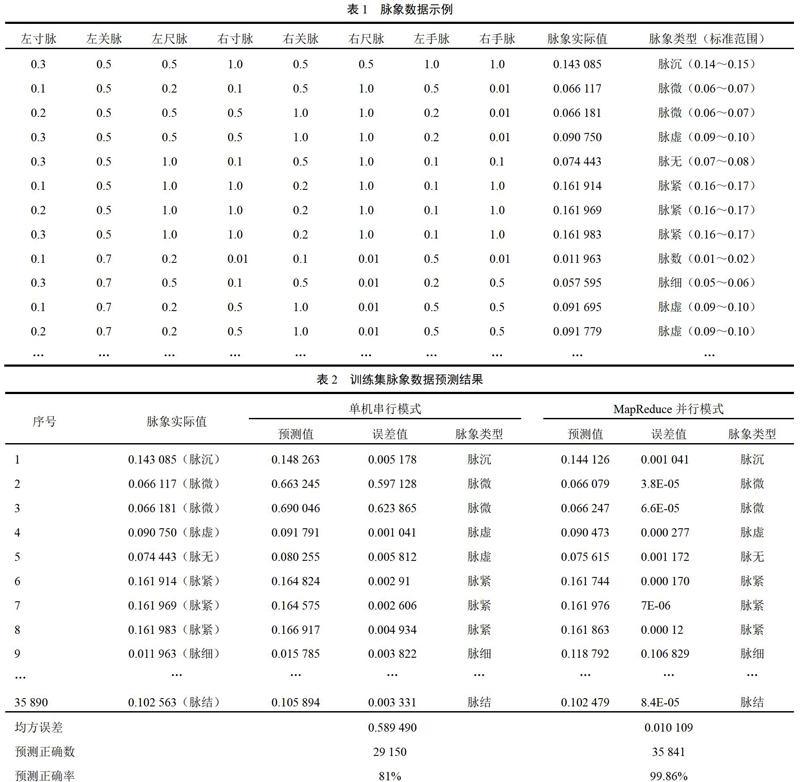
采用食指、中指、无名指3根手指在腕动脉寸、关、尺3个部分进行举、按、寻操作,通过脉搏波动频率反馈的信息判断人体的机能状态[12],采用吕炳奎发明的中医电子脉诊仪来测出辨识指标[13]。Xi={X1,X2,X3,X4,X5,X6,X7,X8},X1~X8分别表示左寸脉、左关脉、左尺脉、右寸脉、右关脉、右尺脉、左手脉、右手脉[14],Yi={Y }表示脉象的实际值,脉象数据示例见表1。
2.3 预测模型
将中医电子诊脉仪的8个输出结果作为神经网络的输入层数据,并决定输入层节点个数。中医脉象类型的指标个数决定输出层节点数,隐含层节点个数的确定采用公式m=√rn,式中m为隐节点数,r为输入层节点数,n为输出层节点数,确定大概节点个数,在此基础上探索m+1、m-1等节点个数的网络,直至得到最优结构性网络8∶6∶1。
将1 G条脉象数据样本分为75%训练集(768 M)和25%测试集(256 M),采用动量-学习率自适应[15-17]调整快速BP算法对神经网络进行训练。训练结束时的网络最终误差设定为10-4,训练过程采用自动停止,即当网络输出误差达到10-4,网络训练过程自动停止。
在实验中,随机生成n组初始化的权值数组,并将首次迭代次数设置为5000,以达到基本的误差收敛平缓阶段,然后将权重组中误差精度最高的1/6选出,进入下一次MapReduce过程,程序设置时间上限为3 h和误差接受范围为(0~0.000 1),如果运算时间达到了规定的上限时间,误差还没有被接受,将继续选择误差最接近的1/6组,进行下一次MapReduce过程,依次循环下去,若误差到达约定范围之内,便跳出循环,接受权重。预测结果见表2。
在768 M共35 890条数据中,单机模式预测正确预测29 150条,正确率为81%;MapRedece并行模式正确预测35 841条,正确率为99.86%。表明Hadoop环境下的BP算法能够准确地进行脉象识别。
2.4 结果分析
BP算法传统单机串行模式下要到达程序设定的误差精度,普通的PC端难以承受该计算量,运算时耗太长。本研究针对上述问题设置了2个对照组。
第1组:使单串行机模式和MapReduce并行模式在同一时间点运行,并在运行至30 s时截止取得权值,然后对256 M数据进行运算并与标准数据比较取得误差作图,见图4。
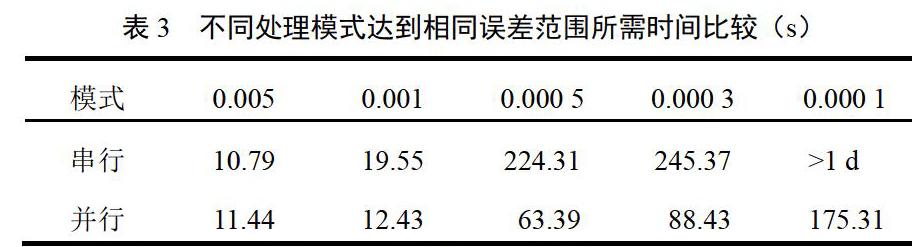
第2组:将2个程序分别设定相同的误差接受范围,并在同一个时间点运行,比较2个程序到达误差范围所需的时间,见表3。
图4表明,在程序运行30 s时终止程序,对256 M实验数据传统串行处理模式和MapReduce链式并行处理模式的所能达到的误差的精确度对比,结果显示MapReduce链式并行处理模式的误差精度远高于传统串行处理模式。
表3表明,要到达相同精度的误差区间时,MapReduce链式并行处理模式所用时间远少于传统串行模式。
网络训练学习完毕后,将检验样本输入神经网络进行脉象分类检验。相同时间内,并行MapReduce所能达到的误差精度比传统单机串行所能到达的精度要高,当对误差的精度要求提高达万分之一点时,传统的计算方法甚至无法算出符合要求的权值,且运算时间超过1 d,资源消耗巨大。而MapReduce模型下的计算仅需4 min便能接受误差,返回多组符合要求的权值。通过分析脉象识别中误差大小的影响因素,可提高对海量脉诊数据处理的速度,探索减小脉象主观识别误差的方法。
3 小结
诊脉“在心易了,指下难明”,学习者需长期积累经验且难以达到精确、客观、统一的标准。计算机技术、信号处理技术、人工智能等多种现代技术的出现,促成了脉象仪产生,脉诊相关研究逐渐呈现信息化发展态势。将多种计算机信息技术与中医研究相结合,使中医脉诊的客观化、标准化成为可能。
本研究基于Hadoop环境改进的BP神经网络算法大大减小了脉象识别中BP算法模型的误差,实验结果表明,采用Hadoop平台下的链式MapReduce方式建模,在时间性能和准确率上远远优越于传统的串行处理方式。对于中医脉象的识别分类和辅助诊断疾病具有一定的临床应用价值。
参考文献:
[1] 朱晨杰,杨永丽.基于MapReduce的BP神经网络算法研究[J].微型电脑应用,2012,28(10):9-12,19.
[2] MILLER M. Cloud computing:Web-based applications that change the way you work and collaborate online[J]. Que Publishing Company, 2008,82(3):303-318.
[3] 崔杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012,49(S1):12-18.
[4] DEAN J. Experiences with map reduce:An abstraction for large scale computation[C]//Proceeding of the 15th International Conferenceon Parallel Architectures and Compilation Techniques. Washington DC:IEEE Press, 2006.
[5] 郝树魁.Hadoop HDFS和MapReduce架构浅析[J].邮电设计技术, 2012(7):37-42.
[6] 武森,冯小东,杨杰,等.基于MapReduce的大规模文本聚类并行化[J].北京科技大学学报,2014,36(10):1411-1419.
[7] YANG D S, LIU Z W, ZHAO Y, et al. Exponential networked synchronization of master-slave chaotic systems with time- varying communication topologies[J]. Chinese Physics B,2012, 21(4):155-162.
[8] 王颖纯,白丽娜.基于BP神经网络的中医脉诊体质类型判定[J].中医杂志,2014,55(15):1288-1291.
[9] 张雪伟,王焱.基于Sigmoid函数参数调整的双隐层BP神经网络的板形预测[J].化工自动化及仪表,2010,37(4):42-44,48.
[10] 黄山,王波涛,王国仁,等.MapReduce优化技术综述[J].计算机科学与探索,2013,7(10):885-905.
[11] 吴斌,刘心光.一种基于改进的链式MapReduce的并行ETL应用[J]. 电信科学,2013,29(12):1-8.
[12] 朱钦士.切脉“寸关尺”有何依據[J].大众科学,2014(12):32-33.
[13] 张丽娜,李垠含,张文顺.脉诊仪在实验教学中存在的问题及改进对策[J].辽宁中医药大学学报,2011,13(6):271-272.
[14] 党宏智.寸关尺部位脉搏信息检测系统[D].兰州:兰州理工大学, 2011.
[15] 宫宁生,钱春阳,张媛.一种BP网的学习速率与动量项自适应算法[J].小型微型计算机系统,2013,34(8):1872-1876.
[16] MAN Z H, WU H R, LIU S, et al. A new adaptive backpropagation algorithm based on Lyapunov stability theory for neural networks[J]. IEEE Trans on Neural Networks,2006,17(6):1580?1591.
[17] WONG W K, YUAN C W M, FAN D D. Stitching defect detection and classification using wavelet transform and BP neural network[J]. Expert Systems with Applications,2009,36:3845-3856.
(收稿日期:2017-04-10)
(修回日期:2017-05-03;编辑:向宇雁)
