
基于多核ARM体系结构的基础函数优化方法
2018-05-30 01:26:13贺爱香顾乃杰苏俊杰
计算机工程 2018年5期
贺爱香,顾乃杰,苏俊杰
(1.中国科学技术大学 计算机科学与技术学院,合肥 230027; 2.安徽新华学院 信息工程学院,合肥 230088)
0 概述
随着嵌入式系统的发展,多核ARM微处理器[1]因其体积小、功耗低、成本低、性能高等特点很快占领了移动通信市场领域。Android[2]是运行于ARM架构处理器之上的一款开源操作系统软件,据市场研究公司Gartner 2016年上半年最新统计数据显示,Android市场占有率为近九成[3]。Bionic[4]是Android系统中以C语言构建的基础函数库,为系统提供系统接口和扩展功能函数。在处理器的性能得到提高的情况下,程序充分利用处理器的性能,不但可以减少计算资源的浪费,还可以提高程序的响应速度,因此对Bionic库基础函数进行优化对提升ARM平台性能与用户体验有很大作用[5]。针对ARM体系结构进行优化是非常重要的工作,很多学者和研究人员利用各种优化方法积极探索该问题。为了高效合理地使用寄存器和存储器,提高程序的执行效率,文献[6]对ARM体系结构提出了减小汉明距离、使用位操作指令、正确选择流程控制语句和压缩代码密度等优化方法。文献[7]基于ARM嵌入式系统充分利用软硬件资源,提出了循环展开、避免使用除法、利用条件执行等C程序优化方法。文献[8]使用128位访存指令、循环展开等方法,结合龙芯3A处理器将BLAS库性能提高了6倍。文献[9]对Bionic库中的热点函数进行了汇编优化,使得Android系统整体性能得到了提升。
基于以上研究,本文在对Bionic库中字符串和内存处理函数进行分析的同时,结合多核ARMv8体系结构特征[10],提出不同的优化方案,包括整字处理[11]、循环展开[12]、特殊指令[13]等优化方法,使得Bionic库中常用基础函数的性能在ARM Cortex-A72平台上有不同程度的提升。
1 背景知识
1.1 ARM体系结构
ARM是一类微处理器的统称[14],基于ARM内核的芯片统称为ARM芯片。ARM体系结构采用精简指令集,具有定长指令、大量的寄存器、独特的装载/保存(Load/Store)等特点[15]。ARM公司从1991年推出ARM1处理器到现在,其体系结构已经从ARMv1发展到现在的ARMv8,每一个体系架构版本都定义了一套指令集和相应的功能框架,并且每个结构体系向后兼容,图1为ARMv5至ARMv8的架构比较[16]。基于ARMv8的体系结构产品不仅主导了移动通信领域,而且在无人机控制系统[17]、汽车导航[18]、智能家居[19]等智能硬件控制系统中应用广泛,本文是基于ARMv8最新架构的研究。

图1 ARMv5至ARMv8架构比较
ARMv8提供一种更加清晰的架构,同时考虑到将来的发展趋势采用一种全新的架构来实现,是目前最新的架构[20]。ARMv8-A系列面向尖端的基于虚拟内存的操作系统和用户应用。ARMv8的架构继承以往ARMv7与之前处理器技术的基础,除了支持现有的16 bit/32 bit的Thumb2指令集外,也向前兼容现有的A32(ARM 32 bit)指令集和NEON指令集,并扩充了现有的A32(ARM 32 bit)和T32(Thumb2 32 bit)指令集。ARMv8采用基于64 bit的AArch64架构,新增了A64(ARM 64 bit)指令集,解决了ARMv7架构遗留的虚拟地址问题,定义了AArch64和AArch32两套运行环境(称作Execution state),分别执行64 bit和32 bit指令集,软件可以在需要的时候,切换Execution state。AArch64架构使用新的概念(exception level),重新解释了processor mode、privilege level等概念。在ARMv7安全扩展的基础上,新增了CRYPTO(加密)模块,支持安全相关的应用需求[21]。在ARMv7虚拟化扩展的基础上,提供完整的虚拟化框架,从硬件上支持虚拟化[22]。其架构框图如图2所示。
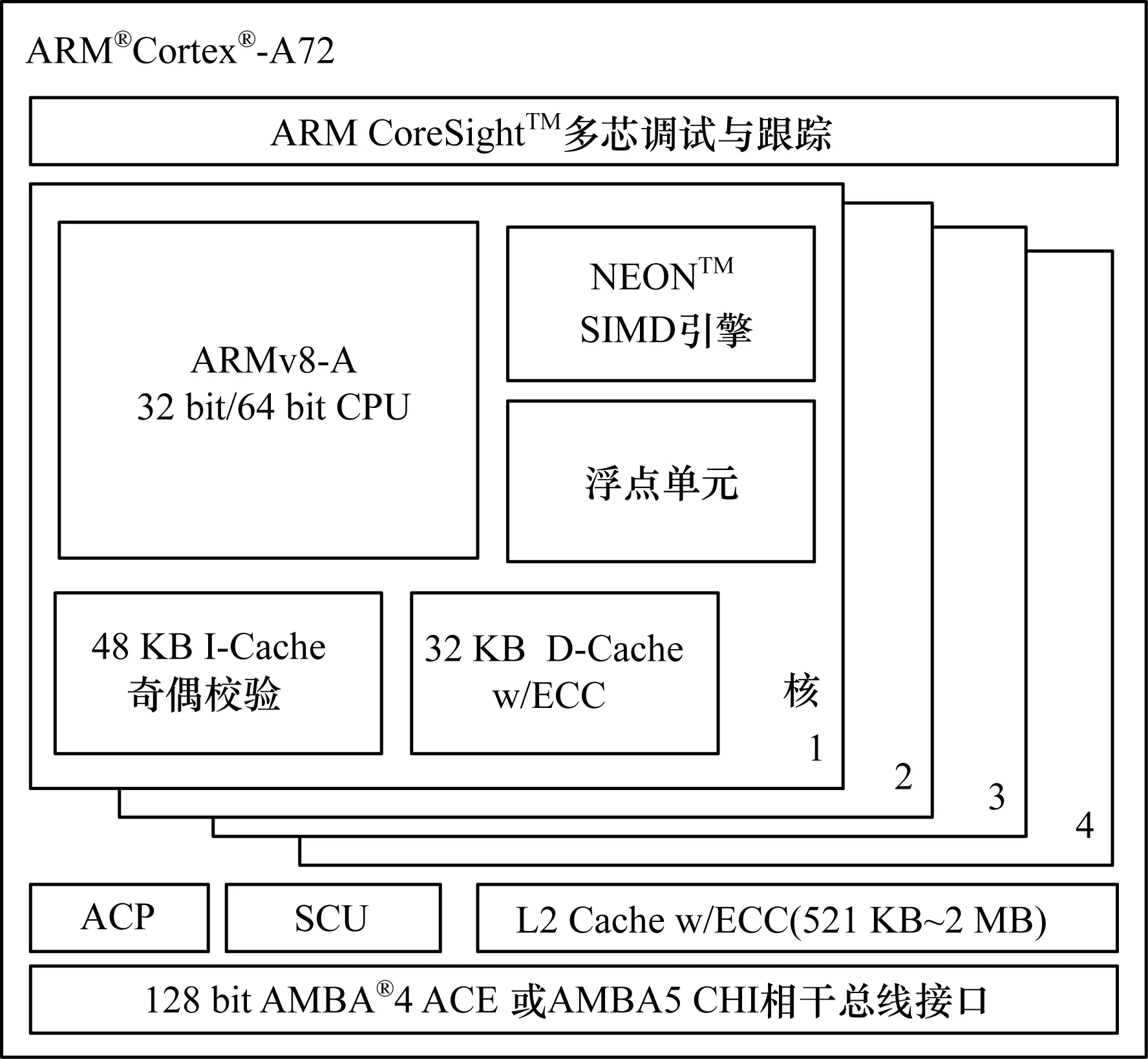
图2 ARM Cortex-A72处理器架构
1.2 NEON技术
现代计算机2个大主流体系结构为X86和ARM,为了高效利用硬件资源,均支持单指令多数据流 (Single Instruction Multiple Datastream,SIMD)技术[23]。NEON是ARM Cortex-A系列处理器新增的一个运算部件,使得每次运算可达到128位,扩展了SIMD,能更快速地处理多媒体数据,使用户体验更流畅[24]。NEON具有128位宽的运算部件,可减少对内存的访问,从而提高数据处理速度。
NEON指令可批处理SIMD;通过对齐和非对齐数据访问,寄存器被视为同一数据类型的元素的矢量;数据类型可为8 位、16 位、32 位、64位有/无符号整型、32位单精度和64位双精度浮点型;指令在所有通道中执行同一操作。如图3所示,显示了UADD16 Q0,Q1,Q2指令操作,实现了对寄存器Q1和Q2中8路16 bit的并行相加,并将最后结果保存到R0中。

图3 8路16 bit整数加法运算
1.3 Bionic
Bionic是Google公司专为Android系统开发的基础函数库,提供C/C++标准库功能。GNU/Linux以及其他类Unix系统的基础函数库最常用的就是Glibc。与Glibc相比,Bionic是轻量级C库,大小仅为200 KB,是Glibc体积的一半,这意味着Bionic占用低内存[25]。
Bionic库中包含字符串与内存处理函数、数学计算函数、排序与查找、字符串加密等基础工具型函数。本文通过大量实验,着重优化Bionic 库中的memset、strcmp、strncmp、strcpy、strncpy、memcpy、memmove、strlen、strcat、strdup等函数。
2 函数优化
针对多核ARMv8体系结构,考虑使用整字处理(合并字节)、特殊指令、循环展开、指令调度等方法进行优化。本节将探讨如何使用这些优化技术,来实现Bionic库中热点函数的优化。
2.1 函数介绍
在Bionic库函数中,字符串是通过一段连续的内存来表示,所以字符串的操作与内存操作基本一致。两者的区别在于字符串是用空字符’�’来表示结尾的,而内存块结尾由其给出大小决定。根据函数的不同功能,可以将字符串和内存处理函数分为以下7类,并选取代表性的热点函数进行优化。
1)求字符串长度的函数有strlen、strnlen。
2)内存拷贝与赋值函数有memcpy、menpcpy、memmove、memccpy、memset等。
3)字符串拷贝与连接函数有strcpy、strncpy、strdup、strndup、stpcpy、stpncpy、strcat、strncat等。
4)字符串与内存比较函数有memcmp、strcmp、strncmp等。
5)字符串与内存查找函数有memchr、memrchr、strchr、strrchr、strstr、strcasestr、memmem、strspn等。
6)字符串分割函数有strtok等。
7)字符串变换函数有strfry等。
2.2 整字处理
整字处理是一种简单的合并操作,即将多个字节合并在一起进行处理。通过分析字符串与内存处理函数得出,大部分函数的行为都是从1个或2个内存地址开始读取内存并进行相应的操作。改变原始单个字节的遍历方式,合并字节,以4 Byte或8 Byte或者16 Byte为单位进行处理。
而在32位的ARM Cortex-A7平台上可以4 Byte合并处理。如测量字符串长度strlen函数,原始函数需要从内存逐字节取数到寄存器进行计算,使用整字处理可以将4 Byte看成一个单元计算。即先按整字判断,当指针已经是4 Byte对齐的位置时,每次读4个字节一起比较,直到最后一次4 Byte的判断,其中必有一个字节为’�’。所以这个串尾的判断是关键。
对于所有整字节优化处理时的串尾判断,都可以考虑使用DEF(X)判断其中是否含’�’。如果没有,继续循环读取,如果发现了读进来的字符有’�’,则将字节数合并或按单字节比较找到第一个出现’�’的位置,然后计算完毕并且返回。对于4 Byte、32位的情况,可定义DEF(X)为(((X)-0X01010101)&~(X)& 0X80808080),其中,X代表4 Byte合并的数据,0X01010101和0X80808080为在4 Byte情况下的2个常量,每个字节的最高位和最低位分别设置为1。如果DEF(X)不为0,则说明X中含有一个值为0的字节。在Bionic库中的求字符串长度函数、内存拷贝与赋值函数、字符串拷贝与连接函数、字符串与内存比较函数均可采用该方法进行优化。以strlen函数为代表的优化流程设计如图4所示。

图4 strlen函数的优化算法流程
2.3 循环展开
循环展开是一种通过复制循环体中的指令,达到扩大循环体、减少循环重复次数的优化方法。通过减少循环变量的计算、比较次数和跳转指令的执行次数来提高代码性能。循环变量的计算和比较都需要一定的执行时间,并且在ARM上跳转指令会打断流水线的正常运转,是执行周期较长的指令。一般情况下对循环体较短的循环进行展开可以有效地减少循环的各种开销,提升程序代码效率。
循环展开除了能降低循环开销以外,更重要的作用在于展开后可以对变量进行重命名以减少数据相关和对基本块进行指令调度。如图5所示,图5(a)是原来的循环,对其直接展开4次可得到图5(b);图5(b)中的变量S会引起数据相关,依次对每一条语句中的S变量进行重命名得到图5(c),有效地减小了数据相关;在ARM体系结构中,所有的操作都需要在寄存器中完成,所以图5(c)中的每条语句事实上需要2条指令完成,先是将数组中的值取到寄存器中,然后进行累加运算,而这两步本身也存在写后读相关,所以增加中间变量并对其进行指令调度得到图5(d),取数指令和运算指令之间存在一定的时间间隔,有效地减少了数据相关带来的延迟。

图5 循环展开示意图
循环展开作为程序优化技术已非常成熟,常用的编译器都会支持这个功能。其直接作用是减少循环控制指令的开销,多层循环的外层循环展开还可以减少访存操作次数。但其缺点就是会导致代码膨胀,增加Cache的压力、寄存器使用的冲突、边界处理代码和控制开销。由于ARM Cortex-A72的一级Cache容量高达64 KB,二级Cache容量为2 MB,一般热点代码都比较短,因此代码膨胀对其影响不大。在特定平台上需要解决的关键问题是循环展开因子的选择,一般的准则是循环内定点和浮点变量的数量都不要超过寄存器的总量。
令ARM处理寄存器数为R,循环展开k次后循环体所需要的寄存器数目为P(k),则为了避免寄存器冲突,最优循环展开因子为:
max{k},P(k)≤R,k∈Z
(1)
ARM Cortex-A72处理器有31个64位长的通用寄存器,即R=31。以图5代码为例,当4次展开时并且采用变量重命名和指令调度,循环体每次迭代时需要8个寄存器,展开k次则需要P(k)=2k个寄存器,由式(1)可知2k≤31,则k≤15,计算得到循环展开因子取15为最佳因子。但在实际应用中,为了保证寄存器不冲突,对于不同平台,最优的展开因子需要通过实验搜索比k略小的值来获得。
Binoic库中的内存拷贝与赋值函数memcpy、 memset,字符串拷贝与连接函数strncpy、strncat,字符串与内存比较函数strcmp、memcmp,函数的实现循环体短导致指令跳转的次数多,流水中断次数多,指令流水线的加速优势得不到充分利用。采用循环展开的方法可以减少指令跳转的次数,从而提升流水性能。
对任意循环都可采用循环展开以提升性能,但循环展开也会导致代码膨胀、增加寄存器压力等副作用。所以,针对不同循环问题如何选取循环展开因子,需结合体系结构实验,使程序性能最优。memset函数是访问密集型函数之一,以memset函数为代表利用循环展开并以4为因子直接展开的优化流程设计如图6所示。

图6 memset函数的优化算法流程
2.4 特殊指令
使用特殊指令是通过使用目标机器指令集中一些特殊的指令来提高程序的性能。ARM Cortex-A7采用了先进的NEON指令集技术,拥有多条128位访存指令。对数据的加载和存储分别使用vld1q和vst1q指令一次可以将128位数取到寄存器中,使用这些指令可以极大地提高取数和存储数的效率。在NEON中对齐与非对齐都使用vld1q和vst1q指令,但非对齐处理的周期要长。利用该指令分别对字符串和内存处理函数进行改写从而优化Bionic库。本文以memcpy函数为代表进行优化设计,流程图如图7所示,memcpy函数优化算法考虑dst地址与scr地址对齐的情况,分为dst与scr地址16 Byte对齐、dst与scr地址非对齐,但偏移值相等、dst与scr地址非对齐,且偏移值不等3种情况。
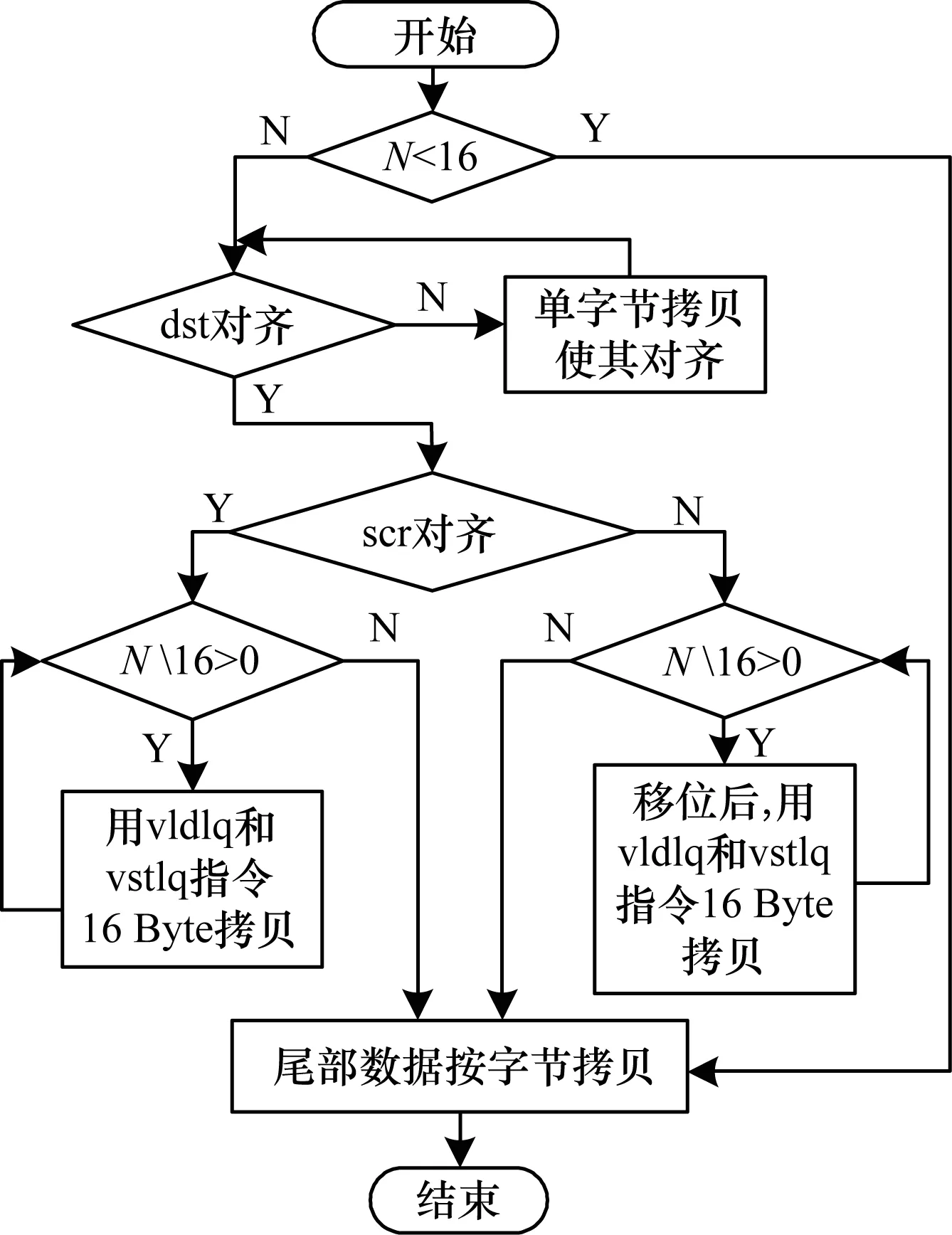
图7 strcpy函数的优化算法流程
3 实验结果分析
本文中实验采用ARM Cortex-A7双核处理器Android平台,取64 B到512 KB倍增的数据规模(size)进行测试,并对每个size运行十万次求平均,记录了原函数和优化后函数的运行时间,再计算出性能提升比。
在Bionic库中的字符串和内存处理函数均可采用整字处理方法优化,以strlen函数为代表采用整字处理,优化结果如表1所示。其在不同的数据规模下平均性能提升了37.96%。

表1 strlen函数优化性能比较
在多核ARM Cortex-A72处理器平台中,通过以memset函数为代表采用循环展开进行优化实验,在不同数据规模的情况下,分别将循环展开因子取1、2、3、4、5、6、7、8、9、10、11、12、16进行实验,计算平均性能比较结果如图8所示。展开因子在5以内,同时数据在L1-Cache中时,访存速度快,循环体的代码执行周期很少,这时性能提升比例几乎可以取得线性提升。memset函数展开时虽不增加对寄存器的消耗,展开因子超过5时,继续展开效果不明显,直到展开因子为8时性能达到最优,这是由于循环展开的副作用开始产生,导致整体性能开始波动,继续展开会引起其他不可控因素而使得性能下降。当展开因子取8时平均性能提升比为83.08%,如表2所示。

图8 循环展开效果

sizemy_memset1/μsmemset/μs性能提升比例/%64 Byte4012166.94128 Byte7321465.89256 Byte8045882.53512 Byte13288585.081 KB2511 83186.292 KB4883 54086.214 KB1 0387 14185.468 KB1 98414 40586.2316 KB3 81528 50386.6232 KB7 44657 19086.9864 KB14 801113 67886.98128 KB28 480228 05787.51512 KB57 961455 29287.27
以strcpy函数为代表利用特殊指令对Bionic库中所有字符串和内存函数进行优化,并考虑对齐、非对齐偏移相等和非对齐偏移不等3种情况,优化结果分别如表3~表5所示。strcpy函数源地址和目标地址均对齐时平均性能提升60.44%,非对齐偏移量相等时平均性能提升39.93%,非对齐偏移量不等时平均性能提升43.75%。

表3 strcpy函数对齐优化性能比较
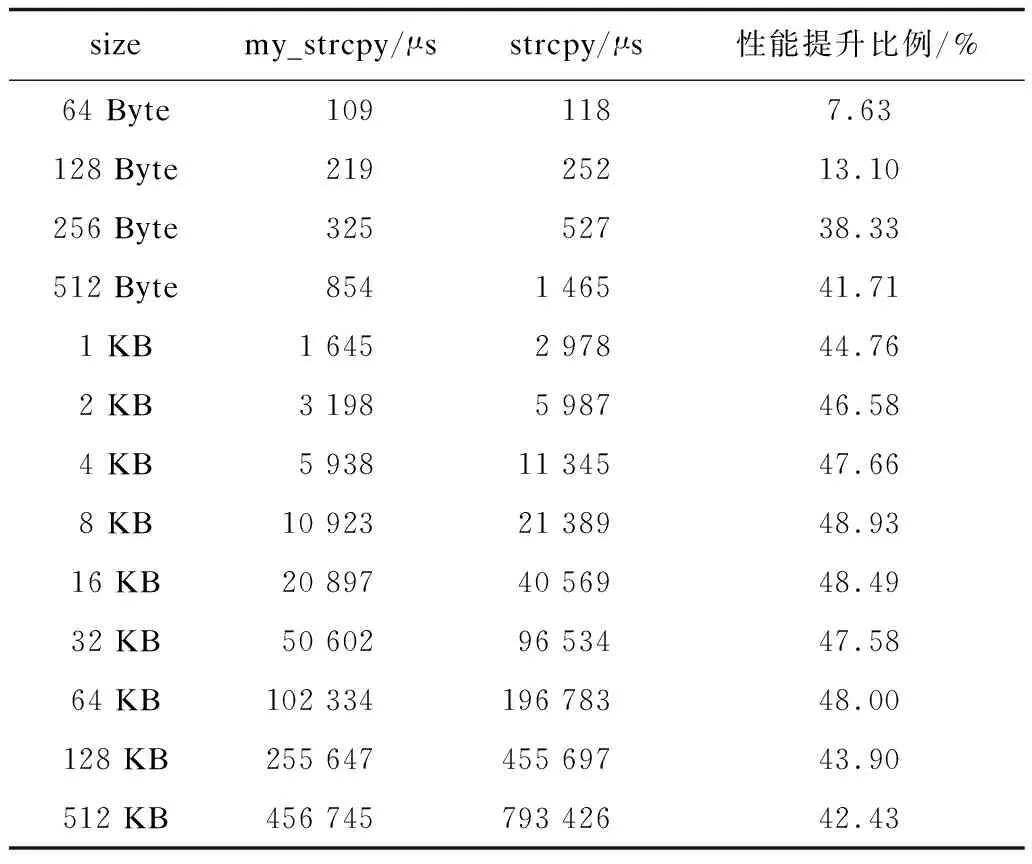
表4 strcpy函数非对齐偏移量相等优化性能比较

表5 strcpy函数非对齐偏移量不等优化性能比较
4 结束语
本文围绕Android系统底层Bionic库字符串和内存处理函数,结合ARM Cortex-A72处理器及其体系结构和指令集特点,通过使用整字处理、循环展开、NEON访存特殊指令等优化方法进行了程序级优化设计。实验结果表明,Bionic库中的字符串和内存处理函数在不同数据规模下平均性能均有提升,并通过大量实验找出了适合于该平台的memset函数最优循环展开因子为8。
下一步将进一步分析ARM Cortex-A72处理器性能及特点,深入研究软件流水[26]对循环展开的影响,找出每个函数的最优展开因子以及影响多层循环展开性能的主要因素。融合整字处理、循环展开、指令调度、数据预取[27]等优化方法,对Bionic库中字符串和内存处理函数、数学计算、查找与排序、加密等函数进行优化,实现高性能的Bionic库。
[1] 赵利军,王震宇,王奕森,等.基于ARMv8架构gadget自动搜索框架[J].计算机应用与软件,2016,33(5):307-311,316.
[2] 雒海东.基于ARM和Android的智能物联网药箱的设计[J].电子设计工程,2017,25(5):146-149.
[3] August.谷歌Android夺回IOS部分市场份额[EB/OL].[2017-05-18].http://mobile.yesky.com/463/104559463.html.
[4] 冯璐霞,李春江,黄亚斌.面向ARM64架构多核微处理器的模板计算性能优化研究[J].计算机工程与科学,2017,39(5):829-833.
[5] 叶炳发.Android操作系统移植及关键技术[D].广州:暨南大学,2010.
[6] 谢 川,贺玲玲.基于ARM处理器的软件优化设计[J].微计算机信息,2009,25(4):164-166.
[7] 金 丽,包志华,陈海进.基于ARM嵌入式系统的C程序优化设计方法[J].南通大学学报(自然科学版),2006,5(3):61-64.
[8] 顾乃杰,李 凯,陈国良.基于龙芯2F体系结构的BLAS库优化[J].中国科学技术大学学报,2008,38(7):854-859.
[9] 曹 越.面向Android系统库文件访存的汇编优化策略[J].测控技术,2016,35(1):113-117,126.
[10] 匿名.ARM授权博通ARMv7与ARMv8架构[J].单片机与嵌入式系统应用,2013,13(3):38.
[11] 罗红兵,张晓霞,王 伟,等.科学计算应用程序单核指令级优化研究[J].计算机研究与发展,2014,51(6):1263-1269.
[12] 何颂颂,顾乃杰,朱海涛,等.面向龙芯3A体系结构的BLAS库优化[J].小型微型计算机系统,2012,33(3):571-575.
[13] MISHRA A,AGARWAL M,RAJU K S.Hardware and software performance of image processing applications on reconfigurable systems[C]//Proceedings of Annual IEEE India Conference.Washington D.C.,USA:IEEE Press,2015:1-5.
[14] 周 余,都思丹.ARM11 MPCore性能分析与优化研究[J].南京大学学报(自然科学版),2009,45(1):5-10.
[15] NAKASHIMA S,NAITO T.Program optimization method,program optimization program,and program optimization apparatus:US 14/799,625[P].2015-07-15.
[16] 张俊卫,王 晶,张伟功,等.基于大数据的高能效数据中心服务器研究[J].计算机工程,2017,43(8):74-81.
[17] 辛海洋,彭 飞.一种基于ARM+FPGA的无人机地面测控系统设计与实现[J].电子世界,2017(15):129.
[18] 刘永刚.基于ARM的汽车导航系统设计[J].山东工业技术,2016(8):282.
[19] 任 瑾,龙小丽,张晓亚.基于ARM和ZigBee技术的智能家居系统的设计[J].自动化应用,2017(8):49-51,54.
[20] 杜 琦,姜 浩,李 宽,等.面向ARMv8 64位多核处理器QTRSM的实现[J].计算机工程与科学,2017,39(3):451-457.
[21] 刘 婧,王天成,王 健,等.基于指令模板的通用处理器约束随机指令生成方法[J].计算机工程,2015,41(10):309-313.
[22] HOFMANN J,FEY D,RIEDMANN M,et al.Performance analysis of the Kahan-enhanced scalar product on current multi-corecore and many-core processors[EB/OL].[2016-03-09].https://arxiv.org/abs/1505.02586.
[23] 董亚卓,常 歌.面向FPGA设计的类C语言及其关键技术研究[J].网络安全技术与应用,2017(8):50-52.
[24] 迟利华,刘 杰.基于安腾微处理器的程序性能优化与分析[J].计算机工程与科学,2011,33(9):42-47.
[25] 余超君.基于CK810的Android系统移植研究[D].杭州:浙江大学,2014.
[26] 张仁高,郑启龙,王向前,等.基于依赖环问题的改进软流水框架[J].计算机工程与应用,2017,53(17):65-69.
[27] 张 琦,陈玉荣,李建国,等.基于多核系统的视频特征提取程序并行化及性能优化方法[J].中国科学院研究生院学报,2011,28(4):531-547.
猜你喜欢
计算机应用(2020年5期)2020-06-07 07:06:44
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
系统工程与电子技术(2016年4期)2016-08-24 07:46:12
现代防御技术(2016年1期)2016-06-01 12:13:27
海军航空大学学报(2015年1期)2015-11-11 17:18:08
空间控制技术与应用(2015年4期)2015-06-05 12:22:40
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
