
基于空间卷积神经网络模型的图像显著性检测
2018-05-30 01:38:20高东东张新生
计算机工程 2018年5期
高东东,张新生
(西安建筑科技大学 管理学院,西安 710055)
0 概述
显著性检测已成为计算机视觉领域的重要研究课题,它的目的就是捕捉吸引人类注意的像素或区域。随着信息技术的快速发展,如何设计及利用计算机模型处理这些以爆炸式速度增长的图像及视频信息,对于弥补人与电脑在视觉理解中的差距具有重要的研究意义和应用价值。
快速且以数据驱动的自底向上的显著性检测方式成为目前研究的主流[1]。其中,Itti模型[2]最早提出利用图像底层特征的“中心-周边差”进行显著性检测。文献[3]则在文献[2]的基础上提出基于图模型的显著性检测算法(GBVS),通过计算不同特征图的马尔科夫链平衡分布获取显著图。文献[4]使用颜色与亮度低级特征计算图像子区域像素与其邻域的像素平均特征向量之间的距离获得显著值,该方法快速且易于实现。文献[5]提出基于局部特征对比度的显著性检测,学习局部信息进行显著性评估,该方法在显著区域的边缘处产生较高的显著值。上述方法都是基于手工设计特征提取图像特征信息,它不能有效地捕捉显著目标的深层特征,也没有均匀地突出显著区域。
然而,深度学习方案的提出显著地提高了系统的检测性能。其中,文献[6]提出利用双层深度玻尔兹曼机(DBM)判别显著性区域,增强了基于低级特征学习的能力,但此方法需要经过大量学习训练,复杂度较高。卷积神经网络(Convolutional Neural Network,CNN)被广泛用于学习图像数据中的丰富特征信息[7-9],在显著区域检测[10-11]与对象轮廓检测[12-13]中都取得较为理想的检测结果。另一方面,一些方法也引入或改进了新的网络架构。文献[14]设计了一个能同时预测人眼固定点及分割突出目标的CNN模型,并结合预先训练的VGG网络和SALICON数据集定位出显著区域。文献[15]提出基于超像素卷积神经网络的显著性检测方法,从颜色唯一性和颜色分布2个超像素序列来计算显著性与非显著性区域。该方法突出了显著物体的内部信息,但在显著边缘的聚焦点不清晰,尤其处理非均匀背景或较复杂场景的图像检测性能较差。
基于以上分析,为了能够更准确地检测出人眼感兴趣的显著点,本文采用完全数据驱动的方式,以CNN模型为基础模型,添加空间变换思想,学习图片中应该关注的区域并且通过仿放射变换放大该区域。再使用Adam优化器来训练网络,提高模型收敛速度和检测的准确度。
1 CNN与STN算法
1.1 卷积神经网络
CNN是首个真正成功训练多层神经网络的学习算法,它通过描述数据的后验概率进而实现网络结构的优化。其基本结构由输入层(Input)、卷积层(Convolution)、池化层(Pooling)、全连接层(Fully Connected)及输出层(Output)组成。

(1)
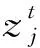
下采样层的主要目的就是降维,即减少卷积层的特征维数,对池化层中每个大小为n×n的池进行 “最大值(max pooling)”或“均值(mean pooling)操作,进一步获得抽样特征,输出过程可表示为:
(2)

1.2 空间变换神经网络
为了更好地处理显著性检测任务,本文在CNN模型上插入空间变换网络(Spatial Transformer Network,STN)[16]。它应用在深度卷积网络之前,与深度网络一起进行端对端训练,增加模型特征提取的旋转不变形。即以一种动态的方式对输入图像进行任意变形(扭曲、拉伸等),这种方式的组成步骤如下:
步骤1由预处理后的图像集U,通过优化后的VGG网络结构输出变换参数θ,即2×3维的空间变换矩阵。
步骤2由上述参数θ,经过仿射变换实现逆向坐标映射,得到输入与输出图像之间的采样网格Tθ。
步骤3将采样网格Tθ输出的结果通过双线性插值技术进行处理,得输出变换图像V。

(3)
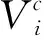
(4)
经过以上理论推导,即实现了对输入图像的空间变换操作,增大了本文模型获取具有高激活值的显著区域的概率。
2 空间卷积网络的显著性检测模型
显著性检测就是在图像区域内找出特征最明显的子区,即检测的关键集中在特征学习上,基于CNN与STN具有的强大的特征提取能力,本文提出应用空间卷积特征学习的显著性检测模型。图1给出了本文模型的整体框架图,其中包括图像预处理、全局与局部显著性估计、显著性融合及显著训练。

图1 显著性检测模型框架图
2.1 图像预处理
给定待处理图像数据集I={Itrain,Ival,Itest},图像预处理过程包括以下步骤:
步骤1将I全部缩放到96×96大小,以适应本文模型的输入。

步骤3将I中像素除以255,归一化到[0,1]中,以加快模型收敛速度。
2.2 模型结构
检测框架主体由全局(shallow model)与局部(STN model)块组成。其中,全局模型包含3个卷积层和3个池化层,在每一个卷积层和全连接层的输出过程当中,都经过ReLU非线性化处理。其连接模型使用:
Conv1→MaxPool1→Conv2→MaxPool2→Conv3→MaxPool3→FC
同时,局部块也采用了相同的设计思路,每层的详细参数说明如图2所示。
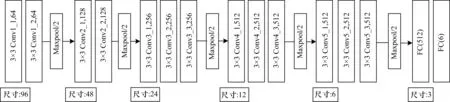
图2 优化后的VGG结构
结构设计遵循如下步骤:
步骤1使用式(1)和式(2),组合3个卷积层与池化层,以构建shallow model。
步骤2通过采用及优化VGG模型以学习出6个变换参数θ,用于下一步的空间变换。
步骤3依据步骤2的空间参数,经过式(3)与式(4),实现对输入图像的空间聚焦变换。
步骤4根据步骤3得到变换后的图像,再嵌入到CNN,进一步组建STN model。
步骤5融合步骤1及步骤4中所得全局显著图与局部显著图,以检测出图像特征表示的最大值。
步骤6在最后一层全连接层前,增加一层maxout激活函数,以过滤出高显著性特征表达,完成显著性检测。
在步骤2的输出中,由于本实验最终目的并不是分类,即对VGG-16结构进行优化以适应本文的显著性检测任务。具体做法为:去掉最后一层原本用于输出类别的全连接层,将第1个FC设置为512,第2个FC大小为6。图2显示了优化后VGG结构的详细参数设置。
2.3 模型训练与优化策略选择
本文采用Adam法代替传统的梯度下降法来训练模型,即每一次迭代学习率都随前面的梯度值进行自适应的调整。相比传统的梯度下降,Adam法计算速度更加高效,且更适用于大规模的数据集训练。采用这种参数更新策略使得参数比较平稳,也加快了模型的收敛速度。同时,训练过程中将iSUN数据集作为训练数据,为了尽量利用有限数据进行训练,使用数据预处理与数据提升技术来增加训练样本。具体做法是在数据预处理阶段,通过一系列的随机变换将训练数据进行提升,使模型捕获不到任何两张完全相同的图像,进而缓解过拟合现象,增强模型的泛化能力。最后,所有样本均进行分批量的训练,每一个批量为32个样本,动量为0.9。鉴于硬件的内存限制,这是可以使用的最大的批量数。Adam中的参数设置:α=0.001,β1=0.9,β2=0.999,δ=10-8。
为了防止模型训练过拟合,本文选择了一些优化策略:1)L2正则化对网络参数进行约束;2)网络损失函数采用均方误差(Mean Squared Error,MSE),以滤除输出中的高空间频率;3)在VGG网络中的第一个全连接层后接入dropout层。其本质是在训练过程中的权重调整时,在隐藏层以一定的概率丢弃一些神经元(丢失率设为0.5)。同时,为使VGG网络更好地适应显著性检测任务,把预训练好的权重值加载到优化后的VGG结构中。最后,对新加入网络层的权重也进行初始化,并随整个网络结构一起训练。
3 实验结果与分析
实验使用Python2.7、NumPy和深度学习库Keras来实现,采用相对复杂的公开数据集进行性能的检测。与现有显著性检测方法进行比较,并从不同的角度分析实验结果。
3.1 数据集
本实验选择了在LSUN挑战中提出的2个数据集,因为它们与通常使用的数据集相比具有一定的复杂性。 这些数据集是:1)SALICON[17]。它通过鼠标跟踪点击突出点进行构建,且所有图像来自流行的MS COCO图像数据库,包含80个物体类别,共有10 000个训练图像、5 000个验证图像、5 000个测试图像;同时,具有丰富的语境信息和分辨率为 640×480像素的图像。2)iSUN。它通过使用网络摄像头并从亚马逊土耳其机器人(Amazon Mechanical Turk)的眼动追踪进行收集,且所有的图像选择于自然场景SUN[18]图像数据库,共有6 000个训练图像、926个验证图像、2 000个测试图像。在选用的数据集中,有些图片的背景特征特别复杂,这也增大了显著性检测的难度。
3.2 评价指标
为了定量评估本文模型的性能及有效性,选用相似性(Similarity)、AUC(Area Under Curve)及相关系数(Correlation Coefficient,CC)作为评价指标。其中,AUC值为ROC曲线与x轴之间距离的积分,能直观地衡量检测结果的优劣程度,取值范围为0~1,且1为最佳状态。CC表示模型预测的显著性区域与人眼关注区域之间的线性关系,由2个映射对应的标准偏差之间的协方差计算得出,该取值范围为0~1之间,且结果值越大说明两者之间具有较好的线性关系,显著性检测准确率也就最高。
3.3 结果分析
在本实验中,所有数据分为2个子集:一个用于训练(75%);另一个用于测试(25%)。55%的数据(训练集)用于训练模型。20%的数据(验证集)用于测试模型训练结果。测试数据(25%)用于获取本文所提出模型的显著性值。图3展示了训练过程的数据分布情况。同时,将本文算法与其他参与者进行比较,包括LCYLab[19]、基线Itti[2]、改进Rare 2012[20]、基线GBVS[3]、Xidian[21]、基线BMS[22]、WHU IIP[19]。

图3 实验数据集分布
表1给出了本文算法在2个数据验证集上的检测结果。可以看出,各个指标值都较为理想,在2个数据集中呈现出非常有竞争力的结果,也体现了本文算法在数据集之间具有较好的鲁棒性。表2、表3详细列举了本文算法与其他显著性算法在2个数据集上所得的实验值。对于所考虑的每个指标,本文算法的检测值与真实显著值的相似度是最高的,且在2个数据集上都取得较好的AUC值,表明了本文所提模型的优越性能。图4直观地比较了显著性预测的平均AUC。与最先进的方法相比,本文算法的检测精度在SALICON数据集上提高了约6.42%,在iSUN数据集上提高了7.32%。整个模型结构表现出较小的偏差,多角度证明了本文提出的算法具有更强的鲁棒性。

表1 不同数据验证集上的测试结果

表2 iSUN测试集上的检测结果比较

表3 SALICON测试集上的检测结果比较
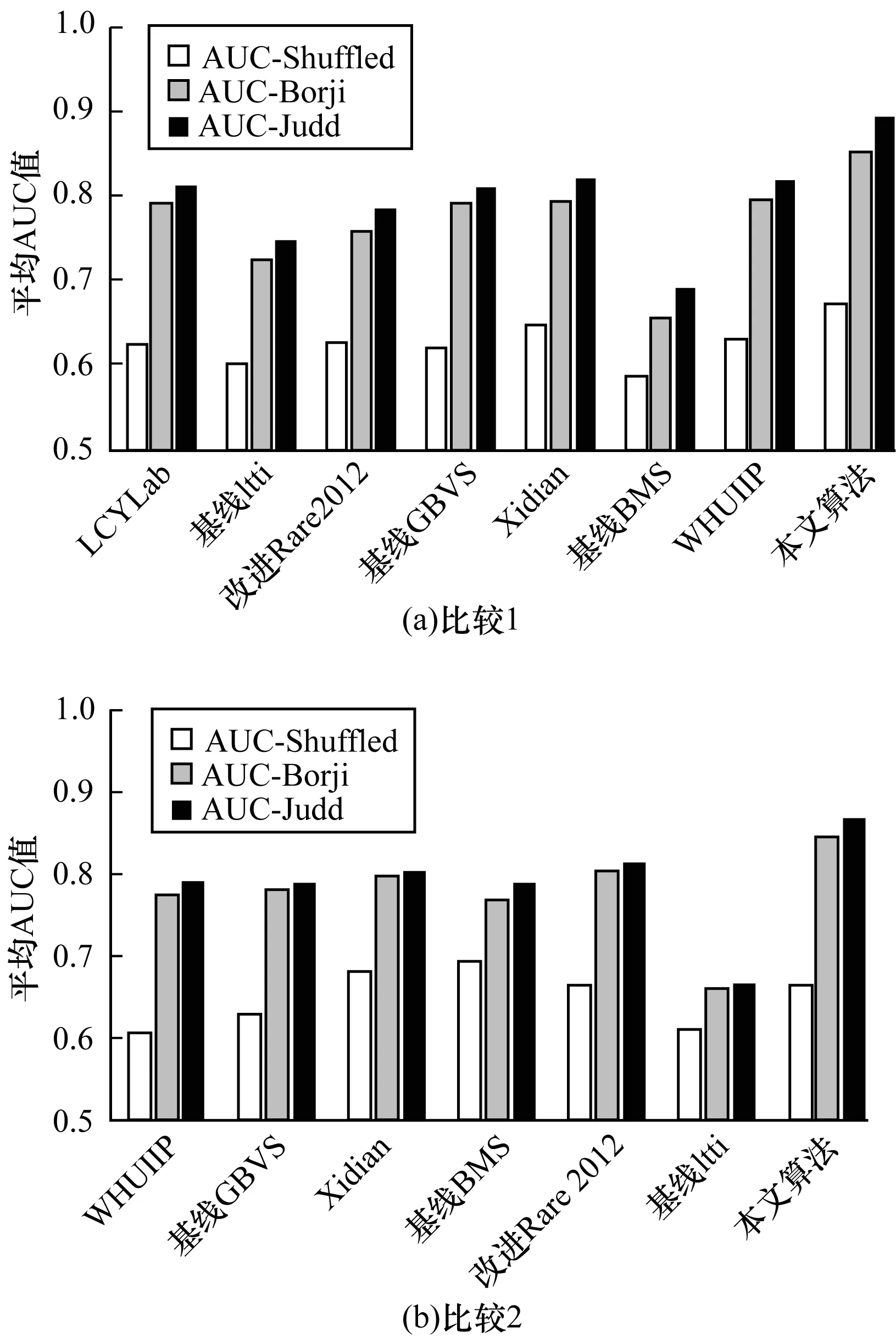
图4 7种显著性检测算法的平均AUC比较
可视化效果如图5所示,在每组中,左边第1列为原始图像,第2列为Ground truth,第3列为本文算法预测的显著图。可以看到,本文算法提供更高的空间分辨率,显著区域的聚焦点突显,也与视觉注意点吻合,满足人眼视觉的观赏性。此外,无论是在复杂场景(草地),还是较大显著目标区域(木屋)或较小显著目标区域(足球场),本文算法都能取得不错的效果,表明提出的模型具有良好的稳定性。然而,在效果图中有一些块状片,影响了部分可视化的愉悦度,产生该现象的原因是对于显著性与非显著区域特征的提取不是很精确。总地来说,从定量化评价与整体视觉效果都一致证明本文算法的预测结果要优于其他算法。这也与本文任务相一致,将显著性检测转换为回归问题,利用深度学习方法设计端对端模型,进而提高检测准确率的能力。

图5 由本文算法在实验数据集上生成的显著图
4 结束语
本文提出一种组合卷积神经网络与空间变换神经网络进行显著性检测的新型端对端算法。首先对源图像进行预处理,接着对全局与局部特征采用不同的提取策略并进行融合。利用CNN深度捕捉上下文信息从而丰富图像的全局特征,用于突出显示显著区域内部的优势;将空间变换技术加入到CNN层以学习局部信息,有助于控制背景噪声。融合全局显著图与局部显著图后获得最终显著结果。实验结果表明,本文算法相较于其他基于图像的显著性检测模型在相识度及AUC上均有一定的提高,算法在iSUN数据集上的平均AUC为0.893 9,相似度系数为0.702 5,相较于主流算法有一定优势,说明了空间卷积神经网络的重要性,以及融合局部与全局特征进行显著性检测的有效性。本文提出的空间卷积神经网络模型能够快速计算图像的显著值,实现了轻量级架构。但是模型参数有限,所以下一步工作是加深该模型的网络深度,进一步挖掘图像中的深层次信息。
[1] ZHANG Xilin,LI Zhaoping,ZHOU Tiangang,et al.Neural activities in v1 create a bottom-up saliency map[J].Neuron,2012,73(1):183-192.
[2] ITTI L,KOCH C,NIEBUR E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[3] HAREL J,KOCH C,PERONAP.Graph-based visual saliency[C]//Proceedings of the 20th Annual Conference on Neural Information Processing Systems.Cambridge,USA:MIT Press,2007:545-552.
[4] ACHANTA R,ESTRADA F,WILS P,et al.Salient region detection and segmentation[C]//Proceedings of the 6th International Conference on Computer Vision Systems.Berlin,Germany:Springer,2008:66-75.
[5] RAHTU E,KANNALA J,SALO M,et al.Segmenting salient objects from images and videos[C]//Proceedings of European Conference on Computer Vision.New York,USA:ACM Press,2010:366-379.
[6] WEN Shifeng,HAN Junwei,ZHANG Dingwen,et al.Saliency detection based on feature learning using deep Boltzmann machines[C]//Proceedings of IEEE International Conference on Multimedia and Expo.Washington D.C.,USA:IEEE Press,2014:1-6.
[7] 易 生,梁华刚,茹 锋.基于多列深度3D卷积神经网络的手势识别[J].计算机工程,2017,43(8):243-248.
[8] 王奎奎,玉振明.基于DCT零系数与局部结构张量的局部模糊检测[J].计算机工程,2017,43(6):207-211.
[9] 江 帆,刘 辉,王 彬,等.基于CNN-GRNN模型的图像识别[J].计算机工程,2017,43(4):257-262.
[10] LI Guangbin,YU Yizhou.Visual saliency detection based on multiscale deep CNN features[J].IEEE Transactions on Image Processing,2016,25(11):5012-5024.
[11] LI Hongyang,CHEN Jiang,LU Huchuan,et al.CNN for saliency detection with low-level feature integration[J].Neurocomputing,2017,226(3):212-220.
[12] QU Liangqiong,HE Shengfeng,ZHANG Jiawei,et al.RGBD salient object detection via deep fusion[J].IEEE Transactions on Image Processing,2017,26(5):2274-2285.
[13] 李岳云,许悦雷,马时平,等.深度卷积神经网络的显著性检测[J].中国图象图形学报,2016,21(1):53-59.
[14] KRUTHIVENTI S S,GUDISA V,DHOLAKIYA J H,et al.Saliency unified:a deep architecture for simultaneous eye fixation prediction and salient object segmentation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2016:5781-5790.
[15] He Shengfeng,LAU R W H,LIU Wenxi,et al.SuperCNN:a superpixelwise convolutional neural network for salient object detection[J].International Journal of Computer Vision,2015,115(3):330-344.
[16] JADERBERG M,SIMONYAN K,ZISSERMAN A,et al.Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems.Cambridge,USA:MIT Press,2015:2017-2025.
[17] JIANG Ming,HUANG Shengsheng,DUAN Juanyong,et al.SALICON:saliency in context[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2015:1072-1080.
[18] XIAO Jianxiong,HAYS J,EHINGER K A,et al.SUN database:large-scale scene recognition from abbey to zoo[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2010:3485-3492.
[19] IBARZ J,SZEGEDY C,VANHOUCKE V,et al,Large-scale scene understanding(LSUN)[EB/OL].[2017-04-20].http://lsun.cs.princeton.edu/leaderboard/#saliencyisun.
[20] RICHE N,MANCAS M,DUVINAGE M,et al.Rare2012:A multi-scale rarity-based saliency detection with its comparative statistical analysis[J].Signal Processing:Image Communication,2013,28(6):642-658.
[21] XIA Chen,QI Fei,SHI Guangming.Bottom-up visual saliency estimation with deep autoencoder-based sparse reconstruction[J].IEEE Transactions on Neural Networks and Learning Systems,2016,27(6):1227-1240.
[22] ZHANG Jianming,SCLAROFF S.Saliency detection:a boolean map approach[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2013:153-160.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年24期)2019-02-23 13:22:26
西南交通大学学报(2018年5期)2018-11-08 10:58:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20 15:25:20
知识产权(2016年8期)2016-12-01 07:01:32
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
