
基于LDA的主题分类系统研究
2018-06-19 02:14郭英杰千博
无线互联科技 2018年3期
郭英杰 千博


摘要:当前人类处于信息爆炸的时代,对于海量的文本数据,可以利用人工智能的工具来提高数据分析处理的效率,来挖掘海量数据的宝藏。文章主要对文本的主题分类算法进行研究,通过改进分类方法并提出可视化方案,使主题分类具有更好的应用价值。首先通过利用LDA主题分类算法进行处理,并提出了一些改进方法使分类效果更优,并最终生成可视化的主题分类结果,进而用于推荐系统、数据挖掘、数据分析等领域。
关键词:自然语言处理:主题分类;数据可视化
自然语言处理是机器学习中的热门领域,随着Internet上数据产出的速度越来越快,文本挖掘广泛用于特征抽取、语义关系挖掘、文本聚类等领域,并且在实践的基础上对文本挖掘的算法进行了丰富的研究和改进。本文给出一个基于文档主题生成模型(Latent Dirichlet Allocation,LDA)的主题挖掘的完整应用,通过爬虫来抓取特定网站的数据,在数据预处理(包括分词、去停用词、词频计算、特征向量化)后,利用LDA主题分类算法进行处理,并通过对分类过程优化和算法改进,得到良好的主题分类效果,最终利用玫瑰图等可视化方式推送给用户,进而将结果利用在知识存储、推荐系统、数据分析等场景。本文最后以某老人健康网站为例,应用该系统展示分类效果。
1 数据采集与预处理
1.1获取数据源
获取数据源的方式多种多样,为了面向数据不断积累的互联网,本节设计了爬虫组件来灵活获取数据源。爬虫[1],是按照一定规则来自动抓取万维网信息的程序或者脚本,是获取信息的有效方式之一。本文设计了基于双阻塞队列的并行化爬虫策略,对某老人健康网站持续爬取,截至当前积累了16 430篇有关老人养老、健康等方面的文章。
1.2文本预处理
对于文本预处理来说,首先需要对文本分词,对于中文的分词处理比拉丁系语言难度更大。和大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字串的形式出现。把字串变为词串难点在与消除歧义[2],本文使用Jieba分析系统,其python版本最高可以完成1.5 MB每秒的分词速度。
其次对于原始文本来说,带有很多噪声,这时运用停用词过滤的技术进行文本预处理[3]。停用词除了不會让日常用词等噪声影响分析结果外,同时也极大降低了计算规模。预处理的最后一步,就是建立词袋模型,这是对语料集的特征向量化,为随后的计算做准备。
2 文本主题分类
2.1 LDA主题模型
LDA为3层贝叶斯概率模型[4],包含文章、主题、词语3层结构,一种无监督的机器学习算法。在LDA中,主题是指在文本集合内具有隐含相关性的词语的组合,适用于文字信息的提炼和归纳。LDA建模过程的概率图模型如图l所示,其中,阴影部分里的圆圈表示观测变量,阴影外的圆圈表示隐含变量,箭头表示变量之间的关联。
LDA主题建模的核心思想认为,一篇文档的生成是一个“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”的过程。在LDA中参数αfalse和βfalse由用户凭经验事先给定,LDA的概率图模型可以得到联合分布率公式:
求解的常用方法包含EM算法、Gibbs抽样法等。本文采用Gibbs抽样法[5],其核心思想为每次只排除当前维度,然后给定其他维度的变量值采样,再用这些采样来估算出当前维度的值。不断重复迭代上述过程直到收敛,得到待估参数。
2.2用TF-IDF改进系统
对于LDA来说,可以发现潜在的主题,但是在分析过程中会有很大的噪声,这些噪声并不是常见的停用词,而是一些在文档中出现的某些干扰词,所以需要从“大局观”的角度来去除燥声,而TF_IDF[6]在这计算词汇重要度方面表现优异,可以通过对文档集进行非重要词过滤,同时保留重要度最高的那部分即可。
3 数据分析
3.1主题分类结果
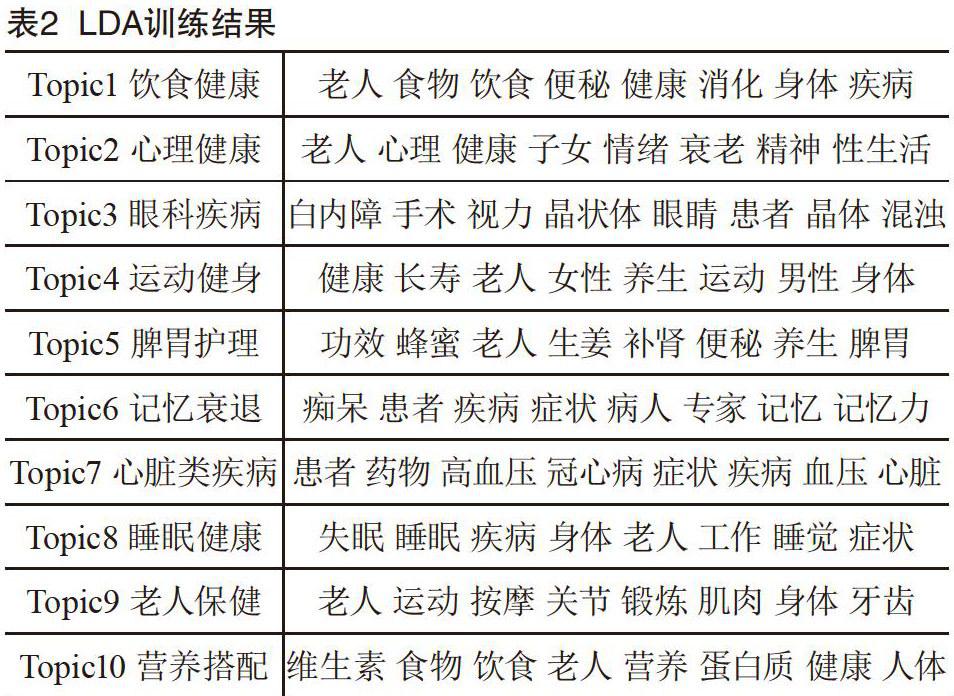
本文系统使用python开发,其中算法部分利用scikit-learn和numpy等开源框架实现,可视化部分利用G2[7]提供的工具。并利用采集的16 430个相关文章作为原始语料,进行分析处理和结果展示。对语料分为10个主题分析,并展示每类主题前8个关键词(见表2)。
3.2数据可视化
“一图胜干言”是数据可视化[8]在数据分析等领域作用的简短体现,便于我们得知其中隐藏的各种联系,进而便于展示和做出决策。主题分类输出的南丁格尔玫瑰图可视化结果如图2所示,可以推断出在该网站上,老人的饮食结构和心脑疾病是最受关注的,老人保健和运动相关主题其次。
4 结语
本文通过运用分词、停用词过滤、数据可视化等手段建立了基于LDA算法对互联网数据进行主题分类系统,通过对大量文本数据的主题模型建立,可以分析主题趋势和用户关注点。在大数据场景下,分布式处理是提高效率的有效手段,今后可以利用spark等开源分布式处理软件,提高本系统应对互联网海量数据的能力。
猜你喜欢
艺术与设计·理论(2016年4期)2017-01-16
计算机应用(2016年12期)2017-01-13
科技传播(2016年19期)2016-12-27
求知导刊(2016年10期)2016-05-01
