
基于用户行为分析的个性化推荐技术研究
2018-07-04 06:34中国电子科技集团公司电子科学研究院李博文
电子世界 2018年12期
中国电子科技集团公司电子科学研究院 李博文
1.引言
近些年,互联网和移动互联网技术快速发展,网络速度不断提高,使用成本逐步降低,网络应用不断增加,促进互联网在全球范围内得到广泛普及。固定上网和移动上网人数剧增,据统计,2017年12月我国网民数量达到7.72亿人,网络普及率达到55.8%[1]。互联网在生活中的各个方面给越来越多的人们带来了巨大的便利。通过网络,可以浏览世界各地的新闻动态、下载文件资料、购买商品及服务、发布信息等等。网络在这个时代发挥着巨大的作用,现代人的生活已经难以离开网络。然而,网络中的信息量快速增长,带来了信息过载的问题。与巨大的网络信息资源相比,网络用户个体所关注的信息是极其渺小的。用户从网络中查找到其感兴趣信息的过程往往会耗费大量的时间且查找效果不够理想。
针对这个问题,研究人员提出了基于用户行为分析的个性化推荐技术。个性化推荐技术通过对用户历史行为数据的分析,挖掘出用户的兴趣偏好,并将用户感兴趣的信息过滤出来并推荐给用户,提升用户与其关注信息的对接效率。目前许多电商、媒体网站,已经应用个性化推荐技术,推荐给用户其感兴趣的商品或资讯。京东在首页通过“今日推荐”和“猜你喜欢”等栏目向不同用户推荐不同商品,个性化推荐技术为京东贡献了10%的订单。Google News通过应用个性化推荐系统,点击率提升了38%。显然,个性化推荐系统在网络中发挥着重要作用,提升了用户体验以及运营者收益。
本文将对基于用户行为分析的个性化推荐技术的流程以及相关的关键技术进行介绍和分析,最后对技术的发展进行了展望。
2.技术流程
完整的个性化推荐流程涉及到用户行为采集、用户建模和推荐算法等3个步骤,如图1所示。

图1 个性化推荐技术流程
用户行为采集指采集用户的网络行为数据,包括用户在网站上的各种操作行为以及发布的内容数据。用户建模是利用用户行为数据来建模分析用户的兴趣偏好和关注点。推荐算法在用户建模的基础上,研究如何给用户推荐其可能感兴趣的信息,以提升信息对接效率。
3.关键技术
3.1 用户行为采集
用户行为采集方式分为两种:显式采集(Explicit Collecting)和隐式采集(Implicit Collecting)[2]。
(1)显式采集
显式采集是通过在网站中的明显位置设计问题表单,需要用户在其中直接填写提交人口统计类信息和兴趣偏好信息等。这种方式采集的数据经过简单的处理,可以较快速地获取到用户的兴趣偏好数据。其缺点是交互性差,需要用户主动参与并且主观性较强,填写的数据未必能准确表示用户的兴趣偏好;同时用户的兴趣偏好是会随着时间变化,通过一次数据采集不能跟踪到用户兴趣偏好的发展变化。
(2)隐式采集
隐式采集是对用户行为数据的无感采集,其不需要用户的主动配合,用户感觉不到数据采集的过程。隐式采集的技术手段一般包括以下2种。1)埋点采集:通过在网站中相应位置通过“埋点”嵌入js代码来采集行为数据;2)日志解析:通过解析网站服务器日志文件来获取行为数据。隐式采集方法能够采集到更多的数据类型(例如用户打开的页面链接、在页面上停留的时间、交易记录、搜索的关键词、收藏、拖动、打印以及发布的内容等)。相比显示采集的数据,这些数据不能直接表示兴趣偏好,然而是用户当前兴趣偏好的客观反映,其对实时在线推荐有重要意义[3]。
综上所述,可知显式采集和隐式采集的优缺点如表1所示。

表1 显式采集和隐式采集的优缺点
3.2 用户建模
采集到用户行为数据后,需要再对数据进行处理分析得到能够表征用户兴趣偏好的模型,这一处理分析的过程就是用户建模[4]。处理分析中会用到统计、自然语言理解、机器学习、预测等算法模型来提取用户的兴趣偏好特征并计算偏好程度。用户模型与推荐算法是相互关联的,用户模型的形式一般取决于所用的推荐算法[5]。目前使用较多的用户模型一般包括以下几种。
(1)用户-项目评分矩阵模型
用户-项目评分矩阵模型使用一个矩阵来记录评分数据。假设网站共有m个用户和n个项目,则可以生成一个维的评分矩阵,如图2所示。Rij为用户Ui对项目Tj的偏好程度。一般情况下,Rij取值区间为(1,5),数值越大表示偏好程度越高[6]。用户-项目评分矩阵适用于协同过滤推荐算法。

图2 用户-项目评分矩阵
(2)向量空间模型
向量空间模型(VSM: Vector Space Model)最早应用于文本检索系统,其将对文本内容的处理简化为向量空间中的向量运算,形式直观易懂。在用户建模中,向量空间模型将用户对各类内容特征的偏好程度表示为向量形式。对于具有n个内容特征关键词的特征空间用户模型可表示为为用户对特征tk的偏好程度。向量空间模型适用于基于内容的推荐算法,缺乏对用户潜在兴趣偏好的发掘能力。
3.3 推荐算法
推荐算法是推荐系统的核心,其研究如何快速准确地从庞大的项目库中挑选出用户感兴趣的项目,提升用户与项目的对接效率,增强用户体验。常见的推荐算法可分为3大类:基于内容过滤推荐算法、协同过滤推荐算法和混合推荐算法。
(1)基于内容过滤推荐
基于内容过滤推荐(Content-based Filtering)是信息过滤技术在个性化推荐领域的应用和发展。基于内容过滤推荐算法认为:用户未来对与其以往感兴趣的项目相似的项目仍然感兴趣。基于此,基于内容过滤推荐算法从内容角度挖掘用户需求与项目的关联性,计算用户模型与项目模型的相似度来预测用户对项目的兴趣度,再通过设置阈值或TopN策略筛选相应的项目推荐给用户,其流程如图3所示。
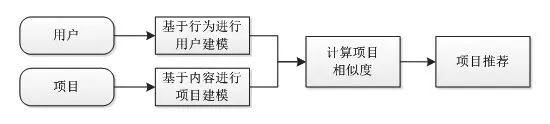
图3 基于内容过滤推荐流程
通常采用TF-IDF方法对内容特征关键词进行分析处理,建立用户和项目的向量空间模型。一般采用夹角余弦来衡量用户与项目之间的相关性。设建立的用户模型和项目模型分别为和则相似度)计算方法如下所示。
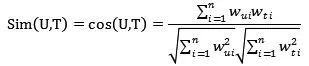
基于内容过滤推荐算法优点在于能够处理项目冷启动问题,给用户推荐的项目具有可解释性;其缺点在于推荐的结果过度特殊化,不能发现用户的潜在兴趣,存在用户冷启动问题,仅适用于文本等能够进行内容分析的项目形式。
(2)协同过滤推荐
协同过滤推荐(Collaborative Filtering)也称为社会过滤,最早由Goldberg等人于1992年提出,是当前最为流行的推荐算法之一[7]。协同过滤推荐算法认为:网络行为相似的用户具有相似的兴趣偏好。因而可以向用户推荐与其相似用户喜欢的项目。协同过滤算法首先进行用户建模,用户模型一般采用用户-项目评分矩阵形式;然后需找近邻,基于用户模型计算用户之间的相似度,再对待推荐用户u,选取若干相似度高的用户组成u的近邻集合;最后产生推荐,计算用户u对其未评分项目的估分,并对估分进行高低排列,将估分高的项目推荐给用户。协同过滤推荐流程如图4所示。
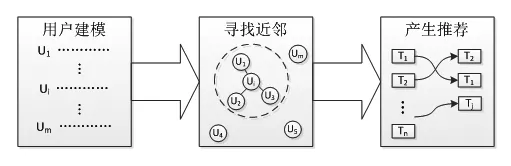
图4 协同过滤推荐流程
用户u对其未评分项目i的评估分数Pu,i的计算公式如下:

内容过滤推荐算法优点在于其推荐具有新颖性,能够发现用户的潜在兴趣,能够适应于难以进行内容分析的项目(如视频、音乐);其缺点在于当数据稀疏时,难以寻找到近邻,并且存在项目冷启动问题。
(3)混合推荐
各种推荐方法都有其优点和缺点,难以在所有场景中发挥出最佳效果。通过前两节的分析,可以发现各种推荐算法的优缺点往往是互补的。通过在推荐的不同阶段实现推荐策略的混合,可以取长补短,发挥优势,避免缺陷[8]。
混合推荐一般包含以下几种方法。加权:将多种算法产生的推荐结果进行加权综合;切换:根据实际情况切换使用不同的算法;混合:混合采用多种算法产生的推荐结果;特征组合:一种算法使用不同算法产生的数据特征组合;级联:先用一种算法产生初步的推荐结果,再用另一种算法在初步推荐结果上进行精炼筛选;特征扩展:一种算法产生的特征信息嵌入到另一种算法的特征输入中;元级别组合:一种算法产生的数据模型集成到另一种算法中使用。
混合推荐能够充分发挥各种算法的特性,适应于更多的场景,达到更高的推荐准确性。混合推荐相比于单种算法具有优越性,但其也有自己的缺点。由于同时使用了多种算法,所以其计算量较大,耗费计算资源,推荐速度更慢。
4.结束语
经过二十余年的发展,个性化推荐逐步引入了大数据、人工智能等先进技术,应用越来越成熟,目前已经能较好的适应于数据稀疏、冷启动等情况。在信息过载问题日益突出的今天,个性化推荐系统发挥着重要的作用。
当前,推荐系统较多地专注于提升推荐的准确性,而忽视了系统的安全性。由于推荐系统可以引导用户的购买行为,带来巨大的经济效益,因而有部分不法商家会在利益的驱使下,通过蓄意构造的恶意行为,对推荐系统进行攻击,以达到打压竞争对手,提高自己产品推荐概率的目的。而在这类行为的干扰下,推荐的准确率会降低,甚至无法产生有效推荐,严重影响用户体验。因而,分析识别出恶意行为并消除其对项目推荐的不良影响将是未来推荐技术的重要发展方向。
[1]中国互联网络信息中心,第41次《中国互联网络发展状况统计报告》,2018.1.31.
[2]余侠,朱林.根据用户反馈建立和更新数字图书馆用户兴趣模型[J].情报杂志,2004(11).
[3]郁雪.基于协同过滤技术的推荐方法研究[D].天津大学管理学院,2009.
[4]任磊.推荐系统关键技术研究[D].华东师范大学信息科学技术学院,2012.
[5]B.obasher.“Data Mining for Web Personaization”in THE ADAPTIVE WEB.vol.4321,P.Brusilovsky,et al,Eds,ed Heidelberg:Springer Berlin,2007,pp.90-135.
[6]郭韦昱.基于用户行为分析的个性化推荐系统[D].南京大学,2012.
[7]D.Goldberg,D.Nichols,B.M.Oki,D.Terry.Using collaborative filtering to weave an information tapestry,Commun.ACM,vol.35,iss. 12,pp.61-70,1992.
[8]Balabanovic M,Shoham Y.Fab:Content-Based,collaborative recommendation.Communications of the ACM,1997,40(3):66-72.
猜你喜欢
科学大众(2022年11期)2022-06-21
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
文苑(2020年4期)2020-05-30
电子制作(2018年17期)2018-09-28
新闻传播(2018年12期)2018-09-19
通信电源技术(2018年5期)2018-08-23
汽车与新动力(2016年6期)2017-01-04
台声(2016年2期)2016-09-16
中国卫生(2015年1期)2015-01-22
现代防御技术(2014年6期)2014-02-28
