
一种语义弱监督LDA的商品评论细粒度情感分析算法
2018-07-04 13:12:16万红新钟林辉
小型微型计算机系统 2018年5期
彭 云,万红新,钟林辉
1(江西师范大学 计算机信息工程学院,南昌 330022)2(江西科技师范大学 数学与计算机科学学院,南昌 330038)
1 引 言
情感分析(sentiment analysis),也叫观点挖掘(opinion mining),主要研究和分析人们对实体对象,如商品、服务、组织、个人、问题、事件和主题及其属性,所表达的观点、情感、评价和态度[1,2].商品评论的情感分析,主要有三个层面:① 文档级别的情感分析;② 句子级别的情感分析;③ 特征级别的情感分析.文档和句子级别的情感分析可以获取商品总体性的情感极性分类,即商品的总体评级(分)或粗粒度的商品评价;特征级别的情感分析是一种细粒度的情感分析,可以获取关于商品局部性的结构、属性和功能等方面的情感评价情况,更能满足用户了解商品细节方面评价的需求.要实现商品评论的细粒度情感分析,首先要有效提取商品特征和情感词,继而发现特征和情感词之间的关联关系.LDA(latent Dirichlet allocation)主题模型[3]具有文本降维和主题聚类功能,可以实现大规模商品评论数据的主题词提取,进一步发现特征词和情感词.但由于LDA是无监督的概率模型,偏向于发现以文档为单位的高频共现关系,很难发现低频及隐含在句式结构中的特征词和情感词,并且缺乏对词语关联和情感隶属等语义关系的理解,造成情感极性分类的准确性不高,具体表现如下:
1)难以提取无特征情感词.在中文商品评论中,经常会在单个句子中省去特征词而直接使用情感词,称之为无特征情感词,如句子“很清晰”“很便宜”中的“清晰”“便宜”,分别省去了特征词“屏幕”“价格”.LDA模型对无特征情感词进行主题分配时,由于特征词的缺失,可能会将这类情感词错误分配到其他频率较高的特征词所在的主题,从而影响此类情感词的提取效果.
2)难以发现次级特征词和低频情感词.次级特征词是描述局部特征词属性的更细粒度的词语,一般和局部特征词关联且词频远低于其关联的局部特征词,如“电池的续航力很强大”“屏幕灵敏度很高”“镜头有灰尘”中的“续航力”“灵敏度”“灰尘”.LDA模型往往难以发现这类频率较低且隐藏在句式结构中的次级特征词.在中文商品评论中,有些情感词只用来修饰某一个或某一类特征词,如“价格很公道”“色彩很鲜艳”中的“公道”“鲜艳”等.这类情感词词频相对于通用情感词要低很多,其和特征词的共现关系容易被其他高频情感词所湮没,使得LDA模型难以发现这类低频情感词.
3)高词频的全局特征词对局部特征词的分配产生干扰.全局特征词具有较高的词频,如相机评论中的“相机”“质量”等,标准LDA在主题词的概率分配过程中偏向于发现此类特征词,造成相对低频局部特征词的分配概率较低,如相机评论中的“屏幕”“价格”等.由于全局特征词具有较高的词频及文档频率,通常会以较高概率值分配到不同主题,而低频的局部特征词的分配概率值相对较低,从而影响了这一类特征词的提取率.
4)主题对情感的语义理解不明晰.LDA是词袋模型,对情感词词义、否定词和修饰程度副词缺乏语义理解能力,难以判断词语情感的极性及强弱,如“好”“坏”“非常好”“不坏”等.没有情感语义先验知识的引入,LDA难以识别这些情感词是正面、负面以及其情感强度.由于缺乏对情感词的语义理解,没有引入否定词和程度副词等语义关系,LDA仅从词语概率分布来识别情感词及情感极性,容易造成分布关系下主题情感分配的随机性,难以实现真实语义表达的情感极性分类.
2 相关研究
LDA是一种无监督概率生成模型,不需要进行人工数据标注,结构包括三层:文档、主题和词语,主要思想是:① 文档是主题的随机混合;② 主题是满足一定概率分布的词语组合.LDA将表达文本的词向量转化为主题向量,大大地降低了文本维度,同时在文本生成过程中可以提取主题词.由于LDA倾向于产生全局性的主题词,为了提取更多的局部主题词,许多研究对LDA主题模型进行了改进和扩展,加入先验知识,形成弱监督或半监督机制下的LDA主题模型.
一些研究利用改进的LDA主题模型进行特征词和情感词的提取.Titov等(2008)[4]将标准LDA模型扩展为多粒度主题模型(multi-grain LDA,MG-LDA),并假设全局主题倾向于捕获商品总体属性而局部主题倾向于捕获用户评价的商品特征,在此基础上对全局主题和局部主题两类不同类型的主题建模;Titov等(2008)[5]对MG-LDA模型进行了扩展,提出了MAS(multi-aspect sentiment)模型,使得MAS可以进行基于特征的细粒度主题建模;Moghaddam等(2011)[6]将评价文本分解为情感短语的形式,提出了ILDA(Interdependent LDA)模型,试图从情感短语中提取特征词及对应的情感词;Mukherjee等(2012)[7]提出的TME(topic and multi-expression)模型对评论中共现的各类情感短语和主题建模,并利用最大熵知识改善TME中的Beta先验分布的粗糙度和微弱性;Chen等(2014)[8]利用词语之间的must-links和cannot-links关系约束用来改善LDA提取特征词和情感词的效果,提出了AMC(automatically generated must-links and cannot-links)主题模型;彭云等(2015)[9]提出了词聚类LDA的商品特征词提取算法,利用词语的相似度和相关度来约束LDA的主题-词语分配,以提取更多的特征词.
一些研究将情感因素融入到LDA主题模型,在提取特征词和情感词的同时,实现情感的极性分类.Lin等(2009)[10]在原始LDA模型的基础上,加入了情感层并考虑每一个情感不同的特征分布,提出了JST( joint sentiment topic)模型用来同时识别主题和情感.JST模型采用预先定义的情感词集作为先验知识加入到LDA,在主题的后验分布的初始化中利用先验知识来决定词语的情感标签和所属主题.模型的先验知识忽略了特征词和情感词的关联性;Li等(2010)[11]也是在标准LDA模型中加入了情感层,提出了Sentiment-LDA模型,实现基于主题的情感分析;Jo等(2011)[12]假设一个句子仅有一个特征,且句子中的所有词语都由某一个特征来生成,首先提出了SLDA(sentence-LDA)模型,其主要任务是用来发现特征词.在此基础上提出了ASUM(aspect and sentiment unification model)模型,它是SLDA模型的扩展,将特征和情感合并同时进行建模,用来发现特征词-情感词匹配单元.由于没有特征词和情感词先验关联知识的引入,仅依赖LDA本身的先验分布难以识别一些句子级别的词语关系;孙艳等(2013)[13]考虑到有监督、半监督的评论文本数据集的标注工作量较大,且存在标注样本不容易获取的问题,提出一种无监督的主题情感混合模型 (unsupervised topic and sentiment unification,UTSU)模型,通过在标准LDA模型中融入情感来实现文档级别的情感分类;黄发良等(2016)[14]针对网络短文本情感挖掘问题,提出一种基于LDA和互联网短评行为理论相结合的主题情感混合模型TSCM(topic sentiment combining model).TSCM模型假设评论中每个句子的主题分布是不同的,产生词语的流程是先确定词语的情感极性,再确定词语的主题,并考虑了词语之间的关联关系;Lu等(2011)[15]提出了STM(sentiment topic model)模型,利用极少量先验知识(种子词形式)来加强主题和特征词的直接关联性;欧阳继红等(2015)[16]基于主题情感混合模型JST和R-JST(reverse joint sentiment topic model),考虑到整体分布与局部分布的关系会影响分类效果,提出了情感分析主题模型MG-JST(multi grain JST)和MG-R-JST(multi grain reverse JST);Poria等(2016)[17]为了有效实现特征级别的观点挖掘,将非结构化数据转化为结构化数据,对评价对象和评价极性的关联性进行建模.提出的Sentic LDA模型不仅仅关注词语共现频率,而且利用词语关联性和常识推理将标准LDA的主题聚类功能从语法级提升到语义级;熊蜀峰等(2016)[18]针对商品短评论中的文本稀疏问题,提出了一个短文本的联合情感-主题模型SSTM(Short-text sentiment-topic model)来解决稀疏性问题.不同于一般主题模型中通常采用的基于文档产生过程的建模方法,直接对整个语料集合的产生过程建模.在产生文档集的过程中,每次采样的一个词对中的词语具有相同的情感极性和主题.
通过对LDA主题模型方法的研究现状进行分析,可以发现LDA主题模型适于提取全局特征词和全局情感词,难以满足细粒度情感分析的要求.同时LDA是词袋型概率生成模型,缺乏语义理解能力使得提取的主题词往往难以满足情感分析的语义要求.本文将基于大数据背景下的中文商品评论文本的语法及语义结构特点,在保留LDA的大容量文本主题词提取功能的基础上,从语义约束角度对主题模型进行弱监督改造,提升LDA对中文商品评论文本的语义理解能力,使它能够按照预定语义目标进行主题词挖掘,实现商品评论的细粒度情感分析.
3 语义知识获取
3.1 词语关联知识
以句子为单位基于依存句法分析和词性分析来发现特征词和特征词、特征词和情感词之间的关联关系,并通过改进的PMI(pointwise mutual information)、词频关联等算法计算关联强度,最后利用这些关联关系和关联强度来影响LDA模型中词语的主题分配,以便发现更多的低频特征词、低频情感词及其关联关系.
3.1.1 无特征情感词的关联组合
1)构建候选关联组合集
利用依存句法关系发现句子中的典型特征词-情感词句法结构,并加以词性关系限制得到候选关联组合集,设置规则如下:
规则1.依存句法关系满足SBV,词性关系满足名词+形容词,其中的名词对应特征词,形容词对应情感词.

图1 例1的依存句法分析及词性标注Fig.1 Dependency parsing and POS tagging for example 1
例1.“这款相机非常不错.”“屏幕大而且像素很高.”2个句子的依存句法分析及词性标注如图1所示.其中,句1的关联组合单元为<相机,不错>,句2具有并列关系,关联组合单元为<屏幕,大>和<像素,高>.
通过规则1可以构建候选关联组合集Sca1,利用S-PMI(sentence PMI)计算Sca1中的元素
(1)
其中,fc(wi,wj)是词语wi和wj在句子中的共现频率,f(wi)是wi的词频,f(wj)是wj的词频.
2)捕捉缺省特征词
捕捉符合缺省特征词的句式结构,并提取其中的情感词,设置规则如下:
规则2.依存句法关系满足ADV或ADV+ADV,词性关系满足副词+形容词,其中的形容词可视为情感词.
例2.“很清晰.”“而且很便宜.”2个句子的依存句法分析及词性标注如图2所示.其中,句1中的情感词“清晰”、句2中的情感词“便宜”都缺省特征词.
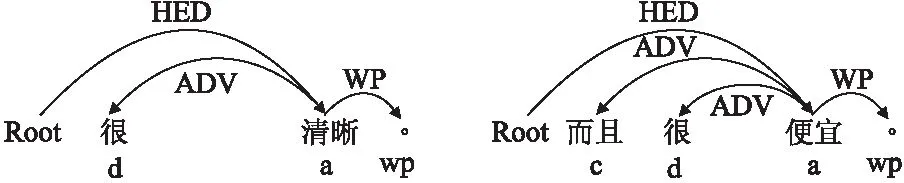
图2 例2的依存句法分析及词性标注Fig.2 Dependency parsing and POS tagging for example 2
对于满足规则2中缺省了特征词的情感词,在候选关联组合集Sca1中查找与其关联度值最大的特征词作为其关联特征词,归一化后构建缺省特征词-情感词集合Sdo.
3.1.2 低频情感词与特征词的关联组合
1)构建候选关联组合集
低频情感词和特征词的句式结构关系同样满足规则1,可以利用规则1提取的候选关联组合集Sca1,在此基础上计算关联度.
例3.“价格很公道;”“做工很精细.”2个句子的依存句法分析及词性标注如图3所示.其中,句1的关联组合单元为<价格,公道>,句2的关联组合单元为<做工,精细>.

图3 例3的依存句法分析及词性标注Fig.3 Dependency parsing and POS tagging for example 3
2)抽取局部特征词-低频情感词的关联集合
低频情感词一般只修饰比较固定的特征词,一些低频的情感词很难被LDA发现.为了提高低频情感词与其修饰的特征词的关联度,从词频比与共现频率差值进行分析,即不仅考察共现频率,而且考察相互的专有性,其关联度计算如式(2).
(2)
其中,ζ1是词频阈值,p′是候选关联组合中wi和wj的词频比,f′(wi)是wi词频与共现频率fc(wi,wj)的差值.
取关联度值大于一定阈值的关联组合并进行归一化后构成局部特征词-低频情感词集合Sao.
3.1.3 次级特征词与局部特征词的关联组合
1)构建候选关联组合集
提取符合次级特征词与局部特征词的基本句式结构,构建候选关联组合集Sca2,设置规则如下:
规则3.①依存句法关系满足ATT+SBV,ATT中词性关系满足名词+名词,前部名词对应局部特征词,后部名词对应次级特征词,SBV中词性关系满足名词+形容词;②依存句法关系满足SBV+VOB,词性关系满足名词+名词,前部名词对应局部特征词,后部名词对应次级特征词.
例4.“电池续航力很强大.”“镜头有灰尘.”2个句子的依存句法分析及词性标注如图4所示.其中,句1的关联组合单元为<电池,续航力>,句2的关联组合单元为<镜头,灰尘>.
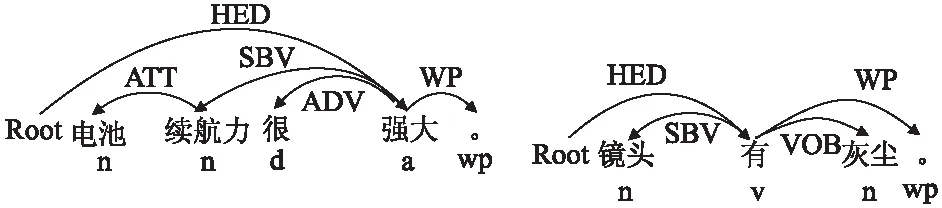
图4 例4的依存句法分析及词性标注Fig.4 Dependency parsing and POS tagging for example 4
2)抽取次级特征词与局部特征词的关联集合
为了区别于全局特征和局部特征的关系,如“相机的屏幕”等,在计算次级特征词与局部特征词的关联性时要满足一定的词频要求,即次级特征词的词频要低于某一阈值.由于次级特征词一般只与固定的局部特征词相关联,且和局部特征词的共现频率基本与本身词频相当,其关联度计算如式(3).
(3)
其中,ζ2是词频阈值,f′(wj)是wj词频与共现频率fc(wi,wj)的差值.
高于词频阈值ζ2的特征词,一般与全局特征词关联,通过LDA模型较容易发现,不属于次级特征词,如“相机的价格”中的“价格”不属于次级特征词,所以关联度置为0,即LDA模型无需利用这类词语间的关联性.
低于词频阈值ζ2的特征词为次级特征词,且关联度越高,则希望LDA模型将其和所关联的局部特征词分配到同一主题的概率越高.取关联度值大于一定阈值的关联组合并进行归一化后构成局部特征词-次级特征词集合Saa.
3.2 全局特征词的识别
全局特征词和全局情感词在句子中存在较明显的修饰关系,利用它们之间高频率的共现关系可以识别全局特征词.设置包含少量全局情感词的种子词集合Seedgo(w),从满足规则1的候选关联组合集中查找且满足一定共现频率阈值的特征词,并加入到全局特征词集合Sga(w);通过全局特征词又可以继续从候选关联组合集中查找满足规则1且满足一定共现频率阈值ζ3的情感词,并加入到全局情感词集合Sgo(w);经过不断反复迭代,直到没有新的全局特征词和全局情感词被发现,最终形成全局特征词集合Sga(w)和全局情感词集合Sgo(w).其迭代发现过程如图5所示.
3.3 主题的情感隶属
由于SWS-LDA增加了情感层,需要计算情感-主题概率分布.在主题分配到情感的计算中,因为吉布斯抽样难以反映情感的语义极性,所以采用模糊隶属度值来表示主题的情感归属度,从而实现主题的真实情感极性分配.

图5 全局特征词和全局情感词迭代过程Fig.5 Iterative process of global aspect words and global opinion words
3.3.1 发现情感关联词组
由于情感词经常会有程度副词和否定词进行修饰,如“价格很贵”“价格不贵”“价格不很贵”“屏幕很不清晰”等,导致同样的情感词,其所表达的情感极性和强度都有所差异.所以,首先利用句法分析发现情感词的关联词组,即不仅仅获取单个情感词,而是将否定词和程度副词也同时提取,这样才能获得较完整的情感语义.利用以下规则来发现情感词关联词组:
规则4.一个单句中满足SBV(主谓关系)+ ADV(状中结构)依存结构关系,或SBV(主谓关系)+ ADV(状中结构)+ ADV(状中结构)依存结构关系,对应的“副词(或否定副词‘不’)+ 形容词”,或“副词(或否定副词‘不’)+ 否定副词‘不’(或副词)+ 形容词”构成情感词关联词组,其中形容词为情感词.
根据规则4,从图6中可以识别出情感词关联词组“很贵”“不贵”“不很贵”“很不清晰”.

图6 词性标注和依存句法分析Fig.6 Dependency parsing and POS tagging for the examples
3.3.2 设计情感层的隶属函数
主题到情感层的隶属度由主题所包含的情感词来决定,主要考虑三个因素:1)正向情感词和负向情感词的数量比率;2)正向情感词和负向情感词的主题分配概率;3)情感词表达的强度,主要通过否定词和程度副词来反映,如“屏幕清晰”和“屏幕很清晰”、“价格很贵”和“价格不贵”等.
情感副词的强度值设置结合中文商品评论特点,按照语义表达程度将强度值置为4个级别,如表1所示.
文档和主题到情感层的模糊隶属函数设计如式(4)所示.
(4)
其中,


表1 程度副词及强度值Table 1 Adverb degree and intensity value

3.3.3 多极性决策二叉树的构造
设计多极性决策二叉树来决定主题的情感极性归属,并且极性的个数可以根据需要动态设置.通过多层次的极性评价,可以更细粒度的获取主题的情感强度,提供更细腻的情感分析.情感极性级数为n级的决策二叉树构造如图7所示.

图7 多极性决策二叉树Fig.7 Binary tree for multi polarity decision
在主题的情感极性模糊隶属计算基础上,可以将隶属度值进一步映射到决策树的多级极性区间,通过决策树判断主题的极性级别,映射公式如式(5).
(5)
其中,maxμk和minμk分别是最大μk(t)值和最小μk(t)值.
4 SWS-LDA模型设计
4.1 SWS-LDA约束机制
将特征词和情感词的关联关系、全局特征词和主题的情感模糊隶属语义约束加入到LDA,其约束机制的设计如下:
1)特征词和情感词的主题分配.在对词语w进行主题分配时,首先以句子为单位找到词语w前一位置相邻词语wp,然后判断
2)全局特征词的主题分配.对词语进行主题分配时,可先进行是否全局特征词的判断.如果是全局特征词,在计算其属于每个主题的抽样概率时,已有主题分配的全局特征词的个数对其分配到某个主题产生影响.如词语w是全局特征词,已有主题ti分配了n个全局特征词,主题tj分配了m个全局特征词,如果n>m,则词语w分配到主题ti的概率要大于tj.这样进行主题词分配,可以将全局特征词集中分配到少量主题下.
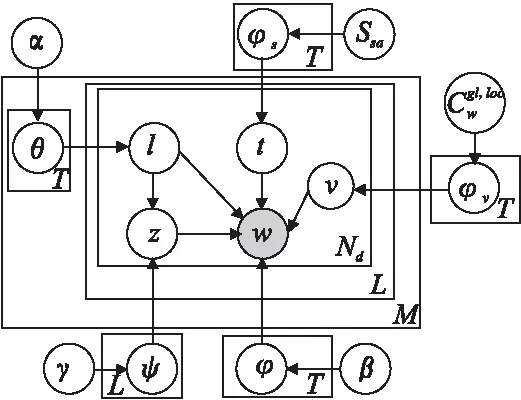
图8 SWS-LDA模型图Fig.8 SWS-LDA model
3)主题隶属于情感的语义关系约束.利用模糊隶属函数来计算主题的情感隶属度值,并利用决策二叉树来判断当前主题的情感极性.如主题t的情感隶属度值为0.54,则可以判断t的情感极性为IV级.
4.2 SWS-LDA结构设计
在LDA中加入情感层,并引入语义弱监督约束:词语关联、全局特征词和主题情感隶属,构建的SWS-LDA模型如图8所示,模型结构包括四层:文档层、情感层、主题层和词语层,图中的符号说明见表2.

表2 SWS-LDA模型符号说明Table 2 Notation of SWS-LDA
SWS-LDA模型的文档生成算法如表3所示.

表3 SWS-LDA文档生成算法Table 3 Text generation algorithm of SWS-LDA
4.3 SWS-LDA参数估计
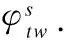
(6)
(7)
(8)
(9)
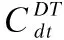
5 实验结果与分析
5.1 数据集选择及设置
数据采集于淘宝网(www.taobao.com)、天猫(www.tmall.com)和京东商城(www.jd.com)的商品评论数据,共采集了213 628篇“数码相机”评论文档.为了避免评论文档字数太少而影响可信度,剔除了少于50个字的评论文档,得到104 785篇评论文档,共包含679 213个句子.分词工具采用中科院ICTCLAS,依存句法分析采用哈工大LTP[19].进行实验效果比较的主题模型分别为SWS-LDA、JST[10]和ASUM[12],分词后保留词性为名词、动名词和形容词的文档为初始数据集,均采用Gibbs抽样进行参数估计.主题模型测试集和训练集评价文档数的比例设置为1:10.相关系数设置为:文档-主题概率分布参数α为50/K,K为主题个数,top-n取值为20(即在每个主题中取按概率降序排列的前top-n个词语作为主题词);主题-词语概率分布参数β为0.01,情感-主题概率分布参数γ为0.01;抽样次数为1 000次,采用10-fold交叉验证.
5.2 评价标准
采用人工方式标注数码相机评论数据中的特征词集、情感词集及关联组合集,其中特征词集元素个数为221,情感词集元素个数为196(其中正向情感词120个,负向情感词76个),关联组合集元素个数为395.以人工标注的数据作为基准对实验结果进行评价,采用准确率P(Precision)和召回率R(Recall)来评估不同模型的效果进行比较和分析.

(10)
(11)

(12)
(13)
召回率计算如式(14)所示,其中Ni@top-n是主题i下top-n个词语中提取的不重复的准确特征词、情感词或关联组合个数,Ns是人工标注的对应词语个数.
(14)
5.3 实验比较分析
5.3.1 特征词提取
特征词提取的准确率和召回率如图9和图10所示.其中,横坐标为主题个数K,纵坐标为准确率P或召回率R.

图9 特征词提取的准确率比较Fig.9 Precision comparison of aspect words extraction
从图9和图10可以看出,在主题数目大于等于80的时候,由于JST难以捕捉低频特征词,准确率值下降较快且明显低于SWS-LDA和ASUM;由于SWS-LDA加入了全局特征词分类的约束,在词语的主题分配中减少了全局特征词的干扰,所以在主题数增加过程中,SWS-LDA准确率值下降并不明显.

图10 特征词提取的召回率比较Fig.10 Recall comparison of aspect words extraction
从召回率值的变化来看,在主题数较高的时候,SWS-LDA的召回率具有较明显的优势,表明对低频特征词有较好的识别度,而其他模型难以进一步发现低频特征词.例如,SWS-LDA可以发现低频的次级特征词,如与局部特征词“屏幕”相关联的次级特征词“灵敏度”,从而提高了召回率.
5.3.2 情感词提取
情感词提取的准确率、召回率如图11和图12所示.其中,横坐标为主题个数K,纵坐标为准确率P或召回率R.

图11 情感词提取的准确率比较Fig.11 Precision comparison of opinion words extraction
从图11和图12可以看出,通过关联性可以提高低频情感词的分配概率,而对于关联于特征词的低频情感词发现具有较好效果.SWS-LDA的R值随着主题数的增加其上升趋势很迅速,也说明了一些低频情感词通过关联约束更好地匹配到了相对应的高频特征词,随着这类特征词的提取而提高了与其关联情感词的发现率.例如,一些低频情感词,如“公道”、“鲜艳”等,在ASUM和JST中没有发现,而在SWS-LDA模型中得以发现.
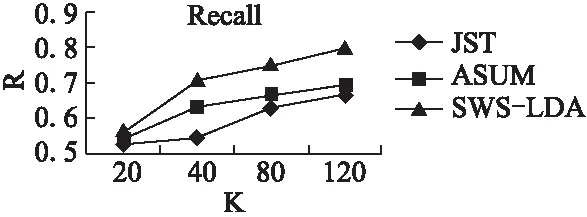
图12 情感词提取的召回率比较Fig.12 Recall comparison of opinion words extraction
5.3.3 关联组合提取
关联组合提取的准确率和召回率可以考察模型的聚合能力,即关联程度高的词语应尽量分配到同一主题.关联组合提取的P和R如图13和图14所示.其中,横坐标为主题个数K,纵坐标为准确率P或召回率R.
从图13和图14可以看出,在主题数较少的情况下,3个模型的准确率差别不明显,原因在于少量主题下分配概率高的都是高频的特征词和情感词.但随着主题数的增加,由于JST和ASUM的词语分配概率无法顾及中低频特征词和情感词的关联性,难以同时发现这类特征词和情感词,造成准确率值的下降幅度很明显.
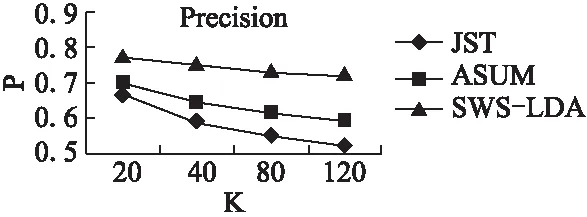
图13 关联组合提取的准确率比较Fig.13 Precision comparison of association groups extraction
从召回率看,JST倾向于发现高频共现词语,这就导致了分配概率较高的词语在各主题下重复性较高,而使得召回率低下.ASUM虽然加入了情感层和种子情感词先验,但一个句子一个特征词的假设限制了发现并列句等复杂句式的特征词和情感词关联性,随着主题数的增加,召回率慢慢趋向于平稳而难以明显提高.SWS-LDA模型的关联性约束使得更有利于发现低频共现的特征词和情感词的关联性,所以随着主题数的增加,其召回率呈不断增加的趋势.例如,对于ASUM和JST模型难以发现的一些低频关联组合,如<价格,公道>等,SWS-LDA模型可以将其分配到同一主题.

图14 关联组合提取的召回率比较Fig.14 Recall comparison of association groups extraction
5.3.4 主题情感极性分类的准确率
主题情感极性分类的准确率如图15所示,其中横坐标为主题个数K,纵坐标为准确率P.

图15 主题情感极性分类的准确率比较Fig.15 Precision comparison of sentiment polarity classification
从图15可以看出,由于SWS-LDA的主题和一类特征具有对应性,且通过特征-情感词的语义约束可以提取更多的特征-情感匹配关系,有利于基于主题进行准确情感分类,如“价位很实惠”“外观很霸气”等一些低频共现匹配关系的识别,JST和ASUM很难识别此类关系;而“价格低,屏幕很清晰,操控很方便”中的<价格,清晰>、<屏幕,低>、<操控,清晰>等非匹配关系由于在同一评论文档中具有一定共现性,容易被JST和ASUM错误识别为匹配关系,从而降低了主题对于情感识别的准确性.由于加入了主题-情感隶属影响,在SWS-LDA引入模糊情感决策约束机制,更能真实反映主题的情感取值,相对于JST和ASUM的情感概率分配的随机性来说更具有优势.
6 结束语
由于LDA主题模型可以从大规模的文本数据中提取主题词,并通过主题聚类发现潜在的特征词和情感词之间的关系,许多研究利用LDA模型实现基于主题的情感分析.但由于LDA模型语义理解能力的不足,同时偏向于提取粗粒度的特征词和情感词,往往不能满足细粒度情感分析的语义要求,尤其是面向具有复杂语法及语义结构的中文商品评论.
本文根据中文商品评论的特点,充分考虑LDA主题模型文档-主题-词语的概率分配机制的基础上,定义了三类语义约束并进行语义获取,包括:词语语义关联、全局特征词识别和主题情感隶属.其中词语间的语义关联约束可以提升中低频特征词和情感词的识别度,全局特征词的识别可以提高特征词的主题内聚度,主题情感隶属可以更准确地描述主题的情感极性归属.将获取的语义约束作为先验知识引入LDA,指导其进行主题-词语和主题-情感分配,将无监督的LDA转变为弱监督形式,可以提取更符合语义要求的特征词和情感词.实验结果表明,提出的SWS-LDA模型在特征词、情感词及其关联关系的提取中具有较高的准确率和召回率,其细粒度情感极性分类的准确性也得到了较大程度的提升.
:
[1] Pang B,Lee L.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1-2):1-135.
[2] Liu B.Sentiment analysis and opinion mining[M].California,USA:Morgan & Claypool Publishers,2012.
[3] Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3(3):993-1022.
[4] Titov I,McDonald R T.Modeling online reviews with multi-grain topic models[C].Proceedings of the 17th International Conference on World Wide Web (WWW),2008:111-120.
[5] Titov I,McDonald R T.A joint model of text and aspect ratings for sentiment summarization[C].Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics (ACL),2008:308-316.
[6] Moghaddam S,Ester M.ILDA:Interdependent LDA model for learning latent aspects and their ratings from online product reviews[C].Proceedings of the 34th International Conference on Research and Development in Information Retrieval (SIGIR),2011:665-674.
[7] Mukherjee A,Liu B.Modeling review comments[C].Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL),2012:320-329.
[8] Chen Z Y,Liu B.Mining topics in documents:standing on the shoulders of big data[C].Proceedings of the 20th International Conference on Knowledge Discovery and Data Mining (SIGKDD),2014:1116-1125.
[9] Peng Yun,Wan Chang-xuan,Jiang Teng-jiao,et al.An algorithm based on words clustering LDA for product aspects extraction[J].Journal of Chinese Computer Systems,2015,36(7):1458-1463.
[10] Lin C,He Y.Joint sentiment/topic model for sentiment analysis[C].Proceedings of the 18th ACM Conference on Information and Knowledge Management (CIKM),2009:375-384.
[11] Li F T,Huang M L,Zhu X Y.Sentiment analysis with global topics and local dependency[C].Proceedings of the 24th Conference on Artificial Intelligence (AAAI),2010:1371-1376.
[12] Jo Y,Oh A H.Aspect and sentiment unification model for online review analysis[C].Proceedings of the 4th ACM International Conference on Web Search and Data Mining (WSDM),2011:815-824.
[13] Sun Yan,Zhou Xue-guang,Fu Wei.Unsupervised topic and sentiment unification model for sentiment analysis[J].Acta Scientiarum Naturalium Universitatis Pekinensis,2013,49(1):102-108.
[14] Huang Fa-liang,Li Chao-xiong,Yuan Chang-an,et al.Mining sentiment for web short texts based on TSCM model[J].Acta Electronica Sinica,2016,44(8):1887-1891.
[15] Lu B,Ott M,Cardie C,et al.Multi-aspect sentiment analysis with topic models[C].Proceedings of the 11th IEEE International Conference on Data Mining (ICDM),2011:81-88.
[16] Ouyang Ji-hong,Liu Yan-hui,Li Xi-ming,et al.Multi-grain sentiment/topic model based on LDA[J].Acta Electronica Sinica,2015,43(9):1875-1880.
[17] Poria S,Chaturvedi I,Cambria E,et al.Sentic LDA:Improving on LDA with semantic similarity for aspect-based sentiment analysis[C].Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN),2016:4465-4473.
[18] Xiong Shu-feng,Ji Dong-hong.A short text sentiment-topic model for product review analysis[J].Acta Automatica Sinica,2016,42(8):1227-1237.
[19] Che W X,Li Z H,Liu T.LTP:A Chinese language technology platform[C].Proceedings of the 23rd International Conference on Computational Linguistics (COLING),2010:13-16.
附中文参考文献:
[9] 彭 云,万常选,江腾蛟,等.一种词聚类LDA的商品特征提取算法[J].小型微型计算机系统,2015,36(7):1458-1463.
[13] 孙 艳,周学广,付 伟.基于主题情感混合模型的无监督文本情感分析[J].北京大学学报(自然科学版),2013,49(1):102-108.
[14] 黄发良,李超雄,元昌安,等.基于TSCM模型的网络短文本情感挖掘[J].电子学报,2016,44(8):1887-1891.
[16] 欧阳继红,刘燕辉,李熙铭,等.基于LDA的多粒度主题情感混合模型[J].电子学报,2015,43(9):1875-1880.
[18] 熊蜀峰,姬东鸿.面向产品评论分析的短文本情感主题模型[J].自动化学报,2016,42(8):1227-1237.
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
时代英语·高一(2019年5期)2019-09-03 02:09:34
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
读者·校园版(2015年7期)2015-05-14 13:11:40
中文信息学报(2015年4期)2015-04-21 08:29:12
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
