
基于机器学习的知识推送系统实现
2018-05-16 12:43中国运载火箭技术研究院研究发展中心
航天工业管理 2018年4期
/中国运载火箭技术研究院研究发展中心

中国运载火箭技术研究院自2011年开展知识管理工作以来,积累了大量宝贵的知识资源。但总体而言,知识的使用效果不佳,70%的知识都处于闲置状态,历史积累的知识资源难以有效发挥其应有的价值,不可避免地导致了运载火箭型号研制效率低、周期长、成本高,在国际航天领域难以发挥持续的竞争优势。针对火箭高密度研制和发射的紧迫形势,有必要借助机器学习方法实现高价值知识的智能挖掘与推送,提升知识质量,提高利用效率,促进知识驱动的运载火箭设计生产模式快速形成。
笔者结合运载火箭知识库的特点,对现有的机器学习算法进行优化改进,从用户模型数据特征、兴趣模型构建、用户兴趣更新机制及推荐算法几个方面进行详细分析,以实现基于用户行为的知识推送。
一、用户模型数据特征
用户模型数据主要是指与用户的兴趣、特征、偏好相关的数据,这些数据的提取是模型数据准备的过程,主要为用户兴趣模型的建立作准备。数据特征提取总体上可以分为显式信息提取和隐式信息提取,显式信息主要包括用户岗位信息(部门、专业、密级、职位、职称、技术能力)、用户检索行为(用户现行搜索)和用户订阅行为(用户订阅词);隐式信息主要包括用户检索行为(历史查询行为)和用户知识行为(用户浏览、用户评分、用户上传、用户下载、用户收藏、用户标签)。
笔者主要采用隐式信息提取,此种方式无需用户的主动参与,而是由系统在不打扰用户使用的情况下跟踪用户浏览行为自动获取的。用户在网页中的浏览行为实质上是客户端与服务器端交互的过程,客户端可用 Ajax、JavaScript 等技术记录用户的浏览行为,如用户的收藏、打印操作、滚动条的滚动速度等,利用用户的浏览内容和浏览行为挖掘用户的兴趣爱好;服务器端则可以通过服务器日志记录用户的IP、ID、访问页面、访问时间等。
针对研究院知识管理系统,用户行为特征获取主要包括用户浏览、用户评分、用户上传、用户下载、用户收藏、用户标签和历史查询行为。对用户知识行为进行分类,其中A表示用户上传、用户下载、用户收藏、用户标签的行为集合,B表示用户评分行为的行为集合,C表示用户浏览行为的行为集合。对上述行为按照图1的流程进行逻辑处理,即可获取用户当前的兴趣关键词(见表1)。

图1 用户行为特征提取业务逻辑图

表1 用户行为特征提取数据流程
二、兴趣模型构建
1.兴趣模型的表示方法
用户兴趣模型是知识推荐系统的关键部分之一,模型的好坏直接关系到推荐系统的质量。实际上兴趣模型是一种数据结构,它的表现形式直接决定用户模型反映用户兴趣爱好的能力和模型的可计算能力。
基于向量空间模型(VSM)的表示法把用户的兴趣模型表示成一个n维的特征向量{(t1,w1),(t2,w2)…(tn,wn)},用以表示用户感兴趣的方面以及对这一方面感兴趣的程度。其中,ti(1≤i≤n)表示兴趣特征项,wi(1≤i≤n)表示特征项ti在模型中的权重,代表用户对兴趣项ti的感兴趣程度,以下简称兴趣度。
模型中的兴趣度可以是表示用户兴趣的关键词,基于向量空间模型的表示法能够反映不同的兴趣项在用户兴趣模型中的重要程度,且便于后期项目资源的匹配计算。
2.兴趣模型的构建流程
用户兴趣模型的构建逻辑如图2所示,用户兴趣模型的数据流程见表2。
三、兴趣模型更新
用户兴趣模型中的每个用户实例不是固定不变的,随着用户使用系统的行为以及兴趣的不断变化,用户实例也会相应变化,需要在一定的时间内进行更新。因此,在用户模型构建过程中需要充分考虑用户的兴趣随着时间变化而改变的因素,保证用户模型的时效性。
1.用户模型更新方法设计
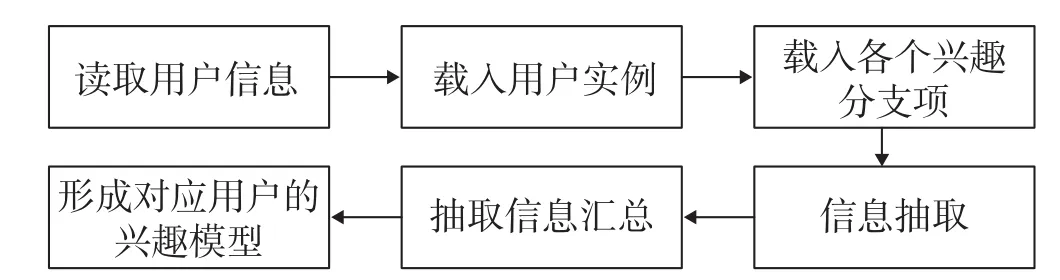
图2 用户兴趣模型构建的业务逻辑流程
实现用户模型的时效性有2种方法:一是全局数据方法,每次知识推送需要用到用户实例时扫描数据库,将用户实例需要的数据重新计算一遍,该方法可以保证数据的实时性,用户实例随着用户兴趣数据变化而实时变化,但是计算任务大且耗时,很大程度上会影响系统的效率;二是基于模型的方法,只需扫描一次数据库就可以把所有用户实例计算完,后续需要用到用户实例时可以直接调用,不需要再计算,但一次性计算的用户模型会产生严重的滞后效应,需要对模型进行整体周期性更新。
此处采用上述2种方法的融合,利用基于模型的方法整体计算便捷、调用方便以及全局数据方法实时性的优点,弥补前者训练代价高和后者计算任务大的缺点,实现了用户模型的更新,执行方法如图3所示。
首先,系统周期性地进行模型计算,当系统符合定时更新系数、到达定时更新时间时,系统会自动检测兴趣已变动的用户,将变动的用户实例计算完成后存入数据库,以方便调用;然后,系统对每个用户实例进行监控,如果某个用户实例中的兴趣点更新变动系数超过阈值,则对该用户实例进行全局数据计算,并将结果存入数据库。
2.用户模型更新模块设计
一是用户模型定时更新模块。用户模型定时更新流程如图4所示,当系统到了定时更新时间,系统会自动检测所有用户的兴趣状态,包括4个维度对应的信息修改情况,然后把修改的用户归入更新用户集,未修改的用户不进入更新流程,以减少整体更新时所做的重复计算。系统针对更新用户集进行每个用户实例的兴趣计算,并将计算后的用户实例归入到用户模型中,形成更新后的用户模型。

表2 用户兴趣模型数据流程
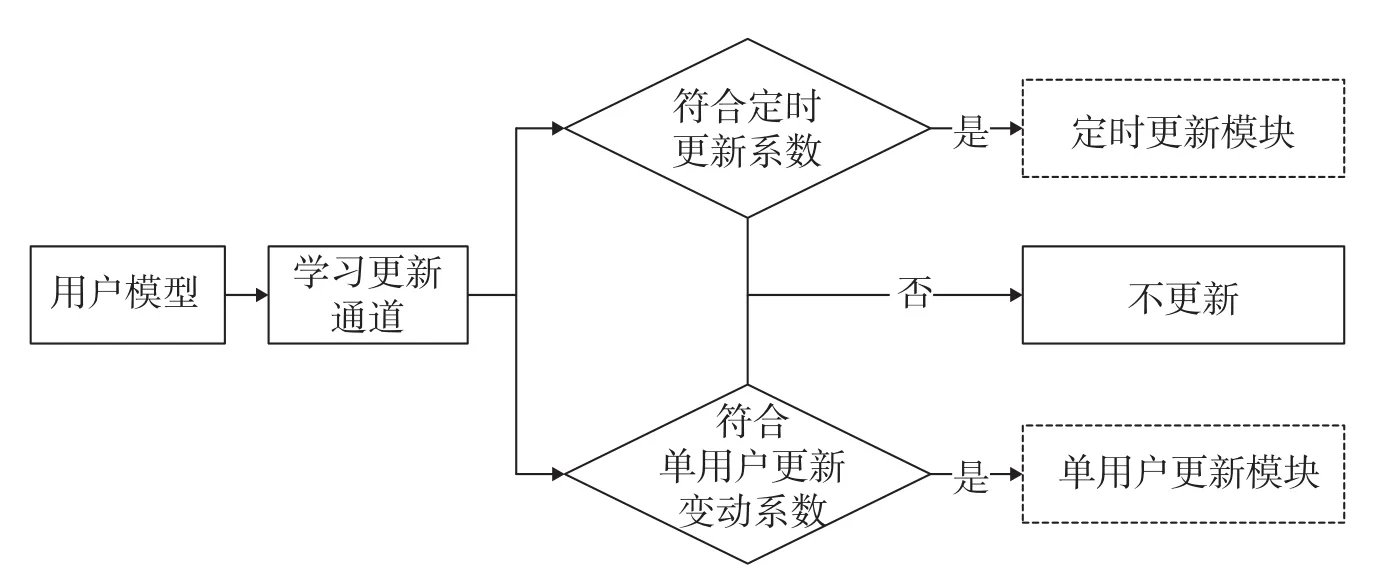
图3 用户学习更新流程

图4 用户模型定时更新流程
二是单用户更新模块。单用户更新比定时更新情况复杂,有多种情况进行触发,分为时间触发更新、数量触发更新和行为触发更新,具体过程如图5所示。
时间触发更新。当用户操作未涉及某个兴趣知识概念超过一定时间后,需要运用遗忘函数对其进行知识概念兴趣度分析,如果用户对该知识概念的兴趣度低于预定的阈值,则需要删除该兴趣点。
用户知识概念兴趣度的计算可以采用概念熟悉程度计算公式,该公式基于记忆遗忘规律,提出记忆受时间和被记忆内容的双重影响。计算用户知识概念兴趣度的公式可以转变为:

其中,yc表示用户对兴趣知识概念c的兴趣度,兴趣度随时间变化不断下降最后稳定下来;表示权重,用于调节兴趣度随时间增长而下降的快慢;wc为兴趣知识概念c在用户实例兴趣分支中的权重;为某知识从被快速遗忘到基本不再变化的转折点,一般情况下取值10天。
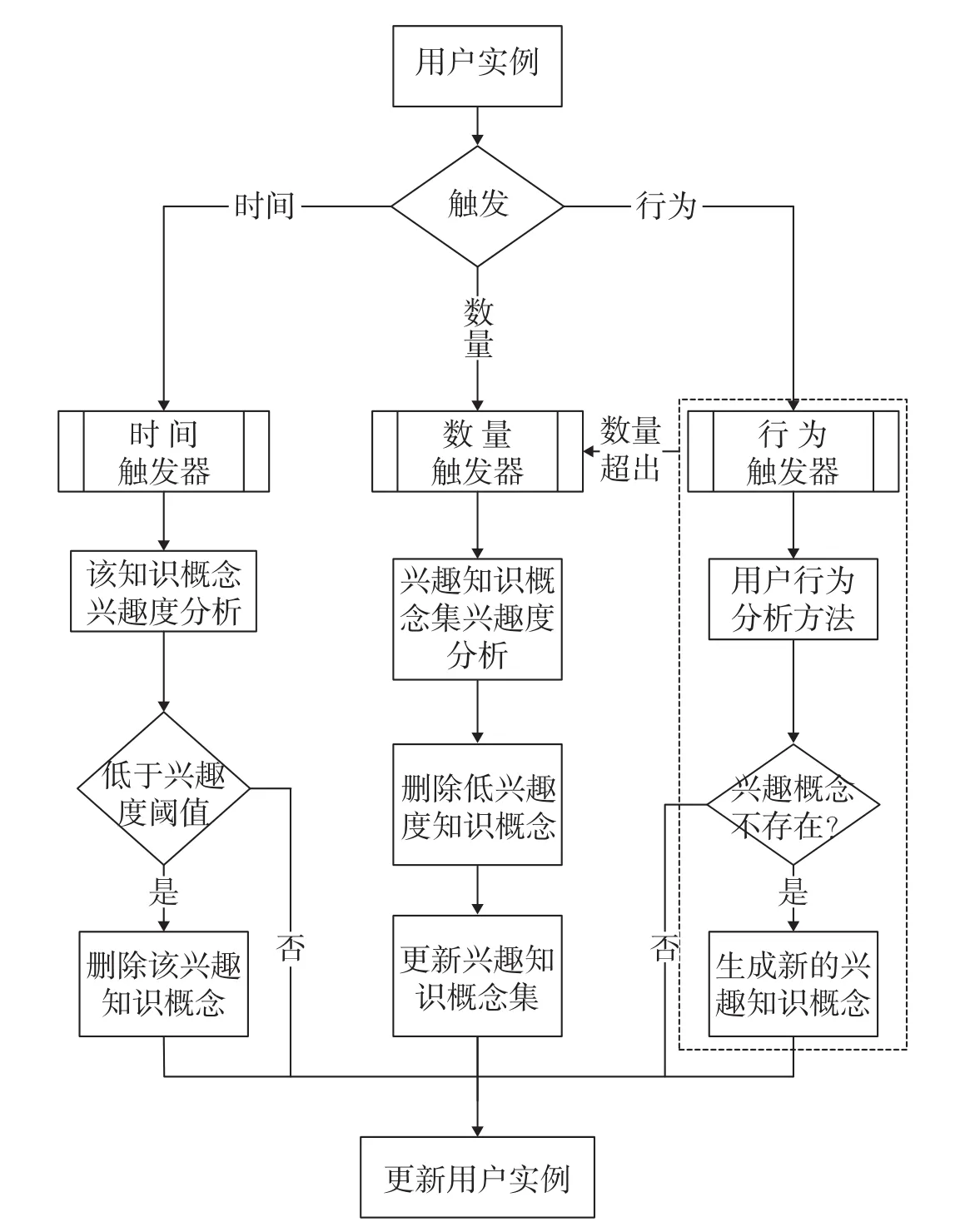
图5 单用户更新过程
数量触发更新。由于行为触发等原因造成兴趣分支知识概念数超出限度时,需要对兴趣分支上的所有知识概念进行兴趣度计算分析,对兴趣度低的知识概念进行删除清理,形成新的知识概念集(知识概念数目为限度数目),更新兴趣分支。
行为触发更新。用户拥有兴趣用户实例后,其新的兴趣知识概念随着用户使用知识管理系统后不断产生变化,系统会根据现有用户行为通过行为分析方法形成新的兴趣知识概念,如果兴趣知识概念已经存在,则对其进行数据更新。
四、推荐算法
目前,主流的个性化推荐算法包括基于人口统计学的推荐、基于内容的推荐、协同过滤推荐。其中,基于内容的推荐方法凭借其模型构建相对容易、个性化推荐效果好的优势在文本相关领域得到了广泛应用。该方法利用知识项的属性特征,并将用户对其选择过的项目的评价作为源数据,不需要使用其它用户的数据,仅根据用户自身的兴趣爱好作推荐,因此不存在用户—项目评分矩阵稀疏的问题,能够为拥有特殊兴趣爱好的用户作推荐。
在基于内容的推荐系统中,知识项被定义成一个特征表示向量,而这些特征选取的好坏直接关系到推荐系统的质量。针对文本类的内容,特征可借助信息技术进行自动提取,也可以人为定义,推荐系统根据用户评价过的项目的特征学习用户的兴趣,并生成用户的兴趣文件,然后通过匹配兴趣文件找到与该用户兴趣相似度最高的知识。
知识推送的业务逻辑流程如图6所示,知识推送数据处理流程见表3。
目前,基于机器学习的知识推送模型已应用于中国运载火箭技术研究院的知识管理系统中,为用户提供知识个性化推荐。通过对设计人员的操作行为进行记录,并结合设计人员的专业背景等相关数据进行分析,将知识库中的知识资源分类处理并推送到个人空间中,从而减少了用户的知识检索成本,提高了知识资源利用率,有效增加了知识管理系统的用户黏度。▲
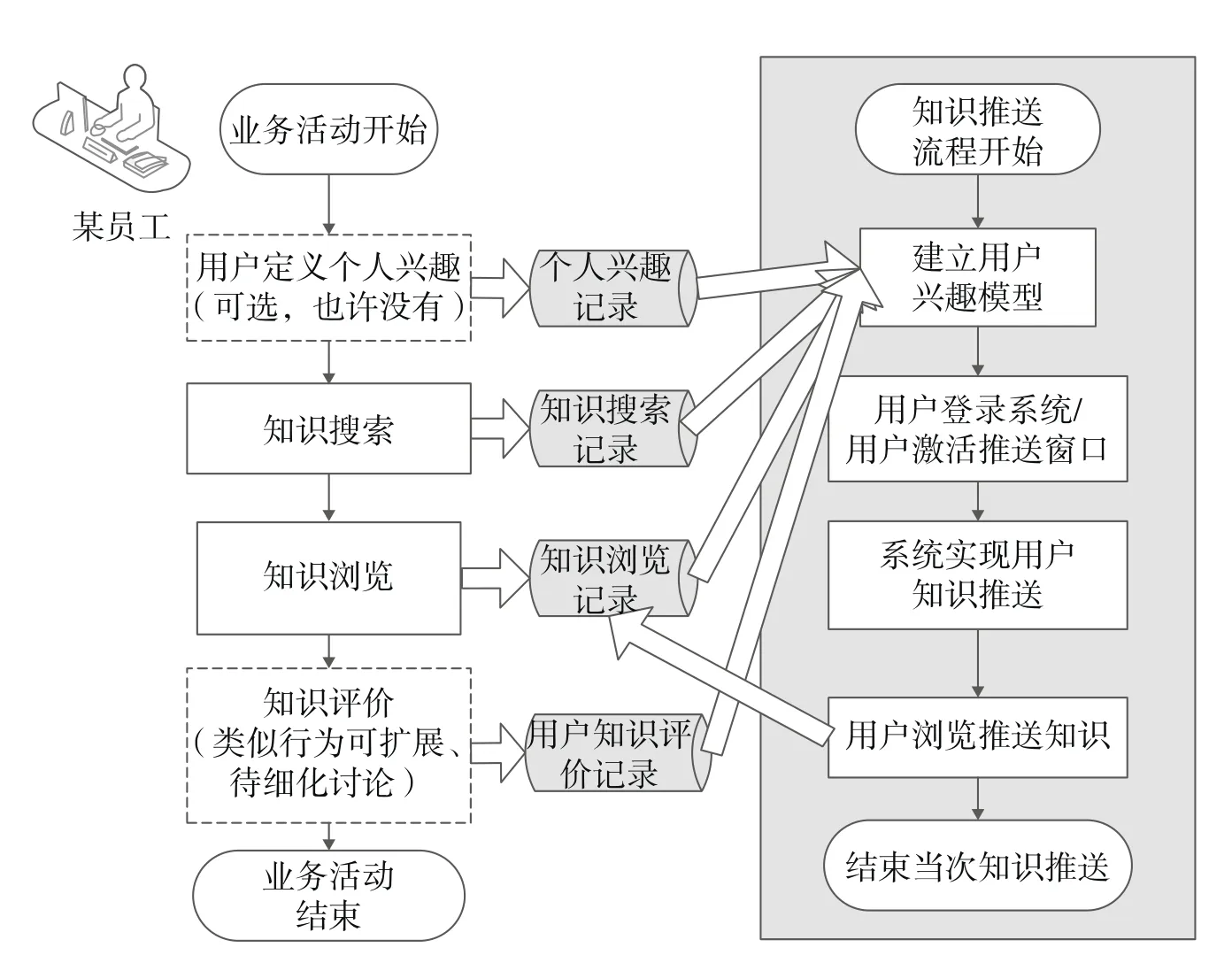
图6 知识推送业务逻辑流程图

表3 知识推送数据处理流程
猜你喜欢
现代装饰(2022年1期)2022-04-19
今日农业(2021年10期)2021-07-28
现代装饰(2020年2期)2020-03-03
ViVi美眉(2019年8期)2019-09-10
中学生数理化(高中版.高一使用)(2018年9期)2018-10-09
劳动保护(2018年5期)2018-06-05
高校招生(2017年7期)2017-06-30
初中生世界·八年级(2016年8期)2016-05-14
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
