
基于服务相似度的移动用户近似邻居选取方法
2018-05-30 01:37:37贾华丁熊于宁
计算机工程 2018年5期
缪 峰,贾华丁,熊于宁
(西南财经大学 经济信息工程学院,成都 610074)
0 概述
近年来,随着互联网技术、信息技术、移动通信和硬件技术的发展,使用移动智能设备上网的人数已经超过使用普通电脑上网人数,同时针对性地也出现了丰富多彩的各种移动网络服务。但是移动智能设备存在着显示界面小、电源持续使用时间短、输入输出能力有限等问题,从而使得移动用户难以实时获取自己所真正需求的服务,造成了严重的移动信息过载或移动信息迷失等问题[1]。移动推荐系统的目的是从过载的信息中识别出用户感兴趣的内容,解决上述问题。其近年来已成为推荐系统研究领域最为活跃的课题之一[2-3],而找到跟目标用户兴趣相似的邻居集是其中非常关键的一个环节[4]。
传统的近似邻居集选取方法忽略了服务之间的相似性,从而遗漏部分具有相似兴趣的用户。部分研究者提出根据标签、分类或评分来计算服务之间的相似性,但是在移动服务提供平台中存在分类较粗、标签缺失、评分矩阵稀疏等问题,从而使得现有方法无法直接应用到移动服务方面。服务介绍是提供移动服务必须的一个内容,其说明服务的功能和作用。为此,本文基于服务介绍内容,通过短文本相似度计算方法求出服务之间的相似性,从而将服务相似度考虑进用户相似计算中,找出真正具有相似兴趣的用户集,针对冷启动等原因造成目标用户近似邻居集数量过于庞大的问题,提出一种分步筛选用户邻居集的方法。
1 研究背景
用户相似度的度量方法主要分为2种:一种是Correlation相似度方法,即通过用户对项目的评分来计算,余弦相似度、Pearson系数、欧几里德距离相似度、斯皮尔曼等级关联法都属于此类[5];另一种是Relevance相似度方法,即通过用户对相同项目的浏览、使用等来计算,如Jaccard方法、对数似然相似度法等[6-7]。传统的相似度度量方法随着项目数量的不断增大导致评分矩阵稀疏,且没有考虑服务之间的相似性,使得用户之间的相似度计算结果不够准确。例如2个用户分别使用了“爱奇艺”和“优酷”2个服务,传统方法认为2个用户使用的是不同的项目,不具有相似性。但从兴趣角度出发,2个用户都体现出了对影音方面的兴趣,应具有相似性。越来越多的学者意识到了这个问题,开始了相关研究。有些学者考虑从项目类别方面计算服务相似度,部分文献简单认为2个服务同属一个类别则相似度为1,否则为0。文献[8]通过构建类别树从多层次多类别上考虑项目的相似性。这些方法要求项目的类别划分较细致,而在移动服务平台中,类别的划分较粗糙一般只有一个层次,因此,利用类别的方式来计算移动服务之间的相似度是不适合的。另外的学者考虑从项目的属性方面来分析项目相似性。其中部分文献使用项目评分来计算项目相似度,如文献[7]通过将(项目的评分次数)/(项目所属类型中所有项目被评分的总次数)得到项目之间的兴趣度特征向量,再代入绝对指数相似性计算公式,计算2个项目之间的兴趣度相似性。然后将其与传统的用户相似度计算公式相结合。但是通常用户对项目的评分矩阵稀疏,少量的评分数据不能准确的体现出项目之间的相似度。这种情况在移动服务方面表现的特别明显,例如安卓市场平台中的“微信”评分次数(2016/10/30统计)。文献[9-10]构建项目与常注标签的关联矩阵,得到项目的标签特征向量,通过余弦相似度方法计算不同物品之间的标签向量的相似程度,从而描述不同物品之间的相似度。但是很多的移动服务平台中并没有标注服务的标签,因此,这种方法也不适用于移动服务的相似度计算中。综上所述,由于移动服务存在分类较粗、相关属性缺失等特点,现有的项目相似度计算方法不适用于移动服务方面。
服务介绍是发布服务时必不可少的一个项目,其说明了该服务的功能和作用。例如安卓市场中“我爱作文大全(1.0)”的介绍:“作文大全是一款旨在帮助学生更好的学习如何写作的应用软件,我们收录了近年高考满分作文,高中优秀作文,中考满分作文、初中优秀作文供学生鉴赏,还给喜欢写作的同学们提供了大量的素材,以便学生们能写出更加优秀的作文出来。适用于小学,初中,高中学生参考,再也不用花钱买纸质作文材料了。”相似的服务其提供的功能和作用也应该是相似的,这就体现在不同服务的介绍内容也应该是相似的。因此本文通过分析服务介绍内容之间的相似度来度量服务之间的相似度。服务介绍通常是较短的一段文字或几句话,因此传统的针对长文本的文本相似度度量方法不适用于此种情况。针对短文本相似度的计算方法现有研究主要分为:
1)基于词典的方法[11-12],其通常的做法是将短文本分解成多个词,然后去掉无用的停用词,再基于语义词典计算词与词之间的语义相似度,最后将词与词的语义相似度综合起来得到文本与文本的语义相似度。
2)基于大规模文本集进行统计的方法,如具有代表型的潜在语义分析法(Latent Semantic Analysis,LSA),LSA能够找出词与词之间的潜在联系,获取词在文本上下文中的一些知识。
3)基于描述特征的方法[13],该类方法的核心在于选择合适的特征值来表示文本,如文献[13]从问题短文本中抽取实词作为最初特征集,通过熵表示特征词权重,再通过聚类的方式得到最后的特征集。
4)借助互联网资源的方法[14-15],该类方法通过借助互联网上的资源如wiki百科、百度百科、搜索引擎等来分析文本相似性。例如2个词通过搜索引擎查找后返回的网页数量,或通过2个词在百科中的链接情况。在这些方法中,基于词典的方法是目前运用最为广泛且十分有效的方法。
2 改进的移动用户近似邻居集选取方法
本节首先分析了基于服务介绍属性的相似度计算方法,然后将得到的服务相似度纳入到用户相似度计算中,给出了一个用户相似度计算方法。根据计算出的用户相似度,本文提出了一个分步筛选近似邻居集的方法。
2.1 服务相似度计算方法
文献[13]提出了一种结合统计相似度和语义相似度的方法来计算答案之间的相似度,这种方法既结合了传统的基于统计计算相似度方法的优点,又考虑了短文本自身的特性,更全面衡量了答案的相似度。但该方法在处理关键词数量较多的短文本环境下存在一些不足,主要体现在2个方面:
1)在统计相似度计算中对所有关键词赋予一样的权重,未考虑关键词对短文本的重要度。现有研究表明短文本中出现次数较多的关键词在相似度计算中应具有较高的权重。例如在上述“我爱作文大全(1.0)”服务中提取的关键词“作文”。
2)文献[13]提出的双向语义相似度计算方法未考虑服务之间关键词数量相差较大的情况,使得计算结果偏向关键词越少的服务,从而使结果产生偏差。比如在“影音”类别下新增一个服务S,其简介内容非常短,最后提取的关键词集合为{节目,电影,播放,视频}。这些关键词在影音类别下是非常常见的关键词,最后结果会发现服务S与影音类别下的其他服务之间都会具有较高的相似度,这明显是不合理的。
本文利用“安卓市场”中的数据进行实验也表明了这一点,如关键词数量相差较大而功能不同的2个服务3245(和讯基金)和4391(手机无线管理)的语义相似度计算结果为0.818 153。服务的介绍内容越详细,表示对该服务的功能描述越全面,其在语义相似度计算中应给于更高的重视。
本文提出一种改进的移动服务融合相似度计算方法(Comprehensive Mobile Services Similarity Calculation Method,CMSSCM)。其具体过程如下:
步骤1将服务介绍进行分词,提取出能够表现出服务功能和作用的关键词集。
本文采用曾获得多项奖项,具有微博分词、新词发现等功能的NLPIR汉语分词系统(又名ICTCLAS2013)对服务介绍进行中文分词及词性标注。分词后得到的词语集合中更关注的是能够体现出服务功能和作用的关键词。通过对服务介绍和已有关键词研究工作分析,发现关键词一般是以名词为主的具有实际意义的词语。所以,将得到的词语集合中的介词、助词、代词、动词等过滤掉。最后得到服务介绍的关键词集合:
NS_Ni={NAi1(n1),NAi2(n2),…,NAim(nm)}
其中,NA代表关键词,nm代表关键词出现的次数。
步骤2基于余弦相似度方法计算服务之间的统计相似度SIMstatistic。
首先根据服务介绍的关键词集合构建服务的特征向量。假设有服务I和J,其关键词集合分别为NS_Ni和NS_NJ。其合集为NS_NIJ=NS_Ni∪NS_NJ。服务I和J的特征向量VI和VJ基于NS_NIJ来构建,其中向量的维度等于合集中词的个数,每一维对应合集中的一个词。如果一个关键词在短文本中出现次数较多,则更能体现出短文本的主题,如上述服务“我爱作文大全(1.0)”中的“作文”关键词。将向量中对应的分量的值等于该词在服务介绍中出现的次数,如果没有出现过则等于0。
例如2个服务关键词集合NS_Ni={高考作文(2),作文(3),应用软件(1),小学(1),高中(1)}和NS_Nj={作文(3),记叙文(1),应用文(2)},则NS_NIJ={高考作文,作文,应用软件,小学,高中,记叙文,应用文}。因此,这2个服务特征向量的维度为7,它们的向量分别为:
Vi={2,3,1,1,1,0,0}
Vj={0,3,0,0,0,1,2}
然后,基于2个向量Vi和Vj用余弦相似度计算它们的统计相似度:
(1)
步骤3基于语义词典计算2个服务的语义相似度SIMsemantic。
知网(HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。本文选择知网作为语义词典,利用文献[16]算法计算词汇间的相似度scm。本文认为一个服务的介绍内容越详细,提取的关键词数量越多,表明对该服务的功能描述越全面,因此,在语义相似度计算中应给予更高的重视。基于此,本文提出了改进的语义相似度计算方法如下:
(2)

步骤4将统计相似度和语义相似度结合,计算整体相似度。其定义如下:
SIMall(i,j)= (1-β)SIMstatistic(i,j)+
βSIMsematic(i,j)
(3)
其中,β是介于0与1之间的参数,它决定语义相似度对整体相似度的贡献。
2.2 改进的移动用户相似度计算方法
有学者认为一个用户对其他非共同评价物品的评价数目不应该影响到两者之间的相似度,从而提出了一种非对称相似系数,其计算公式如下:
(4)
上述公式忽略了服务之间的相似性,从而无法发现具有相似兴趣的用户。假设有用户A和B,A下载的服务集{手机铃声大全,摩安卫士标准版,3D开奖结果};B下载的服务集{免费手机铃声大全,江民手机安全管家,福彩3D};利用式(4)求出的相似度结果为0,从例子中可以看出虽然A和B下载的相同服务集为空,但是他们具有相似的兴趣。基于此,将上述提出的服务相似度方法CMSSCM考虑到移动用户的相似度计算中,提出移动用户有向相似度计算方法(Mobile User DirectionalSimilarity Calculation Method,MUDSCM),其公式为:
(5)

2.3 邻居集筛选方法
在传统的近似邻居集选取方法中,一般会采取设定阈值或固定邻居大小,或两者结合的方法进行选取。但这2种方法无法解决冷启动等问题。当一个新用户进入平台后,由于其刚开始下载的服务数量较少,利用本文的方法会产生大量具有强相似度的近似用户,因此有必要对近似邻居进一步的筛选。筛选的思路是认为目标用户会有很大概率跟随大部分近似用户的兴趣方向。因此,本文通过对近似邻居集进行聚类,找出大部分用户所在的分类,认为该类代表了目标用户最可能感兴趣的方向,该类下的用户相比于其他类而言更适合作为目标用户的近似邻居。
AP(Affinity Propagation)聚类是2007年在Science杂志上提出的一种新的聚类算法。本文选择AP聚类算法作为筛选用户近似邻居的原因主要有2个:第1个是AP聚类支持不对称的相似度;第2个是AP算法不需要事先指定聚类数目。
基于以上思路,本文提出了一种分步筛选近似邻居的方法。具体步骤如下:
步骤1通过指定用户相似度阈值SUMw,将与目标用户相似度高于阈值的用户加入待选集D1;如果D1小于或等于指定邻居集大小K,则筛选结束;返回D1作为最终近似邻居集;否则进入下一步。
步骤2指定服务相似度阈值SIMw,将D1中的用户与目标用户利用式(5)重新计算相似度。在重新计算过程中如果2个服务的相似度小于阈值SIMw,则将其置为0。重新计算后的相似度将降低,再根据第一步的方法进行筛选得到待选集D2。
步骤3设定Preference、阻尼因子和迭代次数,利用AP方法对D2集进行聚类,找出聚类用户数最多的类别,将该类别中的近似邻居以相似度降序排列,筛选出K个作为最终的近似邻居集。
3 实验结果与分析
3.1 实验数据集与评估标准
本文选取2类数据集作为实验数据,并将结果与传统的方法进行对比,以验证本文提出方法的有效性。具体如下:
1)服务相似度计算方法度量。为了验证本文提出的结合统计相似度和语义相似度的综合服务相似度计算方法(Comprehensive Mobile Services Similarity Calculation Method,CMSSCM),通过爬虫程序获取安卓市场应用(http://apk.hiapk.com/apps) 18个类别下共8 242个服务作为实验数据集。将8 242个服务介绍进行分词过滤得到服务关键词集。分别利用关键词重叠法(Keywords Overlapping Method,KOM)、余弦法(Cosine Similarity method,CSM)和本文的CMSSCM方法计算服务相似度并进行对比分析。
2)用户相似度计算方法度量。由于服务平台的真实用户日志记录很难获取,因此现有的研究普遍通过模拟数据的方式作为实验数据集。如文献[10]通过自己设定的3个规则,模拟“Mobile Market”平台的用户日志信息。本文通过随机对西南政法大学的学生做调查问卷,最终获取了417名学生使用手机APP的数据,将其作为实验数据。将Jaccard方法、本文提出的用户有向相似度计算方法(Mobile User Directional Similarity Calculation Method,MUDSCM)以及式(5)变形如式(6)的方法(MUDSCM-B)进行结果对比分析,验证其有效性。
(6)
3)分步筛选用户近似邻居集方法。在用户数据集中模拟一个刚进入的下载服务数较少的用户,通过VB+SQL对其近似邻居集实现AP聚类。在聚类过程中取不同的Preference和阻尼因子参数,分析聚类结果,筛选出用户最终的近似邻居集。
3.2 结果分析
结果分析具体如下:
1)服务相似度中β参数的选取
在服务相似度计算式(3)中,语义相似度在整个相似度中所占的比例是一个介于0~1之间的参数。由于语义相似度运算量非常大,因此本文只选取影音类别下的488个服务进行实验。分别选取β值为0.9、0.8、0.7、0.6、0.5、0.4、0.3、0.2,计算得到每个服务在本类中最相似的服务ID及相似度值。
通过结果分析,发现如果β值取值过高,会夸大服务之间的相似度,使结果产生偏差。例如当计算“蜻蜓FM”服务,β为0.9和0.8时,跟它相似度最大的服务为“DJ舞曲大全”,而其他β值计算出的相似度最高的服务为“悦听FM-广播电台收音机”,因此,选择合适的β值对于服务相似度的计算至关重要。本文通过计算β取不同值时的服务匹配比例来选取β值,其结果如图1所示。

图1 β取不同值时的匹配情况
实验结果表明,当β=0.6时,匹配比例最大。这符合现有的研究成果,即认为语义信息比统计信息更重要,β值应大于0.5。
2)服务相似度计算结果分析
图2列出了关键词重叠法(Keywords Overlapping Method,KOM)、余弦法(Cosine Similarity Method,CSM)和本文的CMSSCM方法在TopN条数据下服务相似度平均值的对比结果。

图2 在TopN条数据下服务相似度平均值对比
为了度量3种方法的准确度,本文首先根据服务的主要功能对服务进行手工标注,标注类型说明如表1所示。

表1 6种服务类型标注说明
如果目标服务找到的具有最大相似度的服务也有同样类型的标注,即认为是正确的。利用KOM、CSM和CMSSCM方法进行实验,其结果如图3所示。其中,线上数字表示相似度。
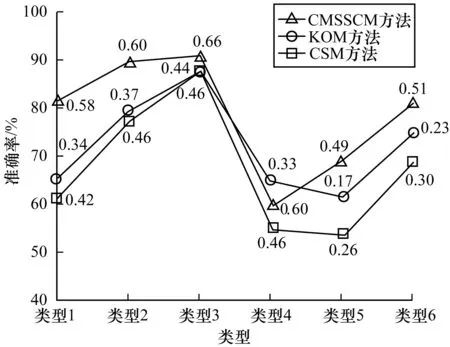
图3 在各标注类型下的准确率和服务相似度平均值
实验结果表明,CMSSCM方法只在标注类型4中准确率低于KOM方法,其原因是在于该类型下的某些服务在其服务介绍中过于突出细节方面的功能而忽略了服务的主要关键特征,使得CMSSCM方法在匹配时倾向于寻找跟其细节更相似的服务,从而使结果产生偏差。整体而言,CMSSCM方法相比于KOM和CSM方法,具有更好的准确度和相似度值。
3)用户相似度结果分析
将用户实验数据做前期处理后,得到了3种用户相似度计算方法得到的相似度区间分布,如图4所示。

图4 用户相似度区间分布情况
通过对实验数据的人工对比分析,发现大部分学生都具有较相似的兴趣。例如都下载了英语学习、词典、课程表、音乐、车票、电影等方面的APP。但是利用Jaccard方法计算的用户相似度普遍分布在[0.1,0.3],MUDSCM-B方法普遍分布在[0.2,0.4]区间,都未能体现出学生之间的强相似性;而本文提出的MUDSCM方法则体现了这一点。
表2列出了编号UUID=14的目标用户分别按3种方法求取的前3名相似度最高的用户及相似度,其中,UUID=14的目标用户的服务ID集合为{2007,2006,4741,4440,1032,2023,4448,1034,4659}。

表2 Jaccard、MUDSCM-B和MUDSCM方法下3名相似度最高的用户及其相似度
在表2中,括号里的数字代表相似度排名,括号外的值表示具体的相似度值,如0.93(2)代表使用MUDSCM方法求出的与目标用户相似度最大2的用户为UUID=33,其相似度值为0.93。从结果中可以看出,Jaccard和MUDSCM-B方法优先选择跟目标用户相似且服务数量较少的用户作为相似用户,而服务数量较大的用户将被筛除掉。MUDSCM方法则忽略服务数量因素,只从跟目标用户使用服务最相似的角度的来选择近似邻居。因此,利用MUDSCM方法选择的相似用户结果会囊括Jaccard和MUDSCM-B方法。从表2结果也可以看出,Jaccard和MUDSCM-B前3位的用户在MUDSCM方法中的相似度也较高,排名也较靠前。虽然这会导致其结果中具有大量强相似度的用户,但是从推荐系统的角度出发,这种方法(MUDSCM)更有效。
4)分步筛选近似邻居集实验结果分析
使用MUDSCM方法会产生大量具有强相似度的用户集,因此,需要对其进行筛选以得到最后的近似邻居集。为了验证本文提出的分步筛选近似邻居集方法的有效性,模拟了一个刚进入平台的用户UUID=5,其服务ID集合为{2006,2007,3000,4448,5907,3477};选取用户相似度阈值SUMw=0.6、指定邻居集大小K=10、服务相似度阈值SIMw=0.4,通过前2步筛选后的相似用户数量还有59个。
第3步通过AP聚类算法,分别选取Preference={中值,最小值,最大值,平均值},阻尼因子lam=0.5对这59个用户进行聚类。结果显示,当Preference取最小值0.6时,聚集的最大类的中心点在UUID=51用户处,其比例为22%,高于中值(20.3%)、最大值(3.3%)和平均值(13.6%)。因此,将该类下的用户按照与目标用户UUID=5的相似度降序排列选出TopK个用户作为目标用户的最终近似邻居集。
4 结束语
本文通过对移动服务的介绍,进行短文本相似度计算分析,从而度量移动服务之间的相似度,从推荐的角度出发,将服务相似度纳入到移动用户的相似度计算中,提出一种有向相似度计算方法。基于移动用户的兴趣,忽略平台中新旧用户对相似度的影响,有效地发现用户之间的真实相似性。针对冷启动所导致的强相似用户数量过大问题,给出一种分步筛选近似邻居集的方法。然而,在服务介绍中,如果出现对服务的描述不准确、侧重于细节方面的描述、出现一些新兴词语等情况,会使得计算结果出现偏差,因此,下一步将针对这些问题展开研究。
[1] FENG Yuanyuan,AGOSTO D E.Overwhelmed by smartphones a qualitative investigation into mobile information overload[J].Proceedings of the American Society for Information Science & Technology,2014,51(1):1-2.
[2] CHIU P H,KAO Y M,LO C C.Personalized blog content recommender system for mobile phone users[J].International Journal of Human-Computer Studies,2010,68(8):496-507.
[3] 孟祥武,胡 勋,王立才,等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[4] 李杰亮.基于数据挖掘技术的移动用户手机推荐系统[D].南京:南京大学,2014.
[5] WANG Y,WU J,WU Z,et al.Popular items or niche items:flexible recommendation using cosine patterns[C]//Proceedings of IEEE International Conference on Data Mining Workshop.Washington D.C.,USA:IEEE Press,2015:205-212.
[6] LU Meilian,QIN Zhen,CAOYiming,et al.Scalable news recommendation using multi-dimensional similarity and jaccard-kmeans clustering[J].Journal of Systems & Software,2014,95(9):242-251.
[7] 李 聪,梁昌勇,董 珂.基于项目类别相似性的协同过滤推荐算法[J].合肥工业大学学报(自然科学版),2008,31(3):360-363.
[8] 李小慧.基于Jaccard项目类别相似性的个性化推荐算法研究[D].长沙:中南大学,2010.
[9] 窦羚源,王新华,孙 克.融合标签特征和时间上下文的协同过滤推荐算法[J].小型微型计算机系统,2016,37(1):48-52.
[10] 王洪明.基于本体和标签的用户偏好提取系统的设计与实现[D].北京:北京邮电大学,2011.
[11] 翟延冬,王康平,张东娜,等.一种基于WordNet的短文本语义相似性算法[J].电子学报,2012,40(3):617-620.
[12] 张 科.基于《知网》义原空间的文本相似度计算研究与实现[D].重庆:重庆大学,2013.
[13] 宋万鹏.短文本相似度计算在用户交互式问答系统中的应用[D].合肥:中国科学技术大学,2010.
[14] SHIRAKAWAM,NAKAYAMA K,HARA T,et al.Wikipedia-based semantic similarity measurements for noisy short texts using extended naive Bayes[J].IEEE Transactions on Emerging Topics in Computing,2015,3(2):1.
[15] MARTINEZ G J.An overview of textual semantic similarity measures based on web intelligence[J].Artificial Intelligence Review,2014,42(4):935-943.
[16] 王小林,王 东,杨思春,等.基于《知网》的词语语义相似度算法[J].计算机工程,2014,40(12):177-181.
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
河北画报(2020年8期)2020-10-27 02:54:20
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
导航定位与授时(2014年2期)2014-04-27 13:41:09
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
