
基于二级CFSFDP的扩展目标量测集划分算法
2018-05-30 01:27:05迟珞珈冯新喜
计算机工程 2018年5期
迟珞珈,冯新喜,蒲 磊,曹 倬
(空军工程大学 信息与导航学院,西安 710077)
0 概述
在传统的目标跟踪问题中,通常忽略目标的外形而将目标简化为一个点,即假设一个目标只能产生一个量测,但随着科学技术的发展,雷达等传感器的分辨率不断提高,使得一个目标在一个采样周期内可产生多个量测,通常称这种目标为扩展目标[1-3]。
近年来,人们越来越重视杂波环境下多扩展目标的跟踪问题。传统算法中需要对数据进行关联,但其计算复杂度较高,容易出现组合爆炸,且在实用性和可靠性上面临着考验。对此,文献[3]在随机集理论基础上,提出了扩展目标概率假设密度(Probability Hypothesis Density,PHD)滤波,有效避免了数据关联问题。随后,势概率假设密度(Cardinalized Probability Hypothesis Density,CPHD)滤波、扩展目标高斯混合PHD滤波[4]、扩展目标高斯混合CPHD滤波[5]等滤波算法又相继提出。但无论采取哪种滤波算法,在扩展目标跟踪问题中都涉及到量测集的划分,直接决定了整个跟踪算法的复杂度与状态估计的精确度。同时,由于扩展目标的提出,使得量测集的划分数目随量测数的增加而急剧上升[6-8]。因此,急需寻找一种快速高效的量测集划分算法。针对此问题,文献[1,4]提出了基于距离的划分算法。但由于跟踪过程中存在大量的杂波噪声,同时对扩展目标的形状存在不确定性,因此很难精准划分量测集。此外,为了找到正确的划分,需要选取阀值区间中所有的值,这样做增加了算法的计算量及时间复杂度,影响跟踪算法的实时性。文献[9-10]提出了一种基于K-means聚类法的量测集划分算法。该算法运算速度较快,适用于大量样本的情况,但聚类结果受初始聚类中心随机性的影响很大。文献[11]提出了一种基于模糊自适应共振原理(Adaptive Resonance Theory,ART)的扩展目标量测集划分算法,相比于现有的距离划分法和其它聚类算法,模糊ART算法划分的速度更快且具有较好的稳定性,但是对步长的选择比较敏感。文献[12]提出一种利用谱聚类进行量测集的划分算法,但需要人为确定聚类数目,且存在对初始聚类中心敏感和鲁棒性较差等问题。
2014年,文献[13]提出一种基于密度峰值的空间聚类算法CFSFDP(Clustering by Fast Search and Find of Density Peaks),这种算法对目标的外形不敏感,可实现对任意外形目标的量测集划分。在此基础上,本文针对杂波环境下多扩展目标高斯混合PHD量测集划分难、计算量大的问题,提出一种基于局部异常因子去噪和二级CFSFDP算法的扩展目标量测集划分算法。
1 扩展目标高斯混合PHD滤波器
扩展目标与点目标产生的量测空间区别如图1所示,根据文献[3]所提出的扩展目标PHD滤波模型,假设每个采样时刻传感器得到每个目标产生的扩展目标观测数服从Poisson分布,且扩展目标的观测服从以目标质心为均值的Gaussian分布。

图1 点目标与扩展目标示意图
根据简单的数学知识,很容易得到每个目标实际被检测到的概率,其表达式为:
(1)
假设1目标状态方程和传感器的观测方程是线性高斯模型,即:
fk|k-1(xk|xk-1)=N(xk;Fk-1xk-1,Qk-1)
(2)
fk(zk|xk)=N(zk;Hkxk,Rk)
(3)
假设2目标存活和检测概率与目标状态独立,即:
pD,k(xk)=pD,k
(4)
pS,k(xk-1)=pS,k
(5)
假设3目标的强度函数为高斯和的形式,即:
(6)
通常称满足以上假设的算法为扩展目标高斯混合PHD滤波算法。
假设已知k-1时刻目标的强度函数γk-1|k-1(x),则扩展目标高斯混合PHD滤波器的预测步和更新步可表示如下:
1)预测步
(7)

2)更新步
γk|k(x|Z)=LZ(x)γk|k-1(x|Z)
(8)
(9)
其中,LZ(x)表示量测伪似然函数,对传感器检测概率、噪声模型、虚警等特性进行了全面的描述,其表达式为:
(10)
k时刻目标后验概率γk|k(x)包括两部分,分别用于处理未检测目标和检测到目标的情况。详细推导公式可以参见文献[1]。
对于扩展目标量测集的划分给出如下实例。若某一时刻传感器获得的量测集Z={z1,z2,z3},则其所有划分为:
D1={{z1,z2,z3}}
D2={{z1},{z2},{z3}}
D3={{z1,z2},{z3}}
D4={{z1,z3},{z2}}
D5={{z1},{z2,z3}}
(11)
显然,量测集的所有可能划分随着量测数的增加而急剧上升,尤其是在杂波密集的环境下,其计算量和时间消耗更是成指数倍增长。因此,急需寻找一种合理可行的量测集划分算法。
2 基于二级CFSFDP算法的量测集划分
2.1 局部异常因子去噪
由于传感器获得的观测数据中不但包含对目标观测的有用信息,也包含着杂波信息,同时这些杂波均匀的分布在观测空间中,对量测集的划分存在很大的干扰。本文首先采用局部异常因子来对量测为杂波的程度进行度量,通过设定阈值的算法进行杂波滤除,接着将层次聚类与新近发表在《Science》上的采用密度极点的算法相结合对量测集进行划分,提高了量测集划分的准确度。
局部异常因子(Local Outlier Factor,LOF)是一种基于密度的离群点检测算法,它通过判断观测样本与其最近邻k个邻居的孤立程度来考虑数据的孤立性,实现对偏离大部分数据的异常数据进行检测。
首先,计算x到x′的可达距离:
RDk(x,x′)=max(k-distance(x′),d(x-x′))
(12)
其中,k-distance(x)表示样本x与离它第k近的样本之间的距离,d(x-x′)表示x与x′之间的距离。
然后,计算x的局部可达密度:
(13)
应用这个局部可达密度,可计算出x的局部异常因子:
(14)
图2表示局部异常因子的实例,可见,偏离大部分正常值的数据点具有较高的异常值。各个样本周围的圆的半径与样本的局部异常因子的值成正比,圆的半径越大,其样本越倾向于异常值。经多次实验仿真,本文设局部异常因子大于2的点为异常值。
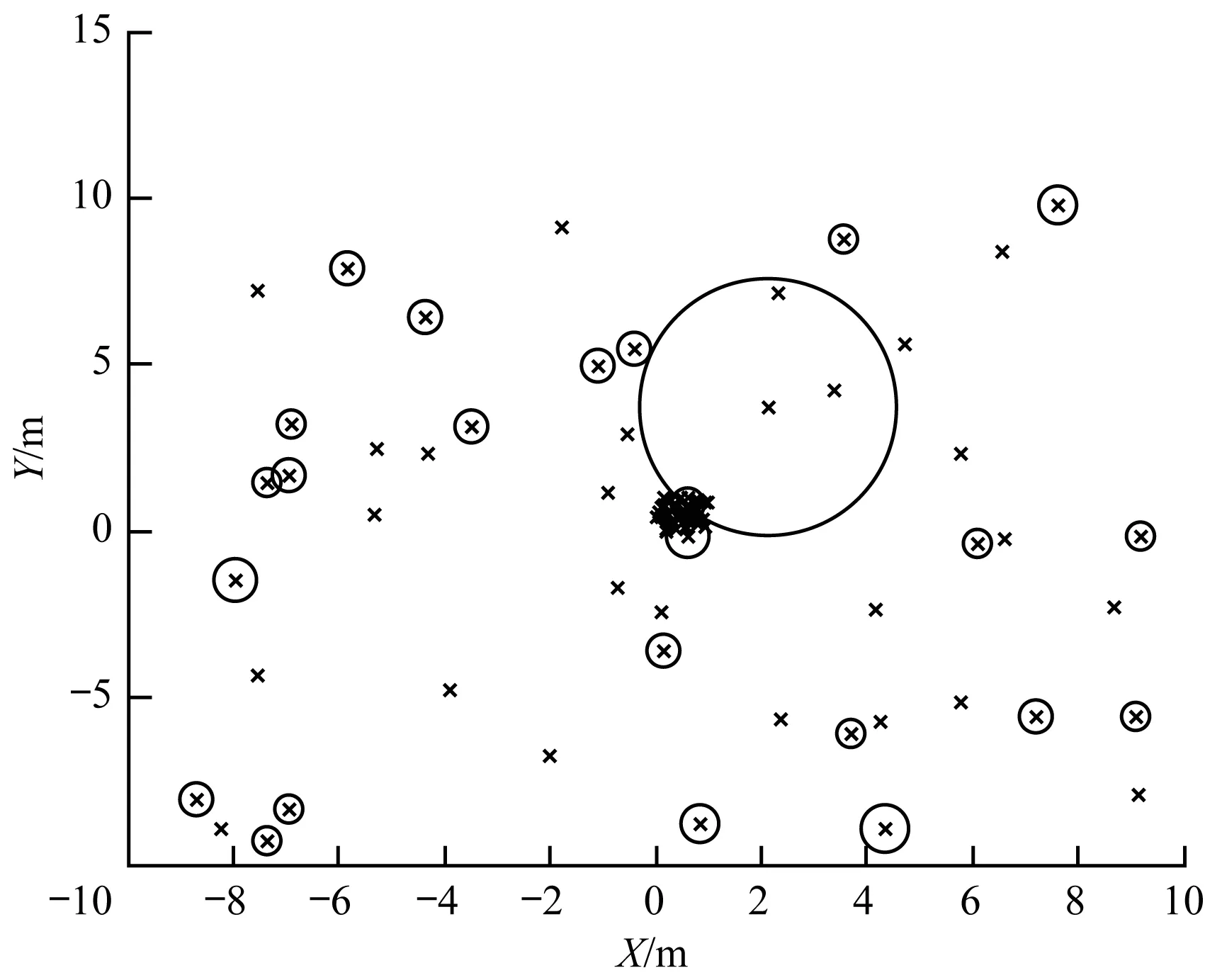
图2 局部异常因子实例
2.2 二级CFSFDP量测集划分算法
2.2.1 CFSFDP算法
2014年,文献[13]提出了一种新的聚类算法CFSFDP。该算法简单新颖、灵活性强,对目标的外形信息不敏感,可以有效处理大数据集,同时解决了聚类初始中心选择难的问题。CFSFDP算法的主要思想为在一个类族中,密度高的类中心总是被密度较低的邻居点包围,且与具有更高密度的任何点都有相对较大的距离。该算法处理流程是:1)通过密度极点确定聚类中心;2)按照一定顺序将数据点归类到距离其最近且密度比它自身密度高的点所属的类中。
对于每一个数据点,该算法只需要计算局部密度ρi、该数据点与密度比它高的最近点的距离δi。算法具体步骤为:
步骤1计算观测点间的距离,构造相似度矩阵。
步骤2通过相似度矩阵和截断距离计算每个观测点的局部密度ρi。
步骤3计算每个观测点与密度比它高的最近点的距离δi。
步骤4使用每一个观测点确定的(ρi,δi)建立决策图,确定聚类中心。
步骤5按密度降序对观测集划分。
算法伪代码如下:
输入观测集为X={X1,X2,…,Xn};截断距离为dc
输出聚类结果为C={C1,C2,…,Cn}
for each point i do
for each point j do
dij=distance from i to j;
//计算每对数据点之间的距离
endfor
endfor
for each point i do
ρi=∑jχ(dij-dc) ;
//计算数据点的局部密度

endfor
//画出决策树,确定聚类中心
sort points by density descend order;
for each point I do
Ci=Cnearest_higer_density_neighbor(i);
//对量测集按密度降序排序,然后按此顺序对数据点//分配,进行聚类
endfor
该算法存在一个很大的缺陷,即当某一类中存在多个密度极点时,那么,一个类将被错误的划分成多个子簇,造成量测集划分不准确的后果。在实际扩展目标跟踪问题中,跟踪的目标存在多种多样的外形特征,不同的外形可能会导致由传感器获得的量测集中存在多个密度极点的现象,此时,若采用CFSFDP聚类对量测集进行划分,则可能错误的将一个目标划分为多个目标。因此,还需要考虑对划分的类再进行合并,以此来实现对任意外形目标的量测集划分,确保算法的跟踪性能。
2.2.2 层次聚类合并准则
在一个多维空间中,不同聚类间通过低密度点集进行划分,每一个聚类都可以表示为一个密度分布相对密集的连通区域。由以上聚类划分思想,即聚类是相对密集的连通区域,聚类之间通过含有密度相对较低的点集的区域来划分的原则,因此相对整个聚类来说,聚类边界的密度是较低的。由此,提出一种合理的假设,即聚类边界区域密度小于聚类平均密度[15-16],当边界密度大于等于聚类平均密度时,则被认为是划分开的不完整聚类的子簇。平均密度和边界区域密度的计算公式定义如下:
(15)
(16)
其中,|Ci|表示第i个聚类中观测点的总数,ρk表示每个观测点的局部密度。聚类合并判定准则如下:
ρbord(Ci,Cj)≥ρavg(Ci)
(17)
ρbord(Ci,Cj)≥ρavg(Cj)
(18)
当式(16)或式(17)成立时,则判定Ci、Cj属于同一聚类,此时需将Ci、Cj进行聚类合并;反之,则无需进行合并。该聚类合并准则,只需遍历一次由CFSFDP算法划分的子簇,即可将满足条件的所有子簇合并得到最终的聚类划分结果,本文称之为二级聚类的CFSFDP量测集划分。
2.2.3 二级CFSFDP算法
由于CFSFDP算法能够高效准确地确定密度峰值点,层次聚类能对其存在的将一个类错误划分成多个子类的缺陷制定合并准则,因此本文采用将CFSFDP 算法与层次聚类相结合的二级CFSFDP算法对扩展目标量测集进行划分。该算法对目标的外形不敏感,可实现对任意外形目标的量测集划分,如图3所示。由图3可以看出,使用二级CFSFDP聚类算法对量测集进行划分,能够在目标处于杂波、近邻、存在多个密度极点等情况下进行精确划分,从而保证对目标的跟踪性能。
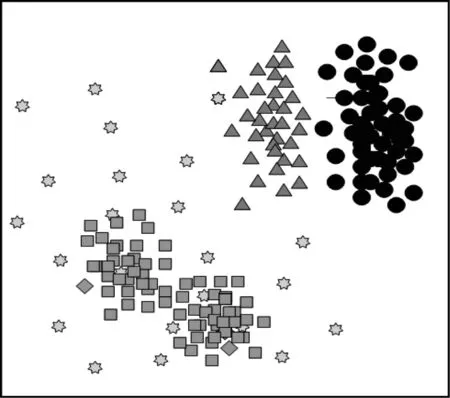
图3 杂波环境下具有不同形状的目标量测集划分
本文所提二级CFSFDP划分扩展目标量测集算法基本步骤如下:

步骤2已知k-1时刻目标的强度函数表示为γk-1|k-1(x),通过式(7)进行一步预测,得γk|k-1(x)。
步骤3计算量测集Zk中观测点间的距离,构造相似度矩阵。
步骤4计算每个观测点的局部密度ρi和高密度距离δi,其表达式为:
ρi=∑jχ(dij-dc)
(19)
(20)
步骤5确定聚类中心。使用点集(ρi,δi)建立决策图,选取同时具有较大ρi值和δi值的点为聚类中心。这里,为了避免用肉眼进行人为观察判断,使该算法可以自主寻找密度峰值点,引进变量α,其表达式为:
α=ρi×δi
(21)
显然,α值越大,越有可能是聚类中心;本文将α进行降序排序,选取前m个点为密度峰值点。
步骤6划分子簇。对前m个点为密度峰值点进行聚类,得到初始子簇{C1,C2,…,Cm}。
步骤7计算每个子簇Ci的平均密度ρavg(Ci)和边界区域密度ρbord(Ci,Cj),按照本文提出的层次聚类合并准则将满足条件的所有子簇合并得到最终的量测集划分结果。
步骤8将划分好的若干个量测集代入式(1)、式(9)中,更新目标强度函数γk|k(x)。
步骤9对更新的γk|k(x)的高斯项进行处理,获得目标状态估计。
3 仿真实验与分析
本文分别在扩展目标处于交叉、近邻2种情景下,将所提二级CFSFDP量测集划分算法与经典的距离划分[9]、K-means++划分[17]、DBSCAN[18]划分等3种算法进行比较分析。对所提算法跟踪扩展目标如下3个方面的性能进行验证:
1)算法的有效性、实时性。
2)是否能发现任意形状的目标。
3)是否能在量测密度差异较大时准确划分量测集。
3.1 扩展目标交叉情景跟踪
3.1.1 实验参数设置
仿真中假设有3个不同形状的扩展目标在监测区域[-1 000 m,1 000 m]×[-1 000 m,1 000 m]内运动,它们的初始状态如表1所示,在第50 s时,3个扩展目标交叉。其中,目标的存活概率Ps=0.99,检测概率PD=0.99,传感器采样间隔T=1 s,整个跟踪过程持续100 s,共进行200次蒙特卡洛实验。

表1 目标初始状态
扩展目标运动模型为:
(22)
其中,Xk=[xk,yk,vx,vy]T,(xk,yk)表示目标的位置信息,(vx,vy)表示目标的速度信息,过程噪声标准差为σw1=σw2=2 m/s2。假设整个过程都是在扩展目标高斯混合PHD模型框架下进行。则扩展目标的强度函数可以表示为:
Db(x)= 0.1×N(x;mb(1),Pb)+0.1×
N(x;mb(2),Pb)+0.1×N(x;mb(3),Pb)
(23)
其中:
mb(1)=[-800,-600,0,0]T,mb(2)=[-900,100,0,0]T,mb(3)=[-700,700,0,0]T,Pb=diag(100,100,25,25)。
扩展目标量测方程为:
(24)
其中,Zk=[xk,yk]T量测噪声标准差σR1=σR2=20 m。背景杂波数服从均值为10泊松分布,且在监测区域内均匀分布。仿真参数设置最大高斯分量数目为Jmax=100,修剪门限Tp=10-4,合并门限U=4。
3.1.2 实验分析
在扩展目标处于交叉情况下,选择3个不同形状的扩展目标,使其产生的量测个数分别服从均值为10,20,40 的泊松分布,将所提二级CFSFDP量测集划分算法与经典的距离划分、K-means++划分、DBSCAN划分等3种算法进行比较分析。用目标估计数、OSPA距离[19]、平均计算时间3个指标对算法的性能进行评价。
由图4可以看出,K-means++划分算法对目标的估计数与实际目标数偏差较大,该算法不能准确辨别错误划分中的量测,使扩展目标数被高估。同时,在目标量测密度差异较大时,距离划分、DBSACAN划分也无法准确估计出目标数,具有一定的局限性。在第50 s 3个扩展目标相交时,相对于其他算法,本文所提的二级CFSFDP由于是根据密度峰值点及低密度边界点进行量测集划分,当扩展目标相交时,只要其密度峰值点不重合,即能够较好地对量测集进行划分,且在其他时刻均能准确估计出任意形状扩展目标的真实数目。
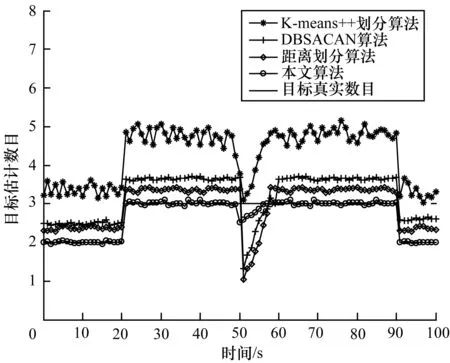
图4 目标交叉时目标数目估计
由图5可以看出,在目标量测密度差异较大且存在交叉情况时,本文所提的二级CFSFDP对任意形状扩展目标量测集的划分结果明显优于其他算法。

图5 目标交叉时OSPA距离
由图6可以看出,本文所提的二级CFSFDP在具有较好扩展目标量测集划分效果的同时,也具有较好的时效性。二级CFSFDP聚类算法虽然是在CFSFDP聚类基础上对划分的类再进行合并,增加了算法的运算复杂度,但是从图6可以看出,该算法的运算效率依然较高,虽然相比于DBSCAN划分,所用时间较多一些,但与距离划分和K-means++划分相比,则显示出明显的优势。在图5中,DBSCAN划分在目标密度差异较大、存在交叉情况下无法准确估计出目标的数目,跟踪性能明显下降。可以看出,在综合考虑目标跟踪性能与时效性方面,本文所提的二级CFSFDP聚类算法具有较好的优势。

图6 目标交叉时平均计算时间
3.2 扩展目标近邻情景跟踪
3.2.1 参数设置
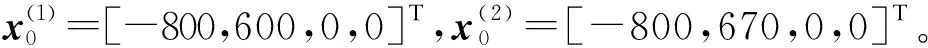
3.2.2 结果分析
在扩展目标处于近邻情况下,选择2个扩展目标,使其产生的量测个数均服从均值为10的泊松分布。用目标估计数、OSPA距离、平均计算时间3个指标对算法的性能进行评价。
由图7~图9可知,当扩展目标处于近邻情况时,由于本文所提的二级CFSFDP是跟据密度峰值点来划分量测集的,因此2个近邻的扩展目标会因密度峰值点的差异而被划分开,能够对任意形状扩展目标量测集进行较好的划分,且时效性相对较好,虽然时效性上略差于DBSCAN算法,但DBSCAN算法容易将近邻的不同扩展目标划分为同一目标,低估目标数目。

图7 目标近邻时目标数目估计

图8 目标近邻时OSPA距离
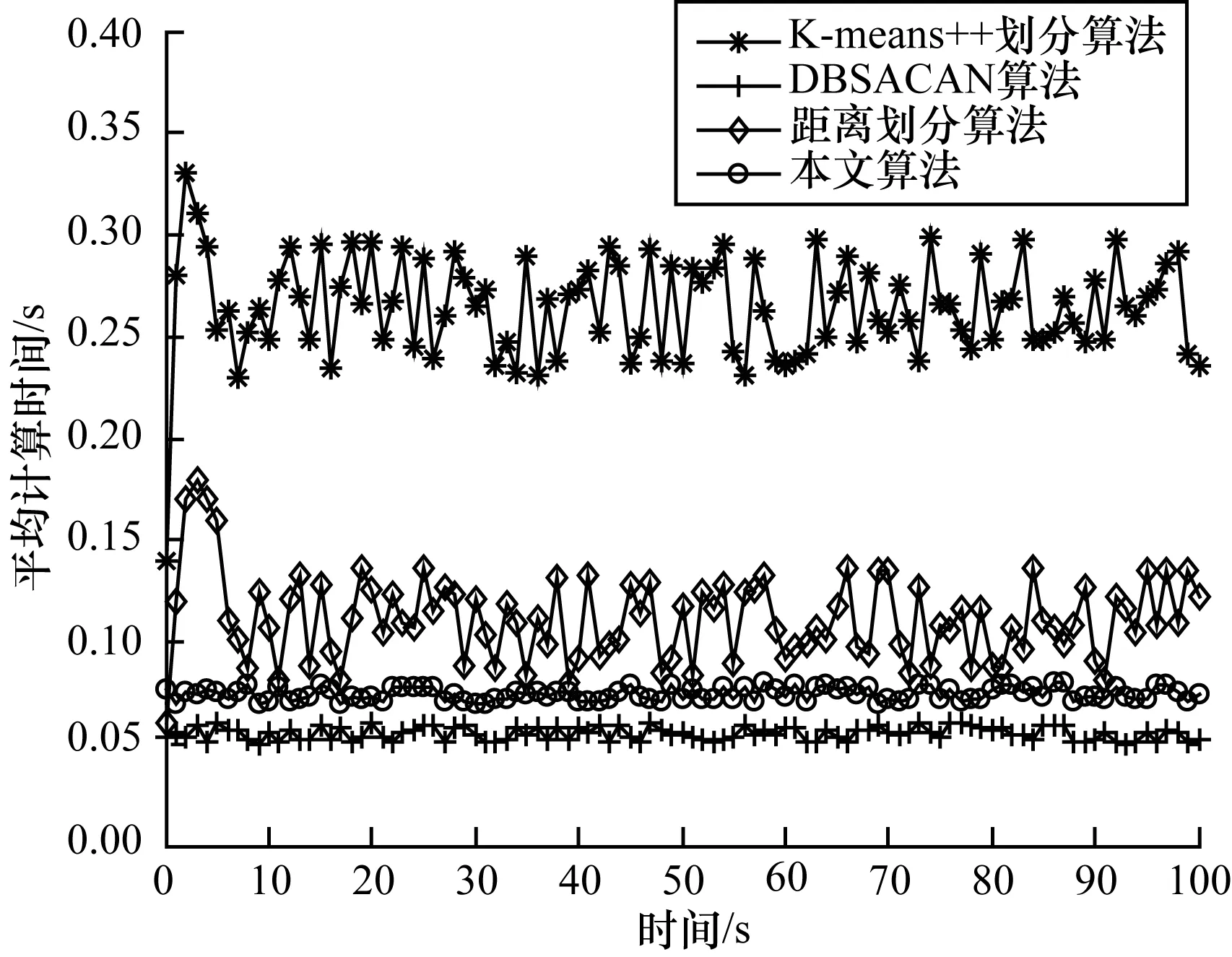
图9 目标近邻时平均计算时间
距离划分虽然可以较好估计目标数目,但其平均计算时间久,时效性差。K-means++划分算法对扩展目标的跟踪效果最差。可以看出,在综合考虑目标跟踪性能与时效性方面,本文所提的二级CFSFDP聚类算法具有较好的优势。
4 结束语
针对扩展目标处于交叉及近邻情况下量测集划分难的问题,本文提出一种基于二级CFSFDP的扩展目标量测集划分算法。实验结果表明,在目标量测密度差异较大,且存在交叉或近邻情况时,该算法能够较为准确地对任意形状扩展目标量测集进行划分,在保证跟踪有效性和可行性的同时,有效减少了计算时间,其结果明显优于其他传统算法。下一步将研究当扩展目标交叉时,该算法目标密度峰值点的重合情况,从而进一步优化算法。
[1] GRANSTROM K,LUNDQUIST C,ORGUNER U.Extended target tracking using a gaussian-mixture PHD filter[J].IEEE Transactions on Aerospace and Electronic Systems,2012,48(4):3268-3286.
[2] 刘风梅.多扩展目标跟踪量测集划分算法研究[D].无锡:江南大学,2015.
[3] MAHLER R.PHD filters for nonstandard targets,i:extended targets[C]//Proceedings of the 12th International Conference on Information Fusion.Washington D.C.,USA:IEEE Press,2009:915-921.
[4] GRANSTROM K,LUNDQUIST C,ORGUNER U.A gaussian mixture PHD filter for extended target tracking[C]//Proceedingsof the 13th International Conference on Information Fusion.Washington D.C.,USA:IEEE Press,2010:1-8.
[5] ORGUNER U,LUNDQUIST C,GRANSTROM K.Extended target tracking with a cardinalized probability hypothesis density filter[C]//Proceedings of the 14th International Conference on Information Fusion.Washington D.C.,USA:IEEE Press,2011:1-8.
[6] 刘妹琴,兰 剑.目标跟踪前沿理论与应用[M].北京:科学出版社,2015.
[7] YANG Jinlong,LIU Fengmei,GE Hongwei,et al.Measurement partition algorithm based on density analysis and spectral clustering for multiple extended target tracking[C]//Proceedings of CCDC’14.Washington D.C.,USA:IEEE Press,2014:4401-4405.
[8] 孔云波,冯新喜,危 璋.利用高斯混合概率假设密度滤波器对扩展目标量测集进行划分[J].西安交通大学学报,2015,49(7):126-133.
[9] LI Yunxiang,XIAO Huaitie,SONG Zhiyong.A new multiple extended target tracking algorithm using PHD filter [J].Signal Processing,2013,93 (12):3578-3588.
[10] 程艳云,周 鹏.动态分配聚类中心的改进K均值聚类算法[J].计算机技术与发展,2017,27(2):33-36.
[11] ZHANG Yongquan,JI Hongbing.Gaussian mixture reduction based on fuzzy ART for extended target tracking[J].Signal Processing,2014,97(7):232-241.
[12] YANG Jinlong,LIU Fengmei,GE Hongwei,et al.Multiple extended target tracking algorithm based on GM-PHD filter and spectral clustering[J].EURASIP Journal on Advances in Signal Processing,2014,117:1-8.
[13] RODRIGUEZ A,LAIO A.Clustering by Fast Search and Find of Density Peaks[J].Science,2014,344(6191):1492-1496.
[14] 章 涛,吴仁彪.近邻传播观测聚类的多扩展目标跟踪算法[J].西安交通大学学报,2016,31(4):764-768.
[15] 许合利,牛丽君.基于层次与密度的任意形状聚类算法[J].计算机工程,2016,42(7):159-164.
[16] 张文开.基于密度的层次聚类算法研究[D].合肥:中国科学科技大学,2015.
[17] ARTHUR D,VASSILVITSKII S.K-means++:the advantages of careful seeding[C]//Proceedings of the 18th Acm-siam Symposium on Discrete Algorithms.New Orleans,Louisiana:Society for Industrial and Applied Mathematics Philadelphia,2007:1027-1035.
[18] ESTER M,KRIEGEL HP,SANDER J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of the International Conference on Knowledge Discovery and Data Mining.Oregon,Porland:the Association for the Advancement of Artificial Intelligence,1996:226-231.
[19] SCHUHMACHER D,VO B N.A consistent metric for performance evaluation of multi-object filters[J].IEEE Transactions on Signal Processing,2008,56(8):3447-3457.
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
科学与信息化(2021年30期)2021-12-24 08:00:20
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
西北工业大学学报(2015年3期)2015-12-14 13:08:44
遥测遥控(2015年2期)2015-04-23 08:15:22
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
电子设计工程(2015年6期)2015-02-27 12:04:53
现代防御技术(2014年6期)2014-02-28 18:26:39
