
基于深度特征和相关滤波器的视觉目标跟踪
2018-07-04 11:57侯建华陈思萌
中南民族大学学报(自然科学版) 2018年2期
侯建华,邓 雨,陈思萌,项 俊
(中南民族大学 电子信息工程学院,武汉 30074)
视觉目标跟踪是在给定视频序列某一帧中目标的初始状态(例如目标的位置及尺寸)条件下,在后续帧中对该目标状态做出估计或预测[1].现有方法大多通过提取目标特征以构建判别性外观模型来实现跟踪[2];然而,受目标形变、遮挡、背景干扰、光照变化等影响,视觉目标跟踪研究仍有许多亟待解决的难题.
近年来,基于相关滤波器的跟踪 (CFT) 因其突出的实时性受到了广泛关注[2-4〗.CFT的基本思想是由目标外观学习一个判别性相关滤波器(DCF),在检测过程中,相关滤波器对真实目标输出相关响应峰值,从而实现目标定位;此外,Bolme等人[2]提出了相关滤波器更新策略,能够自适应的在线训练相关滤波器,提高了算法的鲁棒性.由于相关滤波运算可以在频域通过快速傅里叶算法实现,CFT具有非常显著的实时性优势.如前所述,在CFT跟踪框架下,关键之一仍然是目标特征及外观模型的设计:最初是采用单通道灰度特征来训练相关滤波器[2],但灰度特征的表达能力有限;后来Danelljan等人[3]提出了多通道颜色特征(CN)、Henriques等人[7]则采用HOG[8]特征将相关滤波器扩展多通道.上述手工特征显著改善了CFT算法性能,但欲进一步提高跟踪算法的精确性和鲁棒性,一个自然的思路是借助深度神经网络.
深度神经网络因其强大的特征学习与表达能力,近年来在图像分类、目标检测与目标识别等应用中取得了极大进展[9-12].在图像分类任务中通常的做法是将固定尺寸的图像输入到一个卷积神经网络(CNNs),经过一系列的卷积、池化操作后,通过一个全连接层提取所需的深度特征.在视频目标跟踪中广泛采用16 或 19 层的VGG[13]网络,VGG网络主要由小型的3×3 卷积操作和 2×2 池化操作组成,使用多个堆叠的小卷积核能够有效减少参数数量、加快网络收敛速度;此外,利用迁移学习特性,可以将在图像分类数据库上训练好的VGG网络用于目标跟踪的特征提取,而无需专门对视频序列重新训练.近期研究发现,单独将每一个卷积层的输出(即卷积层特征)用于图像分类也能取得优越的性能[14],其原因在于这些卷积层特征具有判别性和语义特性、蕴含目标定位所需的结构化信息.
本文在基于相关滤波器的跟踪框架下,研究不同特征对于跟踪算法性能的影响,包括传统的灰度特征、RGB颜色特征、HOG特征、以及几种不同形式的深度特征.由于VGG网络迁移能力较强,本文采用在ImageNet[15]库上针对图像分类任务训练得到的网络模型imagenet-vgg-2048-network[16],分别提取该网络的有关层特征用于目标跟踪.本文首先简要介绍相关滤波跟踪基本原理,包括单通道和多通道两种情况;在实验部分,详细分析讨论传统手工特征与深度特征在CFT算法中的表现,并提出一种将不同深度特征层的相关响应图加以融合后提高目标定位精度的方法.本文工作对设计实际的视觉目标跟踪算法具有较好的参考价值.
1 基于相关滤波器的跟踪
1.1 相关滤波跟踪框架
相关滤波跟踪框架示意图如图1所示.

图1 相关滤波跟踪框架Fig.1 Tracking framework based on correlation filter
首先是初始化,在初始帧指定的目标位置处提取图像块,训练相关滤波器;在后续的每一帧中,在前一帧预测的目标位置处提取图像块用于目标检测(即定位),得到新的目标位置作为输出,同时从该位置处提取图像块实现相关滤波器的更新.
以第t帧为例:
1)依据第t-1帧的目标位置在第t帧提取图像块(patch);
2)对图像块做特征提取、并用余弦窗口平滑边界效应;
3)相关滤波运算,得到空域置信图(即响应图);
4)置信图峰值对应的位置即为第t帧的目标位置,即第t帧输出;
5)依据第t帧估计的目标位置,从第t帧提取图像块,用于相关滤波器的更新.
以下分单通道、多通道两种情况,简要介绍相关滤波跟踪基本理论.
1.2 单通道相关滤波
设xk和yk分别代表输入图像块、期望的滤波输出,hk表示待求的相关滤波器.根据信号与系统理论[17],两个信号的互相关运算与卷积运算在频域只相差一个复共轭,因此所求滤波器可表示为:
(1)
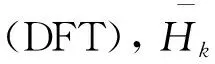
(1)初始化.使用目标外观灰度图像块集合{xk}作为训练样本集,对应的相关滤波输出为{yk},最优滤波器则可以通过最小化以下问题得到:
(2)
(3)
(2)更新.为了保证滤波器能够根据目标外观的变化做自适应调整,需对滤波器H进行在线更新.在第t帧提取新的样本xt分别对分子At和分母Bt更新如下:
(4a)
(4b)
其中η为学习率.(4)式是一个迭代过程,在滤波器更新时,最近几帧序列赋予了更多的权重,而先前帧权重则随时间按指数衰减.
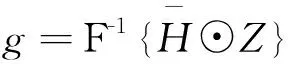
1.3 多通道相关滤波
为了将HOG、深度特征等应用到相关滤波器,需要将上述单通道相关滤波跟踪算法扩展到多通道.


(5)
可以得到h={h1,…,hD},★表示循环相关,λ为正则化参数.
上述(5)式为一个最小二乘问题,可通过Parseval公式[17]将其转换到频域求出其闭式解,但需计算MN个D×D的线性系统方程[18],计算开销很大.为求式(5)的近似解,本文采用与(4)式相似的在线更新策略.在第t帧,滤波器Ht的分子At和分母Bt分别用下式更新:
(6a)
(6b)
则每个通道所对应的的滤波器可以用一个逐元素相除求得:
(7)
第一帧的初始化滤波器则为上述t=1的情形:
(8)
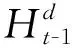
(9)
从(9)式可以看到,测试时,将样本每个通道所对应的滤波器与样本的相应通道逐元素相乘后求和得到响应图,再根据图中得分最大值确定目标位置.
1.4 算法实现过程
测试时,以上一帧目标位置pt-1为中心、以固定的目标尺寸P×Q为基准,对目标区域进行填充,补充目标背景信息,得到大小为M×N的图像块;对裁剪出的图像块提取特征、加hann窗作为测试样本zt;测试样本zt与前一帧滤波器ht-1求相关响应图,通过找到最大的相关得分定位目标的位置pt.
更新时,提取训练样本的方式与测试时类似,即在当前帧以预测的目标位置pt为中心、以固定的目标尺寸P×Q对目标区域填充裁剪,对裁剪的图像块提取特征、加hann窗作为训练样本xk;用训练样本xk与相应的标签函数yk更新相关滤波器.在第t帧的迭代过程如下:

算法流程:在第T帧的迭代过程输入:图像It,前一帧目标位置pt-1,相关滤波器Ht-1输出:估计的目标位置pt,更新后的相关滤波器Ht位置估计1:从图像It以位置pt-1和目标尺寸为基准对目标进行填充后获得采样区域2:对采样区域提取特征(灰度、HOG或深度特征)作为测试样本zt3:对测试样本zt和滤波器Ht-1用公式(9)计算相关响应gt4:通过找到gt中最大的相关值确定目标位置pt模型更新5:对图像It在位置pt处按与测试样本相同的方式提取训练样本xt6:使用训练样本xt和公式(6)和(7)计算相关域滤波器Ht
2 实验结果及讨论
本小节首先介绍实验平台及参数;随后设计了不同特征下相关滤波器的跟踪性能测试,并提出了一种融合不同层深度特征以提高跟踪精度的方法;最后将所提方法与近年来一些性能优异的算法进行了综合对比实验.测试序列均来自于OTB-2013[1]数据库,包含51个视频序列,评测时使用OPE[1]方法.为简化表达,以下将使用灰度特征、HOG特征的方法分别记为CFT_raw、CFT_HOG,对于使用卷积神经网络不同层特征的方法,从第零层到第五层分别记为DeepCFT_c0,DeepCFT_c1,DeepCFT_c2,DeepCFT_c3,DeepCFT_c4,DeepCFT_c5.
2.1 实验平台及参数
本文实验环境:CPU为Intel(R) Core(TM) i5-4590 @3.30GHz,内存为16GB,在Windows10操作系统下,采用MATLAB2016a编程实现本文算法.具体的参数设置如下:使用灰度特征时,padding=2.0,正则化系数λ=0.01,学习率η=0.0025,标记函数方差σ=1/12;使用HOG特征时,cell大小为4×4 Pixel,统计梯度方向数为9,学习率为0.0025;使用深度特征时,不同层的填充大小和学习率不一致,除第1层的填充为3,第0层到第5层的填充均为2,而第0,1,3,4层的学习率为0.0025,第2层的学习率为0.005,第5层的学习率为0.0065.
2.2 不同特征的效果比较
为比较不同特征在相关滤波框架下对跟踪性能的影响,分别使用灰度特征、HOG特征、深度特征作为样本训练相关滤波器.其中深度特征第0层即用视频序列RGB三个通道作为特征,若视频序列为灰度序列,则将灰度值复制3次分别作为RGB的3个通道.
为定量评判算法的跟踪性能,采用视觉目标跟踪领域通用的评价指标:跟踪成功率和跟踪精度[1].图2中精度图的排序标注值为中心位置误差为20 pixel时的跟踪精度,成功率图的排序标注值是曲线与坐标轴所围面积(AUC[1]).

图2 51个测试序列的精度曲线和成功率曲线Fig.2 The success plots and precision plots of 51 sequences
为更直观地显示不同特征之间的精度与成功率的差距,用柱形图分别画出中心误差在20 pixel时的精度分布和成功率AUC分布,如图3所示.
分析图2、图3,可以得到以下结论.
(1)所有基于多通道特征的方法均优于单通道特征方法CFT_raw;因此,多通道特征能够更好的表达目标外观特性.
(2)用深度特征训练的相关滤波器无论在精度还是在成功率上都比传统的手工特征具有较大优势.例如在图2(a)和图3(a)中,使用第5层深度特征的DeepCFT_c5的跟踪精度比灰度特征方法CFT_raw高29.9%,比RGB颜色特征方法DeepCFT_c0高23.5%,比HOG特征方法CTF_HOG高19.8%.
下面分析与讨论深度特征.
(1)从图3可知,当中心误差为20 pixel时,第5层卷积特征能够得到最好的精度与成功率;其次是1层特征,与第5层差距很小.从第1层到第4层,跟踪性能依次下降,这是因为随着神经网络层数加深,卷积特征图空间分辨率下降、纹理信息减少,不利于目标定位;但最后一层(第5层)是个例外,该卷积层特征是为识别任务而专门训练的,包含有完整的语义信息,具有很强的判别性.
(2)另一方面,图2(a)给出了不同中心误差(横坐标)下的精度曲线,当中心误差小于10 piexl时,用第1层、或者第2层深度特征获得的精度最高,这是因为CNN浅层特征图包含了更多的纹理信息、具有更高的空间分辨率,因此在更精确的定位场合(即中心误差更小)能够发挥更好的作用.
(3)同理从图2(b)中的成功率曲线可知,当重叠率大于0.7时,用第1层、或者第2层卷积特征得到的成功率高于第5层卷积特征,同样说明了CNN浅层特征在精确定位上的优势.
基于上述分析,本文提出分别提取第1层、第5层深度特征的相关响应图并做加权后作为最终响应图,以进一步提高目标定位精度,该方法简记为DeepCFT_c1+c5.经过多次实验,跟踪时第一层的学习率设为0.0025,第5层的学习率设为0.0065,填充设为3,对第1层、第5层对于的响应图权重分别为0.2、0.8.具体实验结果见下一小节.
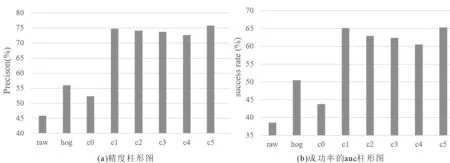
图3 51个测试序列的中心位置误差为20 pixel的精度柱形图和成功率的AUC柱形图Fig.3 The precision column chart with center position error of 20 pixel and the AUC column chart of success on 51 test sequences
2.3 综合对比实验
将所提方法与上一小节中的DeepCFT_c1、DeepCFT_c5,以及近年来一些主流算法进行了综合对比实验,包括:KCF[7],DSST[19],CNT[20],Struck[21],TLD[22],ASLA[23],ACFN-attNet[24].实验结果如图4所示.

图4 10个算法在51个测试序列的精度曲线和成功率曲线Fig.4 The success plots and precision plots of 51 sequences on 10 algorithms
由图4可以看出:
(1)融合了第1层、第5层深度特征的相关响应图后,本文方法得到的跟踪精度比使用单层深度特征的DeepCFT_c1、DeepCFT_c5方法分别高出4.7%、3.7%.由于该方法在目标定位时有效利用了最后一层特征的语义信息、以及第一层特征较高的空间分辨率和纹理信息,因此获得了较显著的性能提升.
(2)与近年来一些主流算法相比,本文方法在精度上排名第一,例如在中心误差为20 pixel时,精度比深度学习方法ACFN-attNet高0.1%,比经典核相关滤波方法KCF高5.5%,比尺度滤波方法DSST高5.5%;在中心误差大于15pixel时,本文算法精度一直保持最高,相对与其他算法来说优势较为明显.
(3)从图4(b)成功率曲线可知,本文使用响应图加权的方法在成功率上排第二,成功率比第一名的ACFN-attNet低2.19%;当重叠率低于0.5时,其性能和深度学习方法ACFN-attNet相近,且明显优于其他方法.
根据上述结果,综合考虑成功率和精度图,本文提出的响应图加权方法对跟踪性能的改善具有较显著的效果.
3 结语
目标外观模型的设计是基于相关滤波器的跟踪方法关键,本文简要介绍了相关滤波跟踪基本原理,包括单通道和多通道两种情况;研究了深度神经网络VGG-16不同卷积层特征的目标跟踪效果,并与传统手工特征进行了比较.实验和分析表明,深度特征相比于传统手工特征具有显著优势,而深度特征的第1层和第5层对跟踪性能的提升最显著.以此为依据,提出将不同深度特征层的相关响应图加权后再进行目标定位,实验结果表明该方法进一步改善了跟踪的精度和鲁棒性.本文工作对设计实际的视觉目标跟踪算法具有一定的参考价值.
参 考 文 献
[1] Wu Y, Lim J, Yang M H. Online ObjectTracking: A Benchmark[C]// IEEE. Conference on Computer Vision and Pattern Recognition. New Jersey: IEEE, 2013:2411-2418.
[2] Bolme D S, Beveridge J R, Draper B A, et al. Visual object tracking using adaptive correlation filters[C]// IEEE. Computer Vision and Pattern Recognition. New Jersey: IEEE, 2010:2544-2550.
[3] Danelljan M, Khan F S, Felsberg M, et al. Adaptive Color Attributes for Real-Time Visual Tracking[C]// IEEE. Conference on Computer Vision and Pattern Recognition. New Jersey: IEEE, 2014:1090-1097.
[4] Henriques J F, Caseiro R, Martins P, et al. Exploiting the circulant structure of tracking-by-detection with kernels[C]//Springer.European conference on computer vision. Berlin:Heidelberg, 2012: 702-715.
[5] 侯建华,边群星,项 俊.基于在线学习判别性外观模型的多目标跟踪算法[J].中南民族大学学报(自然科学版).2017,36(01):81-86.
[6] Xiang J, Sang N,Hou J, et al. Multitarget Tracking Using Hough Forest Random Field[J]. IEEE Transactions on Circuits & Systems for Video Technology.2016, 26(11):2028-2042.
[7] Henriques J F, Rui C, Martins P, et al. High-Speed Tracking with Kernelized Correlation Filters[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(3):583-596.
[8] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]// IEEE. Computer Vision and Pattern Recognition. New Jersey: IEEE, 2005:886-893.
[9] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// IEEE. Conference on Computer Vision and Pattern Recognition. New Jersey: IEEE,2014: 580-587.
[10] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classi- fication with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[11] Ahmed E,Jones M,Marks T K.An improved deep learning architecture for person re-identification[C]//IEEE. Computer Vision and Pattern Recognition. New Jersey: IEEE, 2015:3908-3916.
[12] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//IEEE. Computer Vision and Pattern Recognition. New Jersey: IEEE, 2016:770-778.
[13] Simonyan K,Zisserman A.Very deep convolutional net- works for large-scale image recognition[J]. CoRR, 2014, abs/1409.1556.
[14] Cimpoi M, Maji S, Vedaldi A. Deep filter banks for texture recognition and segmentation[C]// IEEE. Computer Vision and Pattern Recognition. New Jersey: IEEE, 2015:3828-3836.
[15] Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision. 2015, 115(3): 211-252.
[16] Chatfield K,Simonyan K, Vedaldi A, et al. Return of the devil in the details: Delving deep into convolutional nets[J]. CoRR, 2014, abs/1405.3531.
[17] Oppenheim Alan V,Willsky Alan S. HamidNawab S,等. 信号与系统[M]. 北京:电子工业出版社, 2013:192-193.
[18] Galoogahi H K, Sim T, Lucey S. Multi-channel correlation filters[C]// IEEE. International Conference on Computer Vision. New Jersey: IEEE, 2014:3072-3079.
[19] Danelljan M, Häger G, Khan F S. Accurate scale estimation for robust visual tracking[C]// British Machine Vision Conference. Nottingham, September 1-5, 2014. BMVA Press, 2014:65.1-65.11.
[20] Zhang K, Liu Q, Wu Y, et al. Robust Visual Tracking via Convolutional Networks WithoutTraining[J]. IEEE Transactions on Image Processing.2016, 25(4):1779-1792.
[21] Hare S,Golodetz S, Saffari A, et al. Struck: Structured output tracking with kernels[J]. IEEE transactions on pattern analysis and machine intelligence.2016, 38(10): 2096-2109.
[22] Kalal Z, Mikolajczyk K, Matas J. Tracking-Learning-Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence.2012, 34(7):1409-22.
[23] Lu H,Jia X, Yang M H. Visual tracking via adaptive structural local sparse appearance model[C]// IEEE. Conference on Computer Vision and Pattern Recognition. New Jersey: IEEE, 2012:1822-1829.
[24] Choi J, Chang H J, Yun S, et al. Attentional Correlation Filter Network for Adaptive Visual Tracking[C]// IEEE. Conference on Computer Vision and Pattern Recognition. New Jersey: IEEE, 2017:4828-4837.
猜你喜欢
天天爱科学(2022年9期)2022-09-15
当代水产(2022年6期)2022-06-29
中国生殖健康(2020年8期)2021-01-18
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
电子制作(2018年16期)2018-09-26
电子制作(2018年1期)2018-04-04
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年2期)2016-02-06
海军航空大学学报(2015年1期)2015-11-11
