
基于机器学习的多地震属性沉积相分析
2018-07-02 08:39张春雷成育红高世臣黄文辉
特种油气藏 2018年3期
张 艳,张春雷,成育红,高世臣,黄文辉
(1.中国地质大学(北京),北京 100083;2.北京中地润德石油科技有限公司,北京 100083;3.中国石油长庆油田分公司,陕西 西安 710016)
0 引 言
沉积相揭示了目的层段的沉积环境及其分布规律,结合地震资料研究其特征对油气勘探具有重要意义[1-2]。机器学习方法在数据挖掘、图像处理等方面的成功应用,促使该方法在储层预测方面快速发展[3-5]。机器学习方法分为无监督学习和有监督学习方法。无监督学习方法根据数据结构建立数学模型,聚类过程中无标记数据,致使学习过程具有盲目性;有监督学习根据已知标记数据建立数学模型,进而预测未知数据。该方法获取标记样本费时费力,而且当标记样本较少时,所获得的分类器泛化能力较差[6-9]。为此,形成一种介于2种方法之间的新方法——半监督学习,此次研究主要采用半监督模糊C均值(Semi-Fuzzy C Means,SFCM)方法[10-11],通过隶属度表征样本归属每种类别的不确定性。预测过程中以井点数据作为标记数据,以地震数据作为未标记数据,指导SFCM预测过程。丰富的地震数据能够改善预测的准确度,该方法在储层预测过程中具有广泛的应用前景。
1 地质背景
研究区召30区块位于苏里格气田东部,主要产气层为上古生界下二叠统石盒子组盒8段,三维地震资料采集于2010年,满覆盖面积为252 km2,地震有效频宽为8~65 Hz,视主频为36 Hz[12]。取心井段观察和测井相分析,结合构造背景、物源供给等因素,认为研究区属砂质河流相沉积体系[13],主要发育辫状河沉积,顶部有向曲流河过渡的趋势,发育心滩、河道、河道侧缘以及河道间4种沉积类型。有效储层受控于沉积相,多发育于心滩或河道沉积砂体。沉积储层中,砂岩厚度为8~15 m,砂岩孔隙度为5%~15%,渗透率为0.1×10-3~0.5×10-3μm3,含气饱和度平均值在65%左右,总体表现为低孔、低渗、致密的储层特征[14]。
2 方法原理及可行性分析
模糊C均值是一种常用的聚类方法,采用隶属度表征聚类过程的模糊性。半监督学习聚类过程中根据已标记样本得到初始模型,未标记样本引导聚类过程,改进初始模型[15]。
假设X={x1,x2,…,xn}是n个样本组成的集合,SFCM算法迭代过程与FCM算法相同,但是在聚类过程中,引入影响因子α平衡2种数据的比例,该算法最终目标是使目标函数达到最小,其目标函数如下:
(1)
式中:C和n分别为聚类中心和样本的数量;nl和nu表示已知标签数据和未知标记样本点个数;uij表示第i个样本属于第j种类型的隶属度;d(xi,vj)是样本点xi到聚类中心点vj的距离;m∈(1,∞) ,用于控制聚类过程中模糊度,通常取2;α为已知标记数据与无标记数据的比例,用于控制半监督与完全监督函数之间的平衡;fij=1表示已知标签数据的隶属度矩阵,当样本xi属于第j种类别时,fij=1,否则fij=0 。迭代过程中,对应的中心和隶属度公式更新为:
(2)
(3)
为了验证算法的可行性,采用UCI机器学习数据库中的标准Iris数据集进行实验。Iris数据集包含150个样本数据、4个特征值、3种不同的类型。随机选择α分别为10%、20%、30%、40%和50%作为训练集,剩余数据作为测试集,为了减少聚类过程中的随机性,重复实验10次,得到不同α参数下的平均正确率分别为87.72%、88.76%、89.37%、89.80%、90.04%。该结果表明,随着监督信息的增加,识别的正确率增大,同时当参数α增加到30%时,正确率增加的速率变慢。从标准数据集Iris的识别精度上验证了该算法的合理性和有效性,并且说明了参数α在预测过程中重要性。
结合上述分析过程可知,在聚类过程中有标记数据增加会提高识别的精度,故在使用SFCM聚类过程中应尽可能扩大已知标记数据的比例。召30区块18口水平井钻遇盒8段,为了扩充有标记数据的比例,聚类过程中对钻遇的18口水平井的水平段进行分割,每个分割点的沉积类型均为已知,进而丰富已知标记数据,为SFCM方法聚类过程提供数据基础。
3 实例应用
3.1 地震属性分析
地震属性分析逐渐成为油气藏地球物理的核心技术,在储层预测过程中有着重要作用。不同沉积或砂体的储层在地震记录上的响应特征不同,进而在地震属性上有所反映。针对不同的储层和不同的预测对象,地震属性的选取也不相同。针对沉积相展布特征的分析,主要提取均方根振幅、平均瞬时频率、有效带宽等叠后属性。图1为提取这3个叠后属性与井点处气层厚度叠合图。由图1可知,高振幅、低瞬时频率、低有效带宽的范围内主要分布厚度大于10 m的气层;而气层厚度低于5m的范围主要分布在振幅小于4 750、频率大于30 Hz、有效带宽大于115 Hz内。同时通过井点气层厚度与地震属性叠合图之间的关系可知,不同气层厚度的测井在单一的地震属性上呈现一定的分布趋势,但单一的地震属性存在一定的重叠。因此,预测过程中需要综合多个地震属性开展沉积相研究。

图1 叠后地震属性分布及气层厚度叠合
3.2 聚类结果分析
以测井数据得到的沉积相及地震属性作为已标记数据,采用SFCM方法得到研究区沉积相分布图(图2a、b)。
首先对比分析预测结果和地震属性平面分布特征,整体上看,SFCM得到的结果和每种地震属性分布趋势保持一致,但是不同属性之间作用存在差异,如西部预测得到的心滩(图2a和2b中品红色部分),相比均方根振幅,平均瞬时频率和有效带宽起着主导作用;而对于中南部无井区域得到的心滩和河道类型(图2a和2b中蓝色部分),均方根振幅作用更为明显,进一步说明单属性预测得到的结果存在一定的不确定性,所以有必要进行多属性分析的研究。
其次,根据前面分析,SFCM方法中有标记数据的比例α对预测的精度有着重要影响,为此,在聚类过程中分析了不同α值对应的沉积相分布(图2a和2b)。聚类结果表明,不同的α值对应的沉积相展布特征与先验地质认识一致(图2d)。研究区整体发育4条完整河道,均呈南北向条带状展布,中部河道交汇连片分布,至南部汇聚为3条主河道;河道侧缘及河道间分布面积较小。不同的α值聚类结果在无井控地区存在细微差别,如中西部部分井区。与地质人员预测无井控地区认识相比,该方法对井间沉积相的刻画更为精细,特别是针对东部无井控地区,相对于粗略表征河道形态,该方法预测的井间信息更为详尽丰富。为了分析SFCM预测结果,基于多地震属性,采用传统的FCM开展无监督聚类方法研究,得到盒8段沉积相分布(图2c)。相比SFCM结果,传统FCM方法是一种无监督聚类的过程,聚类过程中忽略测井资料,结果随机性较大,得到结果和先验认识相似,但预测结果表现为河道间类型分布范围较广,随机性大,不能表征完整的河道形态。特别是在东部无井区域刻画的也较为粗糙,无法用于地质解释。
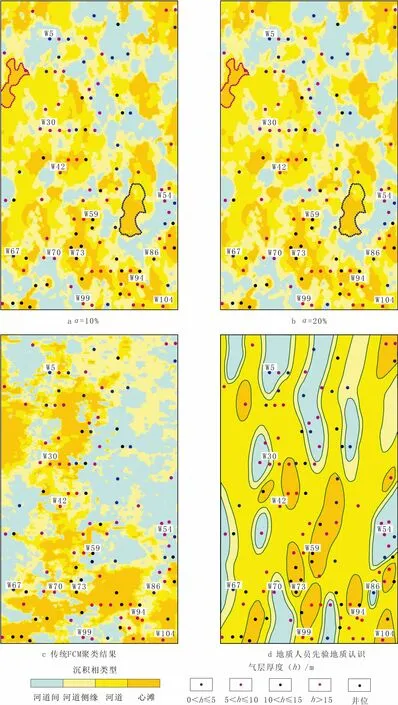
图2 SFCM与传统FCM聚类结果对比分析
最后,通过统计测井处的预测沉积相及砂体厚度,分析不同沉积类型的砂体厚度(表1)。由表1可知,不同的沉积类型对应的砂体厚度存在一定的差异,心滩及河道交汇处沉积砂体最厚,平均厚度为36.00 m;河道沉积砂体厚度为27.00~30.00 m,平均为28.00 m;河道侧缘沉积砂体略小,主要为20.00~27.00 m,平均为25.00 m;河道间沉积对应砂体厚度通常小于20 .00 m,平均为17.00 m。而图2c传统半监督方法得到的结果则与井点处的砂体厚度存在很大的差异。

表1 不同沉积类型对应的砂体厚度(部分井)
4 结 论
(1) SFCM方法在沉积相预测过程中的成功应用,证明了机器学习方法在储层预测过程中的可行性和有效性,同时说明结合井震数据,采用机器学习方法解决致密砂岩储层预测的问题是必然的。
(2) 根据岩心照片及测井资料分析,召30区块沉积环境主要为辫状河,共发育心滩、河道、河道侧缘及河道间沉积相类型。根据研究区的测井资料及水平井资料,开展了SFCM方法的沉积相预测,结果表明该方法能够得到与先验地质认识较为一致的沉积相展布特征。
(3) 从定性和定量角度分析SFCM聚类结果,研究区整体发育4条较为明显的主河道,呈南北向连续分布,而河道侧缘及河道间沉积类型呈零星分布,和先验地质认识较为一致,并且改善了无井区域的地质认识。
(4) SFCM在沉积相预测中的成功应用为储层预测提供新的思路,需要进一步探讨机器学习中的其他方法在储层预测中的应用。
[1] 袁照威,陈龙,高世臣,等.基于马尔科夫-贝叶斯模拟算法的多地震属性沉积相建模方法——以苏里格气田苏10区块为例[J].油气地质与采收率,2017,24(3):37-43.
[2] 赖生华, 柳伟明, 赵永刚, 等. 利用地震信息研究沉积体系平面分布特征:以鄂尔多斯盆地延长探区高家河三维区盒八段为例[J].石油实验地质, 2017, 39(2): 272-277.
[3] 周志华.机器学习[M].北京:清华大学出版社,2016:293-317.
[4] ANTOINE C,LORENZO P,ERWAN G, et al. Machine learning as a tool for geologists[J].The Leading Edge, 2017,36(3):215-219.
[5] 郭继刚,郭凯,宫鹏骐,等. 鄂尔多斯盆地延长组储层致密化及其影响下的致密油充注特征[J].石油实验地质, 2017, 39(2): 169-179.
[6] 唐俊,王琪,马晓峰,等.Q型聚类分析和判别分析法在储层评价中的应用[J].特种油气藏,2012,19(6):28-31.
[7] 唐衔,侯加根,邓强,等.基于模糊C均值聚类的流动单元划分方法——以克拉玛依油田五3中区克下组为例[J].油气地质与采收率,2009,16(4):34-37.
[8] MAJID B,MOHAMMADAR.Seismicfacies analysis from well logs based on supervised classification scheme with different machine learning techniques[J]. Arabian Journal of Geoscience,2015,8(9):7153-7161
[9] BRENDON H. Facies classification using machine learning[J].The Leading Edge,2016,35(10):906-909.
[10] 张阳,邱隆伟,李际,等.基于模糊C均值地震属性聚类的地震相分析[J].中国石油大学学报(自然科学版),2015,39(4):53-61.
[11] FORESTIER G,WEMMERT C. Semi-supervised learning using multiple clusterings with limited labeled data[J].Information Sciences,2016,361-362(C):48-65.
[12] 高世臣,袁照威.地震属性在沉积相预测中的方法研究——序贯随机模式识别[J].地球物理学进展,2016,31(3):1066-1072.
[13] 郭智,贾爱林,何东博,等.鄂尔多斯盆地苏里格气田辫状河体系带特征[J].石油与天然气地质,2016,37(2):197-204.
[14] 袁照威,强小龙,高世臣,等.苏里格气田不同沉积相建模方法及空间结构特征评价[J].特种油气藏,2017,24(1):77-83.
[15] QI J,LIN TF,ZHAO T,et al.Semi-supervisedmultiattribute seismic faciesanalysis[J]. Interpretation, 2016, 4(1):SB91-SB106.
猜你喜欢
科海故事博览·上旬刊(2022年5期)2022-05-17
非常规油气(2021年6期)2021-12-29
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
非常规油气(2021年2期)2021-05-24
化工管理(2021年7期)2021-05-13
矿产勘查(2020年9期)2020-12-25
矿产勘查(2020年8期)2020-12-25
矿产勘查(2020年7期)2020-12-25
石油工业技术监督(2020年2期)2020-04-11
