
基于上下文语义的朴素贝叶斯文本分类算法
2018-06-28 03:30郑开雨
计算机与现代化 2018年6期
郑开雨,竹 翠
(北京工业大学信息学部,北京 100124)
0 引 言
随着互联网技术的快速发展,用户规模呈现爆发式增长,互联网已经步入大数据时代,随之而来的挑战也尤为突出,其中文本类数据增长异常迅猛,挖掘文本类信息的知识,实现文本的分类也一直是近年来数据挖掘领域内研究的热点。
现在常用的文本分类技术有很多,比如K近邻(KNN)、朴素贝叶斯(Naive Bayes,NB)、支持向量机(SVM)、神经网络(Neural Network)等,其中朴素贝叶斯基于古典数学贝叶斯理论,假设样本各属性相互条件独立,判定文本属于哪个类别,是根据文本属于哪个类别的条件概率越大,就判定为哪类,其中类别的条件概率是依据贝叶斯公式计算样本的关键词属于各类别的条件概率乘积[1]。根据文本分类的特点,一般文本中出现的关键词大多属于哪类,文本判定为哪类的可能性就比较大。所以,传统的朴素贝叶斯算法忽略词条相互依赖关系也能达到比较好的效果,在计算上也避免了维数灾难和过度拟合。然而传统的朴素贝叶斯分类首先在计算词的条件概率时忽略了同义词的影响,将有可能出现在关键词词典里的同义词也视为相互独立的词分别计算,这会造成在计算时大大降低这类词对分类的影响,并且也不符合常理上的认知。比如在教育类别下提取的关键词,分别出现了2个词“教师”和“老师”这2种不同的表达方式,传统的朴素贝叶斯在计算时往往分别计算2个词在各类别下的条件概率,而忽略了这2个词实质上是同一概念。其次提取文本关键词构建关键词词典可能由于训练集的参差不齐导致比较稀疏,密度不均,为了降低语料差异对训练的影响,本文使用神经概率语言模型word2vec动态地扩展词典。
为了解决以上问题,文献[2]采用结合同义词词林的方式或者引用外来的知识库扩展来降低假设前提对同义词的影响。但这种方式适应性比较差,随着语言表达的多样化,引用静态的知识库更新缓慢,不能取得很好的效果。在特征词典处理方面,文献[3]使用搜索引擎对词典进行扩充,通过引擎搜索关键词得到相关的近义词,但搜索结果往往不尽人意。文献[4]采用WordNet结合词向量对词典扩展,然后进行分类,并取得了比较好的效果,其中WordNet是由一个覆盖范围宽广的词汇语义网构成,各个词性被分别组织成一个同义词网络,每个同义词集合都代表了一个基本的语义概念,这些集合之间由各种关系连接。但使用WordNet的缺点是对词的语义相似度很难去准确度量,只能给出是否同义的二分类结果,而且人工定义的方式显然已跟不上时代变化的步伐,此外标注和维护WordNet也需要消耗大量的人力和时间[5]。文献[6]采用背景知识来扩展文本的特征,但这个方式过度依赖知识经验,不能全面准确地找到相关特征。
以上这些研究大多是基于规则或者基于知识库,而不是基于统计概率完成改进。基于统计概率最大的优势是建立在大规模数据之上习得普遍规律,适应时代的发展,也成为主流的机器学习算法。为此,本文提出基于上下文语义的朴素贝叶斯分类算法(Context Semantic-based Naive Bayesian Algorithm,CSNB),针对以上指出的传统的朴素贝叶斯问题提出相似词的概念,使用扩展后的相似词词簇代替传统的关键词词典,每个相似词词簇就代表一个意群。在计算词条后验概率时使用其相似词频数总和代替该词出现的频数,旨在改变朴素贝叶斯基于独立词条的粒度上进行文本分类,衡量特征意群对文本分类的影响,可以减小由于独立性的假设前提降低同义词特征的权重带来的影响。
在文本分类中,方差(variance)是在各个不同的训练集上分类模型预测的差异变化,偏差(bias)是预测的结果和实际值之间的差异程度[7]。传统的朴素贝叶斯分类器是个比较简单的分类模型,容易造成欠拟合,导致出现低方差高偏差的问题[8],通过引进相似词的概念,对关键词词典语义合并达到减小偏差的目的,同时结合word2vec训练的结果扩展关键词词典可以减小训练语料的差异对分类的影响,从而进一步减小方差。
1 相关理论
1.1 数据预处理
1.1.1 分词
分词是文本预处理最基础也是最重要的步骤,分词的好坏对接下来的任务处理有着直接的影响。在分词时,分析了现有的几种分词方法,机械分词法以及基于统计模型的序列标注法,前者是通过将文本中的文字片段和现有的词典匹配,能匹配到的作为分词的一个结果,其缺点是无法通过语义的特征切分词语,并且对词典的依赖较大,对于未登录词和歧义词的识别不好[9]。而序列标注法里典型的是隐马尔可夫模型(HMM),通过维特比算法动态规划得到最优分词结果,既可以消除一些歧义词,又提高了分词的准确性。所以本文采用隐马尔可夫模型对训练语料进行分词,得到词的集合。然后使用停用词词库过滤掉一些影响不大的词,包括语气词、副词、介词、连词、虚词等。
1.1.2 特征选择
目前文本分类领域比较常用的特征选择有TF-IDF(Term Frequency-Inverse Document Frequency)、互信息、期望交叉熵、信息增益和卡方统计量等,其中互信息方法被统计语言模型广泛使用,而且大多数的研究表明使用互信息算法特征选择效果显著,优于其他的算法[10]。互信息是信息论里的一种信息度量,是衡量2个随机变量之间的相关度,用于特征提取时基于假设:词条在某个类别下出现的频率高,但在其他的类别下出现的频率较低,那词条与该类的相关性就大,相关性越大互信息就越大。
设随机变量(X,Y)的联合分布为p(x,y),边际分布分别为p(x)、p(y),互信息I(X,Y)的定义如公式(1):
(1)
当应用到文本特征选择时,如公式(2):
(2)
其中,W和C是二值随机变量,W取值为et,文档包含词条t时,et=1,否则et=0。C取值为ec,文档属于类别c时,ec=1,否则ec=0。公式中的概率值通过统计文档中的词条和类别来计算。
1.2 传统的朴素贝叶斯算法
设训练样本集分为k类,记为C={C1,C2,…,Ck},则每个类的先验概率为P(Ci),i=1,2,…,k,其值为Ci类的样本数除以训练集总样本数。对于新样本d,其属于Ci类的条件概率是P(Ci|d),根据贝叶斯定理,得到公式(3):
(3)
P(d)对于所有类均为同一常数,可以忽略。为避免P(Ci)等于0,采用拉普拉斯概率估计:
(4)
其中,|C|为训练集中类的数目,|DCi|为训练集中属于类Ci的文档数,|DC|为训练集包含的总文档数。
对于待分类文本文档d,本文采用向量空间模型,其基本思想是将每一个文本表示为一个向量d=(w1,…,wm),m是d的关键词个数,wm代表关键词[11]。
(5)
朴素贝叶斯分类器将未知样本归于哪类,如下:
(6)
1.3 相似词
本文依据同义词提出相似词的概念,即广义上的同义词,不再严格限制必须是相同语义。词的向量化表示需要凭借上下文语境来量化,所以在给定上下文的情境下最大可能同时出现的词,也就是同一类的词,本文称其为相似词,这样就相对放松了同义词的条件。因为相似词和同义词相比能更好地表达类别中意群的概念,而意群是基于概率模型的文本分类的关键,文本中出现哪个意群比较多,文本就很大可能会分到相应的类别。因此本文选用相似词代替同义词。同时,相似词可以通过给定语料统计得出,突破了同义词必须通过人工定义的局限性,这在大数据背景下的优势很明显,大大减少了人力的浪费。可以根据社会潮流的发展以及语言的多样性来动态地训练相似词。所以本文使用相似词词簇代替传统的关键词词典,通过合并相似词词频参与模型的训练,降低条件独立性假设前提带来的影响。
1.4 word2vec简介
word2vec是一种浅层的神经网络算法,主要包括2个模型,分别是CBOW模型(Continuous Bag-of-Word Model)和Skip-gram模型(Continuous Skip-gram Model),CBOW模型通过词的上下文对当前词预测来学习词向量,而Skip-gram是根据当前词对它的上下文词进行预测来学习的[12]。
word2vec常用来训练词向量,它将词映射到多维的向量空间中,将词表征为一组低维实数向量,被称为分布式表征(Distributed Representation),通常也被称作“Word Representation”或者“Word Embedding”,这与普遍使用的词表示方式的“One-hot Representation”不一样的是,这种表示方式不仅解决了维数灾难的问题,同时语义相近或者相关性大的词向量在距离上也更为接近,常用来做很多自然语言处理工作,比如聚类、词性分析等[13]。
本文通过训练word2vec得到词向量。将用来训练分类算法的关键词词典通过词向量表示后进行层次聚类,构建相似词词簇。然后利用word2vec的训练结果遍历词簇获取每簇簇中心的相似词扩展相似词词簇,以实现词典的动态构建。
2 基于上下文语义的朴素贝叶斯算法
2.1 word2vec训练描述
2.1.1 相似度阈值
这里的相似度主要使用余弦距离计算来表示,取值范围是[0,1],距离越近的词相似度越接近于1。相似度的取值非常关键,过高使相似词起不到作用,过低反而导致分类效果下降,因为有噪音数据干扰影响分类。所以本文采取的策略是首先从同义词词典中抽取几组同义词,通过训练好的模型获取相应的词向量,求出相似度的均值作为改进算法中的相似度阈值。
2.1.2 训练过程
将word2vec的训练语料进行结巴分词,然后去除停用词。调用gensim包的word2vec模块进行训练,接口参数是文件名以及经过实验确定好的模型参数window、size、min_count等。最后持久化模型,模型提供给定词的词向量以及指定阈值的相似词的常用接口。本文主要通过训练该模型生成词向量,然后使用词向量来表示关键词词典并将其进行层次聚类以构建词簇词典。另外,词向量还用于获取关键词指定阈值内的相似词以进一步扩展词簇词典。需要注意的是分类算法和训练词向量的模型是基于不同的语料分别训练的,训练词向量的语料最好对应分类算法数据集的特定领域,采集尽量全面丰富的信息。
2.2 基于上下文语义的朴素贝叶斯算法描述
基于上下文语义的朴素贝叶斯算法在传统的朴素贝叶斯方法基础上,结合word2vec模型训练的词向量来改进。分类算法在构建关键词词典方面,提取的关键词存在语义冗余的现象[14],本文首先通过word2vec训练的词向量将词典的关键词向量化表示,给定相似度阈值使用余弦距离层次聚类,构建词簇词典。
接下来考虑另一种情况,测试文本中如果有词因表达方式不同没有出现在关键词词典中,被过滤掉不参与计算,但语义上和关键词词典某个词相似,基于这种情况的考虑,本文结合语言模型word2vec的训练结果,遍历词簇词典获取簇中心的相似词扩展到词簇词典中。避免了词簇词典因为训练文本的差异而不同所造成的局限性,扩展后的词簇词典更加全面稳定,从而提高文本分类的准确率。
在训练word2vec语言模型时,依据分类算法的数据集采集对应领域的具有完备性和平衡性的语料库[15-16],按照上述的描述训练word2vec生成词向量文件。
基于上下文语义的朴素贝叶斯文本分类的流程:
1)将分类算法的数据集分词,去除停用词后,使用互信息提取训练文本中的关键词构建关键词词典。
2)将词典中的关键词用词向量表示进行层次聚类,实现从上下文语义的角度对关键词词典语义合并,相似度比较大的关键词归为一簇表示相似词词簇,构建词簇词典代替传统的字典。
3)遍历词簇中的每个簇中心,获取给定相似度阈值的相似词扩展到词簇中,达到根据上下文语境动态地扩展词簇词典的目的。
4)将词簇词典中相似词的词频合并参与训练朴素贝叶斯分类模型。
基于上下文语义的朴素贝叶斯文本分类的系统结构如图1所示。
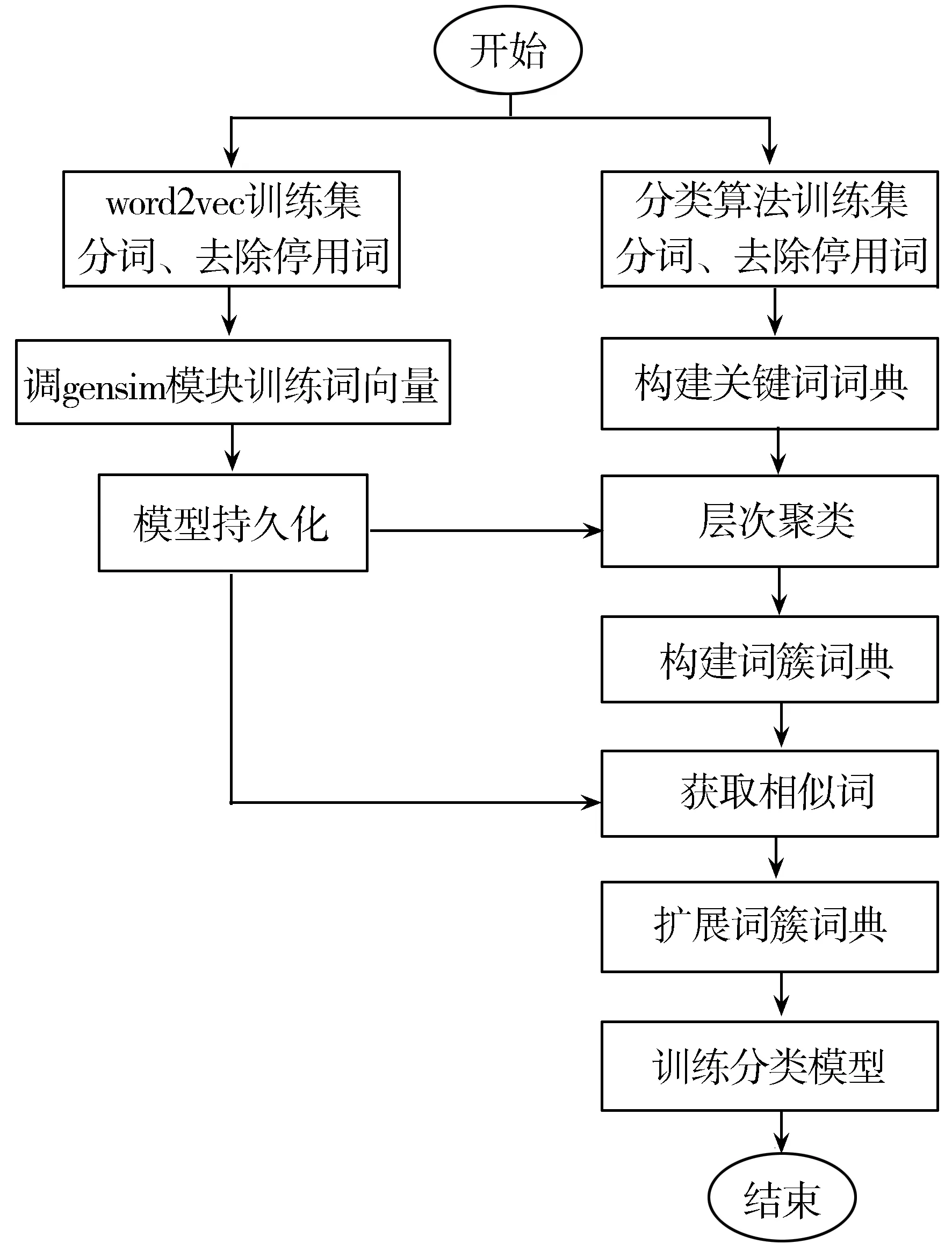
图1 改进后算法系统结构图
3 实 验
本文提出的算法主要针对二分类问题进行分类。为了更能说明CSNB的分类效果,本文通过对比CSNB、NB、fastText这3种模型的实验结果进一步分析各分类器优缺点。其中fastText模型由word2vec衍生出来,其网络架构和word2vec中CBOW模型类似[17],是Facebook在2016年开源的文本分类算法。fastText分类器相比较其他文本分类模型,例如SVM、Logistic Regression和neural network,在保证分类效果的同时,大大缩短了模型的训练时间[17]。本文通过调用封装好的fastText包进行文本分类。
先使用NB算法在数据集上进行两两组合分类,选取分类效果较好的数据集和较差的数据集分别训练这3种模型,比较分类结果。
3.1 word2vec实验研究
3.1.1 训练词向量的数据采集
训练word2vec模型使用的语料库主要是从网上采集的新闻语料、百度百科、公众号以及一些中文平衡语料,大概有100 GB左右。这里的语料和训练分类算法所用的训练语料是不一样的,训练word2vec的语料库最好包含分类算法数据集对应的特定领域里尽量全面的信息。本文使用搜狗新闻语料作为改进朴素贝叶斯算法的数据集,所以训练word2vec的语料库是包含新闻领域在内的尽可能全面的数据。
3.1.2 模型参数
训练模型时窗口参数window大小分别设置为8、12,这里的窗口概念也就是当前词的上下文词,随机选择该词的前后window个词作为上下文参与到模型的训练中。词向量的维度分别选择180、240,选用CBOW模型的哈夫曼树策略,本文尝试了2个参数的不同组合,并且使用同义词词典检验集检验哪组模型参数得到的词向量最佳,采取的策略是用训练的词向量结果表示检验集中的同义词词组,计算每组同义词之间的相似度求平均,选择结果值最大的模型作为最终的模型,参数最终分别设定为window=8,词维度size=240,最小词频min_count=60,迭代10次。
3.2 分类算法实验数据
首先选取公开的搜狗新闻语料作为实验数据集,其中教育和体育在NB算法上二分类效果较好,称作数据集一。股票和经济相对分类较差,称作数据集二。本文主要使用这2个数据集分别训练CSNB、NB、fastText模型,从数据集一、数据集二中对2个类别分别随机抽取5500条作为训练集、2500条作为测试集。
3.3 分类评价标准
文本分类算法常见的评价标准有查准率(Precision)、召回率(Recall)以及F1测试值[18]。本文针对二分类问题进行分类,给出对应的分类结果混淆矩阵,如表1所示。
表1 分类结果混淆矩阵

预测结果 +1预测结果 -1真实类别 +1真正例(TP)伪反例(FN)真实类别 -1伪正例(FP)真反例(TN)
1)召回率:分类器真实类别为正例的样本中真正例的比例,如公式(7):
(7)
2)查准率:分类器预测为正例的样本中真正例的比例,如公式(8):
(8)
3)F1测试值:考虑到查准率和召回率是相互影响关系,追求这2个值都比较高时,就可以用公式(9)的F1值:
(9)
3.4 实验结果和分析
主要使用3.3节介绍的3个指标比对CSNB、NB、fastText这3个模型的分类效果。3个评价指标取值范围都是[0,1],取值越高的分类器相对效果就越好。实验50次分别统计在2个数据集上3个指标查准率、召回率和F1测试值的取值情况。
图2~图4分别是在数据集一上3个算法的查准率、召回率、F1值综合指标的对比情况。从数据集一结果对比图可以看出,NB的F1综合指标均值是0.95,CSNB算法的F1综合指标均值是0.99,相对比提升了4%。而和fastText的F1指标的均值0.96相比相差甚微,平均只提升了3%。CSNB的标准差是0.001,而NB和fastText的标准差分别是0.003、0.004,相对比波动较小。
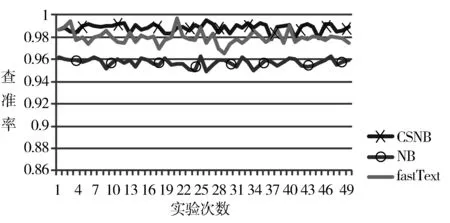
图2 教育和体育查准率对比

图3 教育和体育召回率对比
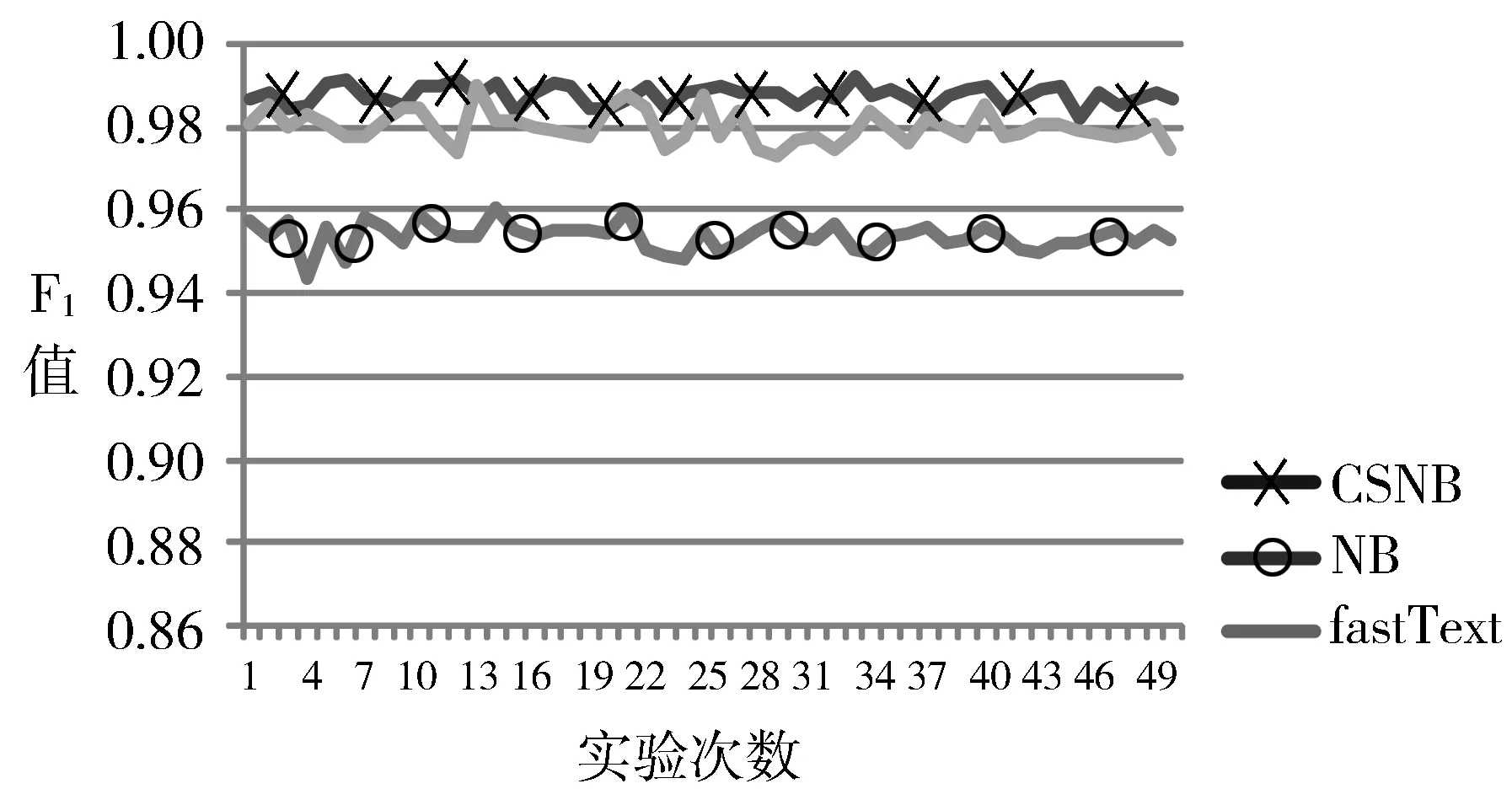
图4 教育和体育F1值对比
图5~图7分别是在数据集二上3个算法的查准率、召回率、F1值综合指标的对比情况。从数据集二对比图可以看出NB的F1综合指标均值是0.92,CSNB算法的F1综合指标均值是0.99,相对比提升了7%。CSNB相对比fastText的F1指标均值0.96提升效果较小。CSNB的标准差是0.002,对比NB的标准差0.005和fastText标准差0.004,波动较小。

图5 股票和经济查准率对比
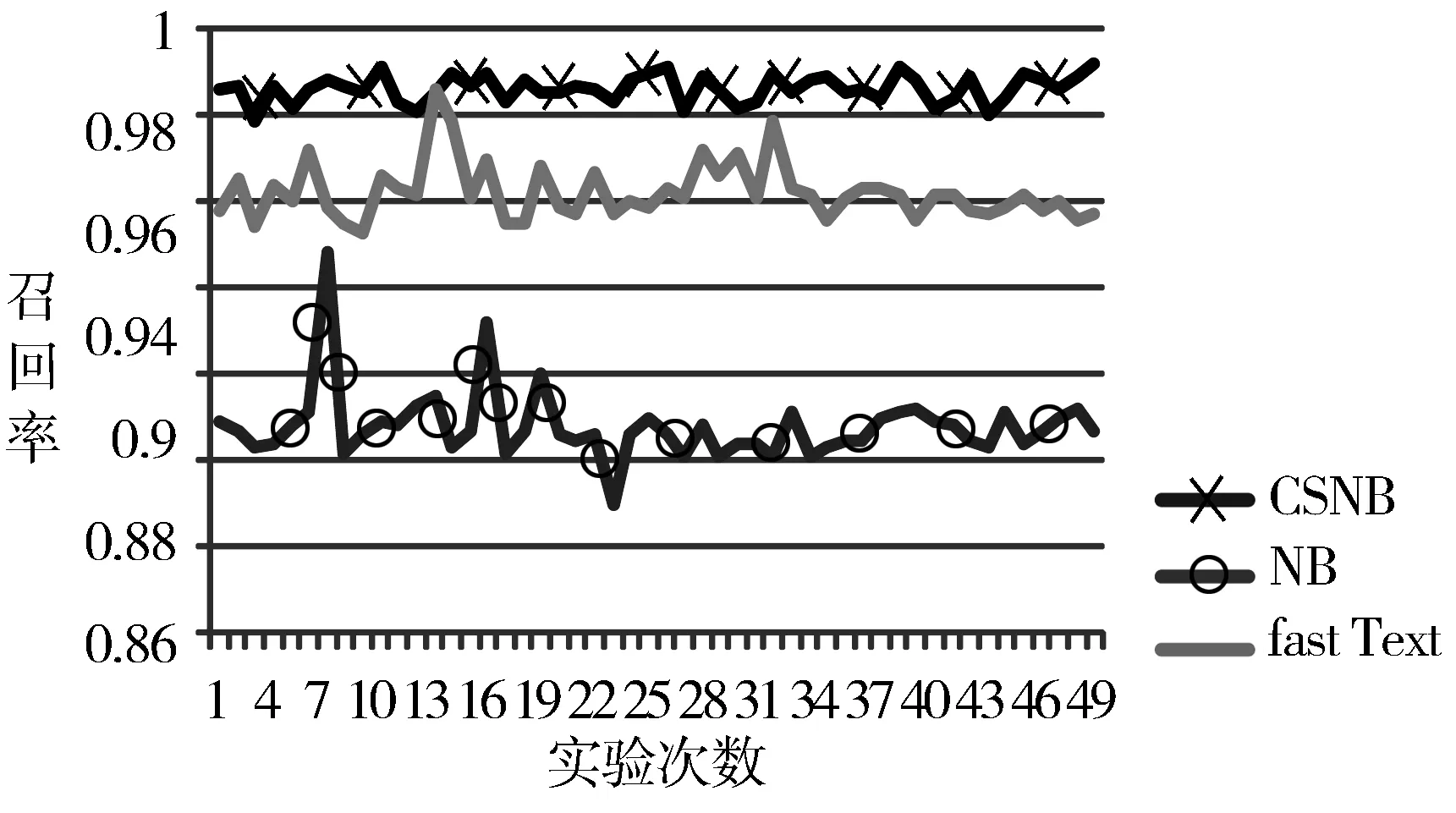
图6 股票和经济召回率对比

图7 股票和经济F1值对比
从2个数据集的实验结果可以看出,随着分类次数的增多,3个模型的取值对比越明显。CSNB分类效果在这3个指标取值上普遍比NB高,从而可以总结出CSNB分类效果相对较好。但和fastText相比效果相差不大。由标准差对比得出,CSNB和其他2个模型相比3个指标取值波动较小,分类结果更加稳定。并且在数据集二上的实验相对比数据集一,明显比NB分类效果提升得多,这是因为数据集二在CSNB算法上,经过关键词词典合并后扩展词簇,使得其中2类的关键词更加全面,语义冗余小,更有利于分类。而数据集一中2个类别相关度比较小,所以在NB算法上关键词词典冗余相对较小,进行聚类扩展改进后对分类的影响比较小。
本文实验采取随机选取训练集的策略,经过分析NB算法分错的样本,发现分错的原因是训练样本空间并不能真正体现真实的数据空间,构建的关键词词典不全面,不准确,以至于有的测试样本识别出的关键词太少,导致分类错误。所以本文通过关键词聚类后扩展,结合语义特征可以构建相对完善的词典,从而提高分类的准确度,同时也能增加分类模型的稳定性。结合实验结果可以看出CSNB模型相比NB提升效果明显,而相比fastText分类效果提升不大,但CSNB的抗干扰性更强一点,比较适合小规模的数据集。
4 结束语
鉴于传统的朴素贝叶斯分类器只是基于词频来计算词条的后验概率,不具有语义特征。针对长文本分类时,提取的关键词数量多,构建的关键词词典高维并且在语义上会出现冗余。word2vec模型可以解决传统的向量空间模型的高维问题,并且可以引入语义特征。本文通过训练word2vec语言模型结合传统的朴素贝叶斯算法,提出了一种基于上下文语义的朴素贝叶斯算法(CSNB),主要是利用语言模型训练好的词向量表示关键词,首先将分类模型中提取的关键词词典进行层次聚类,达到语义合并的目的。相对于模型空间该词典并不全面,而且较大程度依赖于训练样本。基于word2vec训练结果,本文通过余弦相似度计算词之间的距离,得到词典中关键词的相似词扩展该词典。实验表明,CSNB在查准率、召回率、F1值这3个指标上都优于NB和fastText算法,在提高分类准确度的同时也有较强的抗干扰性,具有稳定的分类效果。
本文提出的CSNB算法,由于时间复杂度的提升,时间耗费比较多,所以下一步的研究工作重点将放在如何减少运行时间上,进一步提高分类效率。本文利用词向量并且借助于关键词词典,将样本分词后通过比对是否出现在词典中,得到过滤后的关键词,下一步的研究还将通过计算样本词与词典中的关键词之间的相似度来过滤关键词,有效解决构建的关键词词典不全面的问题。
参考文献:
[1] 张雯,张化祥. 属性加权的朴素贝叶斯集成分类器[J]. 计算机工程与应用, 2010,46(29):144-146.
[2] Jiang J J, Conrath D W. Semantic similarity based on corpus statistics and lexical taxonomy[C]// Proceedings of 1997 IEEE International Conference on Research in Computational Linguistics. 1997:19-33.
[3] 郭永辉. 面向短文本分类的特征扩展方法[D]. 哈尔滨:哈尔滨工业大学, 2013.
[4] Zhang Weitai, Xu Weiran, Chen Guang, et al. A feature extraction method based on word embedding for word similarity computing[M]// Natural Language Processing and Chinese Computing. Springer, 2014:160-167.
[5] 张东娜,周春光,刘彦斌,等. 一种基于WordNet和Corpus Statistics的语义相似性计算方法[J]. 吉林大学学报(理学版), 2010,48(5):811-816.
[6] 袁满,欧阳元新,熊璋,等. 一种基于频繁词集的短文本特征扩展方法[J]. 东南大学学报(自然科学版), 2014,44(2):256-260.
[7] Agrawal R, Imielinski T, Swami A. Database mining: A performance perspective[J]. IEEE Transactions on Knowledge and Data Engineering, 1993,5(6):914-925.
[8] Friedman N, Geiger D, Goldszmidt M. Bayesian network classifiers[J]. Machine Learning, 1997,29(2-3):131-163.
[9] Mladenic D, Grobelnik M. Feature selection for unbalanced class distribution and Naive Bayes[C]// Proceedings of the 16th International Conference on Machine Learning. 1999:258-267.
[10] Yang Yiming, Pedersen J O. A comparative study on feature selection in text categorization[C]// Proceedings of the 14th International Conference on Machine Learning. 1997:412-420.
[11] Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975,18(11):613-620.
[12] Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. 2013,2:3111-3119.
[13] Mikolov T, Yih W T, Zweig G. Linguistic regularities in continuous space word representations[C]// Proceedings of 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013:746-751.
[14] 杨婉霞,孙理和,黄永峰. 结合语义与统计的特征降维短文本聚类[J]. 计算机工程, 2012,38(22):171-175.
[15] Wolf L, Hanani Y, Bar K, et al. Joint word2vec networks for bilingual semantic representations[J]. International Journal of Computational Linguistics and Applications, 2014,5(1):27-44.
[16] Mikolov T, Chen Kai, Corrado G, et al. Efficient estimation of word representations in vector space[J]. Computer Science, 2013(1):28-36.
[17] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. 2017:427-431.
[18] Lilleberg J, Zhu Yun, Zhang Yanqing. Support vector machines and word2vec for text classification with semantic features[C]// Proceedings of the 14th IEEE International Conference on Cognitive Informatics & Cognitive Computing. 2015:136-140.
猜你喜欢
法律方法(2021年4期)2021-03-16
开放教育研究(2020年2期)2020-03-31
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
长江学术(2016年4期)2016-03-11
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
