
基于声纹识别技术的Android设备声音功能自动化测试系统*
2018-06-05 11:46李嘉伟胡海龙林志贤
网络安全与数据管理 2018年5期
李嘉伟,胡海龙,林志贤
(福州大学 物理与信息工程学院,福建 福州350116)
0 引言
目前市面上的彩电等显示器设备大部分已配备Android系统,显示器生产测试过程中需要对设备扬声器与麦克风等声音功能进行测试。声音功能测试包括扬声器(喇叭)、麦克风(耳机孔)等硬件功能的测试,目的是检验声音功能是否存在无声、杂声、失真等不良情况。当前国内外声音功能自动化测试程度尚处于较低水平。文献[1]提出了一种基于小波变换交叉运算的产线噪声故障检测和来源定位系统。文献[2]提出基于高精度音频信号分析技术与灵敏信号辨识技术,可检测发现20 dB以上杂音信号的次品手机。文献[3]通过研究响度测试算法对电视机喇叭响度进行测试。文献[4]过语音识别技术构建了工厂噪声环境下玩具字母发音正确性的自动化检测系统。上述方案仅能对扬声器功能中的杂声或响度等某一种特定不良进行检测,无法对麦克风质量以及语音失真、杂声、无声等多种不良同时做出全面的诊断。目前工厂产线中的声音功能测试大部分依旧采用人耳聆听测试,该方式全靠工人主观判断,所以成本高、效率低、错判率高。
声纹识别,又称为说话人识别(Speaker Recognition,SR)。声纹是携带归属者语音特征的声波频谱,声纹识别就是通过计算机对数字语音信号提取、计算、比对信号的频谱特征,从而辨别该语音信号的归属者[5]。鉴于Android设备智能化的特点以及声纹识别技术对语音特征优质的辨识性能,本文提出一种基于声纹识别技术(Voiceprint Recognition, VPR)的Android设备声音功能自动化测试系统。采用梅尔倒谱系数(Mel Frequency Cepstrum Coefficients,MFCC)结合梅尔倒谱差分系数(MFCC Difference,ΔMFCC)算法提取语音信号特征,通过动态时间规整(Dynamic Time Warping,DTW)算法对麦克风录制语音和扬声器播放语音的模型特征进行比对,实现扬声器与麦克风同步对失真、无声、杂声等多种不良的有效检测。本系统成本低、容易实现,有助于提升企业生产效率。
1 特征提取与模式匹配算法
声纹识别系统一般包含特征提取和模式匹配两个关键的步骤。特征提取应尽可能保留反映个性差异的特征信息,尽可能去掉与语音特征无关的信息,从而提取到声纹特征。模式匹配则是对提取的多个特征信息进行模式匹配,从而判别不同特征的差异[6]。
1.1 基于MFCC的特征提取算法
目前比较普及的特征提取方法有线性预测倒谱系数(Linear Predictive Cepstrum Coefficients,LPCC)和梅尔频率倒谱系数。MFCC 特征系数是一种基于听觉感知频域倒谱系数,本文选择识别性能和鲁棒性更好的MFCC算法作为提取特征参数的算法[7]。由式(1)求得MFCC序列参数c(n):
(1)
其中M为滤波器的阶数,本文中M为26,s(m)为同态处理后信号[8]。
梅尔倒谱差分特征参数ΔMFCC即在静态MFCC特征的基础上提取动态特征。为提高系统识别率,本系统在MFCC 特征中加入MFCC差分系数作为声纹识别系统的特征参数。梅尔倒谱差分特征参数△MFCC的提取公式如式(2)所示,其中k为差分时间差,本文取值为2,d(n)即为所求差分系数。
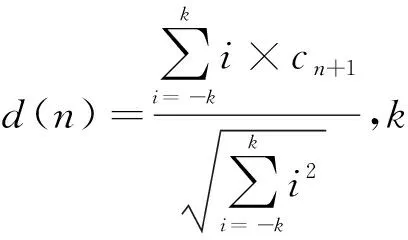
(2)
1.2 基于DTW的模式匹配算法
由于故障设备可能存在某单一声道无声的不良,本系统采用基于解决长短不一语音模式匹配问题的动态时间规整算法作为模式匹配的方法,其核心思想是将时间规整和欧氏距离相结合,对时间序列进行延伸和缩短,按照时间先后顺序和当前帧相邻的帧进行匹配,得到两个时间序列距离最短最相似的映射路径,这个最短的距离也就是这两个时间序列的最后的距离度量[9]。
运用 DTW 算法计算出一个函数j=w(i),将测试模型的i轴非线性地映射到参考模型的j轴上, MFCC参数之间的DTW距离由式(3)计算获得[10]:
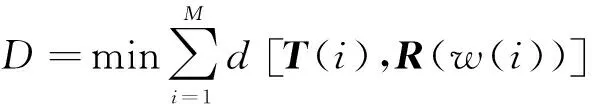
(3)
式(3)中d[T(i),R(w(i))]表示第i帧测试矢量T(i)与第j帧参考矢量R(j)间的欧氏距离。 由式(4)计算获得[10]:
(4)
式(4)中tk为测试矢量T第i帧的第k个数据,rk为参考矢量R第j帧的第k个数据,l为矢量参数各帧的数据个数,本文取值24。
2 系统设计
本系统采用Java语言,基于Android 5.0.1 SDK开发,开发工具为Android Studio,产品形式为apk格式可移植程序安装包,具有可视化操作界面,通过Android系统调用设备底层扬声器和麦克风等硬件实现自动播放和录制音频,再通过Java语言实现数学计算进行语音信号处理。通过界面文字与图像反馈测试结果。
声纹识别系统一般分为“训练”和“识别”两个过程。“训练”阶段对语音信号提取出特征参数,作为参考模型存储起来;“识别”阶段利用模式匹配算法将待测特征模型与模型库中的参考模型进行比对,如找到符合阈值要求的匹配模型,则提示验证通过,否则提示验证失败。由于本系统应用领域的特殊性,“训练”阶段在系统设计前期完成,在已确认声音功能完好的设备中进行“训练”得到阈值和参考模型库,再将该模型库存入系统,供其他待测设备进行“识别”测试。本文设计的系统框架如图1所示。
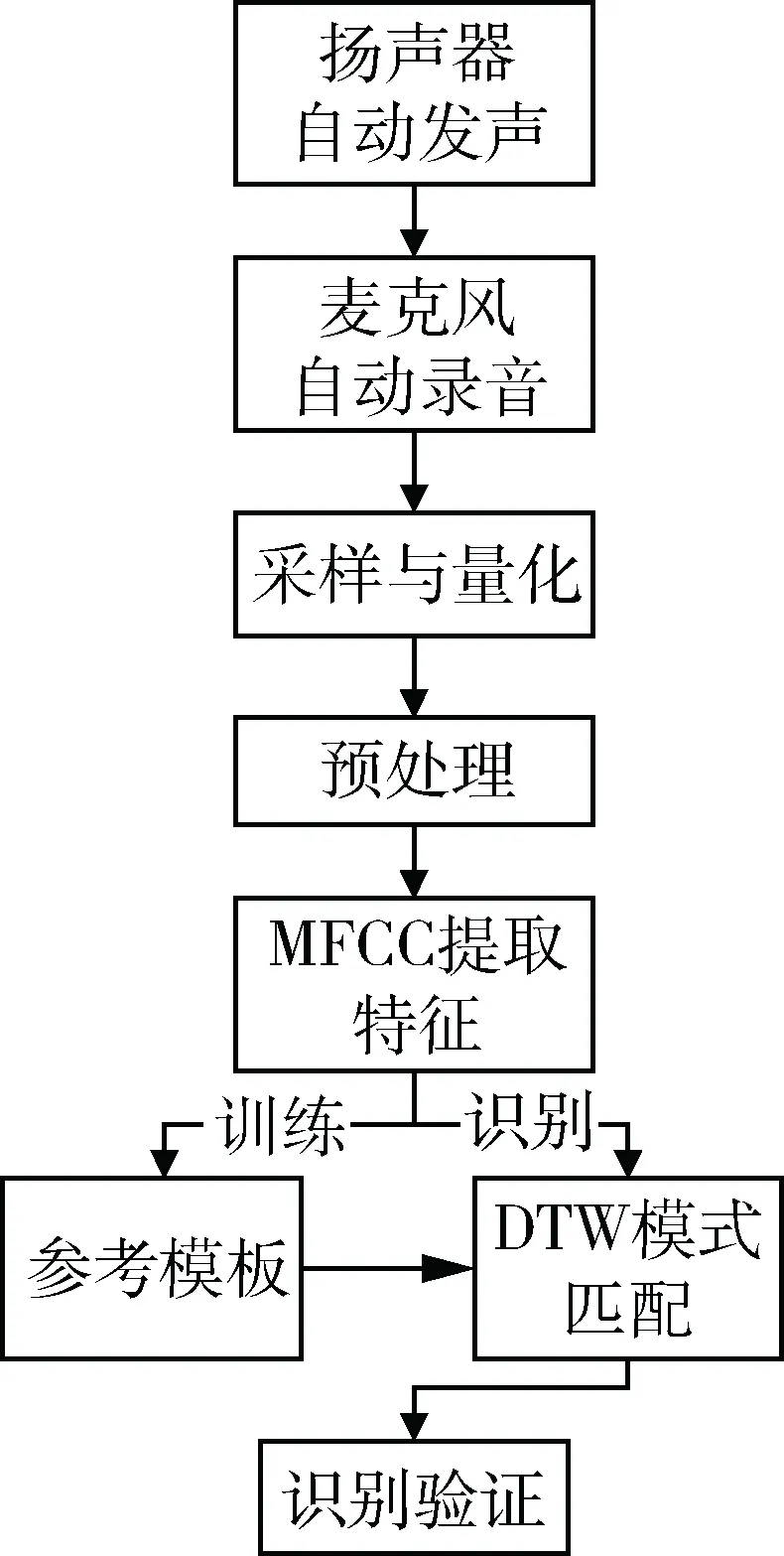
图1 系统架构图
首先扬声器播放左右声道专用人声测试音频8 s。麦克风录制当前扬声器播放的语音。然后对信号进行归一化、预加重、端点检测、加窗分帧等预处理。本系统采用短时能量和短时过零率双重门限的方法进行端点检测,设备“无声”故障主要通过端点检测实现,若有效语音段过短,即可提前判定设备“无声不良”。最后利用MFCC算法提取特征模型。“训练”阶段,在相同环境与条件下先后录制并提取两份语音特征模型,若二者特征误差小于阈值,则作为模型库保存。“识别”阶段利用DTW算法将预设的两个参考模型先后与待测语音信息进行特征模式的相似性匹配,若两次的平均误差小于阈值则验证通过,表明扬声器与麦克风在整个连贯工作过程中没有失真、杂音过大等不良情况,保持了语音原有的声纹特征,即设备声音功能完整,品质达标。反之则说明存在质量问题,系统给出提示,操作员可进一步验证。如图2所示,(a)为系统测试通过界面,并展示了某次测试中DTW距离、帧数、平均误差等信息,(b)为测试不通过界面。其中平均误差为前后两次模式匹配的DTW距离之和除以帧数之和。
3 实验与结果分析
3.1 阈值选定
特征参数是否满足标准,需要有一个阈值作为判定依据,选定的阈值直接决定了产品是否合格。当测试结果超出了阈值时即为不合格,在阈值范围内即为合格。阈值的选定需要针对目标环境及需求进行试验确定。本文中“训练”获得的两模型DTW距离为11 265.429,平均误差为17.030。在5种不同环境下对样本良品设备进行6次常规测试,再通过计算机模拟5种不同程度的失真、5种不同分贝杂音的语音分别对样本设备进行6次测试,部分测试数据如表1所示。由数据分析可知,良品测试语音与模型库的平均误差维持在17左右,与模型库平均误差持平,失真情形的平均误差均在40以上,杂音情形的平均误差均在22以上,稳定在30左右,可见阈值可选区间在18~21之间,由此本文选取阈值为20。

图2 系统检测结果
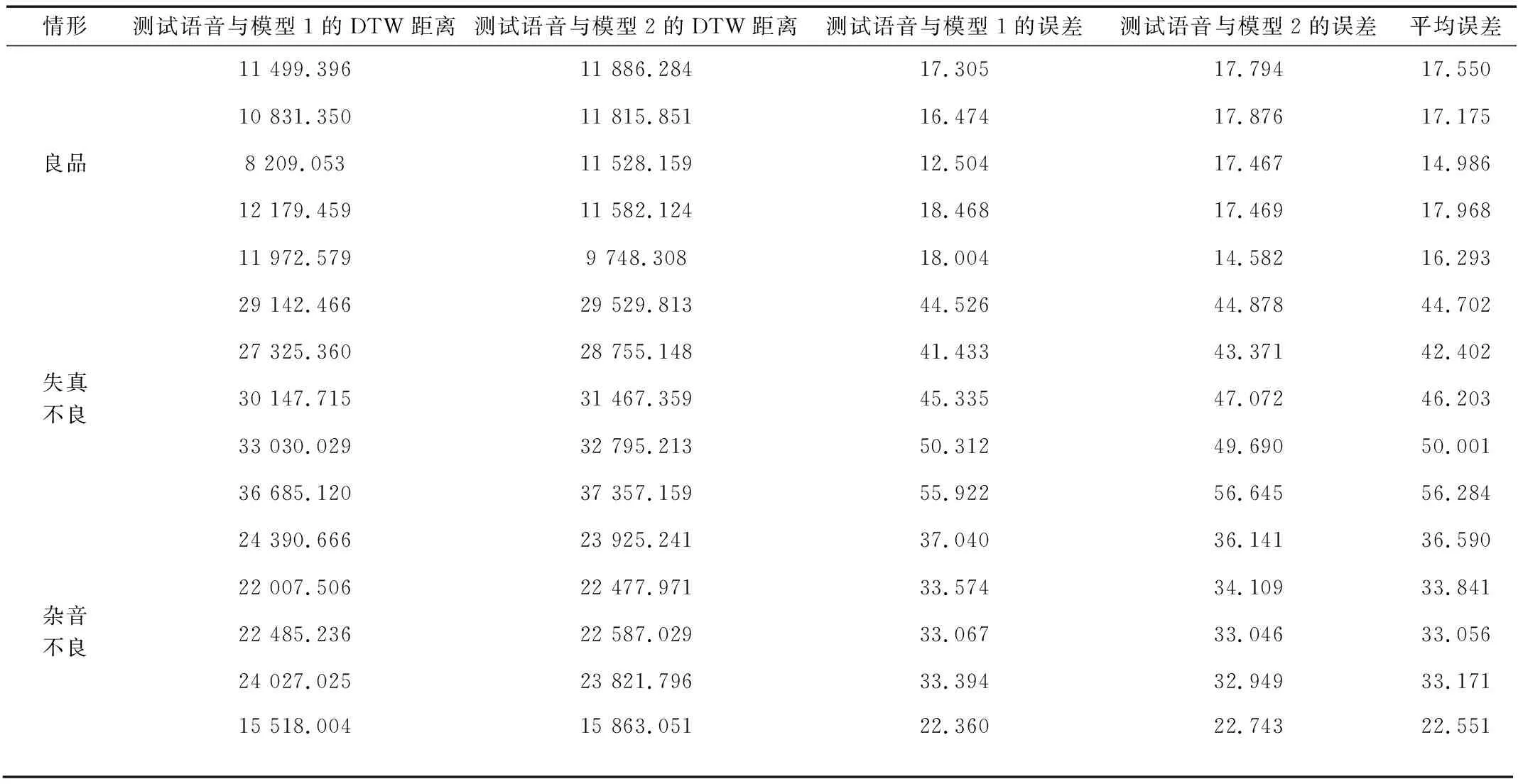
情形测试语音与模型1的DTW距离测试语音与模型2的DTW距离测试语音与模型1的误差测试语音与模型2的误差平均误差良品11 499.39611 886.28417.30517.79417.55010 831.35011 815.85116.47417.87617.1758 209.05311 528.15912.50417.46714.98612 179.45911 582.12418.46817.46917.96811 972.5799 748.30818.00414.58216.293失真不良29 142.46629 529.81344.52644.87844.70227 325.36028 755.14841.43343.37142.40230 147.71531 467.35945.33547.07246.20333 030.02932 795.21350.31249.69050.00136 685.12037 357.15955.92256.64556.284杂音不良24 390.66623 925.24137.04036.14136.59022 007.50622 477.97133.57434.10933.84122 485.23622 587.02933.06733.04633.05624 027.02523 821.79633.39432.94933.17115 518.00415 863.05122.36022.74322.551
3.2 系统性能分析
选定阈值20后,通过计算机模拟无声、杂声和失真三种语音样本对系统进行测试,每种情形测试30次。测试是在与生产线声音功能测试间环境相似的安静环境(环境噪音低于30 dB)下进行的。测试设备为三星Galaxy S4智能手机(2 GB内存,1.6 GHz四核CPU),Android版本为5.0.1,采样率为22 050 Hz,音频的采样精度为8 bit,输入语音流采用单声道,录音测试时间分别采用4 s、8 s、12 s,对失真不良情形进行30次测试,不同时长测试数据如表2所示。由表2可看出,8 s测试时长的准确率最高且平均计算时长较短。因此,在8 s测试时长下分别对不同的不良情形进行了测试,实验结果如表3所示。可以看出,良品与无声不良检测准确率接近100%,失真不良检测准确率高达96.67%,杂声不良检测准确率达93.33%,基本满足需求。
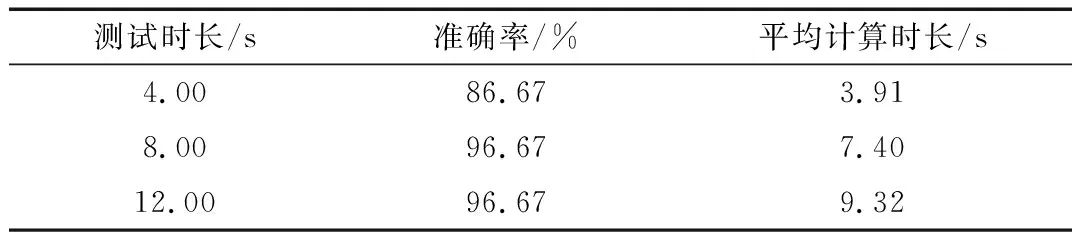
表2 不同时长实验结果
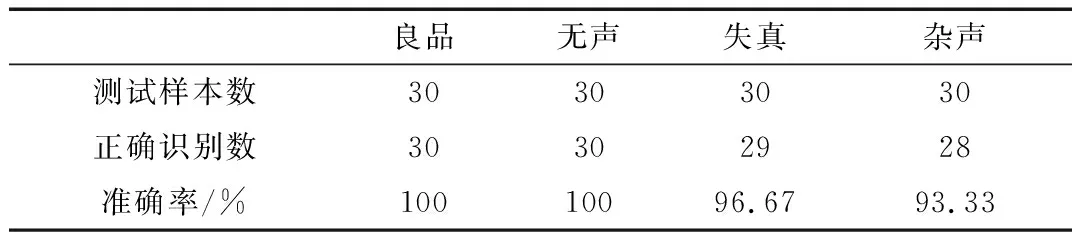
表3 不同情形实验结果
测试时长加上计算时长,本系统总工作时间约为16 s,即16 s可同时判定扬声器与麦克风功能的质量。目前工厂中麦克风测试耗时约1 min,扬声器测试耗时约40 s,因此,本系统可为每台机器省时84 s,效率提高6.25倍。工厂每生产1 000台设备,可节省约23.3 h,本系统将极大促进生产效率。保守估计工厂平均每年生产Android设备80万台,每年将节省18 000 h以上,以5 USD/h计算,显性效益将超过90 kUSD/年。如果在人工出厂测试中发生漏检误检或对工人听力造成损害,损失将更大,初步评估隐形效益至少有180 kUSD/年。
4 结论
显示器生产测试过程中需要对设备扬声器与麦克风等声音功能品质进行测试,针对现有测试系统自动化程度低的问题,本文提出一种基于声纹识别技术的Android设备声音功能自动化测试系统。本系统采用MFCC+ΔMFCC算法提取语音信号特征,通过DTW算法对麦克风录制语音和扬声器播放语音的模型特征进行比对,实现扬声器与麦克风同步对失真、无声、杂声等多种不良进行有效检测。本系统良品与无声不良检测准确率接近100%,失真不良检测准确率高达96.67%,杂声不良检测准确率达93.33%,实现了Android 设备声音功能的自动化测试。相比人工测试,效率提高6.25倍。本系统结构简单、容易实现、移植性强、成本低廉,对企业生产的“无人化”、“自动化”及“机器人化”起到了推进作用。
[1] JI H G,KIM J H. Fault detection and localization using wavelet transform and cross-correlation of audio signal [J]. Journal of the Korean Society for Precision Engineering, 2014, 31(4): 327-334.
[2] 颜敏睿. 手机硬件检测系统的设计与实现[D].成都:电子科技大学, 2014:28-29.
[3] 陈章虹. 音频响度测试与控制系统的研究与实现[D].长沙:中南大学, 2014.
[4] 黄伟鸿. 工厂噪声环境下声音识别系统的设计与实现[D].广州:中山大学, 2014.
[5] CAMPBELL, J P.Speaker recognition: a tutorial[J]. Proceedings of the IEEE,1997,85 (9): 1437-1462.
[6] SAHIDULLAH M.A novel windowing technique for efficient computation of MFCC for speaker recognition[J]. IEEE Signal Processing Letters, 2013,20(2): 149 - 152.
[7] 邵明强,徐志京. 基于改进 MFCC 特征的语音识别算法[J].微型机与应用, 2017, 36(21): 48-50, 53..
[8] 李伟铭. 基于Android的声纹身份验证系统的研究与实现[D].南京:东南大学, 2014.
[9] Hu Bing, Jin Hongxia, Wang Jun, et al. Generalizing DTW to the multi-dimensional case requires an adaptive approach[J]. Data Mining & Knowledge Discovery,2017,31(1):1-31.
[10] 周颖. Android 声纹密码锁设计[D].武汉:武汉理工大学, 2014.
猜你喜欢
电子测试(2022年3期)2023-01-14
青少年科技博览(中学版)(2022年9期)2022-11-01
家庭影院技术(2021年7期)2021-08-14
五金科技(2020年3期)2020-06-28
阅读(快乐英语高年级)(2019年5期)2019-09-10
家庭影院技术(2019年8期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
小学科学(2016年12期)2017-01-06
