
基于Word2Vec的中文短文本分类问题研究①
2018-05-17 06:48王德强
计算机系统应用 2018年5期
汪 静,罗 浪,王德强
(中南民族大学 计算机科学学院,武汉 430074)
1 引言
移动终端的智能化和互联网技术的高速发展促使人们在移动互联网上交流的越来越频繁,由此产生了大量的信息数据[1],这些数据多以短文本的形式作为信息传递的载体,例如微博和即时推送新闻等,其内容通常都是简洁精炼并且含义概括,具有很高的研究价值.因此,如何通过机器对这些短文本内容进行自动分类以及对短文本所具有的丰富含义进行有效的理解鉴别已经成为自然语言处理和机器学习领域研究的热点和难点[2].
短文本自动分类首先需要将文本转化为计算机能理解处理的形式,即文本数据的表示,其对文本分类至关重要,可直接影响分类效果.传统的文本表示方法主要基于空间向量模型 (Vector Space Model,VSM),俗称词袋模型[3],该方法认为文档是无序词项的集合,丢弃了词序、语法等文档结构信息,忽略了词语间的语义关系,存在数据高维稀疏问题,对分类效果的提升存在瓶颈.于是一些学者引入外部的知识库(如搜索引擎、维基百科等)对文本进行特征扩展,丰富词语间语义关系[4,5],但其严重依赖外部知识库的质量,对于知识库中未收录的概念无能为力且计算量大、耗时长.另有部分学者挖掘文本潜在的语义结构[6],生成主题模型如LSA,pLSI和 LDA[7–9],但模型构建属于“文本”层面,缺少细节性研究.因此短文本的表示方法还有待研究.
Bengio在2003年首次提出了神经网络语言模型(Neural Network Language Model,NNLM),但由于其神经网络结构相对较复杂,许多学者在其基础上进行改进优化,最具代表性之一的当属T.Mikolov等人在2013年基于神经网络提出的Word2Vec模型[10].Word2Vec模型通过对词语的上下文及词语与上下文的语义关系进行建模,将词语映射到一个抽象的低维实数空间,生成对应的词向量.Word2vec词向量的维度通常在100~300维之间,每一维都代表了词的浅层语义特征[11],通过向量之间的距离反映词语之间的相似度,这使得Word2Vec模型生成的词向量广泛应用于自然语言处理 (Natural Language Processing,NLP)的各类任务中,如中文分词[12],POS 标注[13],文本分类[14,15],语法依赖关系分析[16]等.与传统的空间向量文本表示模型相比,使用词向量表示文本,既能解决传统向量空间模型的特征高维稀疏问题,还能引入传统模型不具有的语义特征解决“词汇鸿沟”问题,有助于短文本分类[17].但如何利用词向量有效表示短文本是当前的一个难点,目前在这方面的研究进展缓慢,常见的方法有对短文本所包含的所有词向量求平均值[18],但却忽略了单个词向量对文本表示的重要程度不同,对短文本向量的表示并不准确.Quoc Le和Tomas Mikolov[19]在2014年提出的Doc2Vec方法在句子训练过程中加入段落ID,在句子的训练过程中共享同一个段落向量,但其效果与Word2Vec模型的效果相当,甚至有时训练效果不如Word2Vec模型.唐明等人[20]注重单个单词对整篇文档的影响力,利用TF-IDF算法计算文档中词的权重,结合Word2Vec词向量生成文档向量,但其单纯以词频作为权重考虑因素太单一,生成文本向量精确度不够,未考虑文本中所含有的利于文本分类的因素的重要性,比如名词、动词等不同词性的词对于文本内容的反映程度是不同的,词性对于特征词语的权重应该也是有影响的.在上述研究的基础上,考虑到不同词性的词语对短文本分类的贡献度不同,引入基于词性的贡献因子与TF-IDF算法结合作为词向量的权重对短文本中的词向量进行加权求和,并在复旦大学中文文本分类语料库上进行测试,测试结果验证了改进方法的有效性.
2 相关工作
短文本自动分类是在预定义的分类体系下,让计算机根据短文本的特征(词条或短语)确定与它关联的类别,是一个有监督的学习过程.在自动文本分类领域常用的技术有朴素贝叶斯分类器(Navie Bayes Classifier)、支持向量机 (Support Vector Machine,SVM)、K 进邻算法(KNN)等.本文提出的短文本分类算法结合Word2Vec和改进的TF-IDF两种模型.
2.1 Word2Vec模型
Word2Vec 模型包含了 Continuous Bag of Word(CBOW)和Skip-gram两种训练模型,这两种模型类似于NNLM,区别在于NNLM是为了训练语言模型,词向量只是作为一个副产品同时得到,而CBOW和Skip-gram模型的直接目的就是得到高质量的词向量,且简化训练步骤优化合成方式,直接降低了运算复杂度.两种模型都包括输入层、投影层、输出层,其中CBOW模型利用词wt的上下文wct去预测给定词wt,而Skip-gram模型是在已知给定词wt的前提下预测该词的上下文wct.上下文wct的定义如公式(1)所示:
其中c是给定词wt的前后词语数目.CBOW模型和Skip-gram模型的优化目标函数分别为公式(2)和公式(3)的对数似然函数:

其中C代表包含所有词语的语料库,k代表当前词wt的窗口大小,即取当前词的前后各k个词语.针对NNLM输出层采用Softmax函数进行归一化处理计算复杂度较大的问题,Word2Vec模型结合赫夫曼编码的Hierachical Softmax 算法和负采样 (Negative Sampling)技术对式中的条件概率函数的构造进行优化,处理如公式(4)所示,vw和vw'分别代表词w的输入输出词向量,W代表词典大小.之后采用随机梯度下降算法对模型的最优参数进行求解.

当模型训练完成时即可得到所有词语对应的词向量,发现词向量间往往存在类似的规律:由此可以看出Word2Vec模型对语义特征的有效表达.
2.2 TF-IDF模型
词频与逆文档频率(Term Frequency-inverse Document Frequency,TF-IDF)是一种统计方法,用以评估词语对于一份文件或者一个文件集的重要程度.字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降.通俗表达的意思是如果某个词或短语在一个类别中出现的频率较高,并且在其他类别中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类[21].TF-IDF由词频和逆文档频率两部分统计数据组合而成,即 TF×IDF.词频 (Term Frequency,TF)指的是某一个给定的词语在该文档中出现的频率,计算公式如(5)所示:

其中ni, j表示词语ti在文档dj中的出现次数,分母则是在文档dj中所有字词的出现次数之和,k代表文档dj中的总词数.已知语料库中的文档总数,一个词语的逆向文件频率 (Inverse Document Frequency,IDF)可由总文档数目除以包含有该词语的文档的数目得到,计算公式如(6)所示:
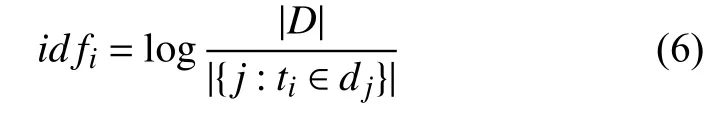
其中表示语料库中的文档总数,代表包含词语ti的文档数目(即的文档数目),如果该词语不在语料库中会导致分母为零,因此一般情况下使用由此可得出词语ti的TF-IDF权重归一化后的计算公式如(7)所示:

3 基于改进的TF-IDF算法的加权Word2Vec分类模型
短文本分类的关键在于短文本的表示,一般的做法是利用向量空间模型将文档表示为TF-IDF的加权向量,但这样得到的短文本向量往往有特征高维稀疏等问题.Word2Vec模型提供了一种独特的方法解决特征稀疏问题,而且引入了语义特征,能训练出更加丰富准确的词向量,短文本向量即可由这些包含语义关系的词向量表示.
在Word2Vec词向量的基础上,结合改进的TFIDF算法即PTF-IDF算法提出了短文本向量的表示方法及短文本分类模型.
3.1 PTF-IDF
传统的TF-IDF权重计算方法用于短文本分类时是将文档集作为整体考虑的,未体现出词性对短文本分类的影响程度,但在实际的分类过程中,不同词性的词语对短文本分类的贡献度和影响力是不同的.因此,本文考虑在TF-IDF基础上根据词语的词性引入一个贡献因子,通过调整词性的特征权重,减少噪音项的干扰,凸显特征词的重要程度,使得不同类的短文本差别更明显.
通过已有的研究可以了解到,名词、动词对文本内容的反映程度更强,更能表征文本的主题,而形容词、副词次之,其他词性的词对于短文本分类的贡献更小.文献[22]更是直接指出中文短文本主要依靠名词、动词、形容词、副词4种词性进行表达,文中给出了各种词性的词语对短文本内容的表征能力,其中动词和名词对短文本内容的表征能力最强,对分类类别具有更高的贡献度.基于此,本文引入基于词性的贡献因子与TF-IDF算法结合作为词向量的权重,改进的TF-IDF算法(PTF-IDF算法)计算公式如(8)所示:

式中,ti表示短文本中的当前词,e即为根据当前词的词性所分配的权重系数,且满足即为公式(7).
3.2 Word2Vec模型结合PTF-IDF算法表示短文本
将Word2Vec模型应用于文本分类解决了传统空间向量模型的特征高维稀疏问题和“词汇鸿沟”问题,但鉴于短文本具有篇幅短小、组成文本的特征词少等不同于长文本的特点,单个词语的重要程度显得尤为重要,因此与引入了词性贡献因子的PTF-IDF算法结合,借助PTF-IDF算法从词频和词性两方面计算短文本中词汇的权重.
Mikolov在文献[10]中指出词向量的学习不仅能学习到其语法特征,还能利用向量相加减的方式进行语义上面的计算.为了突出单个词语对文本内容的影响,考虑其词频、词性特征作为权重,可直接对短文本中的词语进行加权求和.在分类效果相差不大的情况下,相比于通过神经网络构建短文本向量具有较高的复杂度,加权求和构造短文本向量数学模型构造简单且更容易理解.对于每篇短文本其短文本向量可以表示为如(9)所示的形式:

其中,wi表示分词ti经过Word2Vec模型训练出来的词向量,通常将词向量的维数定为200,因此短文本向量同样是200维,大大减少了分类过程中的计算量.即为词语ti引入了词性贡献因子的PTFIDF权重,Word2Vec词向量乘以对应的PTF-IDF权重得到加权Word2Vec词向量.累加短文本中词语的加权Word2Vec词向量,得到短文本向量dj.
3.3 短文本分类的工作流程
对未知短文本的分类过程如图1所示.首先利用Word2Vec模型对大型分好词的语料库进行训练,将所有词语根据其上下文语义关系映射到一个低维实数的空间向量,即可获得每个词语对应的Word2Vec词向量.利用结巴分词工具对训练集中的短文本进行分词并与训练Word2Vec模型得到的词向量一一对应.结巴分词工具同样可以对分好的词语进行词性标注,根据词语的词频和词性计算PTF-IDF值,与Word2Vec词向量结合进行加权求和得到短文本向量.
很多研究表明,与其他分类系统相比,SVM在分类性能上和系统健壮性上表现出很大优势[23],因此实验选用SVM作为分类工具,根据短文本向量及其对应的标签训练出分类器.测试过程与训练过程相似,只是最后通过已训练好的分类器预测测试短文本的标签.

图1 短文本分类的工作流程
4 实验
4.1 实验数据
实验数据集来自于由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组收集发布的文本分类数据集.原始数据集共20个分类,包含文本9804篇文档,每个类别中所包含的文档数量不等.本文选取其中文档数量大于500的类别参与实验,一共包含3435篇文档,分别是艺术类、农业类、经济类和政治类,每个分类下的文档数量如表1所示.从中抽取新闻标题作为中文短文本分类数据集,并把数据集随机划分成5份,每次取其中4份作为训练集,1份作为测试集,然后把5次分类结果的平均值作为最终结果.所有20个类别的正文内容用Word2Vec模型训练词向量.

表1 数据集各类别文档数量
4.2 分类性能评价指标
分类任务的常用评价指标有准确率(Precision),召回率(Recall)和调和平均值F1.其中准确率P是指分类结果中被正确分类的样本个数与所有分类样本数的比例.召回率R是指分类结果中被正确分类的样本个数与该类的实际文本数的比例.F1是综合考虑准确率与召回率的一种评价标准.计算公式分别如下所示:


各参数含义如表2所示.

表2 分类评价指标参数含义表
4.3 PTF-IDF算法的权重系数确定
本文提出的分类模型在短文本分类问题上的准确率受PTF-IDF权重系数的影响较大.为得到较好的分类效果,需要确定PTF-IDF算法中的最优权重系数.当设置不同权重系数时,基于Word2Vec模型与PTFIDF算法结合表示的短文本向量在SVM分类器中的分类效果不同,选取分类效果最好即F1值最大时的系数值作为PTF-IDF算法的权重系数.
由于动词和名词对短文本内容的表征能力最强,因此实验中将名词或者动词的权重系数α从0.5开始取值,按的规则,采用三重循环依次以0.1的步长增大的值.部分实验结果如表3所示.
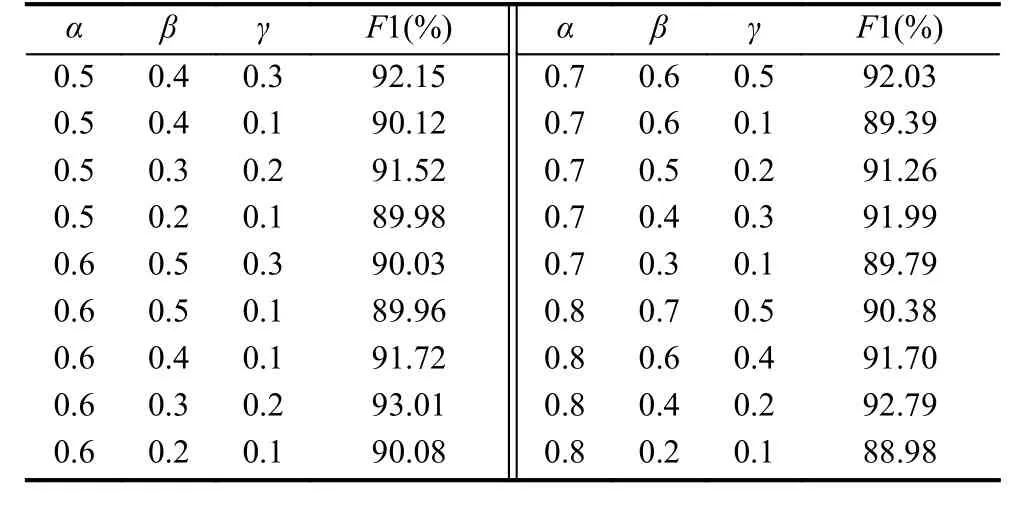
表3 F1 值与权重系数关系
实验结果显示当分别取0.6、0.3、0.2时,分类效果最好,F1 值可达 93.01%.当取 0.8、0.4、0.2 时其次,F1 值也达到 92.79%,而当三者系数相近时,如分别取0.5、0.4、0.3和0.7、0.6、0.5时类似于原TF-IDF算法与Word2Vec词向量加权求和,分类效果适中,由此也验证了引入词性贡献因子改进TF-IDF算法对短文本分类的有效性.但并不是所有的词性贡献因子的组合都能取得不错的效果,当过分看重名词和动词的权重而忽略其他词性的贡献度时结果反而差强人意.因此通过合理调整词性贡献因子组合,获得最优的词向量权重系数,可以提升短文本的分类效果.
4.4 实验对比与分析
本文将分别使用TF-IDF、均值Word2Vec、TFIDF加权Word2Vec以及PTF-IDF加权Word2Vec四种模型对实验数据集中的新闻标题进行分类.
对于TF-IDF分类模型,使用Scikit-learn提供的TfidfVectorizer模块提取文本特征并将短文本向量化.均值Word2Vec模型是计算一篇短文本中所有通过Word2Vec模型训练出的Word2Vec词向量的均值.TF-IDF加权Word2Vec模型是将短文本中词向量和对应词汇的TF-IDF权重相乘得到的加权Word2Vec词向量,累加加权词向量得到加权短文本向量化表示.PTF-IDF加权Word2Vec模型与TF-IDF加权Word2Vec模型类似,只是引入词性贡献因子改进TFIDF算法,综合考虑词性与词频为词向量赋予不同的权重,根据 4.3小节中权重系数确定的实验,将分别设置为0.6、0.3、0.2.
实验中分类算法均使用Scikit-learn提供的LinearSVM算法,所有实验采用五分交叉验证,测试结果用准确率(P)、召回率(R)、F1指标进行测评,测试结果如表4–表7所列.其中类别 C1、C2、C3、C4分别代表艺术类、农业类、经济类、政治类,avg代表C1–C4的平均值.
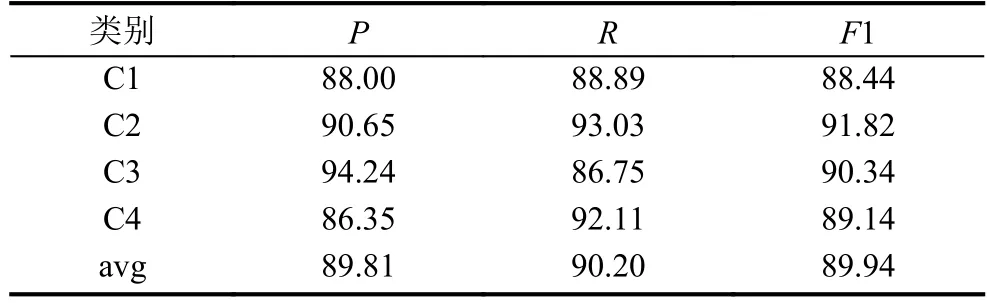
表4 TF-IDF 模型 (单位: %)
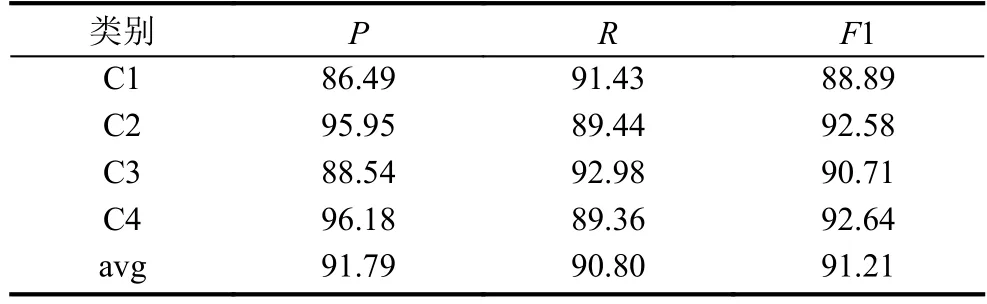
表5 均值 Word2Vec 模型 (单位: %)

表6 TF-IDF 加权 Word2Vec 模型 (单位: %)
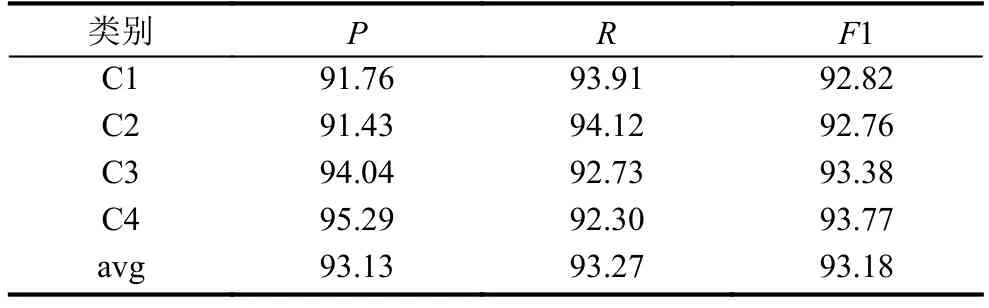
表7 PTF-IDF 加权 Word2Vec 模型 (单位: %)
由表4–表7的实验结果可以发现,均值Word2Vec模型在SVM分类器上的准确率、召回率以及F1值比TF-IDF模型稍有提升,由此也验证了Word2Vec模型应用于短文本分类的可行性以及Word2Vec模型所生成的词向量比传统模型所生成的词向量更能有效地表示文档特征.
基于TF-IDF加权的Word2Vec模型相比均值Word2Vec模型又有所提高,在SVM分类器上所有类别的平均准确率、召回率、F1值分别提升了2.08%,0.21%,1.04%.这归因于 TF-IDF 权重可以权衡Word2Vec模型生成的每个词向量在短文本中的重要性,TF-IDF加权的Word2Vec词向量使用于文本分类的短文本表示更合理准确.
本文提出的引入词性贡献因子的PTF-IDF加权Word2Vec模型较对比的分类模型效果最好,由图2也可以清楚地看出,基于PTF-IDF加权的Word2Vec模型在多数类别上均有不错的表现,所有类别的平均F1值验证了所提出的基于Word2Vec的PTF-IDF加权求和计算短文本向量表示方法在短文本分类方面的有效性.

图2 4种短文本向量表示模型分类效果比较
5 结束语
针对当前短文本向量表示方法的不足,借助Word2Vec模型的优点,将Word2Vec模型与引入词性贡献因子的改进TF-IDF算法结合,综合考虑词频和词性特征,提出了一种基于Word2Vec的PTF-IDF加权求和计算短文本向量算法,并应用于短文本分类问题,在复旦大学中文文本分类语料库上的实验表明,相较于传统的TF-IDF模型、均值Word2Vec模型以及TD-IDF加权Word2Vec模型,本算法模型有更好的短文本分类效果.但文章也有一些不足之处,数据集较少,实验中采用的类别不够丰富,后续可在多个数据集上进行验证,加强所提算法模型的可移植性; 在进行短文本向量表示时只是简单加权求和,未考虑词与词之间的顺序及位置关系,有待后续进一步的研究和实验.
参考文献
1Manyika J,Chui M,Brown B,et al.Big data: The next frontier for innovation,competition,and productivity.McKinsey Global Institute.https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-datathe-next-frontier-for-innovation.[2015-09-05 ].
2余凯,贾磊,陈雨强.深度学习: 推进人工智能的梦想.程序员,2013,(6): 22–27.
3Ling W,Luís T,Marujo L,et al.Finding function in form:Compositional character models for open vocabulary word representation.Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon,Portugal.2015.1520–1530.
4朱征宇,孙俊华.改进的基于《知网》的词汇语义相似度计算.计算机应用,2013,33(8): 2276–2279,2288.
5王荣波,谌志群,周建政,等.基于 Wikipedia 的短文本语义相关度计算方法.计算机应用与软件,2015,32(1): 82–85,92.
6Rubin TN,Chambers A,Smyth P,et al.Statistical topic models for multi-label document classification.Machine Learning,2012,88(1-2): 157 –208.[doi: 10.1007/s10994-011-5272-5]
7Dumais ST.Latent semantic analysis.Annual Review of Information Science and Technology,2004,38(1): 188–230.
8Hofmann T.Probabilistic latent semantic indexing.Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Berkeley,CA,USA.1999.50–57.
9Blei DM,Ng AY,Jordan MI.Latent dirichlet allocation.J Machine Learning Research Archive,2003,(3): 993–1022.
10Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality.Proceedings of the 26th International Conference on Neural Information Processing Systems.Lake Tahoe,NV,USA.2013.3111–3119.
11Zheng XQ,Chen HY,Xu TY.Deep learning for Chinese word segmentation and POS tagging.Proceedings of 2013 Conference on Empirical Methods in Natural Language Processing.Seattle,WA,USA.2013.647-657.
12Tang DY,Wei FR,Yang N,et al.Learning sentimentspecific word embedding for twitter sentiment classification.Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.Baltimore,MD,USA.2014.1555–1565.
13Kim HK,Kim H,Cho S.Bag-of-concepts: Comprehending document representation through clustering words in distributed representation.Neurocomputing,2017,(266):336–352.[doi: 10.1016/j.neucom.2017.05.046]
14Socher R,Bauer J,Manning CD,et al.Parsing with compositional vector grammars.Proceedings of the 51st Meeting of the Association for Computational Linguistics.Sofia,Bulgaria.2013.455–465.
15Lilleberg J,Zhu Y,Zhang YQ.Support vector machines and Word2vec for text classification with semantic features.Proceedings of the IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing.Beijing,China.2015.136–140.
16Xing C,Wang D,Zhang XW,et al.Document classification with distributions of word vectors.Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA).Siem Reap,Cambodia.2014.1–5.
17Le QV,Mikolov T.Distributed representations of sentences and documents.Proceedings of the 31st International Conference on Machine Learning.Beijing,China.2014.1188–1196.
18唐明,朱磊,邹显春.基于 Word2Vec 的一种文档向量表示.计算机科学,2016,43(6): 214–217,269.[doi: 10.11896/j.issn.1002-137X.2016.06.043]
19Turian J,Ratinov L,Bengio Y.Word representations: A simple and general method for semi-supervised learning.Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Uppsala,Sweden.2010.384–394.
20Sun YM,Lin L,Yang N,et al.Radical-enhanced Chinese character embedding.In: Loo CK,Yap KS,Wong KW,et al.eds.Neural Information Processing.Cham: Springer,2014,(8835): 279–286.
21张玉芳,彭时名,吕佳.基于文本分类 TFIDF 方法的改进与应用.计算机工程,2006,32(19): 76–78.[doi: 10.3969/j.issn.1000-3428.2006.19.028]
22黄贤英,张金鹏,刘英涛,等.基于词项语义映射的短文本相似度算法.计算机工程与设计,2015,36(6): 1514–1518,1534.
23李玲俐.数据挖掘中分类算法综述.重庆师范大学学报(自然科学版),2011,28(4): 44–47.
猜你喜欢
客联(2022年3期)2022-05-31
心理学报(2022年5期)2022-05-16
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2020年17期)2020-10-28
时代英语·高二(2018年7期)2018-12-03
人大建设(2018年5期)2018-08-16
时代英语·高二(2018年3期)2018-06-06
证券市场红周刊(2018年3期)2018-05-14
电脑爱好者(2017年7期)2017-05-06
