
满族典籍平行语料库对齐方法与评价
——以《尼山萨满》为例
2018-06-07 02:26田春燕郭淑云大连民族大学外国语学院理学院东北少数民族研究院辽宁大连116605
大连民族大学学报 2018年3期
田春燕,徐 毅,解 威,郭淑云(大连民族大学 .外国语学院; .理学院;.东北少数民族研究院,辽宁 大连 116605)
在现代文化及外来文化的强势冲击下,少数民族的典籍文化流失严重,缺乏人员保护、处于十分濒危的状态[1]。萨满文化是中国东北地区少数民族,尤其是满族的一种重要民间文化,对其所遗留下来的文化典籍保护和推广也成了民族文化传承的重要课题[2]。近年来,一些地方仍然健在的萨满典籍让许多国外学者惊羡,然而这些萨满文化大多是以纸质媒介传播,因而如何运用现代技术手段传承与保护萨满典籍成为当务之急[3-4]。
平行语料库是原文文本及其平行对应的译文文本构成的双语/多语语料库,它对于众多跨语言的自然语言处理研究和应用都具有相当高的研究和实用价值。
1 满族典籍的平行语料库存在的问题
现在比较流行的少数民族平行语料库大多是特定语言环境、特定词汇间的翻译语料库,针对少数民族与汉语之间的平行语料库大多集中在维语、蒙古语、藏族语言与汉语之间的翻译,这些平行语料库大多取材于日常用语及某些杂志期刊,很少涉及到民族典籍的翻译。满族典籍具有其特有的文化特征,翻译的效果受文化传统、风俗习惯等方面影响。大量专业性的双语语料需要段落对齐、句对齐。满族典籍由于其语言文字的局限性,很难像英语、汉语按段落、句子做对应的切分。某些对齐的满族典籍语料,对齐效果也并不理想,这在很大程度上阻碍了满族典籍翻译语料库的研究。
鉴于上述理由,考虑到大连民族大学目前已有多位专家从事东北民族典籍方面的研究,特别是对于《尼山萨满》的翻译和研究都已经非常成熟[5-6]。因此在他们的工作基础之上,笔者及其团队构建了《尼山萨满》的多语平行语料库,本文重点讨论该平行语料库的对齐技术问题。
2 《尼山萨满》典籍平行语料库段落对齐方法研究
语料对齐是指将双语语料中两个互译的语料片段建立对应关系,对齐的语料片段可以分为篇章、段落、句子三个级别,研究最多的是段落对齐和句子对齐。
2.1 基于回车换行的段落对齐方法
在《尼山萨满》典籍中,其原文及其汉语译文的段落基本上遵循一一对应的关系[2]。回车换行符基本都是用作段落分割的标志,通过这种分割可得到基本的段落单体。这种方法实现比较简单,运行效率比较高,当原文与译文文本格式比较规范,可以达到预期的对齐效果。但作者在研究过程中发现某些《尼山萨满》译本附录中有些歌谣或者颂词部分会出现段落不规范的情况;一旦某个段落出现错误,后面的段落或句子对齐的正确率会急剧下降。
2.2 基于人名关键字的段落对齐方法
考虑到本文所选典籍语料《尼山萨满》是一个关于满族文化的神话故事,人名贯穿故事始末,同一人名出现的频率也非常高,《尼山萨满》中部分人名关键字在满汉典籍中出现的次数统计见表1。因此本文给出了一种基于人名关键字的段落对齐方法。首先应用回车符进行自然段的切分,然后利用满汉双语文本中人名关键字信息进行进一步的分段对齐。

表1 《尼山萨满》典籍人名关键字统计表
具体实现步骤可描述如下,算法的流程图如图1。
(1) 首先使用回车符对满汉互译语料进行自然分段;
(2) 将步骤1中对齐的自然段落按顺序对应起来,根据句子特征确定段落对齐;
(3) 以已对齐的满汉互译语料中的段落为单位,按照标点符号为基准划分为若干个句子,得到汉文段落Ci的一个有序句列{Ci0,Ci1,Ci2,…,Ciu}和满文段落Mj的一个有序句子序{Mj0,Mj1,Mj2,…,Mjv};
(4) 从汉语段落Ci的句子序列中依次取出每个包含人名关键字信息的句子 ,将该句子中的所有人名关键字按顺序提取,得到人名关键字序列{N1,N2,N3,…,Ns}(s≥1);
(5)从人名关键字序列中取出一个人名关键字Ns,翻译成满语,然后在满语有序段落Mj的有序句列中进行匹配,若找到匹配项则计数后跳到下一个人名关键字Ns+1继续进行匹配。若没有找到匹配项,则进入下一个满文段落Mj+1进行匹配,一直到找到包含对应人名关键字的满文句子。若一直未找到则进入到本汉语段落中下一个包含人名关键字信息的句子中;
(6) 若根据人名关键字找到匹配的满汉语料句对,则对这个句子进行标记,并将此句作为本段的分割标准,划分为两个分段,然后以下一个分段为基础继续上述过程。若所有分段处理完毕,则算法结束。
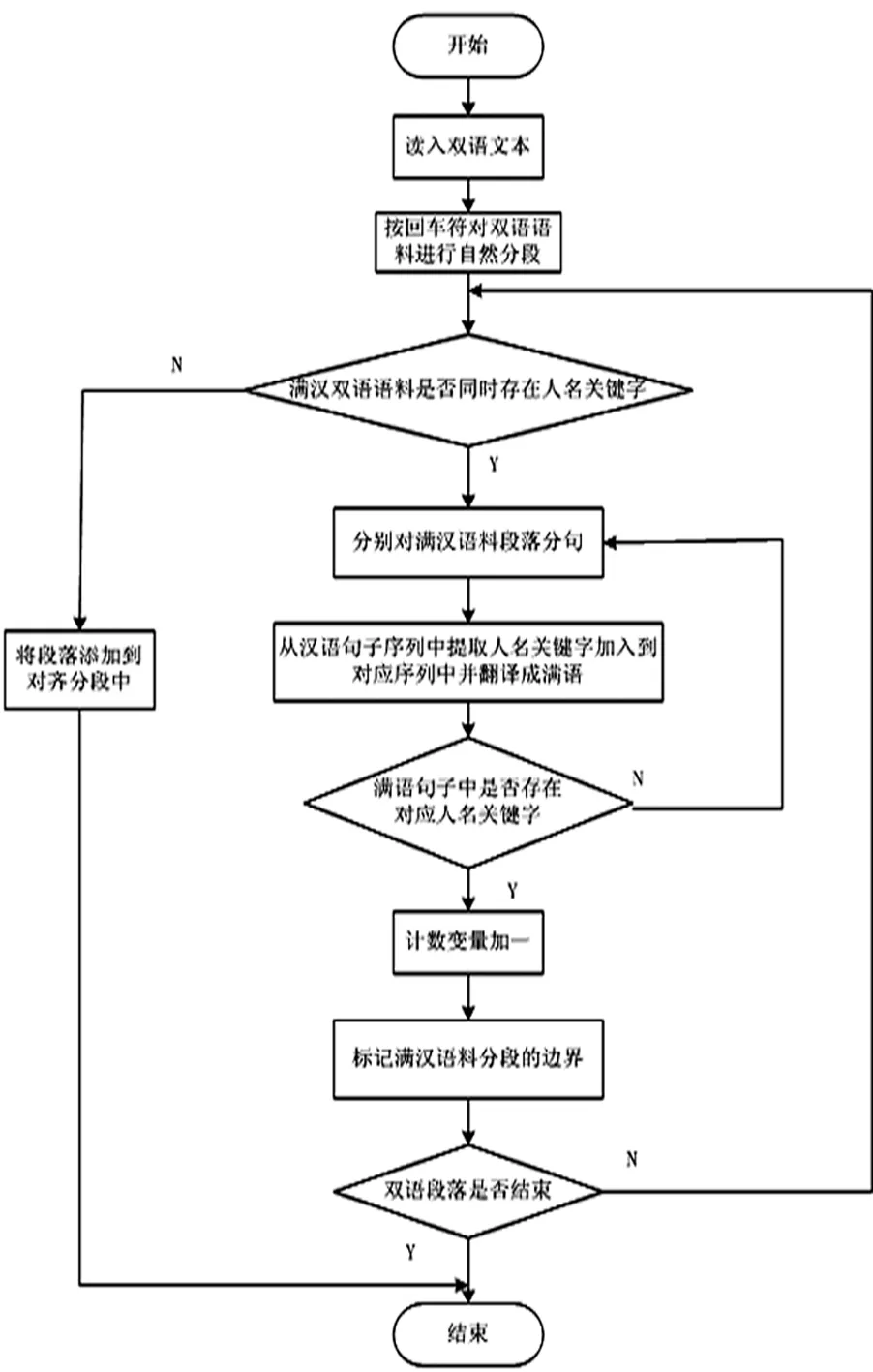
图1 基于人名关键字的段落对齐流程图
3 《尼山萨满》典籍平行语料库句子对齐方法
在实际的典籍平行语料库应用中,段落层次的对齐显然不能够满足典籍语料库的需求,需要做更小的语料颗粒划分句子对齐。句子对齐是语料库对齐中研究最多的一个课题,目前出现了众多句子对齐方法。总体上看,这些方法可以分为如下几种[7]:
(1) 基于长度统计的对齐方法。这种对齐方法是根据互译的两种语言之间长度关系的不同进行对齐,实现这种对齐方法需要统计两种语言语料中对应句子的长度信息,并分析出其统计规律。
(2) 基于典型词汇的句子对齐方法。这种对齐方法根据两种互译语料中特殊词汇信息的比对而实现的对齐方法,实现这种对齐方法需要查询词典并对句子进行必要的处理。
(3) 基于句子长度和词汇信息相结合的对齐方法。这种对齐方法是上面两种对齐方法的结合,取二者的优点,既提高了句子的对齐性能又降低了对齐算法的复杂度。
在对满族典籍平行语料库句子对齐研究过程中,考虑到满语与汉语属于不同语系,满语中单个词汇识别度较差这些情况,决定采用句子长度的对齐方法。
3.1 满汉典籍中句子长度的分析
在进行句子长度分析时,通常会以单词或字符作为最小研究单位。在满汉典籍语料研究中,若以单词作为统计句子长度的最小单位会出现较多问题,主要原因在于汉语与满语并非同一语系,汉语在分词方面有一定的复杂性,这就会导致在统计满文和对应汉语译文句子长度时会出现一定的误差,因此我们以字符数为最小单位对满汉典籍语料句子长度的分析。对《尼山萨满》原文及其海参崴版本译文进行统计后发现,原文典籍共包含654个句子,而对应汉语译文中有663个。在进行分段对齐及手工处理后共得到661个互译句对,以字符数为最小研究单位得到的满汉互译句子长度关系统计如图2。
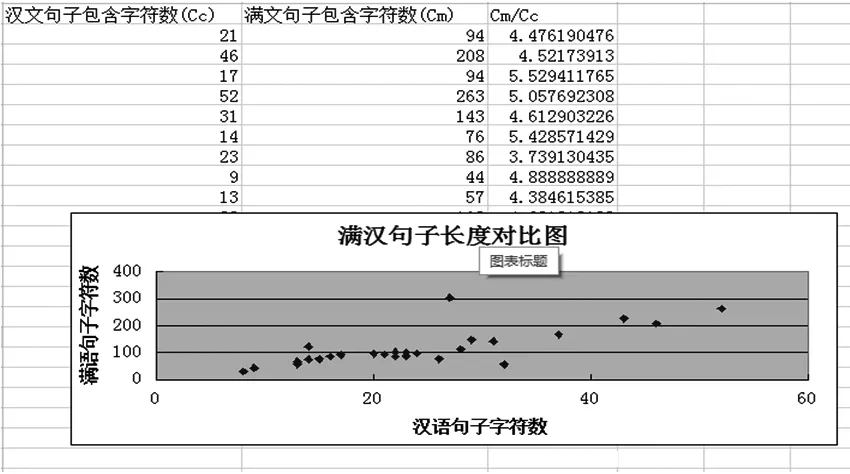
图2 满汉互译句子长度关系统计
分析可知,以字符数为标准的句子长度统计中,满语句子字符数与对应的汉语句子字符数有一定的相互制约关系。一般情况下,汉语句子中的字符数与其对应的满语句子中的字符数的比值是相互独立的,具有一定的随机性,将这个比值记做随机变量X,X的分布具有正态分布的特点,将X的均值记做μ,方差记做σ2,得到相关统计结果见表2。μ≈满语句子字符数/汉语句子字符数,σ2=(Lm-Lc·μ)2/Lc,其中Lm表示满语句子中字符数,Lc表示汉语句子中的字符数。

表2 满汉句子字符比值统计表
由于满语和汉语不属于同一语系,与同一语系的语言相比较,其句子长度之间差别比较大,我们把不满足上述统计参数的句子所出现的范围称为拒绝域。从对统计表的分析可知,满汉典籍语料句子长度比值均值的拒绝域是{Y=Lm/Lc|Y<2或Y>6},拒绝域中的句子格式如下:
从此之后,巴彦夫妇经常求神拜佛、烧香祈祷神灵保佑。作为回报,到了五十岁那年,又生了一共儿子,起名叫色尔古代费扬古。
Tereci bihei eigen gargam suisai se isifi endure fucihi de baime jalbirafi (jalbarifi) geli emu jui ujifi sergudia fiyanggu seme gebulefi。
Y=8.426
3.2 满汉典籍语料基于长度的句子对齐方法
基于长度的句子对齐方法基本思想是按照互译的两种语言句子长度的相关关系研究句子的对齐,而不考虑其句子意思及所包含的词汇信息。根据上述对满汉语料句子长度的统计结果可以求取对应句子的互译概率,于是得到基于句子长度的双语句子对齐模型[8]
(1)
由贝叶斯定理可知:
(2)
式中,p(δ)是一个常数,不会影响句子的互译概率,所以可以得到对应句子的互译概率为
(3)
式(2)-(3)中,P(M(Lm,Lc))表示在不考虑句子长度的情况下得到的(Lm,Lc)句对类型出现的概率。式(2)中δ表示满足标准正态分布类型的双语句子长度关系评价函数,在这个关系函数中,p(δ|M(Lm,Lc))表示按正态分布密度函数[9],它的计算公式为
(4)
式中,μ和σ2分别表示满汉典籍互译句子字符数比值均值与比值方差,可以根据对满汉典籍互译句子字符数比值的统计得到。
(5)
通过动态规划的思想,使用公式(5)找到满足公式(4)的对齐句对。具体操作过程如下:
(1)对于公式(5)做初始化操作;
(2)根据我们已经总结的满汉典籍语料句子匹配类型及其统计概率计算公式(5)的几种可能情况,例如g(i-1,j-1),g(i-1,j-2),g(i-2,j-1),g(i-2,j-2);
(3)设置偏移量,当程序进行到分段段落的结尾时表示查找过程完成,基于长度的句子对齐算法结束;
(4)在查找过程中,如果出现有多个情况满足式(5)的情况,取最小的计算值寻找满足公式(4)的对齐句对;
(5)若一次查找完成后,将控制循环次数的参数进行加一操作后继续执行。
4 对齐方法性能的评价
本文对齐性能的评价方法主要通过计算对齐的召回率和准确率。
(1)假设有组对齐后的语料组{S,T},S表示按照执行对齐算法后得到的对齐句对,T表示人工处理后的需要达到理想状况的对齐句对。把S中对齐正确的双语片段数与T中正确的双语片段数的比值称为S对T的召回率,召回率Recall[10]计算公式为
(6)
分析可知,Recall的范围在0与1之间,当Recall=0时表示S中正确片段数为0,这是句子对齐算法执行时最坏的情况;当Recall=1时表示S中对齐片段全部正确,这是最好的情况。
(2)在同样一组语料组中,把S中对齐正确的片段数与S语段中所有对齐语料片段数的比值称为准确率,S相对于T准确率Precission表示公式为:
(7)
Precission的范围也在0与1之间,当Precission越大表示在对齐算法的准确度越高,当Precission=0时表示没有正确的片段,当Precission=1时表示S中对齐片段全部正确。
4.1 分段对齐结果分析
本文的满汉双语语料分段方法的对齐结果分析见表3。由于《尼山萨满》正文部分比较规范,回车符均是分段换行符,因此基于回车符分段的准确率和召回率均为百分之百,对于《尼山萨满》附录部分,由于很多回车符不是分段换行符,因而对齐的准确率和召回率会显著下降。使用基于人名关键字的方法,虽然准确率和召回率相比基于回车符分段略有下降,但其准确率和召回率均在可接受范围之内,而且其优点是会使句子对齐的准确率和召回率有很大提高;对于《尼山萨满》附录部分,很多回车符不是分段换行符,基于回车符的分段技术准确率和和召回率均有所下降,而基于人名关键字的对齐方法则不受影响。

表3 分段结果分析表 %
4.2 分句对齐结果分析
基于长度的句子对齐方法应用于满汉典籍语料对齐中的对齐结果见表4。由分析结果可知,句子对齐与段落对齐相比略有下降,这主要是因为句子级别的对齐属于更小颗粒的对齐,对齐范围更精确,相比较而言也更容易出错。由于是民族典籍翻译,不要求句对的精确翻译,而是要求句意忠于原文,因此这个统计数据也是在可以接受的范围之内。

表4 基于长度的句子对齐结果分析 %
5 结 语
针对中国少数民族的文化典籍面临的问题,本文以《尼山萨满》为例,研究了满族典籍平行语料库的分段对齐和分句对齐方法。研究结果显示:像《尼山萨满》这样的口传民族文学经典,大多包涵大段的歌谣或颂词,故在建立满族典籍平行语料库时,基于人名关键字的段落对齐方法更加有效;同时,实验结果表明,在句子对齐方面,基于长度的句子对齐方法是切实有效的,可以满足建立满族经典平行语料库的要求。
参考文献:
[1] 张媛,王宏印. 民族典籍翻译的现状、问题与对策——人类学学者访谈录之七十一[J]. 广西民族大学学报(哲学社会科学版),2014(04): 23-26.
[2] 宋和平. 《尼山萨满》研究[M]. 北京: 社会科学文献出版社, 1998: 34-68.
[3] 崔颖. 东北少数民族典籍翻译现状与发展策略探究
[J]. 贵州民族研究, 2016(01): 117-119.
[4] 张玉. 东北地区少数民族典籍翻译研究[J]. 校园英语, 2014(34): 229-230.
[5] 郭淑云. 中国萨满教研究特点与展望[J]. 西域研究,2012(02): 96-103.
[6] 郭淑云. 中国萨满教若干问题研究述评[J]. 民族研究,2011(03): 83-94.
[7] 惠聪. 机器翻译中的高级对齐技术和开发集选择策略研究[D]. 上海: 上海交通大学, 2012.
[8] 王克非. 双语平行语料库在翻译教学上的用途[J]. 外语电化教学, 2004(06): 27-32.
[9] 魏宗舒. 概率论与数理统计教程[M]. 北京: 高等教育出版社, 1996.
[10] 刘昕,周明,朱胜火,等. 基于自动抽取词汇信息的双语句子对齐[J]. 计算机学报, 1998(S1): 151-158.
[11] RENNER. XML data and object databases: The perfect couple[C]. Washington: International Conference on data engineering, 2001.
猜你喜欢
满族文学(2022年1期)2022-01-21
满族文学(2021年1期)2021-11-08
今古文创(2021年30期)2021-08-28
满族文学(2020年6期)2020-11-09
设计(2019年19期)2019-12-23
读书(2019年8期)2019-08-12
金桥(2018年11期)2019-01-21
文化创新比较研究(2017年17期)2017-03-11
文学教育(2016年33期)2016-08-22
中国钱币(2015年6期)2015-11-18
