
一种超椭球免疫理论启发的shellcode检测算法
2018-07-04 10:31芦天亮蔡满春杜彦辉刘颖卿
小型微型计算机系统 2018年6期
芦天亮,张 璐,蔡满春,杜彦辉,刘颖卿
1(中国人民公安大学 网络空间安全与法治协同创新中心,北京 100038)
2(中国人民公安大学 信息技术与网络安全学院,北京 100038)
3(中国移动通信有限公司研究院,北京 100053)
1 引 言
shellcode是由攻击者精心编写的一段可执行的二进制指令代码,一般以网络流量等数据形式发送到存在缓冲区溢出漏洞的目标服务器,通过覆盖返回地址获得执行权限,通常是开放远程shell端口.shellcode编写对于攻击者技术水平要求较高,需熟练掌握汇编指令,函数调用及进程内存堆栈结构.但随着Metasploit等渗透测试工具的出现,shellcode可以根据用户需求直接定制生成,并且可以进行编码以躲避非法字符或特征码检测.根据检测过程中是否执行shellcode,将检测手段分为静态检测和动态检测.
静态检测基于反汇编和特征码匹配等手段,基于特征码匹配的检测,对于已知shellcode样本非常有效,但对于未知的或经过多态编码的shellcode检测效果很差.为躲避特征码检测手段,alphanumeric全字母数字编码shellcode方法被提出,并采用压缩方法使其长度更短[1].Verma N等[2]提出了基于字符串相似度的alphanumeric shellcode检测方法.Zhao Ziming等[3]提出基于反汇编指令序列抽取shellcode特征的方法,利用Markov链实现shellcode检测和基于支持向量机识别shellcode的编码类型.
动态检测是对shellcode模拟执行过程中的行为,包括系统调用、内存读写等进行监控,基于行为特征对shellcode检测.shellcode检测库Libemu可以集成到入侵检测系统或蜜罐中,能够对内存和CPU进行模拟得到指令执行流程.Polychronakis M等[4]提出在网络入侵检测系统中嵌入CPU模拟器,基于自修改shellcode解码过程中频繁对自身内存读写特征进行检测.董鹏程等[5]提取shellcode动态执行特征,基于自动机模型实现检测算法,通过分析API调用序列判定shellcode执行功能和攻击意图.Gu Boxuan等[6]提出基于内存快照的shellcode检测方法,利用数据输入前的进程快照模拟执行并监控系统调用和程序执行流程.
为了有效的检测shellcode,尤其是对多态样本准确快速识别,受生物免疫系统识别和消灭入侵人体病原体机理的启发,本文创新的将免疫理论应用于解决shellcode检测问题,提出了一种基于免疫理论的静态分析和动态分析相结合的shellcode检测算法.检测器采用超椭球编码方式提高非我空间覆盖率以获得更好的检测效果.
2 人工免疫系统相关基础
生物免疫系统能够对入侵人体的细菌、病毒等非我物质精准识别和消灭,是保证人体健康的关键.免疫系统是具有自组织、学习记忆和分布式等特征的复杂自适应系统.基于生物免疫系统的研究成果,多类人工免疫算法被提出,不断完善并应用于多个工程领域,主流的免疫算法包括:免疫网络、阴性选择算法、克隆选择算法和危险理论等.
鉴于识别有害物质的天然相似性,人工免疫系统被用于解决信息安全领域的多个问题[7],包括恶意代码检测[8]、入侵检测[9]、垃圾邮件检测[10]等.本文将人工免疫理论应用于shellcode的检测问题.
2.1 阴性选择算法
免疫系统需要准确区分自我物质和非我物质,这样才能保证在不破坏自身机体的前提下识别和消除病毒等抗原.为避免自身免疫疾病出现,未成熟T细胞在胸腺中经历耐受过程,只有不与自身蛋白质匹配的才可成熟并释放到体液中,否则在胸腺中被消灭.
Forrest S等[11]模拟生物免疫耐受过程,提出了阴性选择算法,包含检测器生成和检测两个环节.
1) 生成检测器:随机产生的不匹配任何自我元素的字符串构成集合D;
2) 检测过程:用集合D中元素测试待检字符串,若匹配则为非我有害数据.
最初的阴性选择算法采用二进制字符串编码,基于r连续位匹配.之后提出实值向量编码方式,可利用计算几何特性加快算法速度.Gonzalez F等[12]将检测器定义为以n维实值向量为中心,半径r固定的超球体.为减少检测器数量,Zhou J等[13]提出改进的半径可变超球体模型.Joseph M等[14]提出超椭球模型,通过伸展半轴使检测器更加灵活.Joseph M指出,只需一半数目的超椭球检测器即可达到超球体同样效果的非我空间覆盖.因此为了提高检测器集合对非我空间覆盖率,本文采用超椭球形式对shellcode检测器编码.
2.2 克隆选择算法
克隆选择理论揭示了生物免疫系统对抗原的强化学习过程.当细菌或病毒等抗原入侵人体后,能与抗原结合的淋巴细胞会大量繁殖并高频变异,不断提高与抗原的亲和度.淋巴细胞的多样性依赖于细胞的高频变异,主要通过随机位置的基因修改实现,优秀的克隆后代会被保存下来.当相同抗原再次入侵时,记忆B淋巴细胞能够快速响应保障人体健康.
基于上述原理,De Castro等[15]将克隆选择理论引入到信息计算领域,并应用于模式识别和旅行商等多类工程问题.本文利用克隆选择算法通过对超椭球检测器遗传变异,获得性能更优的检测器后代,提高对shellcode的识别效果.
3 shellcode特征提取与编码
提取shellcode样本特征,包括基于静态反汇编技术获得指令助记符序列和基于动态模拟执行技术获得API函数调用序列.基于n-gram模型对上述两类序列分解成n长度的序列片段.基于信息熵对n-gram片段进行筛选,选择对shellcode判定贡献较大的n-gram片段组成特征集合.静态和动态特征提取过程如图1所示.
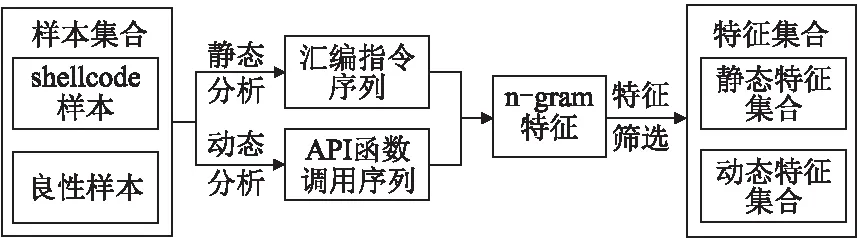
图1 静态和动态特征提取Fig.1 Static and dynamic features extraction
3.1 静态分析技术
反汇编技术在病毒特征码提取和软件解密等方面应用较多.汇编指令携带了shellcode恶意操作的关键信息,利用反汇编技术将二进制shellcode转换为汇编语言.反汇编算法包括线性扫描和递归下降,反汇编软件有IDA、W32Dasm和C32Asm等.
3.2 动态分析技术
动态分析是检测多态shellcode最有效的手段.无论shellcode如何变形或加密,最终在执行过程中都会调用系统API函数来完成特定功能.shellcode实现的功能主要有开放shell端口、下载文件并执行、主动连接控制服务器等.通过挂钩技术可以监控shellcode调用API函数的过程,并可获得输入参数和返回值等信息.工具scdbg利用挂钩技术HOOK多达200多个API,通过模拟可获得API函数调用序列,包括网络操作、文件操作、进线程操作和动态库加载等敏感行为.
3.3 基于n-gram语言模型的特征提取
n-gram代表连续n个单词构成的序列,是自然语言处理中词汇识别常用的统计模型.本文中将n-gram模型用于汇编语言指令序列和API函数调用序列特征提取,把汇编指令助记符和API函数名看成是n-gram模型中的单词.将大量shellcode样本和良性样本静态分析和动态分析获得的序列用于训练语料库,可以统计获得n-gram特征频度信息,并作为后续学习的特征.
对汇编指令序列提取静态n-gram特征,该特征代表了汇编指令助记符局部语义顺序.同理,对于API函数调用序列提取动态n-gram特征,该特征代表了shellcode执行时API函数调用的局部语义顺序.
3.4 基于信息熵的特征筛选
静态反汇编和模拟执行后,从shellcode样本中提取的某些n-gram特征可能会出现在良性样本中.为了保证筛选出的特征对shellcode识别更有价值,采用基于信息熵的特征筛选方法,通过计算每个n-gram特征对shellcode判定的信息增益,筛选出贡献程度更高的特征.
随机变量X的熵值H(X)计算如下:
(1)
其中,X取值1或0,1表示shellcode样本,0表示良性样本.p(X=ai)是随机变量X=ai的概率.
定义随机变量Y,Y取值1或0,1表示样本中含有特征f,0表示样本中不含有特征f.已知变量Y的取值情况下,X的条件熵计算如下:
(2)
知道Y的取值后对判断X的值提供的信息量定义为信息增益IG,计算公式如下:
IG(X|Y)=H(X|Y)-H(X)
(3)
IG值越大表明特征f对于区分shellcode和良性样本的贡献价值越大,即能更好判定样本是否为shellcode.计算所有n-gram特征的IG值,选择前N个特征组成特征集合F={f1,f2,…,fN}.
采用统一的格式化数据对样本的特征进行实值编码,编码的特征向量为p=(p1,p2,…,pN).每个样本对应一个特征向量,特征向量第i维的取值pi代表特征集合F中特征fi在该样本的出现的次数.
4 基于免疫理论的shellcode检测算法
4.1 超椭球检测器定义
n维超椭球定义如下:
(x-ω)TΑ(x-ω)=1
(4)
其中,Α是n阶实对称正定矩阵,ω是超椭球的中心.
超球体在n个正交半轴方向上进行拉伸可以生成n维超椭球.超椭球检测器的体积V代表可覆盖的非我空间的大小.
V=Ωnl1l2…ln
(5)
其中,l1,l2,…,ln是超椭球n个半轴,Ωn是n维超球体的体积.
(6)
正定矩阵Α可分解成Α=VΛVT,Α的正交特征向量是矩阵V的列.Λ的对角元素是与V的特征向量相关的特征值.
(x-ω)TVΛVT(x-ω)=1
(7)
Λ的对角元素Λi,i(1≤i≤n)与超椭球半轴li的关系如下:
(8)
公式(9)用于判断一个样本特征p是否在超椭球检测器d的覆盖范围内.如果小于1,则p落在d的范围内;如果等于1,则p位于d的球体表面;如果大于1,则p不在d的检测范围内.
(p-ω)TΑ(p-ω)<1
(9)
如果待检样本的特征向量p落在成熟检测器d的超椭球内部,则判定为shellcode代码.
4.2 基于免疫理论的shellcode检测模型
基于免疫理论的shellcode检测模型包括检测器生成和shellcode检测两个阶段,如图2所示.
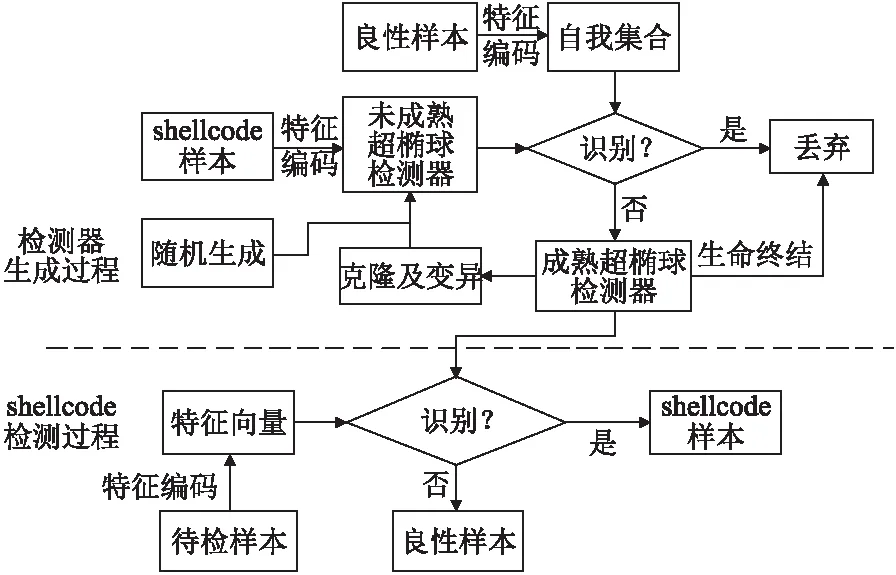
图2 基于免疫理论的shellcode检测模型Fig.2 Shellcode detection model based on immune theory
良性样本经过特征提取和编码后构成自我元素集合,未成熟检测器来源包括shellcode特征编码、随机生成和克隆变异.基于阴性选择算法判断未成熟超椭球检测器是否会识别自我元素,通过免疫耐受检验的成为成熟超椭球检测器.对成熟检测器克隆和变异,生成更加优秀的后代.
4.3 基于阴性选择算法的检测器生成
检测器集合为D={d1,d2,…,dNd},检测器总数为Nd.自我元素集合定义为S={s1,s2,…,sNs},集合中自我元素总数为Ns.在阴性选择算法的免疫耐受环节,如果未成熟超椭球检测器覆盖了自我元素则会被淘汰,只有经过自我集合S中所有元素的检验才会成熟,加入到成熟检测器集合D中.
4.4 基于克隆变异的检测器优化
免疫系统具有强化学习的能力,为了提高超椭球检测器的性能,即在同等数目的情况下,通过对其几何形状的优化调整,使得检测器集合对非我空间的覆盖率更高.本文对亲和度高的检测器进行克隆,然后利用变异手段生成更加优秀的超椭球检测器后代,提高shellcode检测效果.
4.4.1 克隆选择算法
优化检测器,使其覆盖更多的非我空间,同时降低与其他检测器的重叠.克隆后代数目Num(d)与亲和度affinity(d)成正比,α为克隆系数,计算公式如下.
Num(d)=α*affinity(d)
(10)
检测器d的亲和度affinity(d)计算公式如下.
affinity(d)=eN(d,A)-c*O(d,D)
(11)
其中,A为非我空间的抗原集合,D为检测器集合.N(d,A)代表检测器d覆盖的非我抗原数目,O(d,D)代表检测器d与其他检测器重叠空间,c为重叠惩罚因子.
利用2n叉树对超椭球重叠空间进行近似计算.定义树的深度为k,则2n叉树可将n维空间分割成2nk个超矩形.对检测器集合D中超椭球覆盖的超矩形进行计算,得出检测器d的重叠空间O(d,D).
4.4.2 超椭球检测器遗传变异
借鉴生物系统遗传变异的原理,为了生成更高亲和度的检测器,对检测器克隆后代进行变异.对超椭球检测器的遗传变异满足两个原则:
1)经过有限的变异操作,可生成其他任意形状的超椭球;
2)变异是随机的,但变异后的超椭球与变异前的距离不能太远.
主流的变异策略有:高斯变异、柯西变异和非均匀变异等,本文采用高斯变异.超椭球变异操作主要有三种方式:改变朝向、迁移中心和伸缩半轴.
1)改变朝向
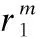
(12)
经过多次的上述二维空间的旋转可以实现超椭球d在n维空间的转向.旋转后的超球体dm分布在原超球体d的方向附近的概率更大.
2) 迁移中心
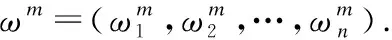
3)伸缩半轴
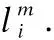
4.5 shellcode判定
shellcode检测过程如图2所示,提取待检测样本的反汇编指令序列和API函数调用序列,分片为n-gram特征,基于特征集合F={f1,f2,…,fN}计算每个样本特征值,生成待检测样本的特征向量p=(p1,p2,…,pN).
样本特征p依次与成熟检测器集合中元素匹配.如果(p-ω)TΑ(p-ω)<1,则p落在超椭球检测器d的覆盖范围内,样本被检测器d检测,判定为shellcode样本.如果通过所有检测器的检测均未识别,则判定为良性样本.
5 实验验证
5.1 样本收集
实验过程中,我们从Metasploit和exploit-db等渠道收集并提取了非编码shellcode样本共500个.良性样本共收集500个,主要来源是exe和dll等可执行文件代码片段以及http等协议网络流量片段,长度在50-300字节之间.
使用多态引擎对shellcode编码,包括Clet,ADMmuate,Jempiscodes,TAPioN以及利用Metasploit中msfvenom命令调用编码引擎Alpha2,Countdown,JmpcCallAdditive,Pex,Call4_dword_xor和Shikata_ga_nai等生成多态shellcode样本.
5.2 实验及分析
在shellcode静态和动态特征提取方面,本文基于capstone反汇编框架对shellcode样本进行线性反汇编并获取指令序列,利用scdbg工具对shellcode样本模拟执行后获得API函数调用序列.基于matlab软件完成n-gram特征提取和特征向量计算,实现人工免疫过程包括检测器生成和克隆变异等算法.
5.2.1 超椭球检测器编码方式优势分析
将收集到shellcode样本和良性样本按照3:2的比例分成免疫训练集合与免疫测试集合.利用训练集合中的良性样本生成自我元素集合,提取训练集合中的shellcode样本特征作为未成熟检测器来源之一.
对比r固定超球体、r可变超球体和超椭球编码,r固定超球体采用迁移中心的变异策略,r可变超球体采用迁移中心和调整半径的变异策略,超椭球采用迁移中心、改变朝向和伸缩半轴的变异策略.下面对比三种检测器编码方式在对非我空间覆盖率即检测效果方面的优劣.取相同的遗传变异代数T=100,对比检测器数目Nd一样时,三类编码检测器对shellcode的检测效果.

图3 不同编码方式检测率对比Fig.3 Detection rate of different coding
如图3所示,超椭球检测器的检测率最高,其次是半径可变超球体,半径固定超球体检测效果最差.当检测器数目较少时(Nd=200和Nd=400),三者之间的检测率差距较大,因为超椭球检测器数目较少时仍能通过伸缩半轴和改变朝向等方式实现非我空间的有效覆盖.检测器数目Nd较多时(Nd=1000和Nd=1200),三类检测器的检测效果趋于接近,说明当检测器数目足够多时均能对非我空间实现较充分的覆盖.
5.2.2 误报率分析
收集的良性样本包括网络流量片段和可执行文件片段,采用10次10折交叉验证方法,将数据集分成10份,轮流将其中9份作为训练样本集,1份作为测试样本集,重复10次,这两类良性样本的误报率结果如图4所示.
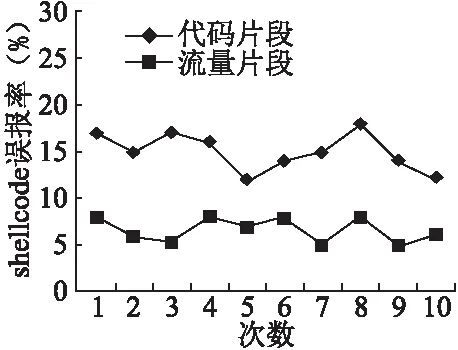
图4 误报率Fig.4 False positive rate
流量片段的误报率明显小于代码片段,这是由于exe或dll等可执行文件的代码片段包含汇编指令,并且调用的API函数也可能包括连接网络、文件操作和启动程序等功能,造成该类良性样本提取的特征向量与shellcode提取的特征向量比较接近,因此误报率相对较高.
5.2.3 多态shellcode检测效果
对免疫测试集合中的200个shellcode样本分别使用5.1节中的10类编码引擎处理,共生成2000个多态shellcode样本.训练集合仍使用非编码shellcode样本.下面分析本文所提出的AIS-SDA检测算法与反汇编静态分析方法和API调用序列动态分析方法进行比较,测试结果如表1和表2所示.

表1 非编码shellcode检测效果Table 1 Detection performance for non-encoded shellcode
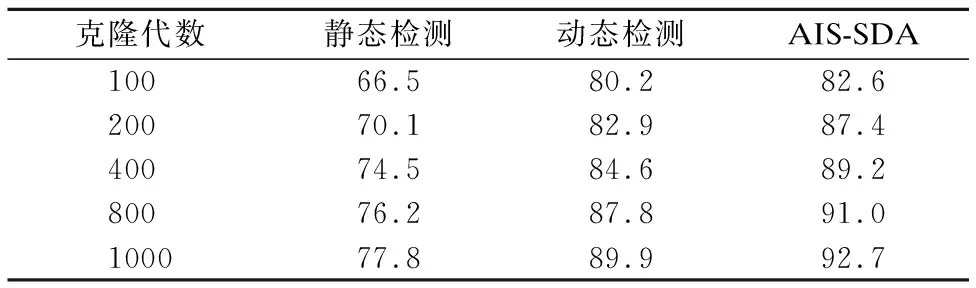
表2 多态shellcode检测效果Table 2 Detection performance for polymorphic shellcode
6 总 结
shellcode检测是基于漏洞攻击的网络对抗中迫切需要解决的关键安全问题.目前杀毒软件和入侵检测系统均嵌入了shellcode检测功能,能够在漏洞渗透过程中对攻击流量或恶意文件进行拦截.但是对于自修改的多态shellcode,由于隐藏了静态特征码,该类安全产品检测率较低.为了解决不断翻新的多态shellcode,受到生物免疫系统准确识别入侵病毒的机理启发,本文提出了基于动态分析和静态分析相结合的shellcode免疫检测算法,实验结果表明所提算法具有较好的检测效果.
:
[1] Basu A,Mathuria A,Chowdary N.Automatic generation of compact alphanumeric shellcodes for X86[M].Information System Security,Berlin:Springer,2014:399-410.
[2] Verma N,Mishra V,Singh V P.Detection of alphanumeric shellcodes using similarity index[C].Proc of 2014 International Conference on Advances in Computing,Communications and Informatics,2014:1573-1577.
[3] Zhao Zi-ming,Ahn Gail-Joon.Using instruction sequence abstraction for shellcode detection and attribution[C].Proc of 2013 IEEE Conference on Communications and Network Security,2013:323-331.
[4] Polychronakis M,Anagnostakis K G,Markatos E P.Network-level polymorphic shellcode detection using emulation[J].Journal in Computer Virology,2006,4064(4):54-73.
[5] Dong Peng-cheng,Kang Fei,Shu Hui.A dynamic method for detecting and analysising of shellcode[J].Journal of Chinese Computer Systems,2013,34(7):1644-1649.
[6] Gu Bo-xuan,Bai Xiao-le,Yang Zhi-min,et al.Malicious shellcode detection with virtual memory snapshots[C].Proc of the 29th Conference on Information Communications,2010:974-982.
[7] Tan Ying.Artificial immune system:applications in computer security[M].Hoboken,NJ:Wiley-IEEE Computer Society Press,2016.
[8] Brown J,Anwar M,Dozier G.Detection of mobile malware:an artificial immunity approach[C].Proc of 2016 IEEE Symposium on Security & Privacy,2016:74-80.
[9] Rathee G,Bano P,Singh S.Artificial immune system based statistical model for intrusion identification[J].International Journal of Computer Science and Mobile Computing,2015,4(6):170-176.
[10] Idris I,Selamat A,Omatu S.Hybrid email spam detection model with negative selection algorithm and differential evolution[J].Engineering Applications of Artificial Intelligence,2014,28(2):97-110.
[11] Forrest S,Perelson A S,Allen L,et al.Self-nonself discrimination in a computer[C].Proc of 1994 IEEE Symposium on Research in Security and Privacy,1994:202-212.
[12] Gonzalez F,Dasgupta D.Anomaly detection using real-valued negative selection[J].Genetic Programming and Evolvable Machines,2003,4(4):383-403.
[13] Zhou J,Dasgupta D.Real-valued negative selection algorithm with variable-sized detectors[C].Proc of Genetic and Evolutionary Computation-GECCO,2004:287-298.
[14] Shapiro J M,Lamont G B,Peterson G L.An evolutionary algorithm to generate hyper-ellipsoid detectors for negative selection[C].Proc of the 7th Annual Conference on Genetic and Evolutionary Computation,2005:337-344.
[15] De Castro L N,Von Zuben F J.Learning and optimization using the clonal selection principle[J].IEEE Transactions on Evolutionary Computation,2002,6(3):239-251.
附中文参考文献:
[5] 董鹏程,康 绯,舒 辉.一种shellcode动态检测与分析技术[J].小型微型计算机系统,2013,34(7):1644-1649.
猜你喜欢
导航定位学报(2022年2期)2022-04-11
雷达科学与技术(2021年5期)2021-11-29
智能制造(2021年4期)2021-11-04
矿山测量(2021年4期)2021-09-18
商品与质量(2020年18期)2020-11-27
支部建设(2020年15期)2020-07-08
北京航空航天大学学报(2017年3期)2017-11-23
百科知识(2015年18期)2015-09-10
小星星·阅读100分(高年级)(2015年4期)2015-05-26
