
基于QoS约束的改进语义Web服务发现方法
2018-07-10 09:24许国鹏马良荔冯泽波
计算机与数字工程 2018年6期
许国鹏 马良荔 冯泽波
1 引言
目前,SOA(Service Oriented Architecture)架构被广泛应用在软件设计领域,同时,Web服务作为实现SOA架构的主流技术手段,发展迅速。互联网平台上,各种形式功能的服务应用呈几何级数增长,实现相同功能的服务数量也越来越多。如何高效、准确和快速地从海量服务中筛选出满足用户需求的Web服务,提高服务发现查全率和查准率,成为当前服务发现领域研究的重点。
目前,Web服务发现方法主要分为两类:一类是基于语法的服务发现方法,代表性的是传统的UDDI服务发现算法[1];一类基于语义的服务发现方法,代表性的是OWL-S/UDDI等级匹配算法[2]。前者是基于关键字的精确匹配,原理简单,但这种语法级的匹配过程无法保证查全率和查准率;后者引入本体概念,使服务描述多了语义信息,通过服务概念间的包含关系进行匹配等级划分,匹配效率有所提高,但是每个领域都需要建立相应的本体,工作量较大,匹配精度不足的特点也较突出[3]。
针对服务发现算法,国内外学者进行了很多相关研究。王新颖等[4]将改进的BM算法作为单纯语义服务发现不足后的补充,有效解决了由于概念歧义而导致的匹配失效问题。Chukmol[5]采用层次分析的思想,将服务匹配过程分解成不同子任务,建立匹配代理模型。马秀军等[6]将信息内容语义相似度计算的思想,与服务的IO语义匹配相结合,提高了服务发现的查全率。
本文分析了OWL-S/UDDI等级匹配算法的优缺点,并从提高服务发现查全率和查准率的角度,提出基于QoS约束的改进语义Web服务发现方法,分阶段进行服务匹配筛选。
2 OWL-S/UDDI等级匹配算法
语义Web服务发现算法的研究很多,其中比较经典的是OWL-S/UDDI等级匹配算法,该算法建立在服务本体概念模型的基础之上,通过概念的上下级包含关系进行逻辑推理,得到四种匹配结果,实现服务发现。
OWL-S/UDDI等级匹配算法通过构建服务本体层次树(如图1)进行简单的逻辑推理,确定匹配对象的包含关系,匹配对象主要是ServiceProfile中的服务输入输出信息,将两个服务概念匹配结果分为4个级别[1]:

图1 本体层次树
1)Exact:用户请求输出与服务输出完全等价或用户请求输出是服务输出的直接子类;
2)Plug-in:服务输出包含用户请求输出;
3)Subsume:服务请求输出包含服务输出;
4)Fail:其他情况。
这四种服务匹配结果按照匹配程度降序排列:
Exact>Plug-in>Subsume>Fail
等级匹配算法的优点是在匹配过程中加入了服务的语义描述,进行逻辑推理,提高了服务匹配的查全率和查准率。然而,由于该算法仅仅只是考虑概念间的上下级包含关系,匹配精度划分不明确,无法反映同一等级内两个服务的具体匹配程度。
3 改进的语义Web服务发现方法
为了进一步提高服务发现的效率,本文采用三级策略分阶段进行服务匹配过程。
首先根据服务语义标注的精度选择,可以把Web服务形式化表示为一个六元组。
定义1 Web服务六元组

式中,包含六个元素,Name表示Web服务的名称;Category表示Web服务所属领域类别;Description表示Web服务的功能描述;Input={i1,i2,i3,…,im}、Output={o1,o2,o3,…,on}分别表示Web服务的输入、输出参数集合;QoS表示Web服务的非功能性描述。
根据Web服务的形式化定义,可以把语义Web服务匹配过程分为三个阶段[7]。
3.1 基本描述匹配
根据服务信息的特点,基本描述匹配依据Web服务六元组中Name(服务名称)、Category(服务类别)和Description(服务描述)三元素进行关键字匹配,完成服务发现的初步筛选,实现如下:
1)全部服务集 W={WS1,WS2,WS3,…,WSn},WSi为单个服务;β1,β2,β3分别为服务属性Name、Category和Description匹配的阈值;服务候选集S初始为空;sim(X,Y)即X、Y的匹配程度;候选服务信息Namew、Categoryw和Descriptionw,请求服务信息NameR、CategoryR和DescriptionR。
2)For WSi∈全部候选集W
If((sim(Namew,NameR)> β1)&&(sim(Categoryw,CategoryR)> β2)
&&(sim(Descriptionw,DescriptionR)>β3))
将WSi加入到服务候选集S中
End if
End For
Return服务候选集S
通过基本描述匹配,划分服务的类别,缩小服务筛选范围,重点是匹配阈值的选取,其直接影响候选服务集的大小。
3.2 功能匹配
在基本描述匹配缩小候选服务集的基础上,依据服务的输入输出(IO)进行功能匹配。
定义2 Web服务的IO相似度

式(1)中,SR、SW分别表示请求服务和提供服务;simIO(SR,SW)表示两个服务的IO相似度;IR=(IR1,IR2,…,IRk),IW=(IW1,IW2,…,IWj)分别表示服务SR、SW的输入参数集;OR=(OR1,OR2,…,ORt),OW=(OW1,OW2,…,OWh)表示服务SR、SW的输出参数集;k、j、t、h均为任意正整数;simIn(IR,IW)表示服务 输 入 的 相 似 度 ,其 权 重 为 α(0≤α≤1);simOut(OR,OW)表示服务输出的相似度,其权重为β(0≤β≤1),且 α+β=1。如果用户对权值没有要求,则采用默认的平均权值,即α=β=0.5。
Web服务的IO相似度由输入参数相似度和输出参数相似度加权计算得到,权重α、β根据对输入、输出参数考虑的重要程度确定。
在本文中,采用编辑距离和本体概念相似度相结合的方法,从语法和语义两方面来综合考虑计算输入输出参数语义相似度。
定义3 编辑距离[8]
指一个字符串转化为另一个字符串所需进行的最少编辑操作(删除、插入、替换等)次数。
采用基于编辑距离的方法计算参数的相似度为
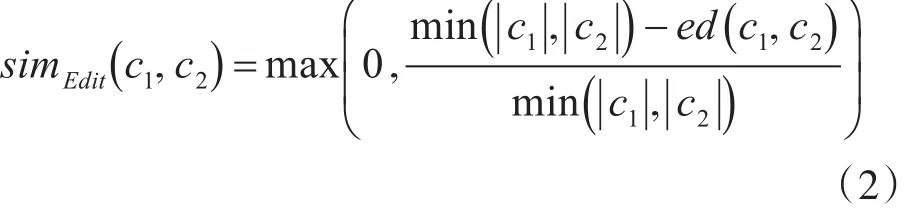
式(2)中,c1、c2分别为进行比较的参数; ||c1、 ||c2分别为参数字符串c1、c2的长度;ed(c1,c2)表示字符串c1转换到c2的最小操作次数。
基于编辑距离的相似匹配只考虑拼写上的差异,但是有些字符串拼写上完全不同,却具有相同或相似的含义。因此,在计算服务输入输出相似度时还需要考虑语义。
本文中使用本体描述服务的IO,层次树中概念节点深度来衡量服务IO参数之间的相似度。基于Wu等提出的LCS算法[9],IO参数语义相似度计算方法,公式为

式(3)中,depth函数表示本体层次树中从根节点到当前节点的深度;LCS表示参数c1、c2所代表的节点的最小公共超集。根据式(2)~(3),得到参数c1、c2的相似度可以表示为
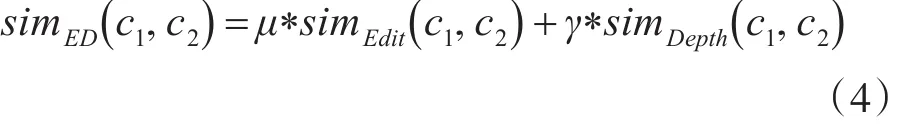
其中,μ、γ分别为基于编辑距离计算相似度和基于本体概念节点深度计算相似度两种方法的权重,μ+γ=1。权重大小的选择没有固定的模式,需要根据具体的应用环境选择。
由于一般服务的IO都具有多个参数,因此要计算每个参数的相似度;并且每个服务参数的顺序不尽相同,难以确定哪些参数是对应的,故请求服务和提供服务的每一个参数都要配对计算相似度,构建相似度矩阵如下:

其中,SI、SO分别为服务输入、输出相似度矩阵;SIkj表示请求服务输入参数集中参数IRk和提供服务输入参数集中参数IWj的相似度,SOth表示请求服务输出参数ORt和提供服务输出参数集中参数Owh的相似度。

以服务输入相似度矩阵为例,遍历相似度矩阵,取相似度最大的SIkj,并将SIkj所在行和列从矩阵中删除,在余下的矩阵中继续重复此操作,直至矩阵为空,得到一个最大相似度序列SI1,SI2,…,SIn(n=min(k,j)),则Web服务输入相似度为
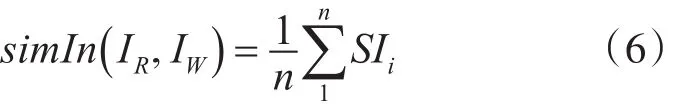
同理,由服务输出相似度矩阵可得一个最大相似度序列 SO1,SO2,…,SOm(m=min(t,h)),则Web服务输出相似度为

综合式(1)~(7),可得到请求服务和提供服务的IO相似度simIO(SR,SW)。通过相似度与选取阈值的比较,进一步得到功能相同或相近的候选服务集。
3.3 QoS约束
服务质量(Quality of Service,QoS)是Web服务的非功能性描述,反映了服务满足用户需求的能力。完成Web服务的功能匹配后,再通过QoS建立量化评价机制,对Web服务候选集进行QoS排序,最终得到满足用户需求的服务集。
QoS衡量服务的标准有很多,包括安全性、吞吐量、可靠性、可用性、响应时间等,有些标准对Web服务而言是积极的,有些是消极的,不同领域对服务的QoS衡量标准没有统一的规定,要求不尽相同。用户在调用服务时,不仅关注服务的功能属性,还对服务的QoS属性提出了要求,不同用户在不同环境和应用场合下对Web服务的QoS需求偏好也不尽相同。
本文以响应时间、可用性、可靠性、信誉度四方面建模描述Web服务的QoS属性[10]。
定义4 Web服务QoS模型

1)其中,s是一个服务。QoS(s)是Web服务的服务质量综合评估;Qtime(s),Qava(s),Qrel(s),Qrep(s)分别为响应时间、可用性、可靠性、信誉度衡量函数。
2)响应时间:从开始对一个Web服务发出调用请求到收到执行结果的时间。包括服务通信时间T1和服务执行时间T2,响应时间T=T1+T2。
3)可用性:表示一个Web服务调用返回成功结果的概率。
4)可靠性:表示一个Web服务正常运行的概率,可以用公式表示为
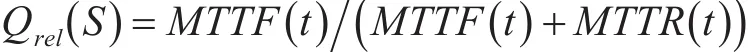
其中MTTF(t)表示服务的平均无故障时间,MTTR(t)表示服务的平均修复时间。
5)信誉度:表示一个Web服务的可信赖程度,反映了大众用户对调用服务后的感性评价,分级定义优劣。
由于四个QoS属性量纲不同,为了能够综合考虑服务的QoS,首先需要将Qtime(s),Qava(s),Qrel(s),Qrep(s)进行归一化处理,得到各属性在[0,1]范围内的表示。=( )Qtime(s),Qava(s),Qrel(s),Qrep(s)为QoS归一化处理的属性向量,=( )w1,w2,w3,w4为用户对以上QoS关注程度的权重向量,w1+w2+w3+w4=1 ,w1、w2、w3、w4取值根据用户偏好,默认情况下w1=w2=w3=w4=0.25;则服务综合QoS评价函数可表示为

Web服务的综合QoS值范围在[0,1]之间,越接近1,则说明服务的服务质量越高,越满足用户的需求。根据服务综合QoS值对服务候选集进行排序,结果返回给用户供其选择满足需求的服务。
4 实验结果和分析
4.1 实验环境
为了验证本文中方法的可行性和有效性,通过实验以查全率和查准率两个指标衡量Web服务发现算法的性能。
查全率:指查询返回符合查询条件的服务数量与查询返回服务总数量之间的比率;
查准率:指查询返回符合查询条件的服务与测试样本集中符合查询条件的服务的比率。
本实验环境为:操作系统Windows XPSP3,应用程序开发与编辑工具为:Visual Studio 2008,实验中使用的服务和本体基于开源的服务测试集OWLS-TC4,选取教育领域100个,旅游领域100个,经济领域200个,共400个服务,并根据本文中建立的服务模型,扩展服务OWL-S描述文件,完善服务描述,形成最终的服务测试候选集。为了简化过程,实验中服务每个匹配阶段所用的阈值统一默认设为0.5。将传统的UDDI服务发现方法、OWL-S/UDDI等级匹配方法和本文的改进匹配方法进行实验比较。
4.2 实验结果和分析
实验结果如图2所示,得到三种Web服务发现方法在不同服务请求下的平均查准率和查全率。
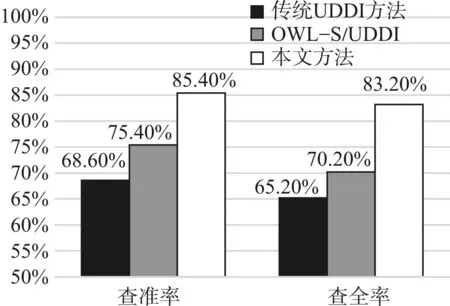
图2 查准率和查全率比较
实验结果表明,由于UDDI基于关键字的匹配方法没有考虑服务的语义信息,具有很大的局限性,查全率和查准率较差;OWL-S等级匹配方法匹配过程提供了服务的语义信息,查全率和查准率有了一定程度的提升,但由于匹配精度不够,查询效果还有待提高;本文中的改进匹配方法实现服务的多层筛选,能够有效剔除多余的服务,服务的查准率得到有效提高,并在服务筛选中加入了QoS约束控制,为用户选择满足需求的服务提供了参考,查询效果优于其他两种方法。
5 结语
随着Web服务技术的广泛应用,传统的服务发现方法已不能满足用户的需求。本文通过分析OWL-S/UDDI服务发现方法的优缺点,提出了基于QoS约束的Web服务发现改进算法,分阶段完成服务匹配过程,最后根据用户偏好综合评估服务QoS值,对候选服务集进行排序以供选择。该方法能够有效提高服务的查全率和查准率,为后续服务的选择组合奠定基础。下一步将逐步完善匹配策略以及QoS数据库的建立、反馈维护机制,进一步提高服务发现效率。
[1]王旭辉,姚世军,焦志勇,等.基于UDDI的Web服务发现研究[J].计算机与现代化,2009(2):31-34.
WANGXuhui,YAOShijun,JIAOZhiyong,et al.Web Service Discovery Research based on UDDI[J].Computer&Modern,2009(2):31-34.
[2]尹辉,季桂树,袁凤璋.语义Web服务匹配算法的研究[J].网络安全技术与应用,2008(9):35-36,75.
YIN Hui,JI Guishu,YUAN Fengzhang.Research on Semantic Web Service Matching Algorithm[J].Network Security Technology and Application,2008(9):35-36,75.
[3]王继东,张瑜,戴耀文.一种改进的语义Web服务等级匹配算法[J].自动化技术与应用,2010(2):31-34.
WANG Jidong,ZHANG Yu,DAI Yaowen.An Improved Semantic Web Service Level Matching Algorithm[J].Automation Technology&Applications,2010(2):31-34.
[4]王新颖,何克清,熊伟,等.基于语义和改进BM算法的Web服务发现[J].小型微型计算机系统,2015,36(4):717-720.
WANG Xinying,HE Ke-qing,IONG Wei,et al.Web Service Discovery based on Semantic and Improved BM Algorithm[J].Small Miniature Computer Systems,2015,36(4):717-720.
[5]CHUKMOL U.A framework for Web service discovery:service's reuse,quality,evolution and user's data handling[C]//Proc of the 2nd SIGMOD Workshop on Innovative Database Research.Vancouver:ACM Press,2008:13-18.
[6]马秀军,陈继东,李坤.基于IO与信息内容的语义Web服务发现[J].计算机系统应用,2016(2):141-145.
MA Xiujun,CHEN Jidong,LIKun.Semantic Web Service Discovery Based on IO and Information Content[J].Computer System Application,2016(2):141-145.
[7]李庆云,魏娟杰.基于多层匹配筛选的Web服务发现模型的研究[J].计算机应用与软件,2010,27(6):142-144.
LI Qingyun,WEI Juanjie.Research on Web Service Discovery Model based on Multi-layer Matching and Filtering[J].Computer Applications and Software,2010,27(6):142-144.
[8]姜华,韩安琪,王美佳,等.基于改进编辑距离的字符串相似度求解算法[J].计算机工程,2014,40(1):222-227.
JIANG Hua,HAN Anqi,WANG Meijia,et al.Algorithm for Solving String Similarity Based on Improved Editing Distance[J].Computer Engineering,2014,40(1):222-227.
[9]Wu Z,Palmer M.Web semantics and lexical selection[C]//Proc of the 32nd Annual Meeting of the Association for Computational Linguistics,New Mexico State University,Las Cruce,New Mexico,1994:133-138.
[10]杨胜文,史美林.一种支持QoS约束的Web服务发现模型[J].计算机学报,2005,28(4):589-594.
YANG Shengwen,SHI Meilin.A Web Service Discovery Model Supporting QoSConstraint[J].Journal of Computer Science,2005,28(4):589-594.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2021年12期)2021-12-31
哈哈画报(2021年10期)2021-02-28
阅读与作文(英语初中版)(2019年8期)2019-08-27
小型微型计算机系统(2019年6期)2019-06-06
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
