
一种面向轨迹信息的时序数据流异常检测算法
2018-05-30 01:36:34高嘉伟刘建敏
计算机工程 2018年5期
高嘉伟,刘建敏
(1.山西大学 计算机信息与技术学院,太原 030006;2.计算智能与中文信息处理教育部重点实验室,太原 030006)
0 概述
轨迹信息是一种时序数据流,具有无限性、快速性和无约束性等特点[1]。对轨迹信息进行有效分析,提取数据中的有效信息,及时发现异常轨迹,已成为目前学术界和工业界广泛关注的领域之一。
传统聚类算法无法对轨迹这类时序数据流进行聚类,为此,国内外学者关于时序聚类算法开展了研究并取得了一些成果。Aggarwal等人于2003年提出了一种时序数据流聚类算法——CluStream[2]。该算法通过在线和离线2个过程并利用金字塔时间框架对不同时间段内的数据进行聚类。由于该数据流聚类算法不能处理任意形状的簇,因此文献[3]提出D-stream聚类算法,其主要思想是将数据空间预先划分成一系列网格,通过将时序数据映射到相应网格,对网格处理得到聚类结果。
然而,D-stream聚类算法需要用户预先设置较多参数且精度较低。为此,许多学者基于该算法做了进一步改进。NDD-stream算法[3]通过计算网格单元的密度和簇的数目,动态地调整网格密度阈值,有效地避免了用户对密度阈值设置的主观性,但由于该算法仅对稠密网格及其边界的过渡网格或稀疏网格进行聚类,忽视了未处于稠密网格边界的过渡网格和稀疏网格。因此,从聚类结果来看,其聚类精度仍较低。文献[4]考虑到数据的时态特征和空间倾斜分布,定义了时态密度和自适应的密度阈值函数,使得更多的网格参与聚类,提高了算法的聚类精度,但该算法对网格进行了预先划分,由于划分参数的不确定性,使得所划分的网格不能很好地自适应当前数据,影响最终的聚类结果。文献[5]定义了样本分布的局部密度,利用类内密度有序性搜索聚类边界并通过圈定聚类边界来获取聚类结果,但该算法通过不断地改变搜索半径来处理数据分布疏密度不一的问题,增加了算法时间复杂度。此外,这些算法以及之后一些改进的算法[6-9],仅能获取当前时段内数据的聚类结果,而不能根据用户需求获取任意时段内数据的聚类结果。
综上所述,目前关于时序数据的密度聚类算法仍存在3类问题:关于解决数据分布疏密不一的方法有待改进;基于网格的聚类方法网格都被预先划分;未能有效地获取任意时段内数据的聚类结果。
此外关于轨迹异常检测方法已有很多,比如文献[10-11]提出对出租车异常轨迹检测的算法,其主要特征是按区域对轨迹划分,对区域内的所有个体的轨迹进行分析,但针对某一个体的轨迹,该算法并未给予有效的异常检测的方法。
本文从个体的轨迹为着眼点,针对以上3类问题对已有的时序数据流聚类算法进行改进,提出一种基于密度和网格的聚类算法,并将其应用于时序数据流异常检测。
1 基本概念
1.1 定义
定义1(数据单元) 数据单元即拥有d个属性值的数据,任意一个数据单元xi=(ai1,ai2,…,aid)[3]。
定义2(数据流) 数据流即按一定时间顺序到达的数据单元的集合,数据流X=(x1,x2,…,xi,…,xN)[12]。
1.2 密度网格
由于数据流具有无限性,如果对数据一一处理,时间复杂度较高。为此,可以通过将数据空间划分成多个子数据空间,先将数据映射到相应的某个数据子空间中,之后再对所有数据子空间进行处理,从而提高数据处理效率。
对于拥有d维属性的数据流,每个数据xi=(ai1,ai2,…,aid)都可存储到相应的d维数据空间S=S1×S2×…×Sd。
定义3(网格单元) 在数据空间S中,对任意一个网格gu,选取每一维的划分为Hgu j(1≤j≤d),则对于任意一个网格单元gu=Hgu 1×Hgu 2×…×Hgu d[3]。
定义4(网格群) 设数据块内所有数据单元形成了R个网格,则由这R个网格形成了一个网格群G=(g1,g2,…,gR)。
网格的位置由生成网格的数据单元所决定,网格之间可能会存在重叠的现象,因此,本文定义了邻近网格。
定义5(邻近网格) 对于网格群内任意2个网格go和gw,若go∩gw≠∅,go⊄gw且gw⊄go,则go与gw为邻近网格,表示为go~gw。
定义6(网格单元密度) 设任意一网格单元gu在时刻t,网格内数据的个数为ru,则此时网格的密度为[3]:
Dgu(t)=ru
(1)
即网格单元密度等于网格内数据的个数。
定义7(网格单元中心点) 对于任意一个网格gu,为其定义一个中心点foucusgu=(φgu1,φgu2,…,φguj,…,φgud)。其中,φguj表示gu网格的中心点在j维的属性值,其数值上等于网格内所有数据单元在该维属性上取值的均值,即:
(2)
其中,ru表示网格单元gu内数据单元的个数。
定义8(网格单元结构体) 网格单元结构体有3个变量和2个数组,用来存储该网格单元内数据的概要信息。当数据单元xi映射到某一网格时,更新该网格单元结构体。设某一时刻某一网格单元gu,其结构体表示为:
GSTRgu= {Dgu,lablegu,focusgu,
{min{azj}|1≤j≤ru,1≤z≤d},
{max{azj}|1≤j≤ru,1≤z≤d}}
(3)
其中,Dgu、lablegu、focusgu、{min{azj}|1≤j≤ru,1≤z≤d}、{max{azj}|1≤j≤ru,1≤z≤d}分别表示某一时刻网格单元gu的密度、类别、中心点与由该网格内数据在每一个属性上取值的最小值和最大值所构成的数组。
1.3 网格单元密度阈值
为解决数据分布密度不一的问题,本文引入了网格密度阈值,用于生成不同类型的网格。网格密度阈值参数的取值,对算法中格簇的形成以及聚类的结果有较大的影响。为此,本文定义了数据块,通过获取数据块内所有网格的特征信息,采用文献[1]提出的平均密度的思想,动态地确定网格单元密度阈值。
定义9(数据块) 数据块用于暂存某时间段内的数据单元,其长度为n(1≤n≤N)。
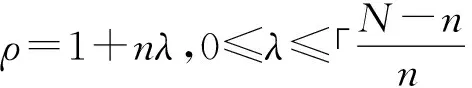
以数据块为数据处理单元,将数据块内所有的数据单元映射到网格中,设在某一时刻t由数据块内数据单元所形成的所有网格的平均密度为Davg(t),网格最小密度为Dmin(t),网格最大密度为Dmax(t):
(4)
其中,Dgu(t)表示t时刻第u个网格的密度,R表示该数据块内网格的数量。
稠密网格阈值为[1]:
(5)
稀疏网格阈值为[1]:
(6)
则在时刻t,对于任意一个网格单元gu,其密度为Dgu(t),有如下定义:
稠密网格:
Dgu(t)≥DGTh(t)
过渡网格:
SGTh(t) 稀疏网格: Dgu(t)≤SGTh(t) 由于本文采用网格划分数据空间的方法,将数据单元先映射到网格中,因此可以通过将有联系的网格聚在一起形成多个格簇,从而得到聚类结果。 为了确定各网格之间的联系,本文引用了图论中图的概念。对于一个网格群G=(g1,g2,…,gR),将网格群中的所有网格的中心点作为图中的顶点。若该网格群内的某2个网格邻近,则认为这2个网格具有一定的联系并为其对应的顶点赋予一条边,边的权重为网格中心点间的距离,从而形成了一个无向有权图。 定义10(格簇) 通过采用深度优先算法对所形成的无向有权图进行遍历并获取对应的连通分支,将该过程所产生的连通分支定义为格簇,连通分支的个数即为格簇的个数。 定义11(格簇关键点) 对于任意一个格簇kf,将格簇中密度最大网格的中心点定义为该格簇的关键点keypkf,keypkf=(φkf1,φkf2,…,φkfj,…,φkfd),其中φkfj表示格簇kf的第j个属性平均值。 定义12(稠密格簇、过渡格簇、稀疏格簇) 稠密格簇为由稠密网格所形成的连通图的点的集合;过渡格簇为由过渡网格所形成的连通图的点的集合;稀疏格簇为由稀疏网格所形成的连通图的点的集合。 定义13(格簇阈值) 格簇阈值即为该格簇可容纳其他格簇内数据点的最大邻域半径。对于不同类型的格簇,其阈值的定义也不同。设某一格簇kf,其关键点为keypkf且有v个网格,则该格簇内所有网格的中心点到该格簇关键点距离的最大值emax、平均值eavg和最小值emin为: (7) (8) (9) 在式(7)~式(9)中,φguj表示网格gu中心点的第j个属性平均值,φkfj表示格簇kf的第j个属性平均值。 本文所有的距离均采用欧式距离,下文不再赘述。 对于任意一个格簇kf,其阈值Th(kf)为: (10) 为了判断某2个格簇内数据点的分布形态变化是否相同,采用文献[5]判断局部散布形态是否发生突变的方法。首先通过主成分分析提取每个格簇内数据点的特征,然后利用最大特征值和次大特征值的比值来确定该格簇内数据点的分布形态变化,并引入格簇内数据点分布形态相似阈值β(β≥1)来判断某2个格簇内数据点的分布形态变化是否相同。对于一个格簇集合K=(k1,k2,…,kL)内的任意2个格簇kp和kq,kp内数据点的分布形态变化为changekp,关键点为keypkp且阈值为Th(kp),kq内数据点的分布形态变化为changekq,关键点为keypkq且阈值为Th(kq)。格簇kp的关键点keypkp与格簇kq关键点keypkq间的距离为: (11) 定义14(相似格簇) 若格簇kp和kq相似,当且仅当满足式(12)和式(13)2个条件[5]: (12) dist(keypkp,keypkq)≤Th(kp)+Th(kq) (13) 定义15(格簇结构体) 为每一个格簇构建一个结构体,用来存储格簇的概要信息。设某一格簇kf,其结构体表示为: LCSTRkf={keypkf,Th(kf),lablekf,changekf} (14) 其中,keypkf、Th(kf)、lablekf、changekf分别表示格簇的关键点、格簇的阈值、格簇的类型和格簇内点集分布的形态变化。 针对前文所述目前关于时序数据的密度聚类算法仍存在3类问题,本文提出一种基于密度和网格的聚类算法,并应用于时序数据流异常检测问题。针对现有时序数据流聚类算法存在的问题和异常轨迹检测算法的局限性,本文主要针对某一个体的轨迹进行分析并提出了一种基于密度和网格的聚类算法。采取按时间段对个体轨迹划分的方法对个体异常轨迹进行检测,通过获取当前数据块内数据的特征动态地设置网格密度阈值、网格划分等参数。针对目前时序数据流存在的问题,本文算法做了如下改进:针对数据分布密度不一的问题,通过对稠密网格、过渡网格和稀疏网格形成的稠密图、过渡图和稀疏图分别进行聚类,并利用自适应阈值对所得结果进行再次聚类。针对网格被预先划分的问题,本文算法引入了动态生成网格的方法。根据当前在线处理过程内数据点的特征,以某些数据点作为网格中心,自适应地重新生成网格。针对获取任意时段内数据的聚类结果,通过获取该段时间内的格簇进行再次聚类,并利用自适应阈值对所得结果进行再次聚类,得到最终的聚类结果。 在传统的异常检测算法中,训练集中必须要有异常轨迹参与训练,否则学习器无法识别异常轨迹。然而,提前获取用户异常轨迹信息可能比较困难,因而本文采用聚类思想解决该问题。由于用户的轨迹信息是一种时序数据流,因此本文算法采用时序数据聚类算法,根据用户的运动规律将训练的轨迹信息划分时间段,并对相应时间段内的轨迹数据进行聚类,其聚类结果作为该用户的训练集。测试轨迹首先对相应时间段内的轨迹信息进行聚类,得到聚类结果作为测试集。若测试集中存在某一类与训练集中的任何一类都不相似,则认为该测试轨迹异常。 该聚类分为在线处理数据和离线处理数据2个处理过程。在线处理数据过程对数据块内的数据进行处理,动态生成网格并将数据一一映射到相应的网格中,通过使用密度阈值对在线算法所产生的网格分成稠密网格、过渡网格和稀疏网格。根据对稠密网格、过渡网格和稀疏网格不同的处理方法对其进行处理,得到格簇集合并将所有的格簇集合存入数据库中。离线处理数据过程,根据用户的需求,取出某时间段内的格簇集合,通过判断任意2个格簇是否相似进行再次聚类,得到最终的聚类结果。 2.2.1 动态生成网格单元方法 传统的固定划分网格方法不能适应当前数据的特征,且网格一旦划分就不会改变。为了避免这种缺陷,本文引入了动态生成网格的方法,根据当前数据块的特征自适应地生成网格,且网格的划分会随着数据块的变化而改变。 当数据块已满即数据块内有n个数据单元时,采集该数据块内数据单元特征,通过计算数据单元每一维属性的均值δj,动态地确定网格单元每一维空间划分的长度hj。每一维属性的均值δj为: (15) 其中,aij表示第i个数据单元的第j个属性值。 网格单元gu每一维空间的划分长度hj为: (16) 根据数据块内数据单元的特征,选取R(1≤R≤n)个数据单元作为网格的中心生成R个网格,对于任意一个网格gu(1≤u≤R)在每一维上的划分Hguj表示为: Hguj=[ωuj-hj/2,ωuj+hj/2] (17) 其中,ωuj表示所选取的第u个数据单元的第j个属性值,则所生成的网格单元可以表示为: (18) 2.2.2 各类网格的处理方法 网格的处理方法主要有以下2种方法: 1)稠密网格处理方法 针对稠密网格,以网格中的中心点作为顶点,若任意2个网格相邻,则为其赋予一条边生成稠密无向有权图,通过深度优先算法获取有权图的连通分支从而得到稠密格簇集合DC(Dense Cluster)。 2)过渡网格和稀疏网格处理方法 针对过渡网格,需先计算稠密格簇中每个稠密网格中所有点距该稠密网格中心点距离的标准差。设任意一个网格gm(1≤m≤R),其标准差为: (19) 其中,rm为该稠密网格内数据单元的个数,azj为第z个数据单元的第j个属性值,φgmj为该网格中心点的第j个属性值,若过渡网格gl的中心点与某一稠密网格的中心点的距离小于标准差SDgm,则将该过渡网格gl归入该稠密网格所属的格簇中,并将gl从过渡网格集合移除。继续计算归入稠密格簇的过渡网格的标准差SDgl,若剩余的某个过渡网格的中心点与归入稠密格簇的过渡网格的中心点的距离小于过渡网格gl的标准差SDgl,则将该过渡网格归入过渡网格gl所属的稠密格簇中,直到剩余的任意一个过渡网格都不可归入某个稠密格簇为止。之后,对剩余的过渡网格采用和处理稠密网格相同的方法生成过渡无向有权图,并得到相应的过渡格簇集合TC(Transition Cluster)。对稀疏格簇采用与过渡网格相同的处理方法得到稀疏格簇集合SC(Sparse Cluster)。 2.2.3 噪声的处理 在对用户的轨迹信息进行训练获取样本集时,可能会有异常轨迹参与训练。这些异常轨迹对于后续分析是很宝贵的资源,而在传统聚类方法中往往将其标注为噪声予以舍弃。因而本文将噪声数据独立生成异常类进行处理。 在时刻t,若某个格簇内所有网格的数据个数之和依然小于稀疏网格阈值SGTh(t),则认为该格簇内所有的数据点为噪声,将该格簇从所生成的格簇集合中分离,并将其标记为异常类。 例如,不妨设SGTh(t)=8,某2个格簇都包含3个网格,在这2个格簇中,一个格簇内所有数据点为噪声,而另一个格簇内所有数据点为非噪声的情况,噪声判别情况如图1所示。 图1 噪声判别情况 由图1(a)可知,图稀疏格簇内数据点的个数之和为5,小于稀疏网格阈值SGTh(t),所以该格簇内所有的数据点为噪声;图1(b)格簇内数据点之和为9,大于稀疏网格阈值SGTh(t),因而该格簇内的数据为非噪声点。 通过分离最后得到2种格簇集合,即正常轨迹格簇集合NNLC=(k1,k2,…,kNL)和异常轨迹格簇集合AABNLC=(kAB1,kAB2,…,kABNL)。 2.2.4 类相似 类实际上是格簇集合,那么对于任意2个类CP和CQ,设CP有bP个格簇,CQ有bQ个格簇,则CP=(k1,k2,…,kbP),CQ=(k1,k2,…,kbQ)。类CP的中心点为cP=(αcP1,αcP2,…,αcPd),类CQ的中心点为cQ=(αcQ1,αcQ2,…,αcQd)。 (20) (21) 设类CP和CQ的距离为: (22) 其中,式(20)中的αCPj表示类CP中心点cP的第j个属性值,式(21)中的αCQj表示类CQ中心点cQ的第j个属性值。 类间距离归一化处理: 设所求的类间距离最大值为DCmax,最小距离为DCmin。 (23) 设类间相似阈值为μ(0<μ<1),若Dcen(CP,CQ)≤μ,则认为这2个类相似;否则不相似。 2.2.5 在线处理数据过程描述 在线处理数据过程如下: 输入数据块Xb=(xρ,xρ+1,…,xρ+n-1) 输出格簇集合K=(k1,k2,…,kL) 步骤1获取数据块Xb中的数据单元。 步骤2计算数据单元每一维度的平均值δj和维度划分的长度hj,并确定每个网格空间。 步骤3读入新数据单元xυ(i≤υ≤i+n-1),如果数据xυ(i≤υ≤i+n-1)属于当前某一网格则该网格密度加1;否则以数据单元xυ(i≤υ≤i+n-1)为中心生成一个新的网格。 步骤4计算时刻t稠密网格阈值DGTh(t)和稀疏网格的阈值SGTh(t)。 步骤5判断网格是稠密网格、过渡网格或稀疏网格。 步骤6对稠密网格、过渡网格和稀疏网格分别进行处理,并得到稠密格簇集合DC,过渡格簇集合TC和稀疏格簇集合SC。 步骤7输出格簇集合DC∪TC∪SC。 2.2.6 离线处理数据过程描述 在该过程处理前,先根据用户所确定的时间段T,从数据库中获取该时段内的格簇集合。 输入时间段T内的格簇集合K=(k1,k2,…,kL),形态相似阈值β 输出聚类结果C=NC∪ABNC 步骤1确定每一个格簇的关键点。 步骤2判断格簇内的数据是否为噪声点,并得到相应的正常轨迹格簇NLC和异常轨迹格簇ABNLC。 步骤3根据格簇相似的方法,对NLC和ABNLC分别进行处理,将相似的格簇归为一类并得到正常轨迹类NC和异常轨迹类ABNC。 步骤4输出最终的聚类结果C=NC∪ABNC。 本文聚类算法的流程如图2所示。 图2 本文聚类算法流程 针对某一用户可能在某段时间内常去一些固定地点,因此其轨迹具有一定的规律。同时,也可能在某段时间内去一些之前未去过的地点。若能及时发现用户在该时间段内出行轨迹的异常,对于用户人身安全防护,尤其是老人、儿童等弱势群体,则具有重要的理论意义和应用价值。 2.3.1 轨迹异常 若测试轨迹中的某一类与训练集中正常轨迹类的任何一类都不相似,则认为该测试轨迹异常。当测试轨迹中的某一类不仅与训练集中正常轨迹中的某类相似,而且也与异常轨迹中的某类相似时,若与异常轨迹类的距离小于正常轨迹类的距离,则认为该测试轨迹异常。 2.3.2 过程描述 异常检测过程如下: 输入某段时间内的数据流X=(x1,x2,…,xi,…,xN),数据块的长度n,类间相似阈值μ 输出轨迹是否异常 步骤1将数据流按数据块长度划分为多个数据块。 步骤2利用2.2节的聚类方法对每个数据块进行聚类。 步骤3对步骤2所得的类,利用2.3.1节的方法,判断轨迹是否异常。 步骤4输出最终判断结果。 本文实验以微软亚洲研究院Geolife项目收集的用户GPS轨迹信息[13]为研究对象。该项目收集了178位用户从2007年4月—2011年10月的轨迹信息。该数据集的GPS轨迹表示时间戳点的序列,其中每一个包含纬度、经度和海拔高度的信息。 本文实验采用2.5 GHz处理器,4 GB内存。算法利用Eclipse4.4.2和Matlab2014a编程实现。 由于有些用户的运动规律不明显,因此本文实验从Geolife项目中筛选了运动规律较为明显且轨迹信息较为完整的50名用户在100 d内的轨迹信息,并根据每个用户的运动规律对其轨迹信息按时间段进行划分。 若类间相似阈值设置不合理,则可能会导致最终异常检测的判断结果。在实验过程中发现类间相似阈值与样本集中的经度之差(最大经度值与最小经度值之差)和纬度之差(最大纬度值与最小纬度值之差)2个变量有关。因此,针对所选出50名用户,随机选取40名用户的轨迹信息进行了分析,并得到类间相似阈值。 由于类间相似阈值无量纲,而经度之差和纬度之差是有量纲的数据,因此需先对经度之差和纬度之差进行归一化处理。以经度之差为例,其归一化过程如下: (24) 其中,ΔLon表示某一用户的实际经度之差,minΔLon为所有用户经度之差的最小值,maxΔLon为所有用户经度之差的最大值,Δlon为归一化后的经度之差。 利用Matlab拟合工具cftool对40名用户的类间阈值信息拟合得到类间相似阈值μ(Δlon,Δlat)与归一化后经度之差Δlon,纬度之差Δlat的关系如下: μ(Δlon,Δlat)= -0.048 61+17.49Δlon-20.84Δlat- 162.7Δ2lon-182.4ΔlonΔlat+ 516.8Δ2lat-626.5Δ3lon+ 769 9Δ2lonΔlat-1.25× 104ΔlonΔ2lat+410 9Δ3lat 类间相似阈值拟合曲线如图3所示。 图3 类间相似阈值拟合曲线 一条拟合曲线往往需要通过一些拟合参数来判断其拟合效果,该曲线的拟合参数值“误差平方和SSE、相关系数R-square、调整后的相关系数Adjusted R-square和标准差RMSE”如表1所示。 表1 拟合参数的取值 若SSE越接近0,R-square越接近1,则曲线拟合效果越好。从表1可见,该曲线的拟合参数R-square为0.951 1,较接近于1,表示该曲线能解释因变量95.11%的变化,SSE误差平方和为0.000 337,较接近于0。因此,可以判断该曲线拟合效果较好,可用该曲线的拟合结果来确定类间相似阈值的大小。 本文算法检测异常轨迹情况以用户4在00∶00—05∶00时间段内的轨迹信息举例说明。利用用户4从2008-08-05—2008-10-25在00∶00—05∶00时间段内的数据生成样本。判断用户4在2008-10-27、2008-10-28和2008-11-05的00∶00—05∶00时间段内轨迹是否异常。最后得到用户4在2008-10-27和2008-10-28的00∶00—05∶00时间段内轨迹正常,在2008-11-05的00∶00—05∶00时间段内轨迹异常。 用户4在2008-10-27、2008-10-28该时段内的正常轨迹,以及在2008-11-05该时段内的异常轨迹如图4~图7所示。 图4用户4从2008-09-25—2008-10-25在00:00—05:00时间段内的轨迹样本 图5 用户4在2008-10-27的00∶00—05∶00时间段内的正常轨迹 图6 用户4在2008-10-28的00∶00—05∶00时间段内的正常轨迹 图7 用户4在2008-11-05的00∶00—05∶00时间段内的异常轨迹 从图7可知,图7中有一部分轨迹在图4中没有出现,可以认为用户可能去了之前没有去过的地方,该轨迹异常。图5的轨迹和图4的轨迹相似,可以认为该轨迹正常。图6中的轨迹是图4轨迹中的一部分,因此该轨迹也正常。 对剩余的10名用户进行测试,该10名用户在原数据对应的编号见表2。利用10名用户前80 d内的数据进行训练得到样本集,并用剩余的20 d数据进行测试,通过类间阈值拟合曲线求得每个用户轨迹信息的类间阈值。10名用户后20 d内的轨迹统计情况见表2。 表2 10名用户轨迹统计情况 各算法检测正确率见表3。其中文献[4-5]算法的参数值均取该文献所建议的最优参数值,而本文算法参数的取值,通过实验获得最优参数。在表3中,TNR为真负率,ACC为准确率,其计算方法与文献[14-15]TNR和ACC的计算方法相同。从表3中可得,文献[4]检测异常轨迹的平均正确率仅为38.4%,文献[5]检测异常轨迹的平均正确率为53.5%,本文算法检测异常轨迹的平均正确率为72.2%,因此本文算法更适合于处理轨迹类数据信息并用来检测异常轨迹。 表3 各算法检测正确率比较 % 本文实验针对10名测试用户的轨迹信息对文献[4-5]和本文算法的时间效率进行了测试,其结果如表4所示。 表4 算法运行时间比较 s 由表4可得,文献[4]的时间效率最高,文献[5]的时间效率最低,而本文算法的时间效率介于两者之间且更接近于文献[4]算法。由实验3.1节可知,文献[4]判断轨迹异常的平均TNR仅有38.4%,因此虽然该方法的时间效率高,但仍不适合用于轨迹信息的处理。文献[5]判断轨迹异常的平均TNR为53.5%,虽然比文献[4]高,但其时间复杂度远大于文献[4]和本文算法,因此,该算法也不适合于对轨迹信息的处理。本文算法虽然比文献[4]消耗的时间多,但判断轨迹异常的平均TNR为72.2%,相当于文献[4]的2倍。 综上所述,本文算法更适用于处理个体轨迹信息等时序数据流的异常检测问题。 本文提出一种面向轨迹信息的时序数据流异常检测算法,算法主要分为训练和测试2个阶段,利用训练阶段得到的样本集并通过类间相似阈值求解方法确定阈值的大小,对测试阶段的测试集进行测试。对于2个阶段的聚类过程,引入了动态划分网格的方法以自适应当前数据的特征,并针对不同类型网格采用不同的方法进行处理,解决密度分布不均等问题。此外,根据用户的需求可得到不同时间段内数据的聚类结果。实验结果表明,本文算法能够较好地处理轨迹信息等时序数据流。由于本文算法仅能检测某时间段内用户的轨迹是否异常,而无法实时判断某一时刻用户所处的位置是否异常,因此如何判断用户某一时刻的位置是否异常和降低算法的时间复杂度,是下一步主要研究方向。 [1] 胡 睿,林昭文,柯宏力,等.一种基于密度和滑动窗口的数据流聚类算法[J].计算机科学,2011,38(5):145-148. [2] AGGARWAL C C,YU P S,HAN J,et al.A framework for clustering evolving data streams[C]//Proceedings of International Conference on VLDB’03.Washington D.C.,USA:IEEE Press,2003:81-92. [3] CHEN Y,TU L.Density-based clustering for real-time stream data[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.San Jose,USA:ACM Press,2007:133-142. [4] 杨 宁,唐常杰,王 悦,等.一种基于时态密度的倾斜分布数据流聚类算法[J].软件学报,2010,21(5):1031-1041. [5] 徐正国,郑 辉,贺 亮,等.基于局部密度下降搜索的自适应聚类方法[J].计算机研究与发展,2016,53(8):1719-1728. [6] 米 源,杨 燕,李天瑞.基于密度网格的数据流聚类算法[J].计算机科学,2011,38(12):178-181. [7] 于彦伟,王 欢,王 沁,等.面向海量数据流的基于密度的簇结构挖掘算法[J].软件学报,2015,26(5):1113-1128. [8] 于彦伟,王 沁,邝 俊,等.一种基于密度的空间数据流在线聚类算法[J].自动化学报,2012,38(6):1051-1059. [9] 马 帅,王腾蛟,唐世渭,等.一种基于参考点和密度的快速聚类算法[J].软件学报,2003,14(6):1089-1095. [10] 朱 燕,李宏伟,樊 超,等.基于聚类的出租车异常轨迹检测[J].计算机工程,2017,43(2):16-20. [11] ZENG Y,CAPRA L,WOLFSON O,et al.Urban computing:concepts,methodologies,and applications[J].ACM Transactions on Intelligent Systems & Technology,2014,5(3):38. [12] 金澈清,钱卫宁,周傲英.流数据分析与管理综述[J].软件学报,2004,15(8):1172-1181. [13] ZHENG Y,XIE X,MA W Y.GeoLife:a collaborative social networking service among user,location and trajectory[J].Bulletin of the Technical Committee on Data Engineering,2010,33(2):32-39. [14] 高嘉伟,梁吉业.非平衡数据集分类问题研究进展[J].计算机科学,2008,35(4):10-13. [15] 高嘉伟,梁吉业,刘杨磊,等.一种基于Tri-training的半监督多标记学习文档分类算法[J].中文信息学报,2015,29(1):104-110.1.4 格簇
2 本文算法
2.1 设计方法
2.2 时序数据聚类

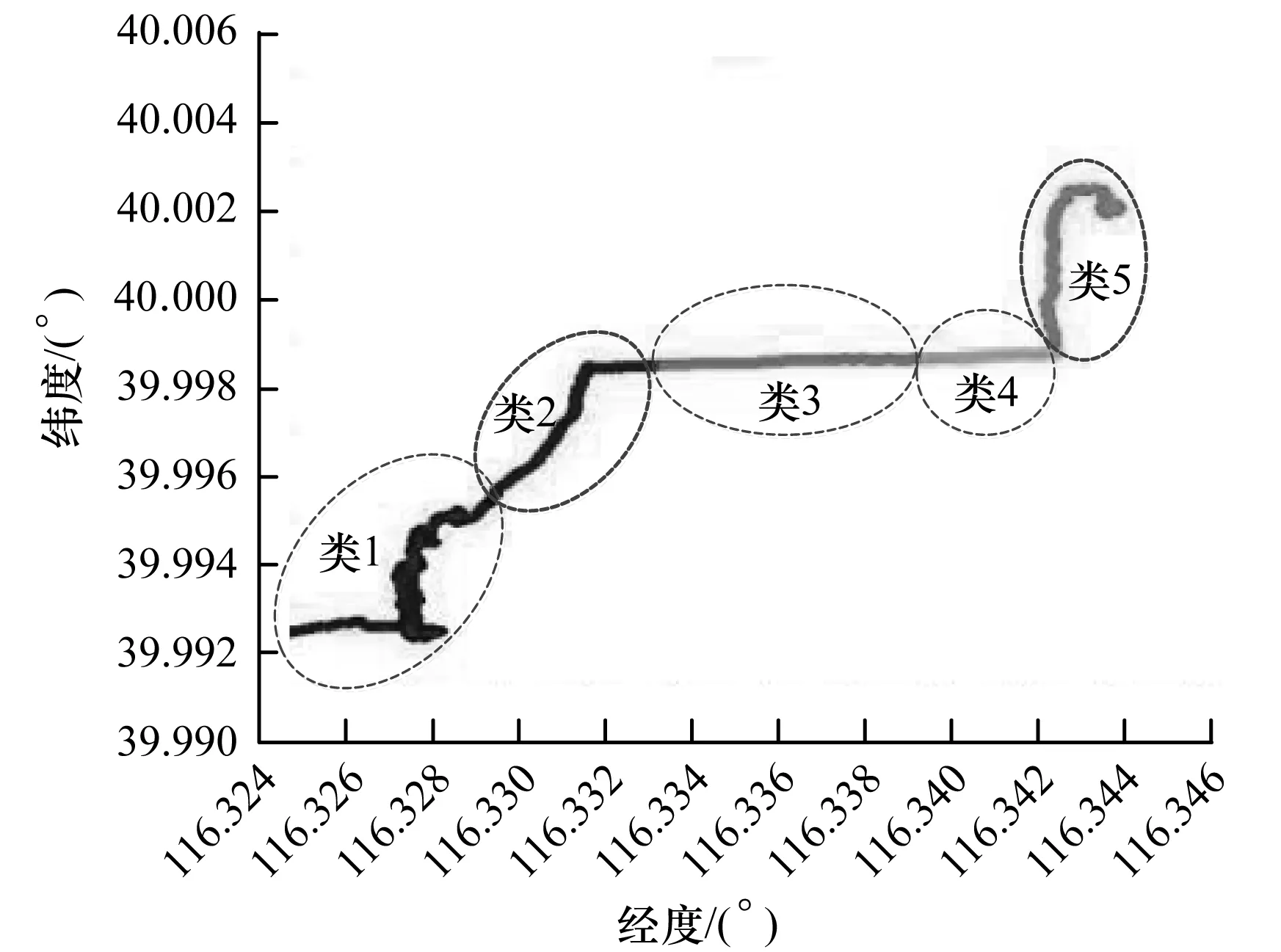
2.3 异常检测过程
3 实验结果与分析
3.1 功能比较







3.2 时间效率比较

4 结束语
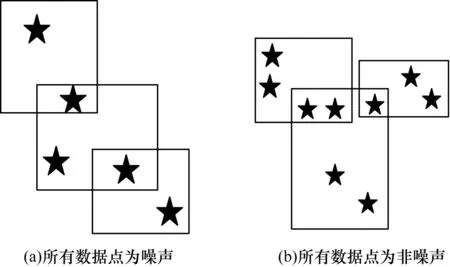
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
汽车维修与保养(2020年11期)2020-06-09 05:42:22
现代装饰(2018年5期)2018-05-26 09:09:39
电脑与电信(2018年12期)2018-03-23 02:37:36
电子测试(2017年15期)2017-12-18 07:19:27
中国三峡(2017年2期)2017-06-09 08:15:29
智能系统学报(2015年4期)2015-12-27 09:38:39
西北工业大学学报(2015年3期)2015-12-14 13:08:48
电子设计工程(2015年6期)2015-02-27 12:04:53
