
基于模糊理论的医院人事档案信息推荐系统
2018-06-22 02:59:30徐竞
微型电脑应用 2018年6期
关键词:权重
徐竞
(赤峰市医院, 内蒙古 赤峰 024000)
0 引言
随着移动互联网的普及与应用,许多三甲医院均推出了智能手机APP与PC端的自助挂号系统[1]。病患用户通过检索医院的医疗资源与专家医生的人事档案选择合适的医疗服务,准确、快速地检索出专家医生的档案是其中最基础、最关键的部分[2-3]。
医院人才的专业性强、人才流动性大、人事信息检索频率高,随着医院信息化建设与移动互联网的接入,使得当前的人事档案信息已经无法满足应用需求[4]。把人事档案信息化管理与医院行政档案、医护人员绩效考评管理有效地对接,能够为医护人员绩效考评提供依据,能够促进医护人员的工作效率与积极性,并且能够为患者用户带来有效的判断依据[5]。
目前的医院人事信息搜索系统主要基于关键字搜索[6],并未有效地利用搜索内容的信息[7],如果患者用户搜索某个专家医生或者某个病症,则系统直接返回与关键字匹配的医生文档信息,如果该医生挂号满员或者无法满足用户的时间要求,则会降低用户的满意度。因此,为医院人事信息搜索系统增加关联性信息[8]与自动推荐功能[9]是医院信息化建设的发展方向。
本文提出了一种基于模糊理论[10]的医院人事档案信息推荐系统,该系统利用了相关反馈技术[11],提取用户的操作特征并且预测用户的兴趣,此外,为文档、用户、检索任务建立基于关键词频率的配置文件,从而提高检索的效率。最终,基于公开的文档数据集进行了仿真实验,结果证明本算法获得了较好的检索结果,并且产生了相关性较高的推荐列表。
1 总体架构
本算法基于相关反馈与模糊理论。将相关反馈作为用户的查询任务、用户、文档配置文件的主要数据源。用户配置文件将用户的兴趣建模,文档配置文件包含了不同用户检索某个文档所使用的不同关键字,任务配置文件包含了不同用户完成同一个任务所使用的不同关键字。将每个任务、用户、文档建模为配置文件中关键字的加权组合,然后与用户查询的关键字比较,通过计算各个配置文件的关键字权重来搜索与用户查询最相关的信息。
用户的检索目标具有不一致性,所以医院人事档案检索系统的相关反馈具有较高的不确定性,而处理好相关反馈的不确定性是提高推荐效果的关键。本文采用模糊理论处理相关反馈的不确定性。本算法的总体结构,如图1所示。
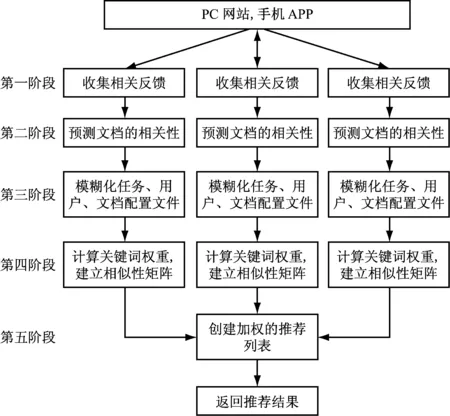
图1 本算法的总体结构
共包含6个阶段。阶段1:收集相关反馈;阶段2:预测文档的相关性;阶段3:模糊化任务、用户与文档配置文件;阶段4:计算关键词权重;阶段5:产生加权的推荐列表。
1.1 收集相关反馈
在检索系统的上层设计了一个模块来捕获用户的相关反馈信息,如图2所示。
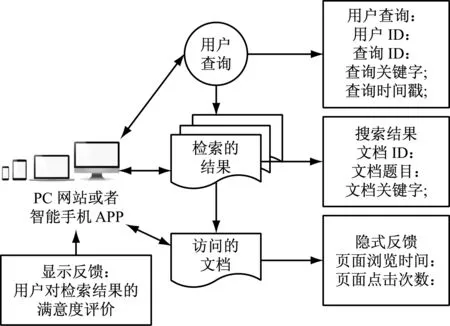
图2 收集相关反馈的过程
相关反馈信息包含隐式参数、显式参数、用户查询与互动特征。隐式参数包括:访问时间戳、页面访问时长、鼠标点击数量、手机屏幕滑动、鼠标滚动等,显式参数则是用户对检索结果的满意度评价,查询信息包括:查询内容、查询时间戳等。互动特征则主要是某个文档是否被用户打开阅读。
1.2 预测文档的相关性
使用线性预测模型与线性回归分析,根据隐式反馈参数计算访问文档的相关性,如表1所示。使用R2评估验证模型的准确率。具体步骤如下:
步骤①:将隐式参数与显式参数分类。
步骤②:对隐式参数与显式参数进行相关分析,识别出对用户反馈具有明显意义的隐式参数,通过排除与显式相关性没有关系的隐式参数,由此可降低参数的数据维度。本文使用IBM-SPSS-Statistics Version 22软件[12]自动地实现相关性分析。IBM-SPSS-Statistics Version 22软件[12]的相关性分析结果,如表1所示。
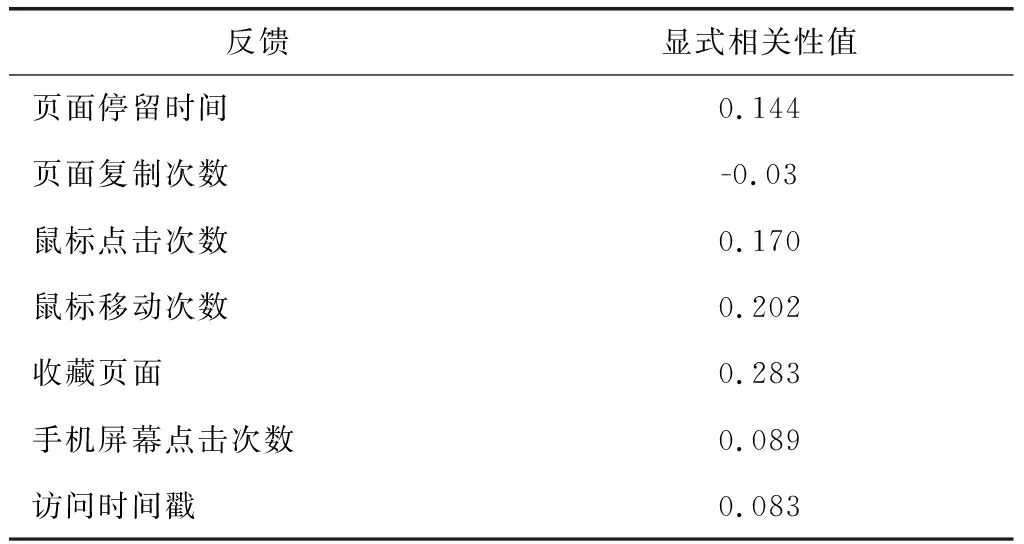
表1 IBM-SPSS-Statistics Version 22软件的相关性分析结果
对于显式相关性有明显意义的隐式参数包括:页面停留时间、鼠标点击数量、手机屏幕点击数量。将这些隐式参数用于步骤③的分析处理中。
步骤③:根据隐式参数预测访问文档的相关性级别,使用线性回归模型分析、计算预测值,线性回归的回归模型包括三个参数:系数β(未知参数),预测器X(独立变量),目标Y(依赖变量),一个线性回归模型可定义,为式(1)[13]:
Y≈f(X,β)
(1)
估计值可定义为E(Y|X)=f(X,β),一般多线性回归模型具有N个独立变量与一个依赖变量[13],为式(2)。
(2)
式中Y′为依赖变量的预测值,β0为截距,βi为变量系数,Xi为自变量,N为独立变量数量。
步骤②的候选隐式参数作为回归分析的预测器,搜索隐式参数与显式参数的线性相关性关系。分析的结果,如表2所示。
将显著度≥0.05的变量作为预测模型的预测器。将表2中的结果代入式(2),显式相关性级别的线性预测模型变为式(3)。
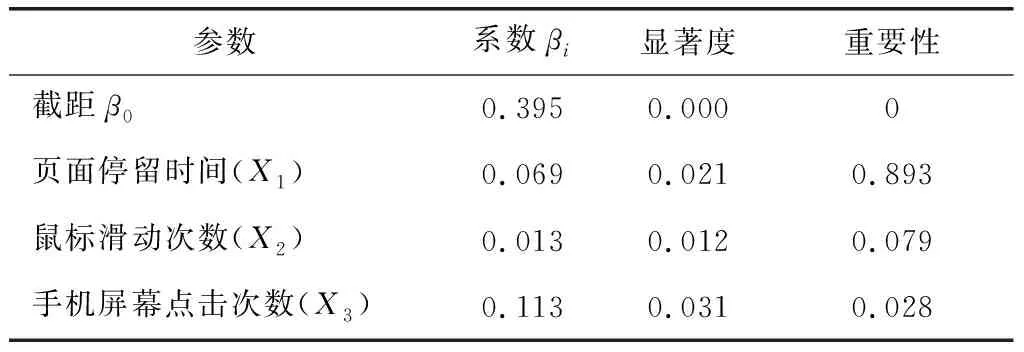
Y′=0.395+X1×0.069+X2×0.013+X3×0.113 (3)
然后,对式(3)进行归一化处理,为式(4)。
(4)
1.3 任务、用户与文档的模糊化配置文件
采用一个自适应模糊方案创建任务、用户、文档的配置文件,构建3个配置文件的方法分别在2.1、2.2、2.3小节详细描述。
1.4 计算关键词权重
将任务、用户与文档3个配置文件总结为统一的关键字权重指标。对于检索任务Sy,如果用户Uk使用关键字ti检索文档Dg,那么对于ti的统一化权重为Wiykg,统一权重考虑了关键字与3个配置文件的总体相关性。该阶段共有4步:
步骤①:提取模糊规则。
使用Mendel Wang方法[14]为输入变量与输出变量建立模糊逻辑的关系,如图3所示,本文采用三角隶属函数。三个参数{a,b,c}即可确定三角隶属函数的形状,三角隶属函数定义,为式(5)。
(5)
式中参数{a,b,c}决定了三角形隶属函数3个角点的x坐标。
最终建立“IF…THEN…”的模糊规则。假设B是模糊逻辑标记{L,M,H}(低、中、高),则模糊规则定义为:
B(WX1),B(WX2),B(WX3)→B(Rh)
(6)
该式表示将X1,X2,X33个参数的权重输出为统一的三角模糊值。
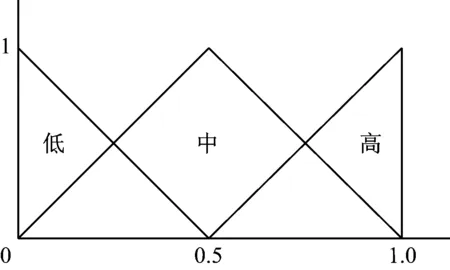
图3 输入变量与输出变量建立模糊逻辑的关系(x轴为三角模糊函数的输入值,y轴为三角模数函数的输出值)
步骤②:压缩模糊规则。
本方案使用模糊支持度与规则的可靠性来评估规则的置信度,规则的模糊支持度计算为规则的支持度与触发强度的乘积,规则的支持度则计算为数据模式的覆盖率,规则的触发强度评估了该规则与输入模式匹配的概率。
规则的模糊支持度可识别出与最频繁数据模式共生的唯一规则,模糊支持度是可扩展的。本方案采用模糊支持度将模糊规则库压缩为唯一的规则集,采用文献[15]的方法计算模糊支持度:
(7)

规则的置信度度量了该规则与数据模式的紧密性,置信度在0~1之间,置信度为1说明该规则是输出集的唯一模式。基于文献[16]计算规则的置信度:
(8)
步骤③:规则权重的计算。
计算模糊支持度与规则置信度的乘积来度量规则的模糊权重:
scWi=scFuzzSup×scConf
(9)
为M个规则分配模糊权重:
B(WX1),B(WX2),B(WX3)→B(Rh)[scWi]
(10)
模糊权重度量了建模数据中每个规则的质量,可用来对输出集进行排列。使用模糊权重来提取最相关的规则模式,选择scWi值最高的模式建立模糊系统。
步骤④:计算统一的关键词权重
模糊规则包含3个输入变量{Wsytez,Wuktez,Wdgtez},将三个权重总结为统一的权重Wiykg,然后将Wiykg值传递至下一阶段处理。
1.5 产生加权的推荐列表(人事文档/专家医生)
根据新的用户查询与参数集(Vh,ti,Sy,Uk,Dg,Wiykg)创建一个推荐的人事文档与专家医生列表。采用第一阶段的方法对新用户进行处理,提取关键字。然后,搜索查询关键字的参数集,获得匹配的文档与专家医生。
如果查询的关键字在参数集中出现,那么则认为该查询与对应文档匹配,然后,计算匹配关键字的平均权重,按照权重的高低将结果降序排列,最终,将推荐结果返回给用户。
2 三个配置文件的构建方法
2.1 用户配置文件
使用相关反馈创建用户的配置文件,配置文件中每个用户表示为一个加权关键词的集合,表示用户的兴趣。具体步骤如下:
步骤①:选择用户查询的文档集合Q。
步骤②:选择所有的用户集U。
步骤③:通过用户Uk创建的查询选择查询Q的子集ΩUk。
步骤④:对集合ΩUk的查询进行预处理,然后通过文献[16]算法变换为一个候选的关键词集合。
步骤⑤:计算每个关键词的频率度量、分布式关键词频率(DTF)、文档频率(DF)与反向文档频率(IDF),然后将每个集合ΩUk的各个指标归一化处理。
使用这些频率度量来计算一个文档集合中的关键词频率,DTF反应了用户查询集中关键词的频率域分布状态,DF表示了集合Q中包含该关键词的查询频率。最终,归一化的关键词分布频率(NDTF)定义:
NDTFi=(TFi/DFi)/(Maxj(TFj/DFj))
式中TFi为查询集ΩUk中关键词ti的频率,DFi为ΩUk中包含关键词ti的查询数量(i,j=1~M),其中M为集合ΩUk中关键词的数量。
归一化文档频率(NDF)的计算方法为:
NDFi=DFi/MaxjDFj
式中DFi为查询集合ΩUk中包含关键词ti的查询数量。
IDF表示查询集合Q中关键词的频率,归一化反向文档频率(NIDF)定义为下式):
NIDFi=IDFi/MaxjIDFj,IDFi=Log(N/ni)
式中N是Q中查询的总数量,ni是Q中包含关键词ti的查询数量。
步骤⑥:将3个输入变量的明确值作模糊化处理,全部映射为模糊集,NDF与NIDF有3个逻辑标签,NTDF有两个逻辑标签,输出变量TW共有6个模糊集。
步骤⑦:采用文献[18]的18个“IF…THEN…”模糊规则,建立关键词ti的模糊权重,搜索具有高NDF、高NIDF值、低NDTF值的关键词。
步骤⑧:采用加权平均法(重心法)对步骤⑦的输出TW做解模糊化处理,获得每个关键词的明确权重值TWUkti。
步骤⑨:将关键词ti与权重TWUkti加入配置文件中。
2.2 任务配置文件
任务配置文件中将每个任务表示为一个加权关键词的集合,权重反应了每个关键词与搜索任务之间的相关性。具体步骤如下:
步骤①:选择用户查询的文档集合Q。
步骤②:选择所有任务S的集合。
步骤③:通过用户查询创建查询集合Q的一个子集ΩSy。
步骤④:对集合ΩSy的查询进行预处理,然后通过文献[16]算法变换为一个候选的关键词集合。
步骤⑤:计算每个关键词的频率度量、分布式关键词频率(DTF)、文档频率(DF)与反向文档频率(IDF),然后将每个集合ΩSy的各个指标归一化处理。
步骤⑥:将3个输入变量的明确值作模糊化处理,全部映射为模糊集,与2.1小节的步骤⑥相同。
步骤⑦~⑨:与2.1小节的步骤⑦~⑨相同。
2.3 文档配置文件
在文档配置文件中,每个文档表示为一个加权术语的集合有被用户使用来检索文档相关性与他们的任务。权重反映了每个术语与文档的相关性。以下是具体步骤:
步骤①:选择用户查询的文档集合Q。
步骤②:选择访问的文档集合D。
步骤③:通过用户查询创建文档集合Q的一个子集ΩDg。
步骤④:对集合ΩDg的查询进行预处理,然后通过文献[16]算法变换为一个候选的关键词集合。
步骤⑤:计算每个关键词的频率度量、分布式关键词频率(DTF)、文档频率(DF)与反向文档频率(IDF),然后将每个集合ΩDg的各个指标归一化处理。
步骤⑥:将三个输入变量的明确值作模糊化处理,全部映射为模糊集,与2.1小节的步骤⑥相同。
步骤⑦~⑨:与2.1小节的步骤⑦~⑨相同。
3 实验结果与分析
3.1 实验环境与配置
采用公开的文档检索数据集TREC Enterprise Track-2007[19]进行实验,该数据集共包含370 715个文档,数据集大小为4.2 GB,包含了不同的文档类型,例如:html文件、text文件、pdf文件等。本系统基于开源软件搭建,由以下几个部分组成:Apache Solr[20]、Apache Tika[21]、Hadoop[22],Hadoop是分布式计算的开源框架,Tika是分析与采集不同类型文档的开源软件,Solr是企业级ISR服务器的开源软件。本实验系统的总体架构,如图4所示。

图4 实验的推荐系统总体架构
随机地邀请了35个用户参与实验,每个用户根据自己的需求检索。
3.2 实验结果与分析
3.2.1 线性预测模型验证
使用R2指标验证模型的准确率,R2指标是一个广泛使用的统计模型准确率度量指标,R2的计算方法为式(11)。
(11)
线性预测模型的R2指标结果,如图5所示。
预测的R2指标为92.3%,可通过提高相关反馈的相关性提高模型的R2指标值。
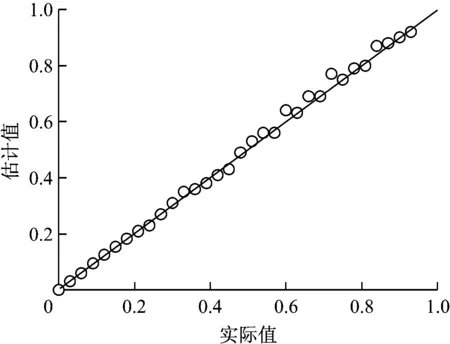
图5 本系统预测值与实际值的拟合图
3.2.2 检索算法的性能比较分析
为了评估总的推荐性能,将本算法与其他两个检索算法进行比较,两个算法分别为标准Solr搜索系统[20]与基于语义的企业检索系统Lucid。两个系统都是基于Solr的搜索平台,区别在于第一个算法使用标准变化索引,第二个算法则使用语义索引。
精度与召回率是评估信息检索性能的两个重要标准,精度与召回率可评估系统检索相关文档的能力,检索系统的精度定义,为式(12)。
P=|Ra|/|A|
(12)
式中Ra是检索的相关文档数量,A是检索文档的总数量,包含检索出的所有文档。
召回率评估了系统代表所有相关文档的能力,R定义,为式(13)。
R=|Ra|/|Rm|
(13)
式中Ra是检索相关文档的数量,Rm是文档集中相关文档的总数量。
3个检索算法获得的结果,如表3所示。

表3 三个检索算法获得的精度与召回率结果
标准Solr系统的平均P值为0.004 28,说明该系统检索了大量不相关的文档。基于语义搜索的Lucid算法P值是0.029 8,明显地高于标准Solr系统,本算法的平均P值为0.071,明显地改进了检索准确率。换句话说,本算法有效地减少了搜索结果中不相关文档的数量,说明本算法加强了相关文档的检索准确率。
根据式(12),增加相关文档的数量或者减少非相关文档的数量均可能导致P值增加,本算法设计了基于模糊规则的配置文件,提高了对相关文档的过滤效果。
4 总结
为了提高医院人事文档信息检索系统的检索模糊性与多样性,设计了一种基于模糊理论与相关反馈的医疗信息推荐系统。本算法收集用户的隐式相关反馈与显式相关反馈,使用线性预测模型与线性回归分析基于隐式反馈参数分析文档的相关性,根据隐式参数预测访问文档的相关性级别,使用线性回归模型分析、计算相关性的预测值,采用一个自适应模糊方案创建任务、用户、文档的配置文件,根据新的用户查询与相关性参数集创建一个推荐的人事文档与专家医生列表。将本算法与其他近期的检索算法进行比较,本算法设计了基于模糊规则的配置文件,提高了对相关文档的过滤效果。
[1] 黄健,王珏,卞寿峰,等. 上海市部分医院一站式服务系统使用现状的调查与分析[J]. 中国卫生资源, 2015(3):185-187.
[2] 欧石燕,唐振贵,苏翡斐. 面向信息检索的术语服务构建与应用研究[J]. 中国图书馆学报, 2016, 42(2):32-51.
[3] 王元卓,贾岩涛,刘大伟,等. 基于开放网络知识的信息检索与数据挖掘[J]. 计算机研究与发展, 2015, 52(2):456-474.
[4] 李蕤. 新形势下中医医院人才培养的重点[J]. 山西财经大学学报, 2015(s1):167-168.
[5] 宋兵,卢建华,丁强,等. 医院近10年人才流失现状分析与思考[J]. 海南医学, 2015, 26(19):2941-2944.
[6] 刘喜平,万常选,刘德喜,等. 空间关键词搜索研究综述[J]. 软件学报, 2016, 27(2):329-347.
[7] 韩军,范举,周立柱. 一种语义增强的空间关键词搜索方法[J]. 计算机研究与发展, 2015, 52(9):1954-1964.
[8] Geng Runian, Dong Xiangjun, Zhang Ping,等. Mining weighted frequent patterns using local graph linking information利用局部图关联信息挖掘加权频繁模式*[J]. 计算机应用研究, 2008, 25(9):2687-2691.
[9] 聂晓,翟小兵. 改进ART算法在数据库自动知识推荐中的应用[J]. 科技通报, 2015(4):215-217.
[10] 徐军,钟元生,朱文强. 一种基于直觉模糊理论的多维信任传递模型[J]. 小型微型计算机系统, 2015, 36(12):2714-2718.
[11] 曹斌,彭宏杰,侯晨煜,等. 基于用户隐性反馈与协同过滤相结合的电子书籍推荐服务[J]. 小型微型计算机系统, 2017, 38(2):334-339.
[12] Kirkpatrick L A, Feeney B C. A Simple Guide to IBM SPSS Statistics for Version 20.0[J]. 2012.
[13] 苏变萍,曹艳平.基于灰色系统理论的多元线性回归分析[J]. 数学的实践与认识, 2006, 36(8):219-222.
[14] Wang L X, Mendel J M. Generating fuzzy rules by learning from examples. IEEE Trans Syst Man Cybern[J]. IEEE Transactions on Systems Man & Cybernetics, 1992, 22(6):1414-1427.
[15] Wu D, Mendel J M, Joo J. Linguistic summarization using IF-THEN rules[C]// IEEE International Conference on Fuzzy Systems. IEEE, 2010:1-8.
[16] Ishibuchi H, Yamamoto T. Rule Weight Specification in Fuzzy Rule-Based Classification Systems[J]. IEEE Transactions on Fuzzy Systems, 2005, 13(4):428-435.
[17] Porter M F. An algoritm for suffix stripping[J]. Program Electronic Library & Information Systems, 2006, 14(3):130-137.
[18] Schiaffino S, Amandi A. Intelligent User Profiling[M]// Artificial Intelligence An International Perspective. Springer Berlin Heidelberg, 2009:193-216.
[19] Bailey P, Vries A P D, Craswell N, et al. Overview of the TREC 2007 Enterprise Track.[C]// Sixteenth Text Retrieval Conference, Trec 2007, Gaithersburg, Maryland, Usa, November. 2007:947-954.
[20] Serafini A. Apache Solr Beginner's Guide[J]. Packt Publishing, 2013.
[21] Burgess A B, Mattmann C A. Automatically classifying and interpreting polar datasets with Apache Tika[C]// IEEE International Conference on Information Reuse and Integration. IEEE Computer Society, 2014:863-867.
[22] 朱珊,艾丽华. 基于Hadoop的大规模图像存储与检索[J]. 计算机与现代化, 2017(6):61-66.
猜你喜欢
高技术通讯(2021年2期)2021-04-13 01:09:46
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
Computer Modeling In Engineering&Sciences(2018年5期)2018-07-11 08:01:24
电信科学(2017年6期)2017-07-01 15:44:57
Asian Herpetological Research(2016年4期)2017-01-20 11:06:27
应用科技(2015年5期)2015-12-09 07:09:51
计算机工程(2014年6期)2014-02-28 01:27:24
河南科技(2014年15期)2014-02-27 14:12:51
教育与职业(2014年4期)2014-01-19 09:08:18
