
一种改进的云环境下排序的密文模糊关键字检索方案
2018-06-29 01:38:40常雪琴
徐州工程学院学报(自然科学版) 2018年2期
常雪琴
(亳州学院 电子与信息工程系,安徽 亳州 236800)
近年来云加密技术、模糊关键字检索技术以及排序检索技术都在蓬勃发展,但以目前的技术情况来说,这些技术的功能不仅较为单一,不能综合处理复杂的问题,而且当前比较流行的模糊关键字检索因为索引的规模比较大,所需要的存储空间较大,对检索的效率具有较大的影响[1].因此,上述问题是当前密文检索算法迫切需要改进的地方.
基于公钥加密的密文检索(PEKS)技术使用的是对称加密方案,对于使用非对称加密的数据文件,授权用户使用自己的密钥就可以进行密文检索[2].PEKS只能够进行比较查询以及子集查询,不支持连续查询,而隐藏向量查询(HVE)支持连续查询,但并不能支持对密文的析取查询[3].
最早的在云服务器环境下的隐私保护模糊关键字检索算法对关键字之间的相似性是用编辑距离来测量的[4],利用通配符构建模糊关键字集合结构(WFSC),即每一个关键字都会拥有一个模糊集合.后来的研究者基于上述的算法进行了改进,将模糊关键字结构变为基于字典集的一种模糊关键字结构(DFSC)[5-6].该结构减小了模糊集合的规模,提高了模糊检索的效率.但是,这些模糊关键字检索技术不支持多关键字检索[7].虽然近年来在云数据上的隐私保护及加密检索技术发展较为迅速[8],但以研究的结果来看,这些技术仅支持单一的功能,不能进行深度复杂的检索,对在检索中的问题或者可能出现的问题都没有进行妥善合理的处理[9-10].
本文在DESC和OPM算法的基础之上,进行索引结构上的创新,提出一种新的索引结构,以在用户进行检索关键字输入时可能出现的错误(拼写错误、格式错误等)为例,进行了模糊查询处理,即在加密云数据的环境下,既能够进行模糊查询,也能够进行排序检索的综合检索方案——PFKS.本文算法与传统算法相比可以减小计算的复杂度,且实现了多关键字检索、模糊查询以及检索结果排序,极大地弥补了传统算法的劣势,提高了检索效率,同时兼顾了安全性.
1 基本框架
在云环境下,模糊关键字检索技术主要分以下两个步骤:
1)Setup阶段.数据的持有人使用KeyGen算法对系统中的参数进行初始化,把数据集中关键字取出,再对这些关键字逐个计算出它们的模糊关键字合集,使用IndexBuilder处理数据文件得到一个能够对它进行检索的倒排索引.再将这些文件进行加密处理,上传外包到云服务器中去.在本阶段,数据的持有者可以将一些密钥发放给授权的客户,发送密钥时,可以使用现有的公钥技术,也可以使用广播技术来进行操作.
2)Retrieval阶段.在得到了授权用户所输入的关键字之后,计算出该关键字对应的模糊关键字集合,然后利用TrapdoorGen算法生成暗门,再将这些信息提交到云服务器上.云服务器接收到该检索请求后,调用Search算法在加密数据索引上进行检索操作,并返回用户检索结果信息,即匹配的加密文件ID和文件分数,这个结果是按照顺序返回的.在这样的流程下,云服务器所获得的信息只有加密文件的ID和加密分数,除此之外无法得到其它的数据信息,保证了数据的安全性.
2 索引结构
在进行规模的数据检索时,索引是一种高效的检索处理方案,而倒排索引是在检索技术中一种经常使用的技术[11],它的主要作用是将关键字与对应的数据文件形成集映射,形成一种集映射的索引结构,保存各个文件中所包含的词汇,所以倒排索引也称倒排表或反向索引,同时该索引支持全文本的搜索.为了使检索的精确度最高并且所得结果能排序,本文使用了一些排序算法来计算文件对应关键字的相关度,相关度用分数来表示;在实现模糊检索时,根据一些关键字之间的相似度标准来量化关键字之间的关系,帮助构建出关键字的集合,本文在进行关键字模糊集合构建时,将以编辑距离为量化标准.
本文的PFKS算法的倒排索引结构见表1.在表1中,关键字集合将编辑距离d作为关键字wi倒排索引的量化标准,文件ID代表含有关键字的数据文件,相关分数为用来进行检索结果排序相关度的分数值.采用的倒排索引结构能够实现可排序的、支持多关键字搜索及模糊查询算法的目标.

表1 倒排索引示例(编辑距离d)
3 加密云环境下的隐私保护PFKS算法
基于上述的基本框架和索引的结构,使用DFSC以及OPM加密算法来实现模糊检索、多关键字查询以及检索结果排序.在加密云环境下,RDKS具体实现如下:
1)Setup阶段
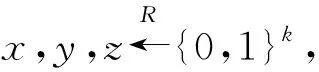
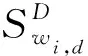
2)Retrieval阶段
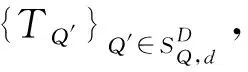
c)按照上一步得到的相关度分数值OPMfz(wi)(SCij)将所得的文件进行排序,然后发送给用户.如果用户定义了只需要k个相关文件,则只需发送给用户前k个文件即可.
d)用户可以利用密钥z来解密服务器返回的文件,得到自己想要的排序检索结果,即

Index(K',F)初始化:对所得的文件集进行关键字提取,文件集定义为F={F1,F2,…,Fn},所得的关键字集合为:W={w1,w2,…,wm},在wi∈W(1≤i≤m)时,获取含有关键字wi文件ID的集合F(wi).满足wi∈W,当构建与该关键字相关的模糊关键词集合SDwi,d满足1≤j≤Ni时:算出文件Fj(含有关键字wi的第j个文件)的相关度分数SCij,再利用算法OPMfz(wi)(SCij)计算出加密的分数,利用所得的分数与该文件的ID一并形成索引Ij索引项:
4 实验性能分析
加密云数据隐私保护算法进行实验验证,算法的实现由C++语言来完成,实验的数据集来自于RFC网站,共10 182个数据文件.
4.1 索引构造算法的实现与性能分析
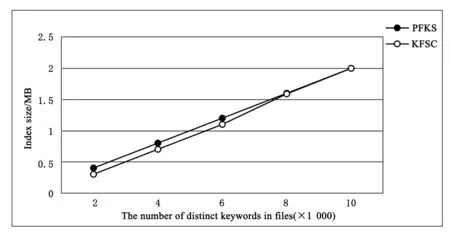
图1 PFKS算法与KFSC算法索引规模比较
在建立模糊关键字索引时,使用的是表1的索引结构.该索引结构在编辑距离d相等时,使用DFSC算法生成的索引规模要比PFKS小得多.本文生成的数据集随机选择为2 000,4 000,6 000,8 000以及10 000个文件.本文的索引规模与主流的索引规模是非常接近的.模糊关键词集合构建时采用的随机长度为5,6,7,10,11,12的关键词共10个.图1为PFSK算法和KFSC算法索引规模的比较,从图1可以看出本文提出的算法和DFSC的方案所得关键字数量是一样的,图中的两个算法的模糊关键字集合的大小是相同的,平均模糊关键字的数量也是相同的.从表2中可以看出,数据集合文件数量为1 000和2 000时,本文所提出的方案为关键字建立索引所花费的时间与传统的方法所花费的时间是非常接近的.同时,本文在已有的算法基础上添加了排序功能,提高用户的检索体验;实现了模糊关键字检索,纠正用户在进行关键字键入时的拼写或者格式上的错误,提高检索的容错.
综上所述,本文的算法方案实现了关键字的纠错和排序查找功能,系统的花费没有因此增加,从而提升了系统的效率和可用性,同时也证明了一对多的保序映射技术凭借索引结构优化使得其安全性和效率性上比传统的算法更好.
4.2 检索算法的性能分析
检索算法的效率体现在算法的计算时间和精度上,模糊关键字算法运算时间不仅包括索引中各个条目的匹配时间,也包含模糊关键字集合匹配的时间以及解密和排序的时间[12-14].因此top-k检索是一种改进的思路,就是返回给用户想要的关键字分数最高的k个文件.在本文提出的方案中,是可以得到和明文检索一样的k个文件.本文算法索引建立的时间相比之下是比较少.出现这种情况的主要原因是因为所采用的关键字相关度分数排序加密算法、倒序索引等规模都较小.除此之外本文的算法还支持多关键字的检索,所以,授权用户在输入了少量的错误关键词时,利用模糊关键字查找出相近的关键字完成检索的过程,对检索的速度和准确度都有不小的提升.

表2 不同数据文件集索引构建花费时间(编辑距离d=2)
综上,本文的算法在传统的算法基础之上做出改进,在传统算法基础之上,缩小了索引的规模,并且允许用户能进行多关键字的检索和排序检索.本文算法在云服务器环境下的安全性上,在算法的精度上,特别是一对多保序映射算法的正确性上,具有较大的提升.实验结果如图2所示.
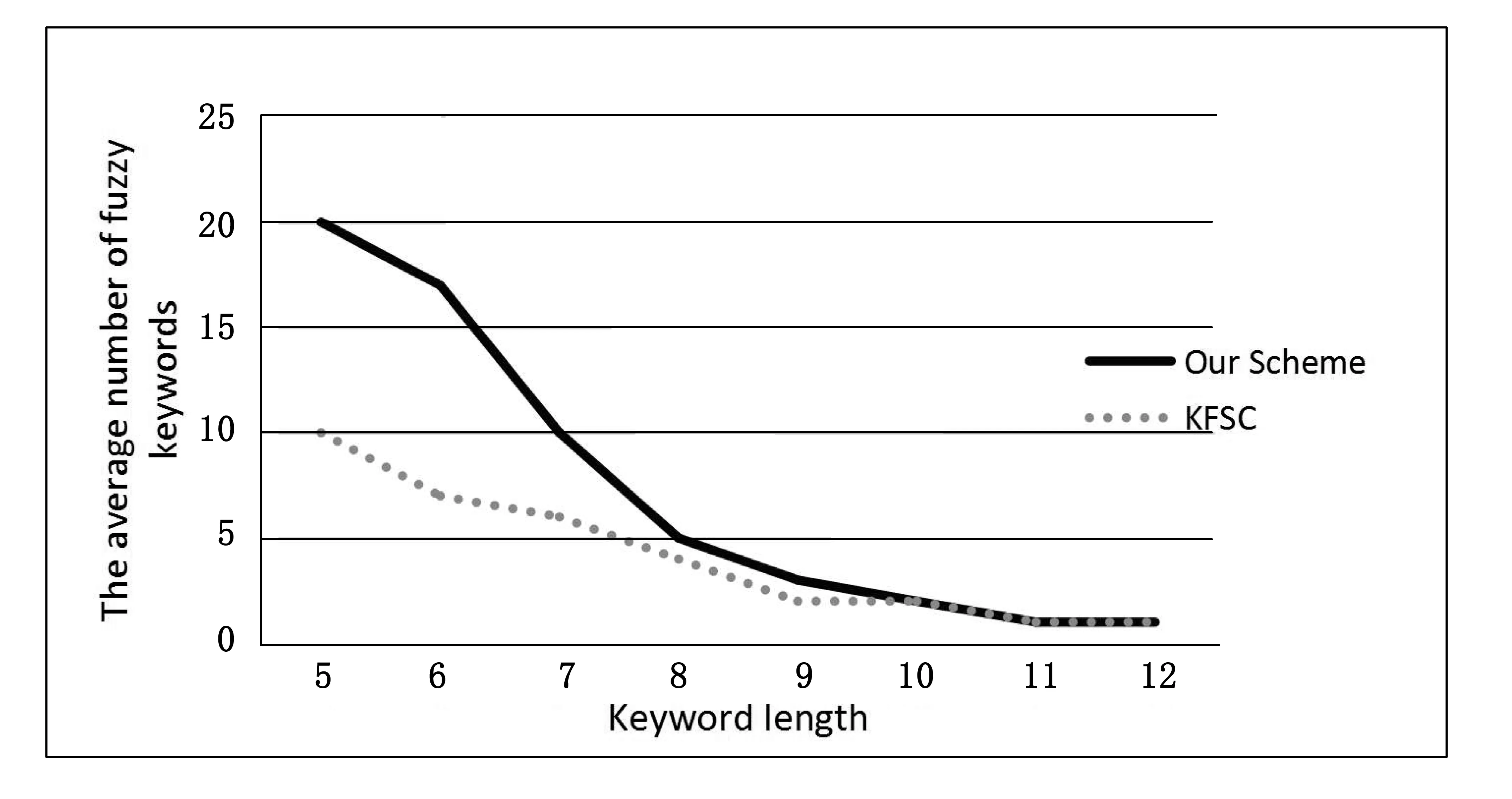
图2 PFKS算法与DFSC方案模糊关键字数目比较
5 结语
针对当前流行的云服务器环境,提出基于隐私保护的PFKS算法;在传统的DFSC算法和OPM密文检索算法基础之上增加多关键字检索、模糊检索以及排序检索,并且改进索引结构.对算法的安全性和效率进行分析研究,结果证明本文算法在云服务器环境下的安全性上,在算法的精度上,特别是一对多保序映射算法的正确性上,具有较大的提升.因此,在云环境下,本文提出的模糊关键字检索技术是可行的、有效的.
参考文献:
[1] 闫明.一种新的云计算环境下数据安全保护算法研究[J].科技通报,2017,33(9):184-187.
[2] LIU C,ZHU L,LI L,et al.Full keyword search on encrypted cloud storage data with smallindex[J].IEEE,2011:269-273.
[3] LI X,LI J,HUANG F.A secure cloud storage system supporting privacy-preserving fuzzydeduplication[J].Soft Computing,2016,20(4):1437-1448.
[4] KHAN A N,KIAH M L M,ALI M,et al.BSS:block-based sharing scheme for secure data storage services in mobile cloudenvironment[J].Journal of Supercomputing,2014,70(2):946-976.
[5] 华钢,王永星.基于信号衰减模型补偿的RSS指纹定位算法[J].徐州工程学院学报(自然科学版),2015,121(4):28-32.
[6] CHAN P T,RAD A B,HO M L.A study on lateral control of autonomous vehicles via fired fuzzy rules chromosome encoding scheme[J].Journal of Intelligent & Robotic Systems,2009,56(4):441-467.
[7] WANG S,ZHAO D,ZHANG Y.Searchable attribute-based encryption scheme with attribute revocation in cloudstorage[J].Plos One,2017,12(8):e0183459.
[8] 张克军,窦建君.基于Contourlet变换和不变矩的图像检索方法[J].徐州工程学院学报(自然科学版),2012,27(1):48-51.
[9] WANG Y,BAO W,ZHAO Y,et al.AnElGamal encryption with fuzzy keyword search on cloud environment[J].International Journal of Network Security,2016,18(3):481-486.
[10] LI W,WEN Q,LI X,et al.Attribute-based fuzzy identity access control inmulticloud computing environments[J].Soft Computing,2017(1):1-12.
[11] ARGONETO P,RENNA P.Supporting capacity sharing in the cloud manufacturing environment based on game theory and fuzzylogic[J].Enterprise Information Systems,2016,10(2):193-210.
[12] SHOJAFAR M,JAVANMARDI S,ABOLFAZLI S,et al.FUGE:A joint meta-heuristic approach to cloud job scheduling algorithm using fuzzy theory and a geneticmethod[J].Cluster Computing,2015,18(2):829-844.
[13] LIU C,ZHU L,LI L,et al.Full keyword search on encrypted cloud storage data with smallindex[J].IEEE,2011:269-273.
[14] SHEKOKAR N,SAMPAT K,CHANDAWALLA C,et al.Implementation of fuzzy keyword search over encrypted data in cloud computing[J].Procedia Computer Science,2015,45(2):499-505.
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
太原科技大学学报(2019年3期)2019-08-05 01:18:18
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
信息安全研究(2016年10期)2016-02-28 20:18:19
电子设计工程(2015年17期)2015-02-27 12:08:03
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:52
