
基于学习风格的自适应学习内容推荐研究
2018-05-23 09:43:04许益通张冰雪赵逢禹
软件 2018年4期
许益通,张冰雪,赵逢禹
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
学习风格被认为是学习者相对稳定的特征之一,在学习过程中占重要地位。不同的学习风格的学习者,对应着不同的最佳教学模式。为了对学习风格进行量化统计,研究者相继提出了 70多种理论,提出了不同的学习风格模型[1]。这些理论中应用较多的模型有:Felder和Silverman[2]于1988年从感觉通道和信息加工角度提出了学习风格模型;Kolb[3]于1976年基于经验学习理论建构的学习风格模型,Honey和 Mumford[4]于 1982年对 Kolb的模型进行修订建构了新的学习风格模型。其中应用最广泛的是Felder-Silverman学习风格模型,其学习风格量表(FSLSM)[5]被认为是较适合开发在线自适应学习系统的学习风格模型[6]。
自适应学习是基于不同学习者的需求和风格特征,设计不同的展示形式,提供不同的学习内容[7]。而支持定制并可以适应每个人的具体喜好的界面可能比设计为“一切适合所有”的界面更有效。在这种情况下,基于不同学习者的学习风格,并定制其用户界面以适应个人的特定偏好和风格是有意义的[8]。
在线学习平台个性化是近年来该领域最重要的研究领域之一,相关研究者希望能够吸收学习者更多的教育背景信息,为使用者提供个性化的学习环境[9]。在这方面,出现了一些值得注意的研究成果,同时也存在着一些问题:Lu等人[10]提出了个性化电子学习推荐系统PLRS,目的是帮助学生找到他们需要学习的学习材料,使用模糊树匹配学习内容。但是由于树自身的结构特征,无法对不同路径的学习内容进行关联,从而影响内容推荐的结果;在另一项工作中,Yong等人[11]提出了一种智能学习系统,引入学习者模型设计自适应匹配规则,使用户界面自适应于用户的学习风格,界面形式相对简单;Zhuhadar等人[12]介绍了一种基于本体的混合推荐系统。该系统的主要优点是能够对学习材料进行语义搜索,但没有涉及学习界面的自适应;Ghauth等人[13]的报告的工作的基本思想是根据内容相似性和学习者的评价形式的反馈向学生推荐学习材料。该研究没有基于学习者的学习风格进行自适应推荐,仅通过优秀学习者的平均评价策略推荐学习材料。
当前的自适应学习系统仍存在不足之处:1.忽略了内容展示形式的自适应,没有针对不同学习风格设计不同的内容展示形式。2.忽略了学习风格对于学习内容推荐的重要性,没有考虑不同类型的学习材料对于不同学习风格学习者的接受程度。
基于以上分析,本文将基于 Felder-Silverman学习风格模型研究自适应学习推荐策略,设计自适应学习内容的展示形式,实现展示形式的个性化;组织学习内容,并提出了 Auto-kg算法,设计学习内容之间的层次关系,以及层次内部和层次之间的关联信息,构建学习内容的知识图谱,然后将学习风格的推荐策略与知识图谱中的关系与节点内容高度匹配的内容进行展示,实现具体内容的个性化。本研究设计并开发了自适应学习内容推荐系统,构建了验证实验,对实验结果进行数据分析和证实。
1 学习风格与自适应推荐策略
自适应学习系统的自适应性依赖于学习风格[14]。学习风格(learning style)是在学习情境中个体表现出来的比较稳定的处理方式和学习策略倾向[15]。基于学习风格设计自适应学习推荐策略能够更有针对性的提高不同人群的学习效果,所以学习风格的量化和自适应学习推荐策略的设计显得格外重要。为了对学习风格进行量化统计,Felder和Silverman于1997年开发 Felder-Silverman学习风格模型,如今已经得到了越来越多研究者的认可,被 CS383、MASPLANG、LSAS、TANGOW等国外著名的自适应学习系统所采纳,在大量实验数据的支持下,证明了其在网络教学环境下良好的适用性和信效度[16]。该量表分别从感知、输入、信息加工、理解四个方面将学习风格分为4个维度8种类型,比较全面地反映了学习者的学习风格,这几种学习风格类型的特点如下:
感觉型与直觉型。感觉型学习者喜欢事实、数据和实验,喜欢通过标准方法解决问题。不喜欢特殊化的解决方法,善于记忆事实,做题仔细但可能很慢;直觉的学习者喜欢原则和理论,喜欢创新解决方法而不喜欢重复,对于细节感到无聊,善于解决难题,善于掌握新概念,做题很快,但可能不细心,擅长于掌握新概念,能理解抽象的数学公式。
视觉型与文字型。视觉型的学习者最了解他们所看到的,如图片、图表、流程图、电影和示范。如果仅仅从文字或语言交流进行学习,他们的记忆并不牢固;文字型的学习者更擅长从文字的和口头的解释中获取信息。
积极型与反思型。积极型学习者是先做后想型,倾向于通过积极地做一些事,讨论或应用或解释来掌握信息,倾向于团队合作;而反思型学习者更喜欢安静地思考问题,更喜欢独立工作。积极型学习者往往是实验家,反思型学习者往往是理论家。
顺序型与全局型。顺序型学习者在解决问题时遵循线性推理过程,融合思维和分析中可能很强,善于学习复杂性和难度稳定进展的学习内容;全局型学习者在解决问题时遵循直观的飞跃,会更好地发散思维和综合,通过直接跳到更复杂和更困难的学习内容时会做得更好。
在确定了对学习风格的量化统计后,针对该学习风格模型的各个维度设计对应的自适应推荐策略,将更有针对性的提高不同人群的学习效果。Felder-Silverman学习风格模型是针对课题学习而开发的,为了将设计出的自适应推荐策略与在线学习平台结合,在设计推荐策略需要考虑在线学习平台的特性。
2 自适应学习内容推荐策略
为了实现自适应学习,本章首先通过 Felder-Silverman量表获取学习者的学习风格,然后对得到的学习风格设计对应的自适应推荐策略,再根据策略中关于学习内容方面提出了 Auto-kg算法构建自适应学习内容知识图谱,最后给出了 Auto-kg算法实现步骤以及具体的算法描述。
2.1 获取学习风格
Felder-Silverman量表的每种维度都对应 11道题,共有44 道题目,每道题有a、b两个选项。
学习者的学习风格判定规则如下:
(1)在题目对应所选择的答案填上“1”。如果该问题的选择答案为 a,则在 a栏填上“1”,否则在 b栏填上”1";
(2)计算答案列选择a和选择b的总数,并填写在总计栏;
(3)用较大的总数减去较小的总数,记下差值(1到11)和字母(a或b),其中字母代表学习风格的类型不同,数字代表程度的差异。
(较大数-较小数)+较大数对应的字母 (1)
通过公式(1),若得到字母“a”,表示属于前者学习风格;若得到字母“b”,表示属于后者学习风格。字母前的系数越大,表明程度越强烈;
其它 3个量表中通过上述规则依次计算出差值,判断出各个维度所属学习风格类型以及量化数值,最后得出该学习者最终的学习风格和不同维度的程度。对于相同学习风格的学习者,根据维度程度大小的不同,设计出不同的学习内容展示顺序和大小。
2.2 自适应推荐策略研究
自适应推荐策略是研究在线学习平台上如何根据学习者的不同的学习风格,设计不同的界面展示形式以及推荐合适的学习内容。推荐策略的好坏直接影响了自适应学习的效果。Felder和Silverman开发的 Felder-Silverman学习风格模型主要是针对的是课堂学习环境,所以在设计自适应学习推荐策略时,需要结合在线学习平台的特性。
根据Felder-Silverman学习风格模型的特点,本文对该模型的四个维度八个方向设计不同的自适应推荐策略。策略设计依据Felder-Silverman对学习风格特点的描述,并结合在线学习平台以学习者为中心、资源海量和开放灵活等特性,以达到合适的推荐效果。
2.2.1 察觉信息维度
察觉信息这个维度包含感觉型和直觉型两个方向。当学习者在Felder-Silverman量表中该维度的统计结果字母为a时,代表学习者在该维度表现为感觉型,否则为直觉型。对于这两个方向来说,其最主要的区别在于学习内容类型。对于感觉型的学习者而言,他们更偏向于具体化的学习内容,而对于直觉型学习者,他们更偏向于抽象化的学习内容。所以该维度针对展示抽象或具体的学习内容方面进行自适应推荐策略的设计。具体的推荐策略如表 1所示。

表1 察觉信息维度自适应推荐策略Tab.1 Awareness of information dimension adaptive recommendation strategy
2.2.2 信息输入维度
这个维度包含视觉型和文字型两个方向,主要是学习者对于信息的呈现形式所表现出的接受性倾向。当学习者在Felder-Silverman量表中该维度的统计结果字母为a时,代表学习者在该维度表现为视觉型,否则为文字型。对于视觉型学习者而言,他们善于接受视觉输入形式的学习内容和组织形式。而对于文字型学习者,则更擅长接受文字和听觉形式的学习内容和组织形式。具体的推荐策略如下:

表2 信息输入维度自适应推荐策略Tab. 2 Information input dimension adaptive recommendation strategy
2.2.3 信息处理维度
该维度主要是区别学习者对于知识和信息的反应形式,可以理解为积极型学习者更倾向于主动团队讨论问题,对知识进行实际应用,而反思型学习者倾向于独立思考问题,对知识进行分析联想。当学习者在 Felder-Silverman量表中该维度的统计结果字母为a时,代表学习者在该维度表现为积极型,否则为反思型。具体的推荐策略如下:

表3 信息处理维度自适应推荐策略Tab.3 Information processing dimension adaptive recommendation strategy
2.2.4 理解信息维度
该维度主要是区分学习者对知识接受步骤。当学习者在 Felder-Silverman量表中该维度的统计结果字母为a时,代表学习者在该维度表现为顺序型,否则为全局型。对于顺序型学习者,在讲解一个理论时,注重理论的形成逻辑,公式推理等方面内容,展示如何通过理论推导出结果;而对于全局型学习者,需要多将当前的学习内容与之前学的和之后学的内容相联系,与其他课程内容相关联,与学习者个人经验相关联。顺序型与全局型的学习者更注重学习内容之间的关联,即在组织学习内容时,需要通过具体的算法对学习内容进行处理。具体的推荐策略如下:

表4 理解信息维度自适应推荐策略Tab.4 Understand the information dimension adaptive recommendation strategy
2.3 构建自适应学习内容知识图谱
为了实现基于学习风格的自适应学习内容的推荐,对各类学习风格的学习者推荐最适合的具体的学习内容,根据所研究的自适应学习内容推荐策略,构建自适应学习内容知识图谱。知识图谱是指由知识点相互连接而成的知识网络集合。将自适应推荐策略中的学习内容构建知识图谱,利用知识图谱高关联性、高结构化、高精准度和高检索速度等特性,完成自适应学习内容推荐模型的设计。本文的自适应学习内容知识图谱以中国建筑史为背景,分成中国建筑史的概述、史前至秦汉时期、隋唐时期、明清时期的中国建筑四个模块。首先,将学习内容划分层次,然后再构建层次之间的关联关系,最后,构建层次内部的关联关系,完成自适应知识图谱的构建。
2.3.1 学习内容层次划分
本文用 INF代表自适应图谱中的学习内容材料,INF={Root,Cb,Cs,Css,Co},Root代表根节点,即中国建筑史,Cb代表大章节,Cs代表小节,Css代表子小节,Co代表内容文件。以“中国建筑史”为根节点,划分层次 AL={S1,S2,…,Si},i代表所在层次。四大章节划分为第一层次S1,小节划分为第二层次S2,子小节划分为第三层次S3,内容的组织形式(抽象概念类、具体实例类)为第四层次S4,关联的文件划分为第五层次S5。每个层次的章节、小节、子小节、内容形式、文件视为节点 NODEi,NODEi={N1,N2, …,Nj},j表示该节点所在层次的位置。每个节点 Nj又包含自己的属性,Nj={name,keywords, path},name、keywords和path分别表示名称、关键词和存放路径。关键词包含内容位置信息、节点信息(普通节点还是文件节点)、摘要信息等。前四层的节点都含有和keywords属性,第五层的节点包含name、keywords和path三种属性。
2.3.2 构建层次间关联关系
层次间的关联关系即节点的从属关联关系。构建层间关联 RELAoutij,i和 j代表不同的层次,第一层次与根节点之间建立“have”关联,即RELAout01=have;第二层次与第一层次之间建立关联RELAout12=content of,第三层次与第二层次之间建立关联RELAout23= part of,第四层次与第三层次之间建立关联RELAout34=classifi of,第五层次与第四层次之间建立关联RELAout45= file of。
2.3.3 构建同层次内部关联
内部关联包括章节、小节等的内容顺序关联(学习顺序)和相关内容关联。构建层内关联RELAini={Ijk},i代表所在的层次,j和k代表层内不同的节点。对NODE属性keywords进行语义分析,获取内容顺序信息和相关内容信息,构建内容顺序关联和相关内容关联。如果内容之间存在内容顺序关联,则Ijk=order of,如果存在相关内容关联,则Ijk=rele of。不同层次之间拥有的一种或多种关联。
2.4 Auto-kg算法
为了构建自适应学习内容的知识图谱,本文提出了Auto-kg算法。Auto-kg算法是将所需构建知识图谱的所有的自适应学习内容划分层次,并构建分层内部学习内容的关联和层次间学习内容的关联,最后得到完整的自适应学习知识图谱。Auto-kg算法分为层次划分、层间关联和层内关联三个部分。
下面给出 Auto-kg算法具体的算法描述,在算法中,符号:
Stage(INF):对学习内容进行层次划分;
count():统计数量;
add():添加集合元素;
Arrt(节点): 获取节点属性;
Rele(节点,节点): 获取节点之间的关系;具体如下:
算法1 Auto-kg算法
输入:INF。
输出:AL、RELAout和RELAin,即层次、层间和层内关系。
Auto-kg算法描述:
1. AL<-Stage(INF)//划分层次
2. for i∈count(AL)do
3.for j∈count(NODEi)do
4.Nj<-Arrt(Nj)
5.NODEi<-add(Nj)//构建节点属性
6.RELAini<-Rele(Nj,Nj+1)//构建层内关联
7.for k∈count(NODEi+1) do
8.RELAoutjk<-Rele(NODEi(j),NODEi+1(k))
9.//构建层间关联
10.end for
11.end for
12.end for
通过 Auto-kg算法构建的学习内容的部分知识图谱如图1所示。
3 系统实现和实验对比
为了检验自适应学习内容推荐模型的实际效果,本文在自适应学习内容推荐模型的基础上开发了自适应学习内容推荐系统,并设计对比试验。
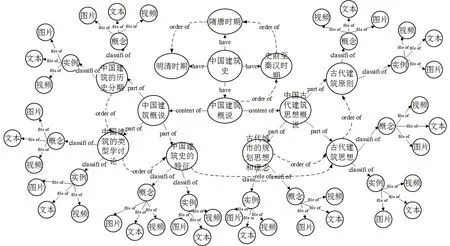
图1 课程的知识图谱Fig.1 Curriculum knowledge map
3.1 系统实现
通过对 Moodle在线学习平台的基础上进行了二次设计,完成自适应学习内容推荐系统的开发。系统所包含内容如下:
(1)设计 Felder-Silverman量表的网页版。当学习者初次使用该系统时会通过量表获取学习者的学习风格;
(2)根据自适应推荐策略中关于内容展现的部分,对 Felder-Silverman学习风格的四个维度八个方向设计不同的展示界面,如图2所示当学习风格为感觉型/视觉型/积极型/全局型时页面的部分展示形式;
(3)将学习内容知识图谱的所有内容包括节点、关系及属性值等存入图形数据库工具Neo4j;
(4)当系统获取到用户的学习风格后,系统会根据该学习风格对应的学习内容推荐策略与图形数据库进行高速匹配检索,在对应的展示界面上展示出相应的学习内容,完成自适应学习内容的个性化推荐。
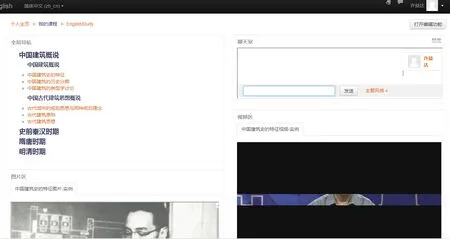
图2 感觉型/视觉型/积极型/全局型页面展示形式Fig.2 Sensory/visual/positive/global page presentation
Neo4j是高性能的图形数据库,在存储图形类数据时,其轻量、高结构化和高读取速度保证了学习内容推荐的效率,而其图形化的存储方式也保证了学习内容推荐的精确度。为了检测自适应学习内容推荐系统是否可以改善学习者的学习效果,设计并实施了相关的实验。完整的自适应学习内容推荐系统部署在我校软件工程专业高性能服务器上。
3.2 实验设计
为了更显著对学习效果的提高,本实验采用了等组的实验方法。具体的设计思路为:
(1)划分实验对象。将选取的实验对象等分为对照组(标记为A1)和实验组(标记为A2)。其中,A1组的学生不进行学习风格检验,直接访问该学习系统,但系统并没有自适应推荐学习内容;A2组的学生通过学习风格检验并使用自适应学习系统,在使用系统前通过填写 Felder-Silverman学习风格问卷,系统确定学习者的学习风格,并向其推荐个性化的学习界面和学习内容。
(2)进行对比实验。让A1组合A2组学生在给定的相同时间内,学习《中国建筑史》相同的学习内容,学习结束后提供线下测验。
(3)分析实验结果。记录两组学习者学习内容所使用的时间和测验成绩两个维度对学习效果进行综合评价。
(4)设计系统满意度评测问卷。从系统的有用性、系统的易用性、系统的认知负担和开放建议四个方面设计问卷,在线下测验后提供A1和A2组填写。
因为两组学习者在学习过程中仅 A2组通过学习风格检验并使用自适应学习系统,所以假设经过相同时间的学习,A2组的学习效果高于A1组(A2组的测验平均用时少且平均成绩高),A2组对自适应学习内容推荐系统满意度高。
3.3 实验对象
从我校大三学生中随机选取 50名学生作为实验对象。为了尽量避免由于学生认知水平差异对实验造成的影响,实验采用了系统随机抽样和简单随机抽样的混合方法选取样本,具体操作如下:
(1)将我校大三计算机专业三个班共152名学生的高考录取名次按升序排列,录入 Excel电子表格中,使用系统随机抽样每三位选取一名样本学生(间距k=152/50),共选取50名学生;
(2)将该50名学生随机打乱,使用简单随机抽样选取 25位样本学生作为对照组(A1组),剩余25位作为实验组(A2组)。
通过对实验对象的调查了解,他们并没有系统接触过中国建筑史的相关课程,所以认为这两组学生认知水平没有差异,整体上可以进行实验分析。
3.4 实验内容
实验内容为记录学习者的学习时长和线下测试的成绩。A1组学习时长由个人记录,A2组的学习时长由自适应系统计时。为了保证学习过程中不受外界干扰,以及 A1组个人计时的准确性,两组统一组织在机房进行学习。学习内容选取《中国建筑史》第三章节的“隋唐时期”,涉及的知识点范围较广,难度以适中为主,题型多,资源类型丰富,适合作为学习内容。课下测验的题型为30个单选题和5个开放性题目,满分100分。
3.5 实验实施
实验过程为:1.实验前,先向50名实验者说明本次实验的目的、意义、过程和规则等。2.组织两个组学生在不同的机房通过访问自适应学习内容推荐系统进行为期三天的学习,为了保证学习效率,每天学习时间不超过2小时,第三天学习结束后组织者向每一位实验者发放测试试卷,在机房进行测试,考试时间1小时,可提前交卷。3.对50份试卷进行批阅,单选题以标准答案为准,一题2分,开放性试题点到给分,每题 8分。4.收集每位同学的学习时长和测试成绩,作为数据分析的依据。
3.6 实验结果与结论
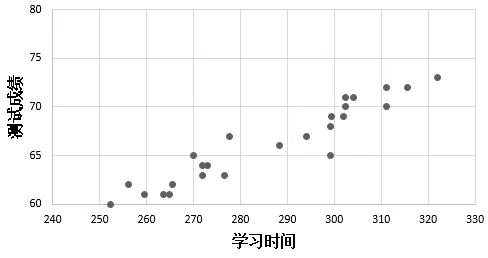
图3 A1组测试成绩-学习时间折线图Fig.3 A1 group test scores-learning time line chart
通过以上的实验,将收集到的每位学生的学习时间和测试成绩输入Excel中,通过Excel从学习时间和测试成绩两个维度对数据进行分析,分布图见图2和图3。对比图3和图4,可以发现:A1组的学生学习用时的跨度较大,随着学习时间的增加,测试成绩也随之增加;A2组的学习时间和测试成绩相对而言较为集中。为了进一步分析两组之间的差异性,使用SPSS工具对数据做独立样本t检验分析,结果见表 3。通过表 3可以看出,在学习时间上,两组学生的平均时间都为280多分钟,但A1组的标准差高于A2 组(20.613>14.681),说明A1 组学习过程中的时间分离度较大。在学习成绩上,两组学生的成绩都处于中等偏上,但 A1 组学生的成绩要差于A2 组(65.24<72.04,4.164>3.541)。结合 Sig.(2-tailed)值可进一步发现,时间t的Sig=P=0.246>0.05,可以看出两组学生学习时间差距较小;成绩t的Sig=P=0.000506<0.05,说明两组学生学习成绩差距较大。
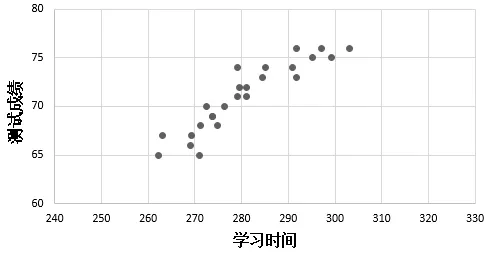
图4 A2组测试成绩-学习时间折线图Fig.4 A2 group test scores-learning time line chart
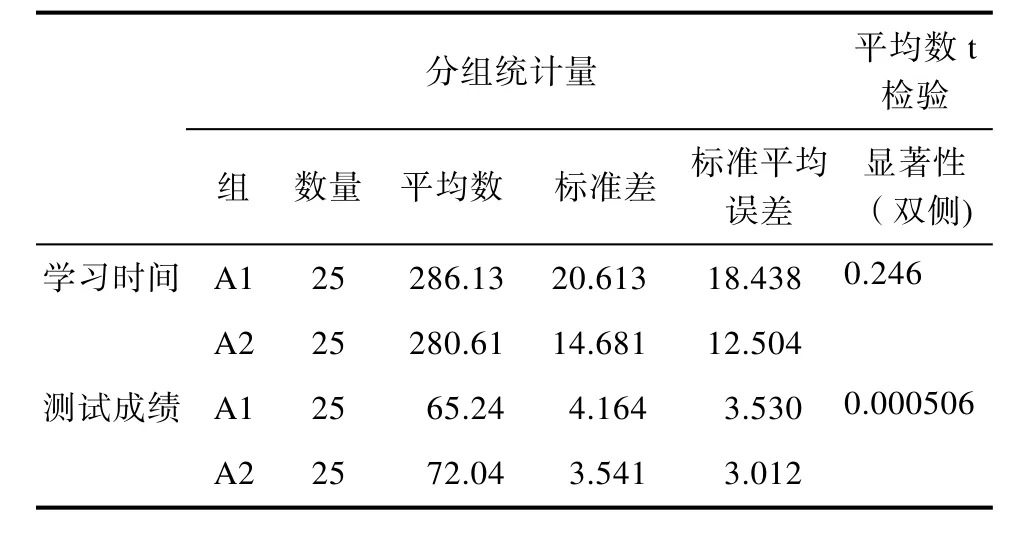
表5 A1组和A2组数据分析Tab.5 A1 and A2 data analysis
通过对照组和实验组的分析结果对比,可以观察到实验组(A2组)的平均学习时间略小于对照组(A1组),实验组(A2组)的测试平均成绩高于对照组(A1组),且实验组(A2组)对自适应学习内容推荐系统满意度高。本实验的结果在一定程度上说明了自适应学习内容推荐系统能够有效的提高学习者的学习效率和学习成绩。
4 结语
针对传统自适应学习网站对学习者学习效果提升有限的问题提出了基于 Felder-Silverman学习风格模型的自适应学习内容的推荐策略,设计Auto-kg算法构建自适应学习内容知识图谱,实现学习内容的自适应推荐,并通过实验证明该模型能够明显的提高学习者的学习效果。但本文仍存在不足的地方,比如页面设计的合理性分析等,是以后需要完善的地方。
参考文献
[1] Truong H M. Integrating learning styles and adaptive e-learning system: Current developments, problems and opportunities[J]. Computers in Human Behavior, 2016, 55(PB):1185-1193.
[2] Felder, R., and Silverman, L. Learning and Teaching Styles in Engineering Education[J], Engineering Education, 1988,78(7): 674–681.
[3] Kolb, D. A. Learning styles and disciplinary differences[J].The Modern American College, 1981: 232–255.
[4] Honey, P., & Mumford, A.. Using your learning styles. Peter Honey Maidenhead, UK. 1986.
[5] Felder, R. M., Soloman. B. A. Index of learning styles questionnaire[DB/OL]. http://www.engr.ncsu.edu/learningstyles/ilsweb. html, 2013-07-25.
[6] Huang, E. Y., Lin S. W., & Huang, T. K. What type of learning style leads to online participation in the mixed-mode e-learning environment? A study of software usage instruction[J].Computers & Education, 2012, 58(1): 338-349.
[7] Nihad Elghouch. ALS_CORR[LP]: An Adaptive Learning System Based on the Learning Styles of Felder-Silverman and a Bayesian Network[C]. Information Science and Technology (CiSt), 2016 4th IEEE International Colloquium on.2016, 494-499.
[8] Karger, D. R., and Quan, D., Prerequisites for a Personalizable User Interface[C], Proc. of Intelligent User Interface2004 Conf., Ukita, 2004.
[9] 郑庆华. 下一代E-Learning系统架构及关键技术[J]. 中国远程教育, 2009(24): 47-47.
[10] J. Lu, Personalized e-learning material recommender system,International conference on information technology for application (ICITA), 2004.
[11] Yong S K, Kim S, Yun J C, et al. Adaptive Customization of User Interface Design Based on Learning Styles and Behaviors: A Case Study of a Heritage Alive Learning System[C]//ASME 2005 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference. 2005: 555-559.
[12] L. Zhuhadar, O. Nasraoui, R. Wyatt, and E. Romero, Multimodel ontology-based hybrid recommender system in e-learning domain, the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology 2009.
[13] K. I. B. Ghauth, and N. A. Abdullah, Building an e-learning recommender system using vector space model and good learners average rating, Ninth IEEE International Conference on Advanced Learning Technologies, ICALT'09, 2009.
[14] Konstan J A. Introduction to recommender systems[C]//ACM SIGMOD International Conference on Management of Data,SIGMOD 2008, Vancouver, Bc, Canada, June. DBLP, 2008,1373-1374.
[15] Guo G, Zhang J, Thalmann D, et al. Leveraging prior ratings for recommender systems in e-commerce[J]. Electronic Commerce Research & Applications, 2014, 13(6): 440-455.
[16] Kovács G, Avornicului M C, Benedek B. Recommender Systems In E-Commerce Applications[J]. Management Intercultural, 2016.
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
学生天地(2020年15期)2020-08-25 09:22:02
意林·少年版(2020年2期)2020-02-18 11:14:52
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
中成药(2017年3期)2017-05-17 06:09:01
读者(2017年5期)2017-02-15 18:04:18
海外华文教育(2016年4期)2017-01-20 08:22:24
领导科学论坛(2016年9期)2016-06-05 14:59:58
继续教育研究(2014年1期)2014-02-27 16:10:08
