
基于大数据的大气监测研究
2018-06-06 10:14曾羽琚
电脑知识与技术 2018年7期
曾羽琚
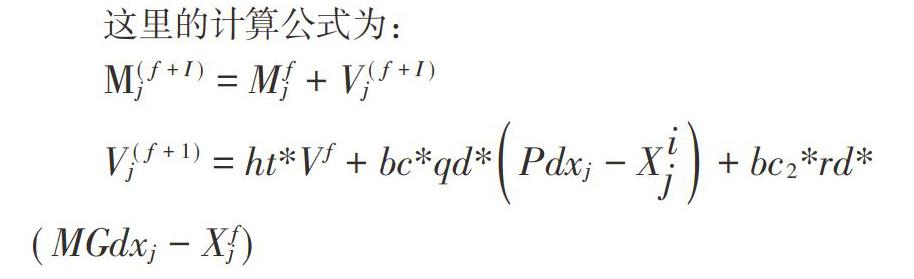
摘要:该文针对在大气环境监测中大数据应用情况和存在的问题,分析了大数据应用的基本原理和当前现状,同时提出了优化控制的方法策略,为后续大数据应用于大气监测深化研究提供依据。
关键词:大气环境监测;大数据;PM2.5
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)07-0015-02
当前我国已经进入物联网新时代,每时每刻每行每业都会不断产生着海量的各类数据。无法在一定时间范围内用常规软件工具进行捕捉、管理和处理这些数据集合。因此,通过新处理模式研发各种大量基础和应用软件的,使得数据计算与数据处理更加完善和丰富,同时在数据信息的储存、运算等功能得到加强。为了具有更强的决策力、洞察发现力和流程优化能力来处理这些海量、高增长率和多样化的信息资源。大数据解析技术在实践生活中的使用,能够充分提高信息采集、数据计算、实际模拟以及各类数据识别等数据操作性工作的效率,能够极大提高环境保护工作的质量和效率。那么根据实际工作环境监测中应用大数据解析技术为例,来分析大数据应用的得与失[1]。
1 大数据技术在PM2.5大气监测中原理及现实情况
当前,全国性大范围长时间的大气PM2.5污染问题,给大众的生活和健康带来重大威胁。空气监测网不健全,覆盖范围不全面,密度低,追踪预警能力低。从全国范围来看,平时常规使用连续自动监测法下的β射线法和震荡天平法对PM2.5进行测量。但是,每个城市无法在多个区域建设大气自动监测站,以便连续稳定获取数据。所以在时间点上的获取的数据就缺乏完整性和代表性。那么解决这个困境的最佳方法就是,加大对大数据解析能力的研究,找出优化控制的方法策略[3]。常见的方法策略主要是:数据采集功能、统计计算、随机过程分析、系统模拟与参数识别等功能。也就是通过解析多元和非线性数据类之间的关系,掌握目标函数的变化规律[4],为控制PM2.5污染提供数据参考。
具体来说,大数据分析技术应用于PM2.5的难点主要是需要处理复杂数据类的关联关系。同时还需要在数据分析过程中对问题进行条理化和简化处理。因此根据以上原则,我们主要做了如下工作:
1)在应用大数据解析技术时,需要有明确科研对象与科研内容。本次研究确定研究对象为湖南省长沙市雨花区,以城市局部地区分布的PM2.5平均浓度作为研究内容。
2)将目标区域按照一定的标准进行网格划分,本次研究划分为500m×500m。因此雨花区这个研究对象可以表达为M=(m1,m2,…,mi,…,mn),其中每个mi均代表一个范围0.25km2 的地点; 而研究内容表達为D=(Dm1,Dm2,…,Dmi,…,Dmn),其中,Dmi表示为mi网格的PM2.5浓度。最终研究内容,通过大数据解析技术应用控制的目标函数,即可表示为:D(Mi)。
3)可将目标函数按照PM2.5监测的实际情况分化:一种是PM2.5自动监测站网格和另外一种是非PM2.5自动监测站网格,非PM2.5自动监测站网格数据是大数据解析技术需要解决的目标数据[5]。大气环境监测中应用的大数据解析技术,能够将各种数据充分融合,能够提高数据处理效率。
2 大数据技术在PM2.5大气监测中主要关键点
湖南省长沙市雨花区每日进行的大气PM2.5监测,首先要解决和完善的问题就是:获取正确的数据类及选择适应特征量。对于数据类的要求是需要获得与目标函数一定相关性的数据类,以便更加精确掌握未设置PM2.5自动监测站网络的环境现状。该数据类与目标函数的关联性不定可以简洁也可以复杂,同时数据类的内部的相关性即各个不同数据类之间可强也可弱。与大气PM2.5监测相关的数据类主要包括:历史PM2.5浓度数据;历史的气压数据;网格内部道路现状数据;网格内与空气污染有关的数据,工厂排放数据、加油站挥发数据、餐饮业排放数据、公园树木净化能力等数据[5]。
目标函数主要是受到数据类的影响,特征量与目标函数呈现正相关。这就需要从复杂数据类中提取有益特征量,以方便更加快速获取数据类。例如,当需要获取清晨5时,目标内网格PM2.5小时平均浓度。当前已知数据是监测点内每两小时的网格PM2.5浓度数据,所以我们需要将之前监测点内PM2.5每两小时平均浓度作为特征量;在明确了所需要的特征量后,通过公式结合已知数据类可以获取目标函数的值,即目标数据类。
这里的计算公式为:
[M(f+I)j=Mfj+V(f+I)j]
[V(f+1)j=ht*Vf+bc*qd*Pdxj-Xij+bc2*rd*(MGdxj-Xfj)]
其中,j=1,2,……d;bc和bc2为加速参数,都是非负常数,本文选定为3;qd为介于[0,1]之间的随机数;ht为惯性权重。
在公式的运用过程中有三个关联因子,分别是:权重ht、加速参数bc、加速参数bc2。权重ht在公式中有特殊重要的作用,主要是维护微数据类本身的特性并且使其能够趋于当前优先位置。而加速参数bc和bc2,他们分别是在特征向量中能够保障单个数据类向最优和族群最优靠近。bc保证数据类不断地向最优位置靠近,bc2保证微数据类粒子不断向最优位置靠近。
在常规情况下,所包含的特征量不会随时间的变化而发生正相关变化,这是一个非动态的反应变化过程。特征量对目标函数的影响是主要是多节点多层次线性化传递路线。数据类在输出时有时是离散状态有时是线性状态,但是都具备静态神经网络的基本特征。神经网络的结构由一个输入层、若干个中间隐含层和一个输出层组成。神经网络分析法通过不断学习,能够从未知模式的大量的复杂数据中发现其规律。神经网络方法克服了传统分析过程的复杂性及选择适当模型函数形式的困难,它是一种自然的非线性建模过程,无需分清存在何种非线性关系,给建模与分析带来极大的方便。用来模拟预测局地网络,进而为大数据解析技术应用提供重要数据支撑[6]。
通过上述公式的分析过程,发现在以下方面存在弱项需要解决,包括:需要解决收集、清洗和分析数据;要解决当前数据存在有不准确、片面性、间接获取等问题;需要解决特征量的获取,已经相对应的各种统计分析方法。数据类和数据类中特征量的选取,是关键所在:如何选择所需要的特征量的,对于获得最终准确结果确是有效果[7]。
3 总结
总体而言,大数据解析技术在PM2.5大气监测中的应用,需要从实际出发,在针对有明确的研究对象和研究内容,可以确定数据类的特征量,从而提高数据质量,获取完整有效的信息。今后对于PM2.5开展基于云计算的数据管理、在线分析,基于智能手机的数据采集,基于大数据的PM2.5空气质量演化及预测模型,基于大数据的预警模型研究加强。能够使大气环境监测工作的开展具有可靠性,并采取行之有效的各种控制措施,进行相关污染问题治理。
参考文献:
[1]包权.上海市环境空气质量自动监测数据审核体系的构建及其应用[J].环境科学与管理,2010(12).
[2] 宁亚东,李宏亮. 我国移动源主要大气污染物排放量的估算[J].环境工程学报,2016(8):4435-4444.
[3] 潘月云,李楠,郑君瑜,等.广东省人为源大气污染物排放清单及特征研究[J].环境科学学报. 2015(09): 2655-2669.
[4] 杨斌.大气监测布点的优化策略[J].化工设计通讯,2017(2).
[5] 徐杰.试论我国大气环境监测布点原则及方法[J].山东工业技术,2015(19).
[6] 刘随军,李峰,张洪凯.星座图法在大气质量评价中的应用[J].中国环境管理干部学院学报, 2002(4).
[7] 刘毓,胡文海,史忠科.一种大气质量评价方法的改进及应用[J].环境保护科学,2001(1).
猜你喜欢
军事文摘(2023年10期)2023-06-09
电子制作(2019年19期)2019-11-23
中国资源综合利用(2017年4期)2018-01-22
河北书画研究(2016年2期)2016-08-24
摄影之友(影像视觉)(2016年2期)2016-08-16
公民与法治(2016年4期)2016-05-17
中国资源综合利用(2016年12期)2016-01-22
