
基于Storm的分布式实时数据流密度聚类算法
2018-06-27 05:55:04牛丽媛张桂芸
天津师范大学学报(自然科学版) 2018年3期
牛丽媛,张桂芸
(天津师范大学计算机与信息工程学院,天津300387)
随着网络的不断发展以及大数据时代的到来,海量的数据分析变得尤为重要,数据流聚类是大数据处理的关键技术.流数据具有连续、实时、高维、有序等不同于传统数据集的特点.这要求数据流聚类算法要具备实时处理增量数据的能力;能够挖掘数据流中任意形状的簇;能够处理高速数据流,并要降低时间、空间复杂度,有效处理数据流中的噪声.Aggarwal等[1]在2003年提出的CluStream经典框架使用在线微聚类对数据流进行初始聚类,并按金字塔时间框架存储,按离线宏聚类对用户查询做出响应.文献[2]提出的基于密度的空间数据流在线聚类算法OLDStream,在先前聚类结果上对增量空间数据进行聚类,但该算法仅通过对新增空间点及其满足核心点条件的邻域数据做局部聚类,来实现空间数据流的在线聚类,不能体现数据流聚类的实时性.文献[3]提出的DRCluStream算法对CluStream进行了改进,将流数据的在线微聚类部分拆分成局部和全局2个部分做分布式计算,但由于在线微聚类过程中使用K-means聚类方法,需要用户指定聚类的簇数,且算法使用基于距离的度量准则,聚类结果均趋于球形,无法挖掘任意形状的簇.文献[4]提出了DBSCAN增量式聚类算法,该算法对新增数据聚类后,按照规定逻辑将结果合并到已有数据中,从而避免了对已有数据进行“二次聚类”,但它只对单个增量数据的合并逻辑进行了处理,并没有考虑到批量数据的合并,因此对于较大级别的增量数据,其增量合并的效率较低.基于以上研究的不足,本文提出一种分布式混合数据流聚类算法DBS-Stream.该算法在局部节点使用CluStream经典框架,利用DBSCAN初始化数据,得到非球形聚类结果,从而克服了CluStream框架对非球形和噪声数据聚类效果不佳的缺点,同时,对多个局部聚类结果进行增量合并,在一定程度上弥补了DBSCAN算法的不足,在中心节点采用基于密度的聚类算法,对全局进行再次聚类,同时在Storm分布式环境下实现算法,避免了提前确定K值,因此可有效优化聚类效率和通信代价.
1 基本概念和算法
1.1 基本概念
定义1对空间中一点p及距离r,以p为中心、r为半径的区域内数据点的个数称为点p关于距离r的密度,记为 D(p,r).
定义2对空间中任一点p、距离r,及给定阈值pmin,若 D(p,r)≥pmin,则称 p 为核心点.
定义3对核心点q,以该点为中心、r为半径的圆形区域{p∈D|dist(p,q)≤r}称为核心点q的邻域,记为Nr(q),其中dist(p,q)表示p、q之间的距离.
定义4对于核心点q,点p∈Nr(q),而点p为非核心点,称p为q所在簇的边界点,不在任何簇中的点称为孤立点.
定义5给定一列空间点p1,p2,…,pn,若pi直接密度可达于 pi+1(i=1,2,…,n-1),则称 p1密度可达于pn.
定义6带有时间戳T1,T2,…,TN的d维点集X1,…,XN,称(2d+3)元组为微簇,其中:和分别表示数据的一阶矩和二阶矩,CF2t表示时间戳的平方和,CF1t表示时间戳的和,n表示微簇中的数据点个数.
定理若核心点p分别属于2个簇C1和C2,则C1和C2可密度相连为一个簇.
证明设当前数据集为D.因为核心点p∈C1,所以任意属于簇C1的空间点o都密度相连于点p,又由于任意密度相连于点p的空间点都密度可达于核心点p,所以任意空间点o∈C1都密度可达于点p.同理,任意空间点o′∈C2也都密度可达于点p.因此o∈C1和o′∈C2密度相连,所以C1和C2可密度相连为一个簇.
定理的结论说明若核心点p分别属于多个聚类簇,则可以合并这些簇为一个簇,因此核心点最终仅属于一个簇.
1.2 CluStream经典两段式框架
CluStream是经典的两段式流聚类框架.一段是在线微聚类过程,首先利用K-means算法初始化微簇,并将结果按金字塔时间帧结构储存,然后提取实时流入的数据流特征进行增量维护微簇,通过为每个微簇定义一个阈值,来判断新到达的数据点属于某个已有的簇或需要创建一个新簇.若需要创建一个新簇,为了保持q值不变,需要删除最近最少使用的簇或者对2个已有的簇进行合并.同时,利用离线宏聚类对用户查询作出响应.另一段是离线部分,根据用户给定的时间范围h和期望的宏簇数目k,对不同时间粒度的聚类结果进行查询.将当前时间点tc的快照减去tc-h的快照,得到最近时间范围h内的快照N(tc,h),然后将N(tc,h)视为加权虚拟点,利用Stream算法进行聚类,得到时间范围h内的数据流聚类结果.
1.3 DBSCAN算法
DBSCAN是典型的密度聚类算法.其基本思想是寻找相邻区域内密度可达的部分,将其聚成一类.它的优势是可以利用类的高密度连通性快速发现任意形状的类.首先从数据库对象集D中任取一点p,并给定半径r和数据点阈值pmin;然后确定D中从p关于半径r密度可达的所有数据点的邻域.如果p是核心点,则可找到一个关于r和pmin的类;如果p是一个边界点,则p被暂时标注为孤立点.
2 分布式实时数据流密度聚类算法DBS-Stream
2.1 算法基本思想
DBS-Stream算法采用CluStream两段式流数据处理框架和DBSCAN算法,并将CluStream的在线微聚类过程分为局部节点聚类(生成局部微簇)与中心节点聚类(利用局部微簇对全局微簇进行增量更新)2部分,这种做法可有效解决内存消耗过大的问题,进而降低时间复杂度.
DBS-Stream算法具体步骤为
(1)中心节点初始化全局微簇.
(2)在一个单位时间内,局部节点接收待挖掘的数据.
(3)到达下一个单位时间后,利用局部节点处理数据,生成局部微簇结果,并发送结果到中心节点.
(4)判断局部微簇是否能合并到全局微簇,若能则合并,若不能则将局部微簇作为新微簇加入到全局微簇.
(5)删除全局微簇中权重不满足条件的微簇,并更新金字塔存储快照.
在局部节点聚类中,为克服K-means算法的局限性和缺点,使用DBSCAN代替K-means进行聚类,产生局部微簇.具体过程为,数据流进入每个局部节点后,在单位时间t内使用DBSCAN算法对局部节点累积的数据进行聚类,得到局部节点的核心点、边界点和孤立点.为了节省内存开销,局部节点采用滑动窗口模型,对先到达的数据设定较低权重,而后到达的数据设定较高权重.
在中心节点聚类中,为尽量降低时间复杂度,将孤立点舍弃.中心节点利用局部节点发送的核心点与边界点对全局微簇进行增量更新.具体过程为,判断局部节点微簇的核心点是否与全局微簇的核心点直接密度可达,若是,则将二者合并,同时更新簇内数据的平均到达时间,若否,则生成新的微簇并添加到全局微簇结果;然后根据时间权重在全局微簇结果中移除过期的微簇;最后存储更新后的全局微簇结果,等待下一次增量更新[5].
2.2 算法描述
算法实现的伪代码如下.
初始化数据:中心节点根据初始化数据进行DBSCAN聚类,获得中心节点初始聚类结果:由核心点集合P、边界点集合Q、孤立点集合O组成.
在线部分:
局部节点在线聚类:
Input:新到达的数据P,时间间隔t.
Output:局部节点DBSCAN之后的微簇结果(核心点集合,边界点集合,孤立点集合,当前时间).
Begin:
Repeat:
t时间间隔内,获得到达的数据点集合P;对数据集合P进行DBSCAN聚类;通过聚类结果得到微簇.发送聚类结果到全局节点.
End
全局节点增量合并:
Input:局部节点发送来的局部聚类结果,微簇删除周期T.
Output:全局增量合并后的聚类结果.
Begin:
得到局部节点发送的微簇;初始化合并结果记录数组R.
Repeat:取得中心节点的微簇.
Repeat:获取局部节点微簇Xi.
IF(Xi可以和 Yi合并)
{记录Yi可以合并Xi,将这条结果保存到R}
Until遍历所有局部节点的微簇.
Until遍历所有中心节点的微簇.
根据合并结果记录数组R,合并局部微簇到中心节点微簇,同时更新每个微簇的时间.
没有被合并到中心节点的微簇各自作为一个新的微簇结果,合并进中心节点微簇.遍历中心节点微簇.
IF(当前时间 tc微簇的 t< T)
{删除该微簇}
根据微簇结果更新金字塔结构.
End
离线部分:DBSCAN满足用户查询.
3 在Storm平台上的实现方案
3.1 Storm部署
Storm[6]是一个实时的、分布式的具备高容错的计算系统.Storm的核心组件[7]中Nimbus是主节点,负责资源分配和任务调度;Supervisor是配置的从节点,负责接受Nimbus分配的任务,并启动worker用以运行具体处理组件逻辑的进程.worker中每一个spout/bolt的线程称为一个task.
在Storm中,需要设计一个用于实时计算的图状结构,即拓扑.这个拓扑会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(workernode)执行.一个拓扑中包括spout和bolt两种角色,spout发送消息,bolt则负责转换这些数据流,并完成计算、过滤等操作.
3.2 DBS-Stream算法在Storm平台上的拓扑图
DBS-Stream算法在Storm平台上的拓扑图见图1.图1中,SpoutA接收初始化数据,将其发送到DBSCAN Blot;SpoutB通过KAFKA[8]接收实时到来的待处理数据,并发送到Local Bolt;SpoutC做时间计算;SpoutD接收初始化参数,将其发送到DBSCAN Blot;Spout E通过KAFKA接收用户的查询参数,并发送到Macro Clustering Bolt;DBSCAN Bolt以SpoutA和SpoutD传送来的初始化数据和参数进行初始化全局微簇.Local Bolt属于分布式部分,到达的数据会平均分配到每一个Local Bolt线程.当接收到SpoutC传送来的时间信息后,在Local Bolt上生成局部微簇,并将结果发送到Redis进行保存.Global Bolt实现全局微簇的增量更新,SpoutC传送时间信息后,Global Bolt开始取出Redis中的数据进行全局微簇结果的增量合并.Macro Clustering Bolt接收SpoutE传送来的用户查询参数,对Global Bolt中的全局结果进行聚类查询,并将查询结果发送到Print Bolt.

图1 DBS-Stream在Storm上的拓扑图Fig.1 DBS-Stream′s topology on Storm
4 算法实验与结果分析
4.1 实验环境与数据集
算法实验在实验室小集群上实现,集群中设有1个Nimbus节点和3个Supervisor节点,软件环境由Jdk-1.8.0-32bit、Zookeeper-3.4.6、Storm-0.9.1、KAFKA-2.9.1、Redis-2.4.5等构成,操作系统为centos6.4.实验采用的数据集是经过预处理的酵母菌数据集[9],描述预测蛋白质的细胞定位点包含1 486条实例数据,数据分布状况为:CYT(细胞质或细胞骨架)463条;NUC(核)429条;MIT(线粒体)244条;ME3(膜蛋白,无N末端信号)163条;ME2(膜蛋白,未切割的信号)51条;ME1(膜蛋白,裂解信号)44条;EXC(细胞外)37条;VAC(液泡)30条;POX(过氧化物酶体)20条;ERL(内质网腔)5条.实验通过每秒随机抽取该数据集中的100条数据来模拟数据流.数据集共含9维属性,其中1个是序列名称,另外8个预测属性分别是mcg、gvh、alm、mit、erl、pox、vac和 nuc.
4.2 实验结果与分析
对DBS-Stream和CluStream在Storm上处理相同数据集的聚类精度(clutering accuracy)进行对比,结果见图2.由图2可见,本算法的聚类质量高于CluStream,而且在数据量不是很大的时候明显高于CluStream.DBS-Stream通过在局部节点进行局部微簇聚类,可以过滤大部分噪声数据,同时在全局节点合并时会根据时间权重有效处理权重低的微簇,也进一步保证了聚类质量.
对于相同的数据流,DBS-Stream和CluStream产生的通信代价(communication cost)见图3.由图3可见,DBS-Stream的通信代价要明显低于CluStream.因为与CluStream相比,DBS-Stream会对聚类结果中无效的噪声点进行过滤,避免了无效数据的传输,从而较CluStream节省较多的通信资源,因而在通信代价上具有明显的优势.噪声点的存在也会降低聚类的质量和效率,因此DBS-Stream对噪声点的处理既降低了通信代价,又提高了聚类的质量和效率.
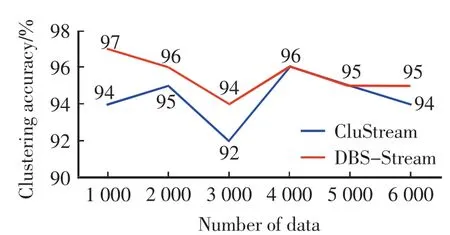
图2 DBS-Stream算法和CluStream的聚类精度Fig.2 Clustering accuracies of DBS-Stream and CluStream
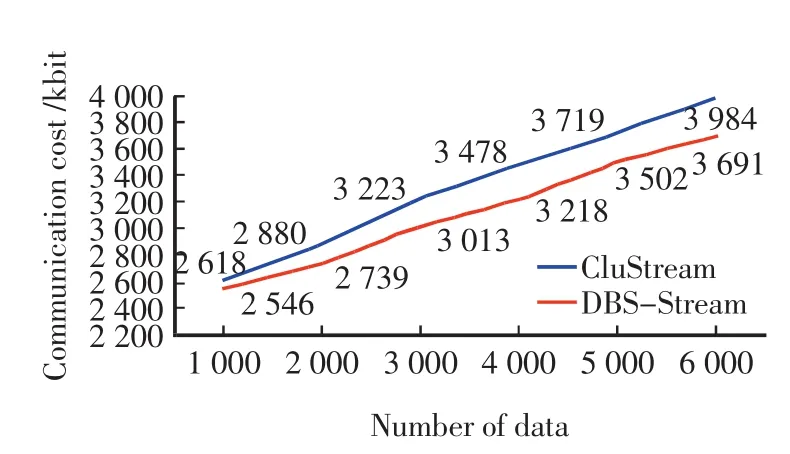
图3 DBS-Stream算法和CluStream的通信代价Fig.3 Communication costs of DBS-Stream and CluStream
图4给出了依据测试结果得出的线程处理压力(threadhandlingpressure)与线程个数(numberofthread)的关系.由图4可见,Local Bolt线程的处理压力随着并行线程数的增加而降低,Global Bolt线程的处理压力随着并行线程的增加呈净增加的趋势.该测试结果与理论一致.
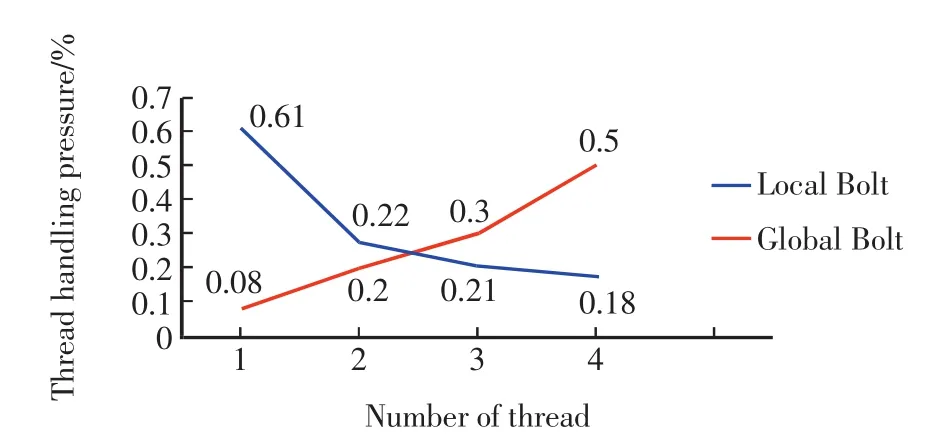
图4 线程处理压力与线程个数的关系Fig.4 Relationship between thread handling pressure and number of thread
利用数据集单位时间产生固定的数据条数来模拟数据流,分别用CluStream和DBS-Stream处理相同的数据流,处理所用时间t(processing time)见图5.由图5可见,DBS-Stream与CluStream的执行时间均随数据流的增长呈线性增长趋势.DBS-Stream处理时间略长,这是因为DBSCAN算法的复杂度比K-means高,但DBSCAN的优势在于可对任意形状的簇进行聚类.当数据条数较大时,二者处理时间相差不大,不超过10%,属于可接受范围.总体上说,相对于DBS-Stream在聚类精度和通信代价方面的优化,在处理时间上稍做牺牲是值得的.
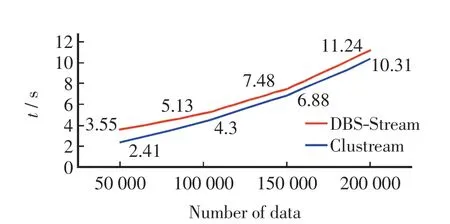
图5 DBS-Stream和CluStream的处理时间Fig.5 Processing time of DBS-Stream and CluStream
5 结束语
基于Storm平台的DBS-Stream算法与CluStream算法相比,在聚类质量及通信代价方面均有较好的表现,并且DBS-Stream算法可以处理任意形状的数据流,在聚类结果的形状上没有偏倚,而且不需根据经验确定K值,也就无需对数据形成先验知识.
[1]AGGARWAL C C,HAN J W,WANG J Y,et al.A framework for clustering evolving data streams[C]//Proceedings of the 29th VLDB Conference,Berlin,2003.
[2]于彦伟,王沁,邝俊,等.一种基于密度的空间数据流在线聚类算法[J].自动化学报,2012,38(6):1051-1059.YU Y W,WANG Q,KUANG J,et al.A density based spatial data flow online clustering algorithm[J].Acta Automatica Sinica,2012,38(6):1051-1059(in Chinese).
[3]马可,李玲娟.分布式实时流数据聚类算法及其基于Storm的实现[J].南京邮电大学学报(自然科学版),2016,36(2):104-110.MA K,LI L J.Distributed real-time streaming data clustering algorithm and its implementation based on Storm[J].Journal of Nanjing University of Posts and Telecommunications(Natural Science Edition),2016,36(2):104-110(in Chinese).
[4]田路强.基于DBSCAN的分布式聚类及增量聚类的研究与应用[D].北京:北京工业大学,2016.TIAN L Q.DBSCAN-based Distributed Clustering and Incremental Clustering Research and Application[D].Beijing:Beijing University of Technology,2016(in Chinese).
[5]高宏宾,侯杰,刘劲飞.分布式密度和中心点数据流聚类算法的研究[J].计算机应用与软件,2013,30(10):181-184.GAO H B,HOU J,LIU J F.Research on distributed density and centralized data flow clustering algorithm[J].Computer Application and Software,2013,30(10):181-184(in Chinese).
[6]陈东明,刘健,王冬琦,等.基于MapReduce的分布式网络数据聚类算法[J].计算机工程,2013,39(7):76-82.CHENG D M,LIU J,WANG D Q,et al.A distributed network data clustering algorithm based on MapReduce[J].Computer Engineering,2013,39(7):76-82(in Chinese).
[7]Apache.Storm:Distributed and fault-tolerant realtime computation[EB/OL].http://storm.Apache.org,2015-09-18/2017-08-09.
[8]Apache.Apache Kafka:A high-throughput,distributed,publish-subscribe messaging system[EB/OL].http://kafka.Apache.org,2015-09-18/2017-08-12.
[9]UCI.Kenta Nakai.Datasets yeast[EB/OL].http://archive.ics.uci.edu/ml/datasets/Yeast,2015-09-19/2017-09-12.
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
汽车维修与保养(2020年11期)2020-06-09 05:42:22
金桥(2018年4期)2018-09-26 02:24:54
电脑与电信(2018年12期)2018-03-23 02:37:36
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
西北工业大学学报(2015年3期)2015-12-14 13:08:48
电子设计工程(2015年6期)2015-02-27 12:04:53
中国卫生(2014年7期)2014-11-10 02:32:54
