
融合类别线索词的中文问题分类
2018-06-19 07:50杨思春万家山
苏州科技大学学报(自然科学版) 2018年2期
高 超 , 杨思春 ,万家山
(1.安徽信息工程学院 计算机与软件工程系,安徽 芜湖 241000;2.中国科学技术大学 计算机科学与技术学院,安徽 合肥230027;3.安徽工业大学 计算机科学与技术学院,安徽 马鞍山243032)
自动问答技术(Question Answering,QA)[1]目前在自然语言处理领域是一个热门方向。通过自动问答技术可以理解自然语言表达的问题,并可以精确抽取问题的答案。目前通常情况下所设计的自动问答系统都包含以下三个部分:问题分析、段落检索以及答案抽取[2]。问题分析作为自动问答系统中的第一步,为后续的检索和抽取都供了约束作用,有着很强的指导意义。因此,问题分析在自动问答系统中起着重要的作用。
问题分析主要完成问题分类、问题主题识别、问题指代消解和问题句法分析等。其中最常用的问题分析方法就是问题分类。问题分类的主要目的是通过问题答案将该问题分类到某一类别当中,后续的检索和抽取会根据该类别从而采取不同的策略。有研究指出,问题分类的性能可以直接影响整个自动问答系统的性能[3]。
早期问题分类主要采用了基于规则的方式,需要人为的制定大量的语法规则,且分类的效果并不具有普适性。后来使用基于统计的方式(如:Bayes,K近邻,SVM等)进行分类,分类的精度往往和特征提取的好坏相关。特征提取越丰富,分类的精度就越高。传统上问题分类由于含有的文本信息不如文本分类丰富。因此,仅仅使用词袋特征不能有效的捕捉问题中词语的语义关系,往往不足以提高分类的精度,还需要更深入的提取问题中其他的相关语义信息。
针对上述问题,笔者在原有的词袋特征基础上,进一步提出一种基于问题类别线索词的绑定特征来提高问题分类的精度。另外,针对于目前中文问题分类语料数据集的不足,文中也通过实验详细考察了在不同规模、不同分布上的该绑定特征对于分类性能的影响。
1 相关工作
在早期工作中,问题分类主要采用了手工构造规则的方式进行。但由于这种方法不可能构造出适合所有问题的统一规则,因而缺乏普适性。后续工作中普遍采用了基于统计的方法,提取问题相关词法、句法和语义等特征进行问题分类[4]。具有代表性的如Huang等[5]采用疑问词,unigram,核心词,以及WordNet等特征,在UIUC数据集小类上分类精度达到89.2%;Loni等[6]采用了unigram,bigram,核心词和WordNet等特征在UIUC数据集小类上也获得了89%的分类精度。
可见基于统计的方法在英文问题分类上已经有很好的效果。在中文问题分类领域,受限于中文句子的复杂性,很难从问题中抽取有效的特征,因此中文问题分类的方法较为困难。具有代表性的如:余正涛等[7]采用高频词汇作为特征,对有标签和无标签两类数据通过Co-training的方式,分别在大类和小类上获得88.9%和78.2%的精确率;Liu L等[8]采用结合依存分析结果和词性信息作为核函数的方法,分别在大类和小类上获得了85.18%和80.66%的精确率。
另外随着深度学习方法的广泛使用,越来越多的学者也将深度学习方法应用到自然语言处理领域[9-11]。如Haihong等[12]采用多通道双向长短期记忆网络结合多粒度卷积网络进行问题分类,在TREC数据集上达到了96.6%的准确率。中文问题分类方面李超等[13]采用混合长短时记忆网络和卷积神经网络的学习框架在大类上达到93.08%的精确率。
从上述工作中可见,对于中文问题分类的准确率很大程度上受限于中文问题特征的提取或者特征模型的建立。对于中文问题分类来说,可以将其看作一种特殊的文本分类。但其与一般的文本分类又有所不同。通常情况下一个问题所包含的文本较少,不能像传统文本分类一样获取大量的信息。若仅从问题的文本角度来看信息较少,就需要从问题的句法或语义信息去挖掘更多对分类有用的信息。
对于中文问题分类,常见的做法是采用基本词袋特征(bag-of-word,BOW)和词性特征(part-of-speech,POS)进行分类。但该方法并不能获取更能表达语义信息的其他特征,从而损失分类精度。此外,目前对于已标注的问题集数据较为匮乏,语料标注需要大量的人力和时间资源。因此,如何利用目前已有的小规模不平衡的数据资源来提升分类的性能也是一个迫切的问题分类任务。针对小规模不平衡数据进行学习训练,传统的方法主要有过采样或欠采样以及调整权重方法[14]。但现实中在数据集规模较小的情况下,使用采样的方式来调整数据集从而弥补不平衡问题是难以实现的。因此,笔者曾提出了一种绑定特征的方法进行问题分类[15]。在分别提取问题中的词袋、词性和词义等基本特征及其对应的词袋绑定特征的基础上,通过将基本特征与词袋绑定特征进行融合,以获取更加高效的问题特征集合。但通常情况下引入所有词袋可能会引入噪声数据,问题中并不是所有包含的词都可以准确的刻画问题的类别。例如:在问题“非洲第一高峰乞力马扎罗山的海拔高度是多少?”中,对于刻画问题类别有效的词仅仅只是其中的几个能够体现分类特征的线索词。因此,笔者就提出了一种问题类别线索词的特征提取方法来提高对分类具有贡献的词的权重,从而提高问题分类的精度。
2 特征提取方法
2.1 基本组合特征提取方法
由于一般情况下中文问题中所包含的文本信息相对较少,基本的词袋信息通常会忽略掉句子中词的顺序、词性等信息。因此,文中采用LTP平台对问题进行分析,从问题中提取基本特征,包括:词袋特征、词性特征、命名实体(NE)和依存关系(DR)。例如:对于问题“非洲第一高峰乞力马扎罗山的海拔高度是多少?”,通过LTP平台进行分析后可以得到如图1所示的结果。并通过将BOW、POS、NE特征组合起来作为Baseline组合特征使用,可以有效的弥补传统词袋特征对于句子信息的缺失。

图1 基于LTP平台的问题分析结果
2.2 基于线索词的绑定特征提取方法
一般来说,通过问题中的主干词(主语,谓语和宾语)以及疑问词和疑问词相关词可以有效确定问题的类别。如上述问题中,其疑问词和其相关词分别是“高度”,“是”,“多少”,“多少”和“是”。因此,借鉴文勖等[16]的做法,通过问题类别线索词特征提取算法将问题中的核心词(HED)、主语(SBJ)、疑问词(QW)及其相关成分(REL)定义为问题类别线索词集(Category Clue Words set,CCWs)。问题类别线索词特征提取算法伪码如下:
输入:经过分词、词性标注、命名实体识别处理后的问题文本。
输出:问题类别线索词集合 (HEDs,SBJs,QWs,RELs)
1:Initialization sent=[W1,W2,…,Wn],Wi=(head,rel) //词 i包含其父节点编号和依存关系名
2:for i from 1 to|W|do
3:if the rel of Wiis HED do add Wiin HEDs//若其依存关系为HED,则加入HEDs集合
4:for i from 1 to|W|do
5:if the rel of Wiis COO and the head of Wiin HEDs then add Wiin HEDs//若其依存关系为COO且其父节点是HED节点,则将其加入HEDs集合
6:for i from 1 to|W|do
7:if the rel of Wiis SBV and the head of Wiin HEDs and Wiis nearest to HED then add Wiin SBJs//若其依存关系是SBV且是其父节点HED最近的词,则将其加入SBJs集合
8:for i from 1 to|W|do
9:if each SBJ has several continuous Wiwhich rel is SBV or COO then add Wiin SBJs//若是从SBJ发出的连续的SBV或者COO关系,则将其加入SBJs集合
10:for i from 1 to|W|do
11:if pos of Wiis r and Wiis in Interrogative Table then add Wiin QWs//若其词性为r且存在于疑问词表,则将其加入QWs集合
12:for i from 1 to|W|do
13:if the head of Wiis in QWs then add Wiin RELs//若其父节点是疑问词,则将其加入RELs集合
通过上述算法,可以获得问题线索词集特征:是、高度、多少、是。针对中文问题分类任务来说,宾语常常会和疑问词或者疑问词相关词重合,但问题中隐含的其他句法语义特征并不可忽视。所以主干词中去除了宾语的成分。因此,将线索词特征分为两类:能直接表示问题类别的疑问词组合(QWs,RELs)和间接表示句法语义信息的主干词组合(HEDs,SBJs)。
2.3 绑定特征提取方法
文中也提出了一种基于绑定的自动生成分类特征方法。该方法通过绑定部分特征与其他基本特征从而自动地获得一种新的特征用于分类。这样可以利用所获取特征与词汇之间的语义关联,以很小的额外处理开销获得一类潜在的问题特征。
通过实验发现,将CCWs分别和词性进行绑定可以提高分类的精度。因此,文中采用以下四种特征组合,对不同规模和分布的数据集进行验证:
(1)Baseline基本组合特征:由词袋、词性、命名实体特征组合构成;
(2)疑问词组合特征(QW,REL):由疑问词和疑问词相关成分特征组合构成;
(3)主干词组合特征(HED,SBJ):由核心词和主语特征组合构成;
(4)绑定特征组合(REL/pos,HED/pos,SBJ/pos):由疑问词相关成分和词性绑定,核心词和词性绑定以及主语和词性绑定特征组合构成。
通过上述四种不同的特征,可以从不同的语义层次对问题进行表示。因此,采用组合绑定特征筛选算法,对不同组特征分别进行组合并分类,从而筛选出分类精度较好的特征进行保留。组合绑定特征筛选算法伪码如下:
输入:特征组合包括:baseline,疑问词组合特征=[QWs,RELs],主干词组合特征=[HEDs,SBJs],绑定特征组合=[REL/pos,HED/pos,SBJ/pos]。
输出:精度最高的组合绑定特征及其精度值
1:Initialization features group is baseline//初始化特征组合为baseline
2:for each groupiin[qr,sa,bfs]do
3:for each featurejin groupido
4:Accuracyj=SVM(featuresgroup+featurej)//计算组合新特征后经SVM分类器分类的精度
5:Accuracymax=Max(Accuracyj)
6:featuresgroup=featuresgroup+featuremax//将精度最高的一组特征加入特征组合
3 实验与分析
3.1 数据集
文中数据集采用哈尔滨工业大学社会计算和信息检索研究中心所提供的中文问题分类数据集。其中包含训练集4 966个问题,测试集1 300个问题。在此基础上,又通过人工标注的方法扩展了该数据集。其中扩展后的训练集6 522个问题,测试集2 749个问题。另外,通过对原训练集问题数量的调整均衡,得到在小类上基本分布平衡的训练集。各个训练集规模见表1。

表1 训练集和测试集规模
3.2 实验分析
为了验证支持向量机(SVM)算法在不同特征组合方法上的分类有效性,文中设计了3组实验分别来对问题集数据进行分类。首先针对哈尔滨工业大学问题数据集采用基本词袋特征和Baseline特征组合在整体数据集上进行分类预测,预测的精度如图2所示。
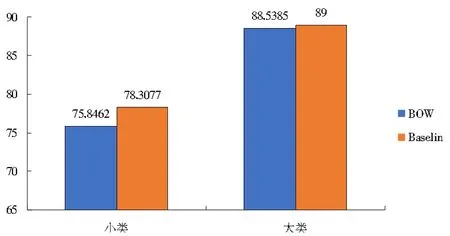
图2 BOW特征与Baseline特征分类精度对比
由图2可见,使用多种特征组合来对问题进行分类比单纯使用词袋特征的分类精度要高。因此,使用特征组合的方式可以有效提高SVM分类器分类的精度。此外由于训练数据的规模小且数据不平衡,对于SVM分类器的训练会造成一定的影响。为了弥补数据不平衡所带来的影响,可以采用对不同特征进行加权的方式调整。Baseline特征组合仅从词法的角度刻画了句子的成分和含义,在此基础上再组合疑问词组合特征和问题类别线索词组合特征就可以从不同的侧面来刻画句子的句法信息,从而达到对描述问题类别的特征进行加权。因此,采用组合绑定特征筛选算法,对不同组特征分别进行组合并分类。最终得到的最佳特征组合分别为Baseline特征组合,b+q+r(Baseline+QW+REL)特征组合,b+q+r+SBJ+HED特征组合,以及b+q+r+SBJ+HED+r/pos特征组合。各种不同特征组合在问题分类数据集上的分类效果如图3所示。

图3 各种最佳组合绑定特征的分类精度
由图3可见,对于小类分类不同的特征组合可以有效的提高分类的精度。对于类别数较少的大类分类来说,使用较少的特征组合就可以达到较好的精度,当特征组合过多时反而会引入噪声使得分类精度有所下降。也就是说,通过问题类别线索词组合特征的方式更利于类别数目较多的小类分类。
其次,对比在不同数据规模上的特征绑定方法分类的有效性。通过对训练集按照每个类别所占比例分别扩展30%和缩减30%,使用SVM分类器分类的结果如图4和图5所示。

图4 不同规模训练集在小类上的分类精度
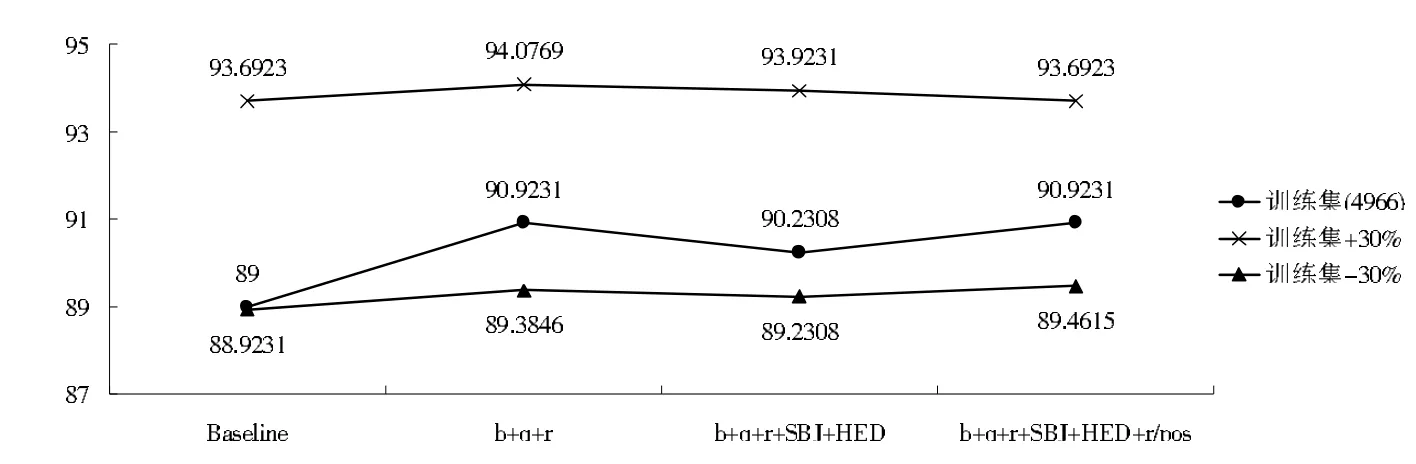
图5 不同规模训练集在大类上的分类精度
由图4和图5可见,在不同规模数据集上,数据集规模越小,使用基于问题类别线索词的组合特征能更快的提高其分类的精度。也就是说文中所设计的组合绑定特征在小规模语料之上是可以更好地体现出其合理性和优越性,提高分类算法的有效性。
另外,第三组实验通过手工采样方式设计在小类上基本分布平衡的数据集。通过图6比较也可以看出,原始数据集上最终分类精度在小类和大类上分别提高了2.23%和1.92%。而在平衡的数据集上分别提高了1.23%和1.46%。可以看出在原始数据集上采用文中设计的组合绑定特征可以更有效的提升分类的精度。所以基于问题类别线索词组合绑定特征可以适用于在语料数据分布不平衡的数据集中。

图6 原始数据集与均衡样本数据集分类精度对比
3.3 与现有同类工作的对比
文中采用了LibSVM来实现SVM多标签分类。以往的大多数学者都是采用Bayes分类器或者最大熵等分类方法。基于中文问题分类数据集上,表2列出了近年来一些代表性的同类工作。

表2 与现有同类工作对比
4 结语
文中提出了一种基于问题类别线索词的特征提取方法。该方法通过LTP平台对问题进行分析得到基本的词法、句法信息,然后在此基础上提出问题类别线索词集提取算法来提取问题深层语义信息。利用特征组合绑定方式进而生成一组组合绑定特征来提高分类的精度。通过实验对比,该方法比单纯使用基本组合特征在小类上分类精度提高2.23%(大类上提高1.92%)。因此,可以得出基于问题类别线索词集的特征更适用于分类体系较为复杂的小类分类。另外,文中也通过在不同规模的数据集上进行验证,可以发现在不同规模的数据集上,文中所提出的问题类别线索词集特征的组合绑定特征均可以不同程度提高分类的有效性。因此,也可以说明该特征对于小规模语料数据集上有着同样的效果。并且当调整语料数据的各类问题的分布使之均匀分布,在相同条件下分类器的精度并没有显著的提高。因此,在数据集分布不平衡的语料上,该特征提取方法仍可以有效的进行分类。 另外,通过文中所提出的方法,后续还有两点工作可以进一步深入展开研究:(1)考虑如何去使用规模更大的未标记数据来提高分类精度;(2)考虑使用更多的先验知识来进行深度学习,从而提高问题分类的精度。
[1]张志昌,张宇,刘挺,等.开放域问答技术研究进展[J].电子学报,2009,37(5):1058-1069.
[2]何靖,陈翀,闫宏飞.开放域问答系统研究综述[C]//第六届全国信息检索学术会议.北京:中国中文信息学会,2010:114-121.
[3]MUDGAL R,MADAAN R,SHARMA A K,et al.A novel architecture for question classification based indexing scheme for efficient question answering[J].International Journal of Computer Engineering,2013,2(2):27-43.
[4]MISHRA M,MISHRA V K,SHARMA H R.Question classification using semantic,syntactic and lexical features[J].International Journal of Web&Semantic Technology,2013,4(3):39.
[5]HUANG Z,THINT M,CELIKYILMAZ A.Investigation of question classifier in question answering[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing:Volume 2-Volume 2.Association for Computational Linguistics,2009:543-550.
[6]LONI B,VAN TULDER G,WIGGERS P,et al.Question classification by weighted combination of lexical,syntactic and semantic features[C]//Text,Speech and Dialogue.Springer Berlin/Heidelberg,2011:243-250.
[7]YU Z,SU L,LI L,et al.Question classification based on co-training style semi-supervised learning[J].Pattern Recognition Letters,2010,31(13):1975-1980.
[8]LIU L,YU Z,GUO J,et al.Chinese question classification based on question property kernel[J].International Journal of Machine Learning and Cybernetics,2014,5(5):713-720.
[9]DONG L,WEI F,ZHOU M,et al.Question answering over freebase with multi-column convolutional neural networks[C]//Meeting of the Association for Computational Linguistics,International Joint Conference on Natural Language Processing,2015:260-269.
[10]ZHANG D,WANG D.Relation classification via recurrent neural network[J].arXiv:1508.01006,2015.
[11]SHI Y,YAO K,TIAN L,et al.Deep LSTM based feature mapping for query classification[C]//Proceedings of the 2016 Conference of the Nort American Chapter of the Association for Computational Linguistics:Human Language Technologies,2016:1501-1511.
[12]HAIHONG E,HU Y,SONG M,et al.Research and implementation of question classification model in Q&A system[C]//International Conference on Algorithms and Architectures for Parallel Processing.Springer,Cham,2017:372-384.
[13]李超,柴玉梅,南晓斐,等.基于深度学习的问题分类方法研究[J].计算机科学,2016,43(12):115-119.
[14]HE H,GARCIA E A.Learning from imbalanced data[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(9):1263-1284.
[15]杨思春,高超,秦锋,等.融合基本特征和词袋绑定特征的问句特征模型[J].中文信息学报,2012,26(5):46-52.
[16]文勖,张宇,刘挺,等.基于句法结构分析的中文问题分类[J].中文信息学报,2006,20(2):33-39.
猜你喜欢
一重技术(2021年5期)2022-01-18
数学小灵通(1-2年级)(2021年4期)2021-06-09
少儿画王(3-6岁)(2020年4期)2020-09-13
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年11期)2018-08-04
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
浙江大学学报(工学版)(2015年1期)2015-03-01
