
改进Softmax分类器的深度卷积神经网络及其在人脸识别中的应用
2018-07-05 09:29:08刘鹏伟
上海大学学报(自然科学版) 2018年3期
冉 鹏,王 灵,李 昕,刘鹏伟
(上海大学机电工程与自动化学院,上海200444)
近20多年来,人脸识别是一种被广泛研究的生物识别技术,在许多领域得到了应用,同时也有许多新的方法被提出,并取得了较好的成果.传统的人脸识别方法主要是基于图像像素的子空间方法,如主成分分析(principal component analysis,PCA)法、线性判别分析(linear discriminant analysis,LDA)法、独立成分分析(independent component analysis,ICA)法等.这些传统的人脸识别方法在特征提取时,往往是通过人工手段去获取好的样本特征,并在此基础上进行识别和预测,因此这些方法的有效性很大程度上受到人为因素的制约[1-2].
2006年,多伦多大学教授Hinton等[3]提出了深度学习这一新的概念,解决了人工提取特征的难题.深度学习是一种逐层贪婪学习的方法,用于对传统的前馈神经网络的初始化,并能自动从网络中学习到有效的特征,使网络得到更好的训练结果.深度学习是相对于浅层学习而言的,浅层学习模型如人工神经网络(artif i cial neural networks,ANNs)、逻辑回归(logistic regression,LR)和支持向量机(support vector machine,SVM)等.浅层学习模型大部分都不含隐藏层节点(如LR),或只有一层隐层节点(如ANNs,SVM).深度学习是一种深层学习模型,通常具有至少5层网络的结构,类似于含有多隐层的神经网络.不同的是,传统的多隐层神经网络往往很难学习出一些具有代表性的特征,并且所得结果并不一定优于只含单隐层的神经网络,这主要是由于网络初始权值的选取比较困难,使得多层神经网络的训练容易陷入局部最优[4].
深度学习是最近几年最热门的研究领域之一,其较好的特征学习能力使其在许多领域的研究得到了较大的突破,并得到了广泛的应用,如在语音识别[5-6]、自然语言处理[7]、图像分类[8-10]、行人检测[11]等方面均取得了较好的成果.
深度学习在人脸识别领域中的研究,也取得了前所未有的进步.如由Schroあ等[12]利用卷积神经网络的方法在著名的LFW[13]人脸数据库上取得的人脸确认识别率达到了99.63%,而该数据库在人肉眼识别时识别率仅为97.53%[14].由Taigman等[15]提出的DeepFace算法,是通过对400万张图像分析,找出关键的定位点并进行3D建模,利用9层深度神经网络对在非限制条件下的人脸数据库进行训练,最终得到了97.35%的识别率.目前,利用深度学习方法,在LFW人脸数据库上得到的最高识别率由百度公司取得[16],为99.77%.柴瑞敏等[17]采用稀疏深度信念网络的方法在低像素人脸图像的识别上得到了较好的识别结果.
本工作提出了一种改进Softmax分类器的深度卷积神经网络(improved Softmax classifer for deep convolution neural networks,ISCDCNNs)的方法,通过构建9层结构卷积神经网络,利用卷积神经网络进行人脸特征提取,在网络输出层利用改进的Softmax回归算法对提取的特征进行分类识别实验.在实验中,首先利用CASIA-Webface人脸数据库对卷积神经网络进行预训练;然后在YALE[18],FERET[19]和LFW-A[13]3个人脸数据库中进行人脸识别实验,有效解决了小样本的人脸识别问题;最后与其他现有的几种人脸识别方法进行对比.结果显示,本方法在各人脸数据库上的识别率均优于其他几种人脸识别方法.
1 卷积神经网络
1.1 卷积神经网络概述
卷积神经网络(convolutional neural networks,CNNs)最早于1998年由LeCun等[20]提出,并在手写体数字识别上得到了成功的应用.CNNs是为识别2维或3维信号而特殊设计的一种网络结构,具有较好的容错能力、并行处理能力和自学习能力.本质上,CNNs仍是一种多层感知器,相较于全连接的多层感知器,CNNs采用了局部连接和权值共享的方式.这种设计方式一方面减少了训练参数,使得训练更容易;另一方面,由于采用了局部连接的方式,使得训练过程降低了过拟合的风险.
1.2 卷积神经网络的特性
CNNs由一组或多组卷积层和下采样层构成,其最大特性是相邻层结点间采用了局部连接和权值共享的方式,其另一个特性是可通过不同的卷积核对图像进行卷积,得到多个具有不同特征的卷积输出.
如图1所示,输入结点与隐藏层结点间采用了局部连接.相对于全连接而言,局部连接很大程度上减少了参数个数,并具有一定的稀疏性.
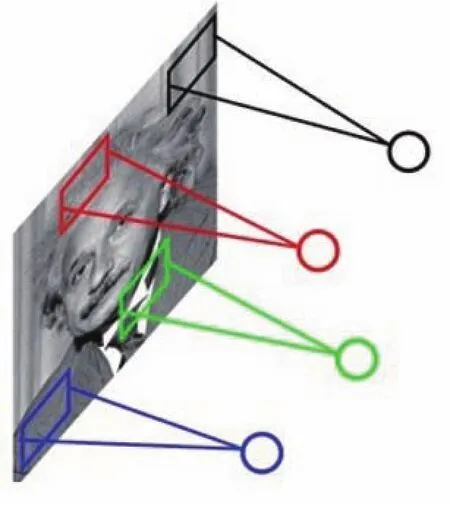
图1 卷积神经网络相邻层结点间局部连接Fig.1 Adjacent layer node local connection of convolution neural networks
CNNs的权值共享方式体现为相邻层结点间局部连接权值是共享的.在图1中,每个结点连接着上一层的局部区域,每个局部区域的大小均相同,且具有相同权值参数.
通常,所连接的局部区域大小为卷积核大小.对于一张输入图像,可以利用多个卷积核进行卷积,每个卷积核能够得到一种卷积特征,这些卷积特征称为特征图(feature map).对于一张输入图像,多个不同的卷积核可得到多个特征图(见图2).
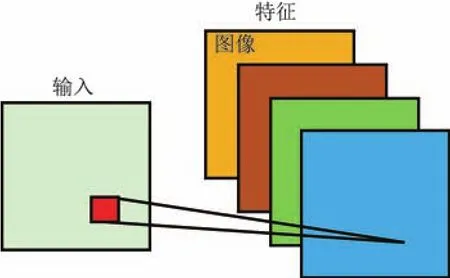
图2 卷积输出特征图Fig.2 Diagram of convolution output feature map
1.3 卷积神经网络的训练过程
与全连接的神经网络训练过程类似,卷积神经网络的训练过程仍然采用了反向传播算法,具有前向过程和反向过程.其中,卷积神经网络的前向过程包括图像卷积、下采样(池化)过程;反向过程则通过误差反向传播,从而更新权值参数.
在卷积层,输入图像在n(n≥1)个卷积核作用下可得到n个特征图,对于每个输出特征图j(j≤1),有
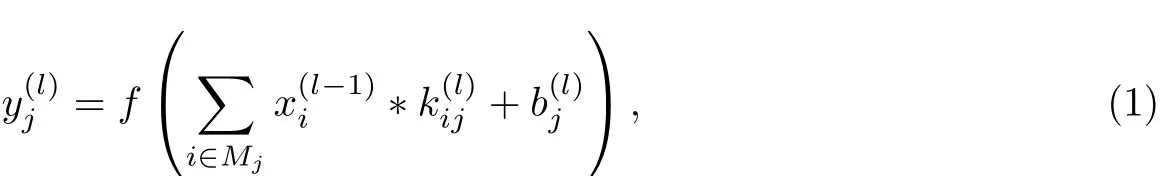
式中,为l层的第j个特征图的输出,*表示卷积,Mj为输入的特征图集合,为第l−1层的第i个特征图的输入,为第l−1层的第i个特征图与第l层的第j个特征图之间的卷积核,为第l层的第j个特征图的偏置项,f()为激活函数.
对图像进行卷积后,设输入的图像大小为m×n,卷积核大小为p×p.如果采用完全卷积,则所得到的卷积输出大小为(m+p−1)×(n+p−1);如果忽略图像边界,则卷积输出大小为(m−p+1)×(n−p+1).也可通过对完全卷积结果进行裁剪操作,使得卷积特征图大小与输入大小一致.
式(1)中,对于激活函数f(x),传统的B-P算法通常选择非线性激活函数Sigmoid或Tanh,但有时Sigmoid或Tanh会出现梯度消失(vanishing gradient)的问题[21],使得靠近输入端的隐藏层参数不能得到有效的训练,容易陷入局部最小点.为了能够较好地克服梯度消失问题,采用修正线性单元ReLU(recti fi ed linear unit)作为激活函数,通常ReLU的效果也优于其他的激活函数,ReLU的函数式为

在得到卷积特征图后,可直接将提取到的特征用分类器(如Softmax分类器)训练,但这样做计算量将会比较大,不利于网络的训练,且容易出现过拟合的问题.为了解决这个问题,可对卷积输出进行下采样(down sampling),对输出特征的不同位置进行聚合统计,可以计算图像一个区域上的某个特定区域的平均值(或最大值).这样的处理能使特征具有更低的维度,同时还使得在训练过程中不容易出现过拟合.这种聚合的操作也称作池化(pooling)[20],将取某个区域的平均值的池化称为平均池化(avg-pooling),取最大值则称为最大池化(max-pooling).
为了计算网络的训练误差,需要计算网络中梯度,而在CNNs中则需要计算各层的输出误差.由于在输入时进行卷积后,紧接着对卷积输出进行了池化,而经过池化后的特征图里的一个像素对应了卷积输出的特征图的一块像素区域,因此需要将池化层中的特征图进行上采样(upsampling),使之与卷积层特征图大小一致,这样才能计算出第l层卷积层的输出误差,进而求出特征图的误差梯度:
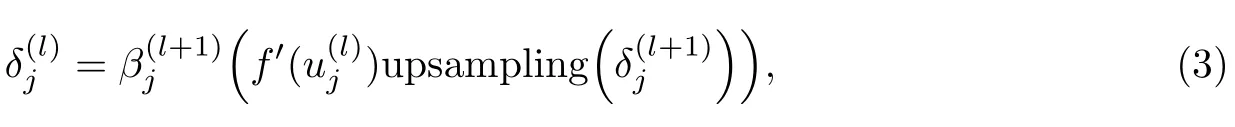
式中,β为常数,u为特征图输出,f′()为激活函数的导数,upsampling为上采样.
Upsampling通过Kronecker积实现,如果下采样的采样因子是n,则上采样操作使得输入图像水平和竖直方向复制n次:

对于每一个输出特征图,计算卷积误差.对第l层偏置项的梯度计算,并对第l层特性图中所有节点的梯度进行求和计算,即

由于CNNs中很多连接的权值是共享的,因此对于一个给定的权值,需要对所有与该权值有联系(权值共享)的连接点求梯度,然后对这些梯度进行求和:
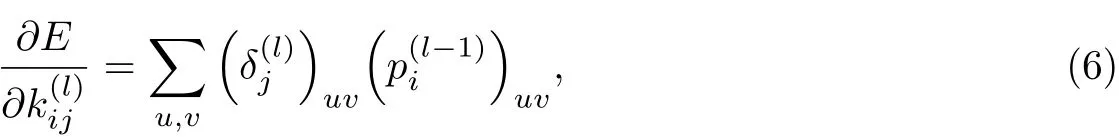
式中,为第l−1层的卷积输出与卷积核逐元素相乘的元素块(patch).
在池化层,池化输出与卷积输出的特征图个数相同,只是池化输出的每个特征图都变小了,故对于每一个池化特征图,其输出为

式中,b为加性偏置,β为乘性偏置,downsampling为下采样.对于每一池化层输出,需要根据输出误差更新b和β,并计算误差对b和β的梯度.误差对b的梯度如式(5)所示.对于乘性偏置β,定义
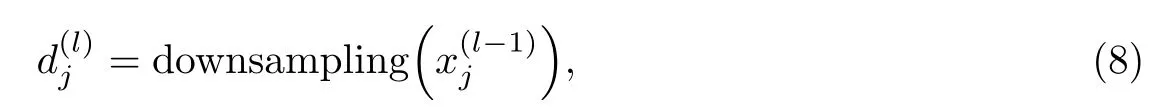
误差对β的梯度计算式为

2 Softmax回归分类
2.1 Softmax回归理论
传统的逻辑回归(logistic regression,LR)模型主要解决二分类问题,Softmax回归则是逻辑回归模型在多分类问题上的推广.逻辑回归模型函数为

对应的损失代价函数为
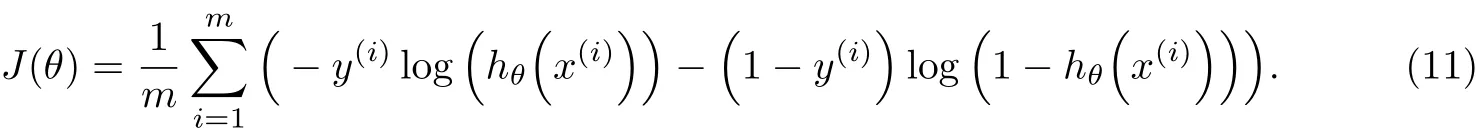
式(10),(11)中,x(i)为训练样本;y(i)(y(i)∈{0,1})为样本对应的标签;m为样本类别总数,对于二分类问题m取2;θ为训练的模型参数.
对于多分类问题,如k(k>2)类,对于给定的样本输入x,如果针对每一个类别j估算出概率值p=(y=j|x),则有
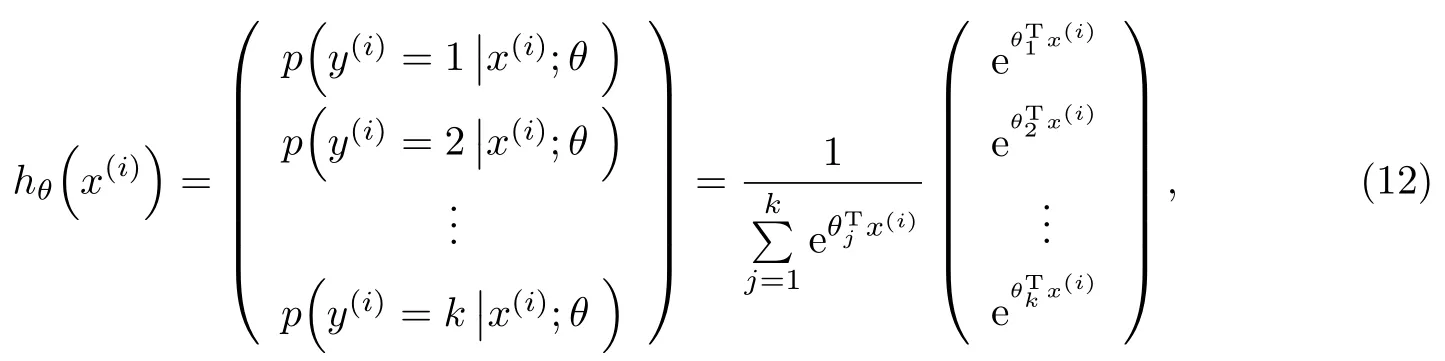
在实现Softmax回归时,通常将θ用一个矩阵来表示,该矩阵是由θ1,θ2,···,θk按行罗列起来得到

所得Softmax回归的损失代价函数为
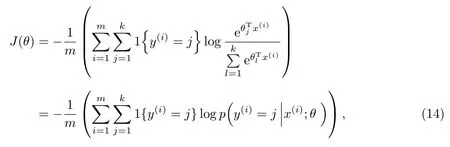
式中,1{·}为示性函数,其取值规则为

p为将x分类为类别j的概率,
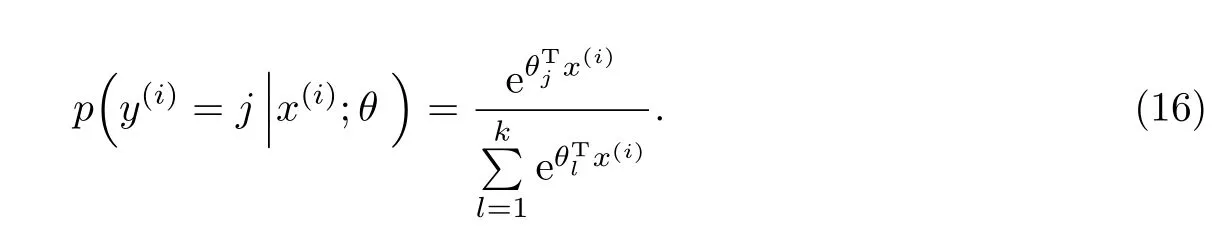
求出式(14)的偏导数

式中,∇θjJ(θ)是一个向量,其第l个元素∂J(θ)/∂θjl是J(θ)对θj的第l个分量的偏导数.
得到式(17)的偏导数式后,利用梯度下降法求解式(14)的极小值,根据梯度更新公式(18)更新模型参数θ:
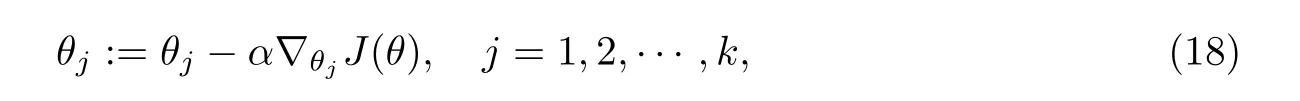
式中,α为学习速率.
2.2 Softmax回归的改进
在Softmax回归求解模型参数θ时,存在一个“冗余”参数集,根据式(16),从参数向量θj中减去一个向量Ψ,完全不影响预测结果.
证明
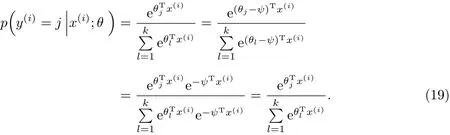
由式(19)可以看到,减去一个向量Ψ后,结果并不会受影响.这说明损失函数J(θ)并不是一个严格非凸的函数,即在局部最小值点附近是“平坦”的.这样所造成的结果是对于任意的输入数据,将得到相同的参数模型.由此,可以对式(14)作进一步的改进,加入一个规则项:
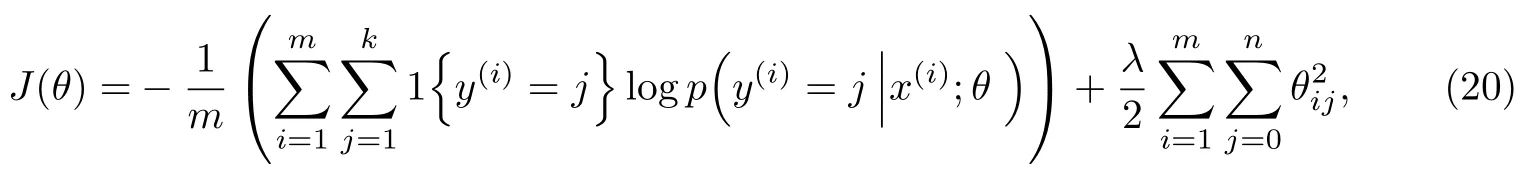
式中,λ(λ>0)为权重衰减参数.在加入后,代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解.同样,为了求解模型参数θ,对损失函数J(θ)进行极小化,求出J(θ)的偏导数,得到
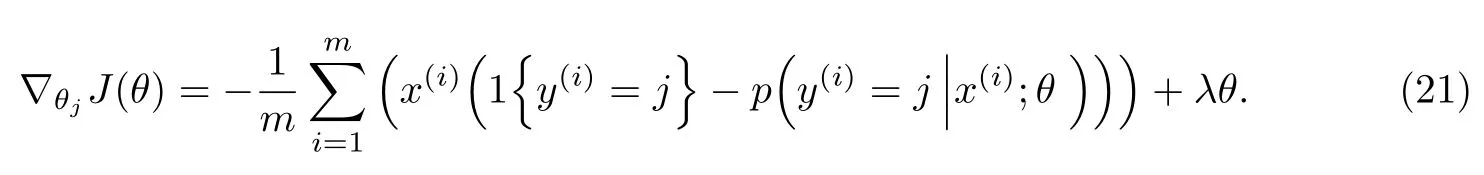
最后,再利用式(18)的梯度更新公式进行参数更新,求解出Softmax的参数模型θ.
3 实验网络结构
本实验卷积神经网络结构包括输入层、3个卷积层、3个最大池化层、1个全连接层(特征提取层)、1个输出层(Softmax分类层).输入层大小统一为32×32×1,分别经过3层卷积和3层池化后,提取得到512维的特征向量,输出层为Softmax分类层,大小为样本类别总数N.本实验卷积神经网络结构如图3所示.

图3 实验卷积神经网络结构Fig.3 Convolution neural networks structure of the experiment
在实验中,激活函数采用ReLU函数,为使网络具有更好的泛化性能,对卷积层1和卷积层2应用ReLU后的卷积输出加入局部响应归一化(local response normalization,LRN)[9]:
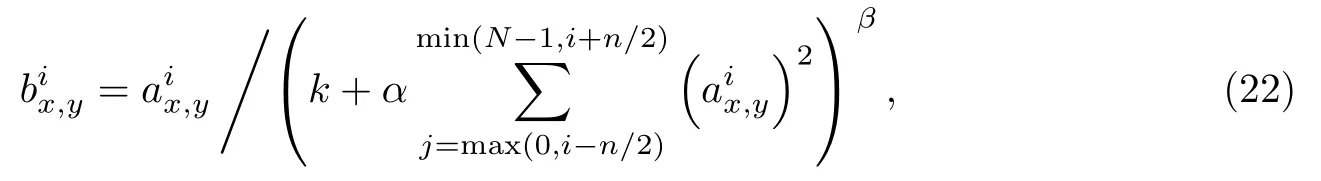
式中,为经第i个卷积核在(x,y)卷积后应用ReLU的输出,作为LRN的输入;为LRN的输出;N为当前卷积层总卷积核数;n为卷积输出的局部区域大小;k,α,β为常量.设置k=1,n=5,α=0.000 5,β=0.75.
为了更有效地防止过拟合,并减小错误率,一种非常有效的方式是在网络的隐藏层中加入dropout[21](dropout是在训练过程中以一定概率p(0≤p≤1)将隐含层节点的输出值置0),本工作中对全连接层的输出加入了50%的dropout,即p=0.5.
4 实验数据及处理
本工作利用了CASIA-Webface人脸数据库中的数据进行网络的预训练,该数据库中有10 575人494 414张图像,每张图像大小均为250×250像素的彩色图像.利用图像处理库OpenCV进行人脸检测,并利用文献[22]中的人脸对齐方法对齐人脸5个关键点(左眼、右眼、鼻尖、左嘴角和右嘴角),根据5个关键点经校正后裁剪出人脸图像,最后图像大小统一缩小为32×32像素,其处理结果如图4所示.

图4 人脸关键点检测及人脸图像裁剪Fig.4 Key points detection of face and face image cropping
经处理后,最终得到共10 483人423 350张图像.将所得到的图像分为训练集和确认集2部分,训练集样本数为381 418,确认集样本数为41 932.在实验中,为了扩大训练样本集,将每个训练样本图像进行水平翻转,故实际训练集大小为762 836.利用这些人脸图像进行网络的预训练.
将预训练所得到的网络连接权值作为新的初始网络连接权值(不包括全连接层与输出层之间的连接权值),利用YALE,FERET和LFW-A这3个人脸数据库进行人脸识别实验.其中,YALE数据库中包含15人,每人11张人脸图像.图像主要包括光照条件的变化、表情的变化等.FERET数据库总共有200人,每人7张人脸图像,每人的图像包括了人脸的姿态、表情、光照等变化.LFW人脸数据库中共有5 749人13 233张图像,但其中大多数人只有1张图像,仅158人有至少10张图像.本实验方法参考了文献[23],利用了158人的LFW数据子集LFW-A,实验所用的3个人脸数据库中部分人脸图像如表1所示.
5 实验结果与分析
本工作利用改进的Softmax分类器的深度卷积神经网络的方法,通过CASIA-Webface数据库中大量人脸数据进行预训练,再利用YALE,FERET和LFW-A这3个人脸数据库进行人脸特征学习,并在3个人脸数据库进行人脸识别实验.本实验采用了随机梯度下降法进行网络的训练,学习速率基准为0.005,学习速率随着迭代次数的增加而减小,动量项设置为0.9,权重衰减设置为0.000 5.

表1 人脸数据库中部分人脸图像Table 1 Part face images in diあerent face databases
5.1 Softmax分类器改进前后实验对比
本实验中的人脸数据库中的每人均选择2张图像作为测试集,FERET人脸数据库中每个人分别选择其余2~5张图像作为训练集,YALE和LFW-A人脸数据库中每人分别选择其余2~6张图像作为训练集.在Softmax分类器改进前后,各人脸数据库的测试集识别率分别如图5中的曲线所示.

图5 不同人脸数据库Softmax分类器改进前后测试集识别率Fig.5 Test set recognition rate before and after improvement softmax classif i er on diあerent face databases
从图5中可看出,各人脸数据库在不同训练样本数时,改进后的测试集识别率均比改进前有了一定的提高.
5.2 本方法与其他方法的实验对比
本工作利用现有论文中的几种方法:SDAEs[24],RRC[25],MPCRC[23],CRC[26]和SRC[27]作为基准,与本方法(ISCDCNNs)进行人脸识别的测试集识别率对比.其中,SDAEs方法参考了原始文献中的网络结构设计,也采用了CASIA-Webface数据库进行预训练,其余几种对比方法未利用外部数据进行预训练,而是直接利用预处理后的人脸图像进行实验,实验所用的3个人脸数据库训练集及测试集均完全一致.对每个人脸数据库进行20次实验,以测试集识别率的平均值(%)作为实验性能指标.
5.2.1 YALE人脸数据库
YALE人脸数据库包含15人,每人11张图像,随机选择每人的2~6张图像作为训练集,再从每人的其余图像中选择2张图像作为测试数据库.实验结果如表2所示.
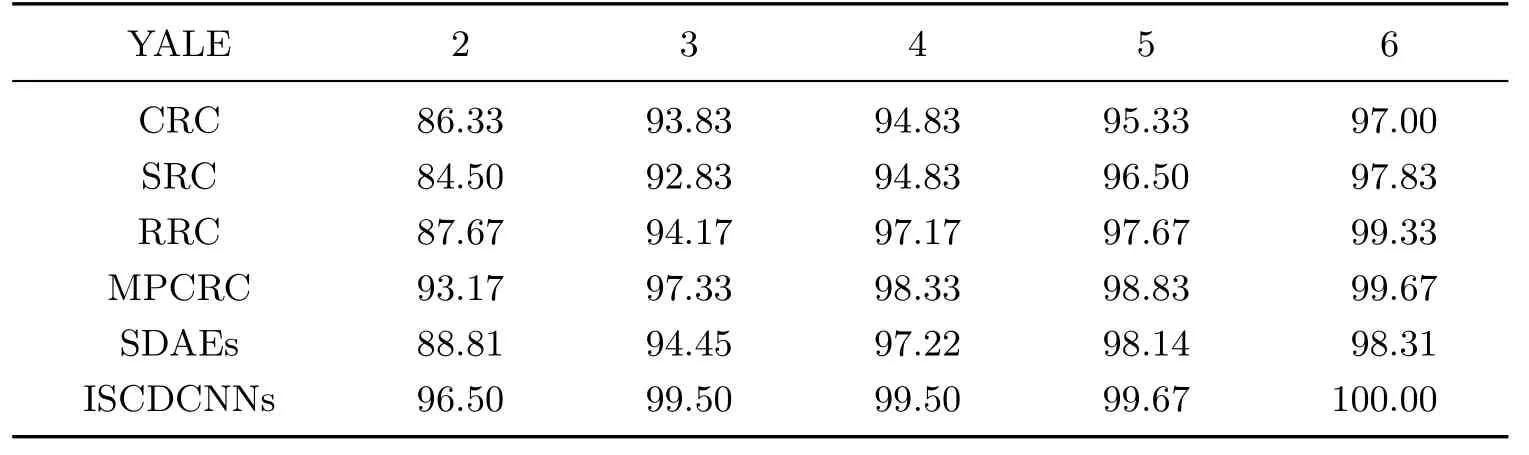
表2 YALE人脸数据库在不同训练样本数时不同方法的测试集识别率Table 2 Test recognition rates of diあerent methods in YALE face database %
由表2中的实验结果可以看到,采用本方法所得到的结果均优于其他方法.随着训练样本数的增加,测试集的识别率也随之增加,当选择每人6个训练样本时,测试集识别率可以达到100%,而在其他方法中MPCRC所得到的识别率最高为99.67%.
5.2.2 FERET人脸数据库
FERET数据库中共有200人,每人7张人脸图像.在本实验中,随机选择每个人的2~5张图像作为训练集,从其余图像中每人选择2张图像作为测试集.实验结果如表3所示.
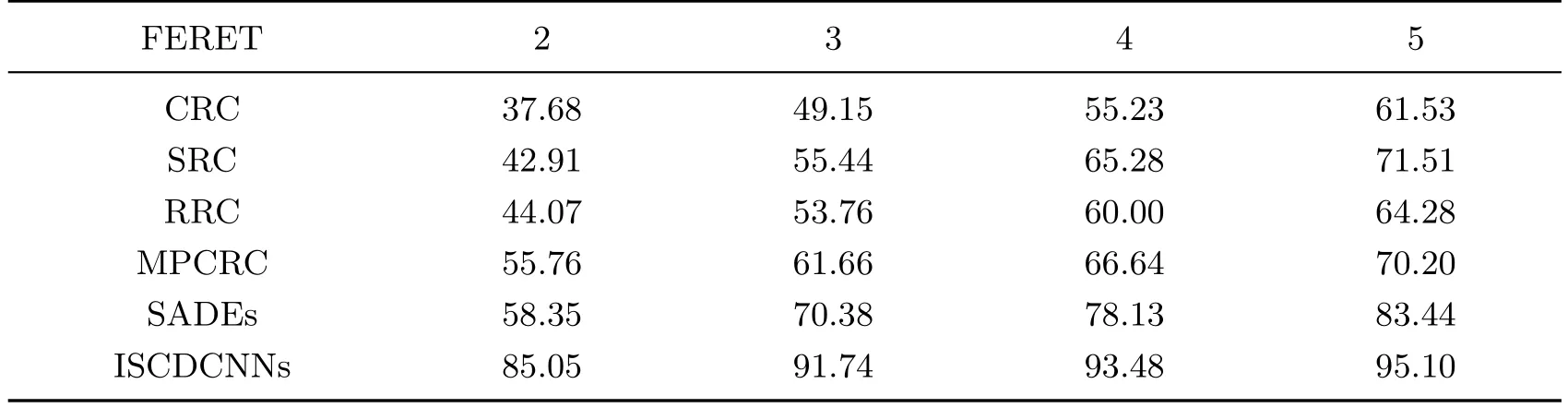
表3 FERET人脸数据库在不同训练样本数时不同方法的测试集识别率Table 3 Comparisons of recognition rates of diあerent methods on the FERET face database%
从表3可以看出,随着训练样本数的增加,本方法所得到的测试集识别率均高于其他方法.在不同的训练样本数下,本方法对比MPCRC方法所得到的测试集识别率,要高出25个百分点.当训练样本数为5时,本方法所得到的测试集识别率达到了95%以上,超出SDAEs方法10个百分点以上.5.2.3 LFW-A人脸数据库
LFW-A数据库中共有158人,每人至少10张人脸图像,随机选择每人的2~6张图像作为训练集,选择每人其余图像中的2张图像作为测试集.实验结果如表4所示.
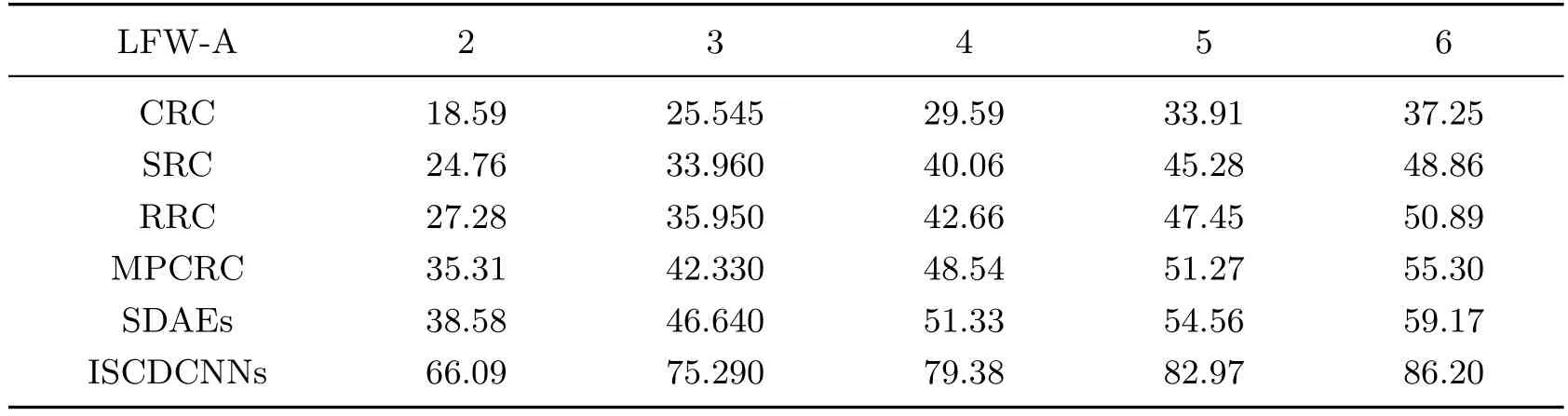
表4 LFW-A人脸数据库在不同训练样本数时不同方法的测试集识别率Table 4 Test recognition rates of diあerent methods on the LFW-A face database %
从表4的实验结果可以看出,采用本方法所得到的测试集识别率明显优于其他方法.当训练样本数为2时,本方法所得到的测试集识别率达到了66.09%,而SDAEs方法仅为38.58%.在不同的训练样本数下,本方法所得到的测试集识别率比MPCRC方法平均要高出30个百分点.
5.3 本方法与其他方法的时间性能分析
本实验所用的硬件及软件平台为Intel Core i5处理器,主频3.1 GHz,内存8 GB,GTX 970显卡,显存为4 GB,操作系统为Ubuntu 14.04LTS.
本工作通过构建了9层结构的卷积神经网络,利用CASIA-Webface人脸数据库对网络连接权值进行预训练,总共预训练样本集大小为762 836张人脸图像,每张大小均为32×32×1,预训练迭代次数为120次.本方法所对比的其他方法(除SDAEs方法外)并未采用CASIAWebface数据库进行预训练,SDAEs方法采用了5层结构的栈式自编码器:1 024-2 048-1 024-512-256,预训练迭代次数为120次.由于本工作采用了大量的人脸数据进行预训练,为了更快速地完成预训练,本方法的实验程序及SDAEs方法的实验程序均采用了GPU的高性能并行计算,以提高预训练速率.表5中列出了本方法及SDAEs方法预训练时间对比.

表5 本方法与SDAEs方法的预训练时间对比Table 5 Comparisons of the pre-training time between this method and SDAEs method
由表5中可以看到,对于预训练人脸数据,2种方法均花费了较长的时间.本方法预训练完所有数据花费了大约63.5 h,而SDAEs方法预训练时长较短一些,为50.8 h.这是由于2种方法的网络结构不一样,本方法的网络结构为9层卷积神经网络,对比5层结构的栈式自编码器而言,本方法的网络训练参数比SDAEs方法的网络训练参数要多得多,预训练时间比较长也是合理的.
经过预训练,将预训练得到的网络连接权值作为网络的初始权值,再利用小样本的数据集进行训练及识别.同样,本方法及SDAEs方法的训练及识别的程序均运行在GPU上,而所对比的其他4种方法则运行在CPU上.在相同的训练集大小的情况下,采用GPU的训练将会比采用CPU的训练效率高很多,因此实际上本方法及SDAEs方法与其他几种方法的训练时间性能对比是不公平的.不过作为训练时间性能参考,本方法利用LFW-A数据库中158人每人6张图像进行训练,在表6中列出了本方法与其他方法在不同的处理器下的训练时间对比.其中,训练的迭代次数依据各方法对数据集的收敛情况,当训练达到收敛后程序自动迭代终止.
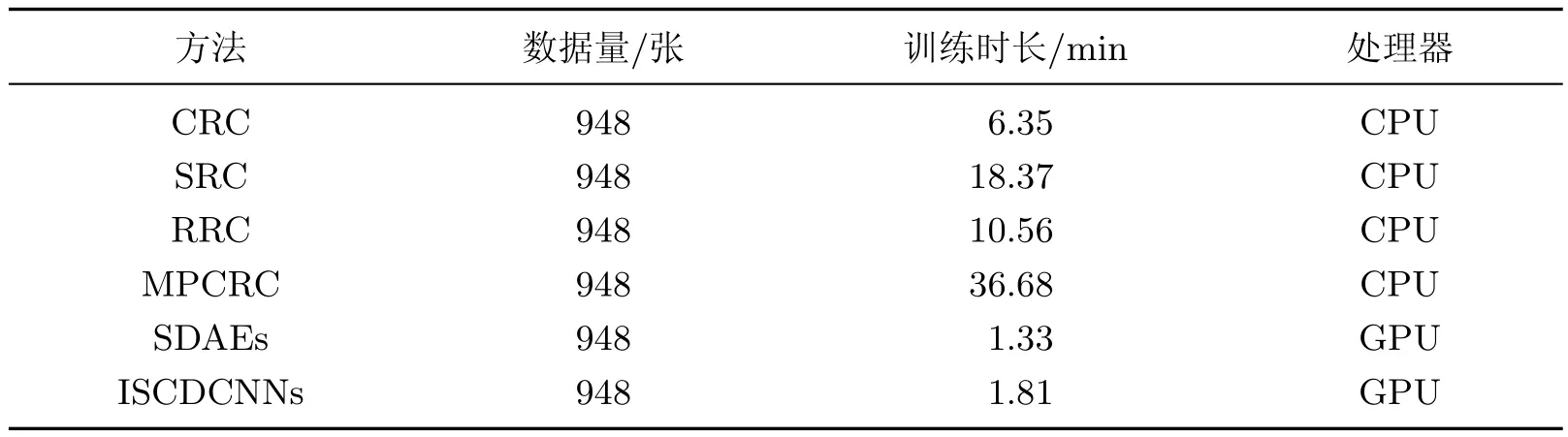
表6 本方法与其他方法的训练时间对比Table 6 Comparisons of the training time between this method and the other methods
从表6可以看到,本方法及SDAEs方法训练时间明显少于其他几种方法,这是由于本方法及SDAEs方法的程序采用了GPU进行训练,而其他方法采用的是CPU进行训练.在采用GPU训练的2种方法中,本方法训练时间对比SDAEs方法要多一些,这是因为本方法的网络结构更复杂,需要训练的网络参数更多;另一方面,本方法及SDAEs方法利用了大量的数据进行预训练后,再利用小样本量的数据进行训练,收敛时间也明显缩短.而采用CPU训练的4种方法,CRC方法训练时间最少,这是由于CRC方法的理论实践中并未涉及较多的矩阵运算,而在花费时间最多的MPCRC方法的理论实践中,涉及较多的矩阵运算,并且将训练数据分成了若干份,每份数据都进行了训练,将所有数据中训练得到的最佳结果作为最终的结果,从而导致训练时速度较其他几种方法慢,训练时间较长.
从表6中对LFW-A数据库训练时间的对比可以看到,本方法及SDAEs方法采用了CASIA-Webface数据库进行预训练,尽管在预训练过程中花费了很长的时间,但是在预训练结束后,利用预训练网络权值作为初始网络权值,再利用小样本量的人脸数据进行人脸识别实验,训练时间将明显减少;并且,从表2~4中不同数据库的识别结果可以看到,本方法在缩短训练时间的同时得到了更好的识别结果.
5.4 不同数据库的Top-k识别率
在某些环境下,人脸识别的应用只需要前几名候选结果.为了进一步说明本方法的有效性,本工作测试了3个人脸数据库的Top-k识别率,即在测试集识别结果中,前k个候选结果中存在正确识别结果的比率.本工作分别给出了3个人脸数据库的Top-1,Top-3,Top-5识别率,分别如表7~9所示.

表7 YALE人脸数据库在不同训练样本数时的Top-k识别率Table 7 Top-k recognition rates of YALE face database in diあerent train samples %

表8 FERET人脸数据库在不同训练样本数时的Top-k识别率Table 8 Top-k recognition rates of FERET face database in diあerent train samples %

表9 LFW-A人脸数据库在不同训练样本数时的Top-k识别率Table 9 Top-k recognition rates of LFW-A face database in diあerent train samples %
表7的结果显示,在不同训练样本数时Top-3识别率已经达到了100%.从表8中可以看出,在不同训练样本数时,Top-3及Top-5的识别率对比Top-1均有较大的提高.当训练样本数为3时,Top-3的识别率已达到99%以上;而当训练样本数为4时,Top-5的识别率达到了100%.
从表9的结果可以看出,在不同训练样本数时对比Top-1的识别率,所得到的Top-3及Top-5识别率均有明显的提升.
6 结束语
本工作利用改进Softmax分类器的深度卷积神经网络的方法,在3个人脸数据库中进行人脸识别实验,通过构建9层结构的卷积神经网络,利用大量人脸图像数据进行网络的预训练,调整网络的初始权值,再利用3个人脸数据库的图像进行特征提取.本实验从大量的人脸图像数据中自动学习到了有效的特征,经过多层的学习,提取到了能够较好地表示人脸的特征,并利用Softmax分类器对特征进行了分类.实验结果表明,本方法得到了比其他方法更好的识别结果.在本工作所构建的网络的第8层提取到的特征,不仅可用于Softmax回归分类,也可利用其他分类器进行分类,如贝叶斯分类器、支持向量机分类器等.另外,本工作利用深度学习的方法解决的问题是人脸识别问题,基于本方法的思路,也可以解决其他很多与模式识别相关的问题.
深度学习是近几年来发展比较快的研究方向,人工智能也是未来发展趋势.随着深度学习方法的不断发展与成熟,在不久的将来,在人工智能领域必然会取得前所未有的突破,并将掀起新一轮的科技革命.
[1]常亮,邓小明,周明全,等.图像理解中的卷积神经网络[J].自动化学报,2016,42(9):1300-1312.
[2]王晓刚.图像识别中的深度学习[J].中国计算机学会通讯,2015,11(8):15-23.
[3]HINTON G E,SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313:504-507.
[4]孙志远,鲁成祥,史忠植,等.深度学习研究与进展[J].计算机科学,2016,43(2):1-8.
[5]SAINATH T N,KINGSBURY B,SAON G,et al.Deep convolutional neural networks for large-scale speech tasks[J].Neural Networks,2015,64:39-48.
[6]王山海,景新幸,杨海燕.基于深度学习神经网络的孤立词语音识别的研究[J].计算机应用研究,2015,32(8):2289-2298.
[7]LE Q V,MIKOLOV T.Distributed representations of sentences and documents[C]//International Conference on Machine Learning.2014:1188-1196.
[8]王伟凝,王励,赵明权,等.基于并行深度卷积神经网络的图像美感分类[J].自动化学报,2016,42(6):904-914.
[9]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet classif i cation with deep convolutional neural networks[C]//2012 Advances in Neural Information Processing Systems(NIPS2012).2012:1097-1105.
[10]杜骞.深度学习在图像语义分类中的应用[D].武汉:华中师范大学,2014.
[11]芮挺,费建超,周遊,等.基于深度卷积神经网络的行人检测[J].计算机工程与应用,2016,52(13):162-166.
[12]SCHROFF F,KALENICHENKO D,PHILBIN J.FaceNet:a unif i ed embedding for face recognition and clustering[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR2015).2015:815-823.
[13]HUANG G B,RAMESH M,BERG T,et al.Labeled faces in the wild:a database for studying face recognition in unconstrained environments[M].Amherst:University of Massachusetts,2007.
[14]SUN Y,WANG X,TANG X.Deep learning face representation from predicting 10 000 classes[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR2014).2014:1891-1898.
[15]TAIGMAN Y,YANG M,RANZATO M A,et al.Deepface:closing the gap to human-level performance in face verif i cation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR2014).2014:1701-1708.
[16]LIU J,DENG Y,BAI T,et al.Targeting ultimate accuracy:face recognition via deep embedding[J].CoRR,2015,DOI:http://dblp.uni-trier.de/db/journals/corr/corr1506.html#LiuDBH15.
[17]柴瑞敏,曹振基.基于改进的稀疏深度信念网络的人脸识别方法[J].计算机应用研究,2015,32(7):2179-2183.
[18]BELHUMEUR P M,HESPANHA J P,KRIEGMAN D J.Eigenfaces vs.f i sherfaces:recognition using class specif i c linear projection[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence.2002:711-720.
[19]PHILLIPS P J,MOON H,RIZVI S A,et al.The FERET evaluation methodology for face recognition algorithms[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence.2000:1090-1104.
[20]LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition[J].Proceeding of the IEEE,1998,86(11):2278-2324.
[21]HOCHREITER S,BENGIO Y,FRASCONI P,et al.Gradient f l ow in recurrent nets:the diきculty of learning long-term dependencies[M].Piscataway:IEEE Press,2001:1-15.
[22]REN S Q,CAO X D,WEI Y C,et al.Face alignment at 3000 FPS via regressing local binary features[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR2014).2014:1685-1692.
[23]ZHU P,ZHANG L,HU Q,et al.Multi-scale patch based collaborative representation for face recognition with margin distribution optimization[C]//2012 European Conference on Computer Vision(ECCV2012).2012:822-835.
[24]PANG S C,YU Z Z.Face recognition:a novel deep learning approach[J].Journal of Optical Technology,2015,82(4):237-245.
[25]YANG M,ZHANG L,YANG J,et al.Regularized robust coding for face recognition[J].IEEE Transactions on Image Processing,2013,22(5):1753-1766.
[26]ZHANG L,YANG M,FENG X.Sparse representation or collaborative representation:which helps face recognition[C]//2011 IEEE International Conference on Computer Vision(ICCV2011).2011:471-478.
[27]WRIGHT J,YANG A,GANESH A,et al.Robust face recognition via sparse representation[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence.2009:210-212.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
计算机工程(2020年3期)2020-03-19 12:24:50
科技创新与应用(2020年6期)2020-02-29 10:39:27
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
自动化学报(2017年7期)2017-04-18 13:41:02
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
