
基于自适应形状上下文特征的实时杆号识别
2018-06-26 10:19谭泽富
计算机工程与应用 2018年12期
杨 梅,谭泽富,蔡 黎
重庆三峡学院,重庆 404000
1 引言
随着我国高铁线路的不断建设,高铁运营里程不断增加,运营速度越来越快,如何保证高速铁路的安全运营已经成为一个重要的课题。为了快速发现问题解决问题,减少检测所需人力,利用图像检测方式对接触网进行检测显得越来越重要。而利用图像检测方式,其中一个重要的模块在于将一杆的图像归到正确的杆号下,为此要达到精确归档需要利用图像识别算法对杆号进行识别。
铁路杆号牌不像汽车号牌具有统一的标准。不同线路的号牌样式不一样,有横向号牌、竖向号牌、四位数的号牌、三位数的号牌以及字体大小也不尽相同,这就加大了实时杆号识别的难度。2015年朱挺[1]对接触网支柱号在线智能识别定位技术进行了研究,其主要是利用常规的图像识别技术,如图像分割、字符提取、特征提取以及分类识别等进行杆号识别,其存在的问题是算法的适应性差,只能适用于竖向号牌的识别,不能实现横向号牌的识别。因此,这种算法很难应用到实际工程中。
传统杆号识别算法[2-3]主要是利用常规的图像识别技术,如图像分割、字符提取、特征提取以及分类识别等进行杆号识别。识别过程中,需要将图中的字符一个一个地单独提取出来分别识别,算法的每一步与前后两步都具有较强的耦合性。采用神经网络[4]、SVM[5-6]等机器学习算法对样本进行学习后再分类识别的方法,识别的准确率受到字符的字体样式、大小、宽度等因素影响。为了提高识别的准确性,需要收集足够多的字符样本进行训练;同时,为了满足检测的需要,每条线路可能需要配置不同的识别算法;分类识别算法开发的工作量大,周期长,稳定性以及识别的实时性难以保证。因此,上述方法用于杆号识别具有较大的局限性,不能快速适应线路检测的需要。本文基于Shape Context[7-8]进行实时杆号识别,算法将整个号码牌作为一个整体,一次将里面的数字全部识别出来,解决不同线路杆号的差异性对识别带来的困难。实验表明,本文方法具有良好的通用性、较高的准确率和较好的实时性。
2 Shape Context形状匹配
2.1 形状上下文特征
形状上下文特征[9]于2002年被提出,它通过对图像边缘采样得到表示物体形状的特征点的集合,n表示特征点的数目。对于边缘任意一个特征点,它与其他n-1个特征点可以构成n-1个特征向量[10],如图1所示字符“2”的一个特征点的部分特征向量。以n-1个特征向量构成一个列向量,从而对于n个特征点就形成了一个n×(n-1)的特征向量矩阵。
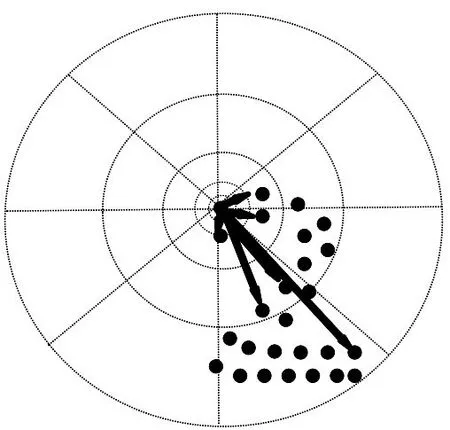
图1 一个特征点对应的特征向量示意图
为了便于统计,采用直方图来表示这些特征向量。对于特征点 pi,在对数极坐标映射下,其余n-1特征点分布直方图hi(k)为[11]:
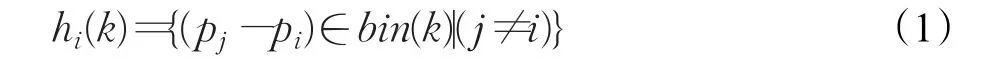
式(1)中,1≤k≤K,K为直方图栅格数目。
2.2 形状上下文匹配度计算
利用上述特征点抽取及特征信息计算方法对所有字符模板进行特征信息提取,然后利用卡方距离计算模板字符与杆号图像中的字符的匹配代价,匹配代价函数计算方法如式(2):
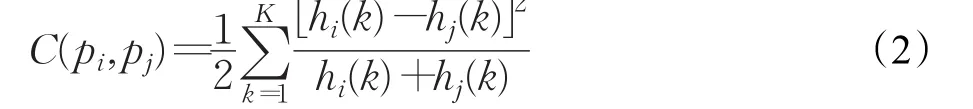
式(2)中,形状 p中 pi点的形状直方图用hi(k)表示,形状q中qj点的形状直方图用hj(k)表示。
为了得到字符的最优匹配结果,需要利用最优匹配算法使整个代价最小。最后基于这个最优匹配得到整个形状代价,以作为两个形状之间的差别衡量,代价越小,形状匹配度越高,形状代价函数如式(3):

薄板样条(TPS)变换模型[12-13]可以把非刚性的映射准确地分解成非仿射性变换和仿射变换,其物理意义[14]是:在二维空间中,如果模板表示成有n个点组成的点集A,待匹配目标是由n个点组成的点集B,点集B中的n个点用TPS变换来模拟形变,从而保证n个点可以正确的匹配。在Shape Context算法中,点集之间一一对应,可以使用TPS变换模型最小化弯曲能量求解点集之间的映射参数及匹配矩阵。薄板样条仿射函数 f(x,y)在对应点集{xi}和{yi}最小弯曲能量函数如式(4):
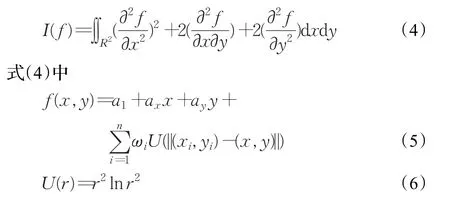
通过选择α和ω来最小化弯曲能量。
3 基于自适应Shape Context的实时杆号识别
3.1 字符模板提取
模板是算法的重要组成部分,模板质量的优劣也直接决定了识别结果的好坏。模板内容为杆号字符的轮廓,轮廓越清晰越完整,匹配效果也越好。
本文采用基于双阈值的canny边缘检测算法对字符边缘进行提取。提取步骤为:
(1)选择成像质量较好的杆号图像,如图2(a)。
(2)框选需要提取的字符,如图2(b)。
(3)提取字符轮廓,如图2(c)。
(4)根据式(7)调整提取的轮廓质量。
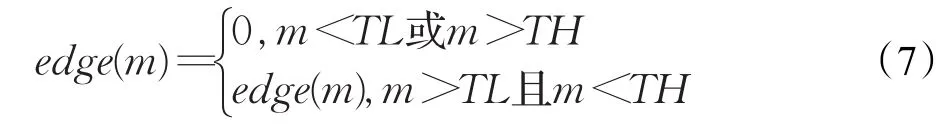
式(7)中,m为边缘像素点的个数,TL为边缘像素点个数的最小阈值,TH为边缘像素点个数的最大阈值。

图2 字符模板提取过程图
根据字符模板提取方法依次提取杆号中出现的字符0~9,同时根据采集时的角度不同、隧道内外杆号的字体、大小等不同,同一个字符可以提取多个模板用于字符匹配,以提高识别准确率。对于一条线路,在相机角度没有较大变化时,只需1个模版即可。
3.2 实时杆号识别
实时杆号识别是指在采集图像的过程中将采集到的杆号图像中的杆号利用图像识别的方式得到杆号,对实时性和准确率要求较高。识别算法主要包括图像预处理、基于Shape Context的形状匹配算法以及根据匹配结果得到杆号的自适应策略算法。
3.2.1 图像预处理
由于铁路白天运营车辆较多,杆号图像的采集时间一般为晚上,采集的图像如图3所示。采用形状匹配算法耗时与图像的大小相关,一般图像越小,完成匹配的时间越短。从图3可以看出,如果只取出图像中的号牌部分用于形状匹配的时间会远远小于利用整幅图像进行形状匹配的时间。为此需要利用图像分割获取到号牌所在位置的图像。

图3 杆号图像
首先利用式(8)对图像进行分割处理,结果如图4所示。

式(8)中,T为分割阈值,取值通过Otsu阈值算法[15]自适应获取,该算法计算简单快速,在保证检测效果的同时极大缩短了检测时间。

图4 杆号图像分割结果
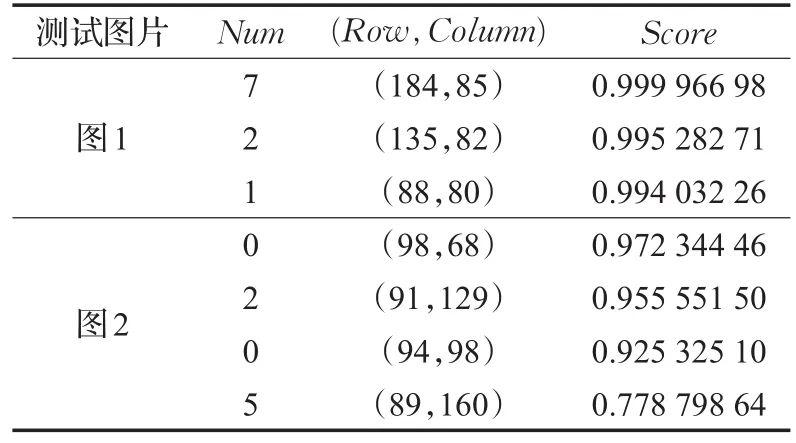
根据不同号牌中数字部分所占面积与号牌面积比例的大小,设两个面积阈值T1、T2,其中T1 将图4中第i个连通区域二值化,从而将号牌中的背景和数字分割出来,area(i)为数字部分的面积与联通区域面积的比值。号码牌一般是3~4个数字,T1的值为提取的模板中数字区域与模板号牌区域面积比值的最小值,T2的值为模板数字区域与模板号牌区域面积比值的最大值。 由于字符一般为黑色,为了分割出的区域包含字符,需要利用式(10)对图4所示的结果进行膨胀处理得到图5(a)、(b)所示结果。 式(10)中,结构元素B为100×100的结构元素。 图5 杆号图像分割后进行膨胀处理的结果 利用式(11)对图5中的目标区域计算平行于坐标轴的包围杆号区域的最小外接矩形,并得到矩形区域的图像如图6所示。 图6 杆号区域图像 将图6所示的矩形区域用于形状匹配,匹配的效率将会得到大大提高。 3.2.2 基于Shape Context的形状匹配算法 在Shape Context算法中,图像形状不是以区域轮廓来表示,而是由一些离散且分布均匀的特征点来描述,然后针对点集中的每个特征点计算其对应的形状直方图,最后两个形状之间的匹配问题就转化成了两个特征点集之间的匹配度问题。本文中,将利用3.1节得到的所有字符模板与杆号图像中的杆号字符进行匹配,匹配算法的结果为杆号图像中字符中心坐标对应于匹配度最高的字符模板。本文基于Shape Context的自适应杆号识别算法流程如图7。 利用3.1节的杆号模板提取算法对预处理得到的杆号图像,如图6进行边缘提取,处理结果为图8。采用轮廓跟踪算法对提取出的轮廓目标进行特征点抽样,轮廓跟踪算法[16]步骤如下: 步骤1首先按从上到下,从左到右的顺序扫描图像,寻找没有标记跟踪结束记号的第一个边界起始点A0,A0是具有最小行和列值的边界点。定义一个扫描方向变量dir,该变量用于记录上一步中沿着前一个边界点到当前边界点的移动方向,其初始化取值为: (1)对4连通区域取dir=3。 (2)对8连通区域取dir=7。 图7 基于Shape Context的自适应杆号识别算法流程 图8 杆号区域图像边缘标注 步骤2按逆时针方向搜索当前像素的3×3邻域,其起始搜索方向设定如下: (1)对4连通区域取(dir+3)mod 4。 (2)对8连通区域,若dir为奇数取(dir+7)mod 8;若dir为偶数取(dir+6)mod 8。 (3)在3×3邻域中搜索到的第一个与当前像素值相同的像素便为新的边界点An,同时更新变量dir为新的方向值。 步骤3如果An等于第二个边界点A1且前一个边界点An-1等于第一个边界点A0,则停止搜索,结束跟踪,否则重复步骤2继续搜索。 步骤4由边界点A0、A1、A2、…、An-2构成的边界即为要跟踪的边界。 特征点的选取是Shape Context算法中至关重要的一步,为了避免计算量过大和特征信息的丢失,本文选取的特征点个数为120。 根据上述方法得到杆号图像中每个目标的最优匹配结果,匹配度Score采用式(12)计算: 式(12)中,Dsc表示Shape Context的相似度,Dbe表示弯曲能量相似度。 用图4所示的两幅图像进行匹配测试,匹配结果如表1所示。Num表示识别结果,(Row,Column)是识别出的每个目标字符的中心的位置,Score表示字符对应的最高匹配度,其中,匹配度已经做了归一化处理。 表1 匹配结果 3.2.3 自适应策略算法 在实际应用场景中,存在图3所示不同类型的杆号牌。3.2.2小节得到了正确的数字,但数字的位置并没有确定,本节将根据3.2.2小节的计算结果利用自适应策略算法得到正确的杆号结果。自适应策略算法步骤如下: 步骤1去除低匹配度数据,设阈值T1。 (1)当Score≥T1时,匹配结果有效。 (2)当Score 步骤2判断号牌的方向。 (1)分别取出匹配数据的X和Y坐标序列。 (2)对取出的X和Y坐标序列分别做排序处理,结果为{x1,x2,…,xn},{y1,y2,…,yn}。 (3)利用下式对第(2)步得到的结果进行计算,得到{dx1,dx2,…,dxn},{dy1,dy2,…,dyn}。 (4)设阈值T2,判断第(3)步结果中dx,dy小于T2的个数分别为Nx,Ny。 (5)如果Nx≥Ny,号牌为横向号牌,反之则为竖向号牌。 步骤3根据号牌方向,得到号牌结果。 (1)若为横向号牌:根据X坐标对匹配结果由小到大排序。 (2)若为竖向号牌:根据Y坐标对匹配结果由小到大排序。 (3)根据排序结果,将匹配字符组合得到杆号结果。 利用自适应策略算法对表1中的数据进行处理后得到对应的杆号为:127、0025。 为了验证本文方法的有效性,选取100帧铁路现场采集设备采集的图像进行实验。由于铁路运输系统白天比较繁忙,检测试验只能在晚上,所以,采集到的图像全是夜间图像。实验配置为:Win7 64位操作系统、NVIDIA GeForce 405显卡、4GRAM、Intel®CoreTMi3-2120 CPU 3.30 GHz,实验软件平台为Matlab。 图9~13是选取的100帧图中其中4帧对号牌的识别过程及结果。图9是原始图像,(a)、(c)图的采集距离较远,杆号牌较暗淡模糊且光照不均,(b)、(d)图的采集距离较近,杆号牌比较清晰;图10中红色区域是对原始图像进行分割后膨胀处理的结果;图11是根据膨胀结果提取的杆号区域及边缘特征点(标红的点);图12是匹配出的匹配度最大且大于0.5的匹配结果,“+”表示模版号版数字的特征点,“O”表示号牌中数字的特征点;图13是识别出的号牌,从结果可以看出,无论是纵向号牌、横向号牌还是有污渍的号牌,都能识别出杆号。 图9 原图 图10 杆号图像分割后膨胀处理的结果 图11 提取的杆号区域 为了从数据上本方法的准确性和快速性,将本文方法与传统的模版匹配、BP神经网络、SVM方法进行比较,不同方法下的识别率、准确率和耗时如表2。 图12 最大匹配度下的匹配图 图13 识别结果 表2 不同方法下的指标参数 从表2可以看出,本文算法的识别率高于其他几种方法,准确率达到97%。同时本文算法在速度上具有较大优势,很好地满足了工程实践。 本文从工程应用实际出发,结合传统杆号识别算法存在的问题,提出了一种基于Shape Context的形状匹配实时杆号识别算法。该算法利用已知的模板字符与杆号图像通过Shape Context形状匹配算法进行杆号识别和定位,然后通过自适应策略算法得到正确的杆号。对于铁路杆号识别,与传统算法相比,对于不同形状,不同大小的杆号牌,本文方法辅以较少的配置就可以实现杆号识别,识别准确率95%以上,具有更大的适用范围和通用性。 [1]朱挺.基于接触网支柱号在线智能识别定位技术研究[J].上海铁道科技,2015(1):24-25. [2]武翔宇.基于图像的接触网支柱检测与编号识别[D].成都:西南交通大学,2015. [3]丁超员.字符识别技术在机车元件检测中的应用研究[D].江苏苏州:苏州大学,2013. [4]刘万军,梁雪剑,曲海成.基于双重优化的卷积神经网络图像识别算法[J].模式识别与人工智能,2016,29(9):856-864. [5]姜映映,田丰,王绪刚,等.基于模板匹配和SVM的草图符号自适应识别方法[J].计算机学报,2009,32(2):252-260. [6]施隆照,强书连.基于组合支持向量机的车牌字符识别[J].计算机工程与设计,2017,38(6):1619-1623. [7]Lades M,Vorbruggen J C,Buhmann J,et al.Distortion invariant object recognition in the dynamic link architecture[J].IEEE Transactions on Computers,1993,42(3):300-311. [8]Amit Y,Grenander U,Piccioni M.Structural image restoration through deformable templates[J].Journal of the American Statistical Association,1991,86(414):376-387. [9]Belogie S,Malik J,Puzicha J.Shape matching and object recognition using shape contexts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(2):509-522. [10]Belongie S,Malik J,Puzicha J.Shape matching and object recognition using shape contexts[J].IEEE Transactions on Pattern Analysis& Machine Intelligence,2010,24(4):509-522. [11]韩敏,郑丹晨.基于模糊形状上下文特征的形状识别算法[J].自动化学报,2012,38(1):69-75. [12]Duchon J.Splines minimizing rotation-invariant seminorms in Sobolev spaces[M]//Constructive Theory of Functions of Several Variables.Berlin Heidelberg:Springer,2006:85-100. [13]杨小娜.基于形状上下文的目标形状识别与匹配[D].昆明:昆明理工大学,2013. [14]夏小玲,柴单.基于Shape Context的形状匹配方法的改进[J].东华大学学报:自然科学版,2009,35(1):79-83. [15]覃海松,黄忠朝,赵于前,等.一种新的MLBP-Otsu算法及在舌裂纹分割中的应用[J].计算机工程与应用,2014,50(23):151-155. [16]Ang Y H,Li Zhao,Ong S H.Image retrieval based on multidimensionalfeature properties[C]//Proceedings of SPIE,1995,2420:47-57.


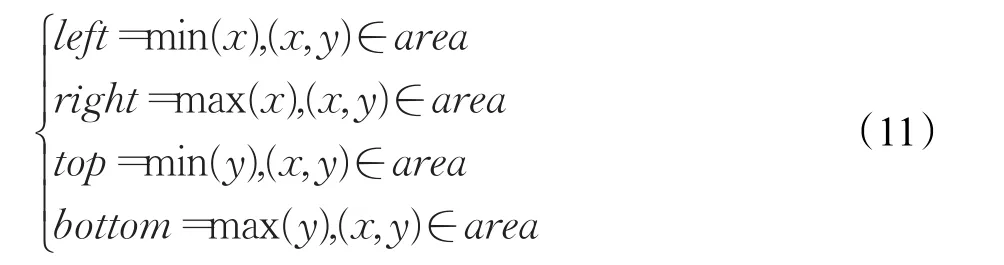

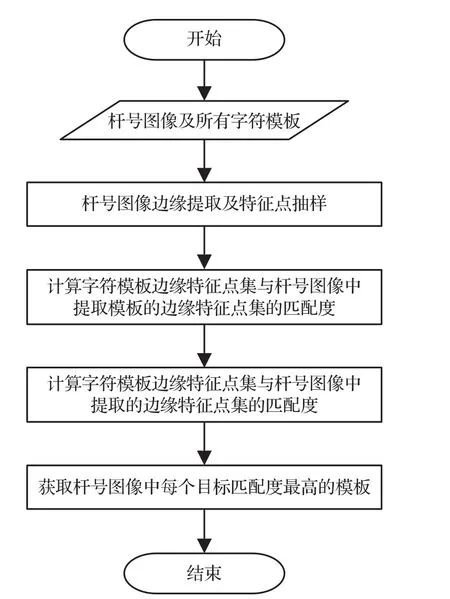


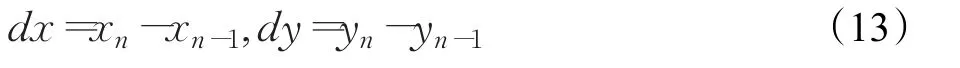
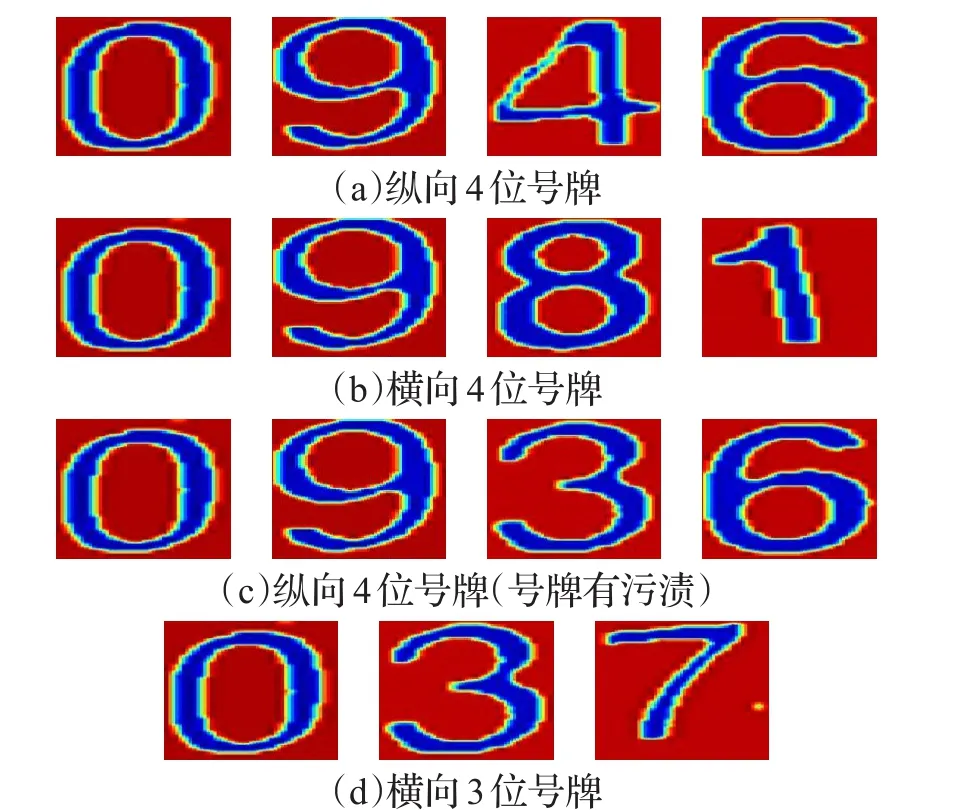
4 实验结果及分析




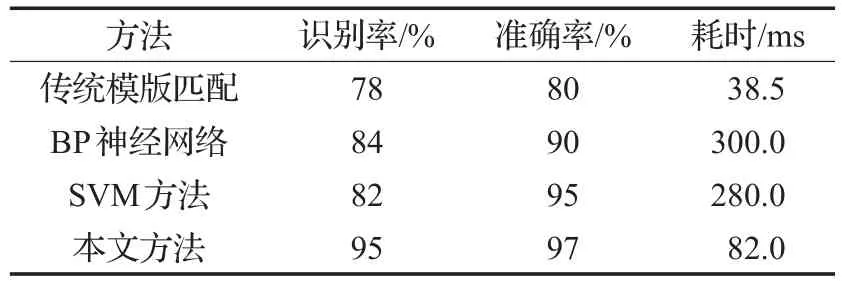
5 小结
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25汽车与驾驶维修(汽车版)(2020年6期)2020-07-24小学生学习指导(低年级)(2019年12期)2019-12-04电子制作(2019年19期)2019-11-23数字通信世界(2019年3期)2019-04-19新世纪智能(英语备考)(2018年11期)2018-12-29时代农机(2018年10期)2018-12-12少儿美术(快乐历史地理)(2018年7期)2018-11-16小学生学习指导(低年级)(2016年10期)2016-12-01人民交通(2016年4期)2016-03-20
