
基于属性权重的实体解析技术探讨
2018-06-27 02:38张晏李继云
无线互联科技 2018年5期
关键词:大数据
张晏 李继云
摘 要:大数据时代下,数据呈爆炸式的增长态势,而这些数据结构本身有一定的差异,这为数据解析带来较大难题。根据既往研究资料中提及,考虑引入基于属性权重的实体解析技术,以此使数据解析与处理效率提升。文章对实体解析技术做简单介绍,分析属性权重基本模型,在此基础上提出属性权重下实体解析的方法。
关键词:属性权重;实体解析技术;大数据
数据海量的生成与处理为大多企业带来较多难题,特别因实体表达形式不同,可能使错误信息产生,这就使实体解析面临极多问题。尽管以往实体解析法应用下能够处理多数据源记录,且在发展中逐渐将数据预处理、比较函数选取以及特征向量选取等,但操作中仍可能将部分关键属性忽视,降低解析结果准确性。在此背景下,考虑将属性权重引入,保证实体解析的效率与准确度。因此,本文对属性权重下实体解析技术的研究,具有十分重要的意义。
1 实体解析技术相关解读
关于实体解析,覆盖较多领域,如数据库领域、机器学习领域、人工智能领域、信息检索领域与统计学领域,各领域均强调利用实体解析技术做数据源的处理。如单一结构数据集,引入实体解析技术一般做相似度计算,计算方法选择距离函数模型,如编辑距离,计算中对记录相似度分析,同时明确实体之间关系,可借助语义信息进行记录。再如结构不同数据,实体解析技术应强调匹配计算异构数据集,在明确数据集合的情况下,做匹配计算。需注意的是,因数据结构不同,所以引入实体解析方法中可能面临如何确定属性权重。从既往研究资料中可发现,一般认为所有属性均可呈现为匹配属性,其意味各数据记录均有相应的属性,所以在处理记录匹配上能够取得较高的效率。但这种处理方式应用下,直接导致部分关键属性被忽视。有研究中也指出在属性权重分配中,直接由专家指定属性,虽然满足匹配属性要求,但若专家来自不同领域,在数据集观点上有一定差异,所以最终指定的属性难以保证一致。针对这些问题,需考虑如何在实体解析技术上优化[1]。
2 属性权重模型构建
2.1 属性权重模型基本定义
属性权重模型是实体解析技术优化的基础。本次研究中从多个定义对属性权重模型进行分析,具体定义内容包括:(1)匹配属性,基于相似度的属性匹配,例如部分研究中提及记录中相似度的属性均作为匹配属性。(2)最佳分类属性,主要指按相关的原则由匹配属性集合内挑选分类属性,以信息增益方法为例,可计算各属性信息增益值,这样便可获取权重,在此基础上做最佳分类属性的确定。(3)信息增益值,通过数据挖掘方法获取信息增益,若得到的属性信息增益值较大,意味属性涵盖的信息量较多,记录中内部分特征也会被呈现出来。(4)基本相似度,与匹配属性概念不同,该定义下的相似度获取通过基本相似度函数实现,如编辑距离相似度函数,通过做单个属性计算,获取相似度。(5)最终相似度,需以基本相似度为基础,取属性权重加入,做复合运算便能获取最终结果[2]。
2.2 属性权重方法选择
属性权重方法常见的有相似度衡量、专家制定方法。以相似度衡量方法为例,强调使匹配记录保持一定的相似度,特别部分Web数据源较多情况下,实体识别中便需明确匹配记录,取相似度最小值,这种方式对于确定属性权重准确度较高,但整个操作过程中涉及较大的计算量,重复匹配,同时在匹配结束后,不会对属性赋予权重。另外一种方法即专家制定法,应用中要求有相关领域的专家对属性权重进行确定,结合自身知识经验对各属性分配相应比重,最后选择其中权重较高的属性计算,获取相似度结果。尽管这种方法运用下相对简单,但因不同领域专家在数据集认知上有一定差异,所以所得出的结果准确性难以保证。针对上述两种方法应用下存在的问题,本次研究中考虑引入其他两种方式,包括信息增益、概率统计,旨在使权重分配准确率提高。其中信息增益法亦被称之为IG法,实现的原理在于利用依托于数据挖掘,确定信息增益值后,若结果较大,意味属性影响作用明显,所以在最佳分类属性集合中应选择信息增益值较高的属性。而引入概率统计方法,强调借助数据工具将数据集合中的规律挖掘,如在训练数据集合利用下,检验与计算各属性字段,假定各属性字段均以单独匹配属性形式呈现,此时对属性准确度对比,可获取权重结果。
3 属性权重下实体解析具体方法
3.1 合理分配权重属性
考虑到属性权重分配中,因忽略元组属性加权重,将降低匹配准确度,出现數据信息遗漏情况。所以,本次研究中强调依托于概率统计知识、信息增益方法,满足赋予权重属性要求。而具体分配属性权重中,有相关的要求,包括:(1)数据集预处理。处理中应保证数据集格式的规范,然后通过概率统计或信息增益,确定可以代表所有数据记录的集合,称其为最佳分类属性集合。(2)权重计算。在信息增益方法运用下,可将信息增加量计算出来,然后由数据集内选择属性,对各属性信息增益值计算,在此基础上完成权重分配计算过程。
3.2 合理选择最佳分类属性
属性权重的获取借助概率统计、信息增益变可实现,而在最佳分类属性确定中,则需引入其他相关的方法。本次研究中选择两种确定分类属性的方法,其一为在抽取的所有属性中,均被当作匹配属性,各属性有相应的权重,此时选择其中权重较大的作为关键属性,使实体解析准确度提高。另外一种方法则细化为阈值与top-k方法,其中阂值方法运用下要求做信息增益阈值α的确定,与α相比属性信息增益值较大情况下,说明这一属性能够充当分类属性,反之则将该属性忽略。对于top-k方法,实现的原理在于通过权重排序,将排在前列的属性纳入属性集合中。通过上述两种属性集合确定方法,有助于实体解析召回率的提高以及关键属性的凸显,实体解析准确度因此得到保证。
3.3 计算相似度
相似度计算中,主要采用编辑距离方法实现。所谓编辑距离方法,指为取两个字符串,将其中一个向另外一个转换中需要的编辑次数,若编辑距离较大,意味两个字符串有较大差异,反之则相近。通过编辑距离相似度函数做基本相似度计算,在此基础上与对应属性权重相乘,便会获取相似度结果[3]。
3.4 引ABlocking技术优化
关于Blocking技术,主要指根据使用记录已知信息,判断记录是否相似,若相似可划入_组,该过程可称为Block。从該方法应用优势看,主要体现在利用快速识别技术,做记录匹配,由实体解析系统分析两条记录是否能够匹配,假若可在同一聚类中放入可匹配记录,说明两条记录匹配成功,而系统若判定两条记录无法匹配,最后的聚类内则无法放入匹配记录。因此,实体解析中,为使实体解析效率提高,考虑将Blocking技术引入其中,技术运用下在保证解析准确度的同时,将搜索空间缩小,实体或记录比较此时也因此较少,这对于实体解析效率的提高有积极作用[4]。
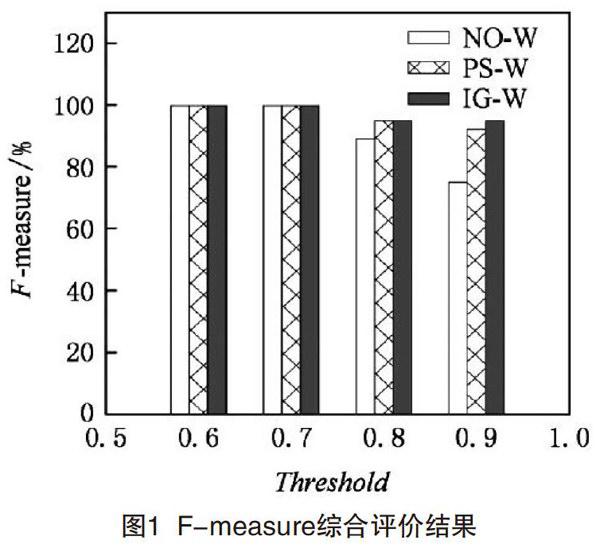
为验证以上方法应用下所得到的结果,本次研究中设定一定的实验环境,评价解析结果情况。其中在实验环境方面,取Microsoft Windows7为操作系统,选择Intel core 2Quad 2.67 GHz CPU为硬件环境,C++编译环境。同时,选择10 000条记录数据集,各记录被赋予10个属性,解析后以F-measure综合评价方法衡量评价,如图1所示,为最终评价结果。其中IG-W,PS-W,No -W分别表示信息增益方法、概率统计方法、无权重计算方法。由图中可发现,相比无权重计算方法,利用信息增益方法、概率统计方法取得的实体解析结果优势明显。
4 结语
实体解析是当前数据处理中的技术支撑。实际开展实体解析过程中,考虑做好属性权重确定工作,该过程需引入概率统计与信息增益方法,使个属性权重明确,与以往专家制定分配权重方法更能保证结果准确性,且对比相似度衡量无需过多的计算量,因此,未来在实体解析研究中应将这些属性权重方法作为主要研究实践方向。
[参考文献]
[1]宫云宝,甘亮,黄九呜.基于概率软逻辑模型的实体解析[J]计算机工程,2017(8):188-192,199.
[2]陈远,康虹,张静雅.基于IFC标准的BIM模型编程语言解析方法研究[J]土木建筑工程信息技术,2017 (3):85-89.
[3]高劲松,周习曼,梁艳琪面向关联数据的实体链接发现方法研究[J]中国图书馆学报,2016 (6):85-101.
[4]李文鹏,王建彬,林泽琦,等面向开源软件项目的软件知识图谱构建方法[J].计算机科学与探索,2017 (6):851-862.
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
