
Narrative Science:讲述隐藏在数据中的故事
2018-05-15 08:17陈铭徐丽芳
出版参考 2018年2期
陈铭 徐丽芳
摘要:机器擅长数据分析,人类更倾向于阅读故事而不是去分析大量复杂的数据。Narrative Science是一家提供自然语言处理服务的科技公司,可以帮助客户分析海量数据之间的关系,并转化为简明凝练、具有可读性的文本。凭借优质的、不断拓展更新的产品和服务,该公司超越最初的出版传媒市场,为其他行业需要分析和理解大量数据的用户提供基于自然语言的数据分析文本服务。毋庸置疑,随着自然语言处理技术的突破,人工智能将进入更多高级人力劳动的领域。
关键词:Narrative Science
2017年1月,麦肯锡全球研究所(Mckinsey Global Institute)发布的报告《可实现的未来:自动化、就业和生产力》显示,目前人类所从事的一半职位有望在2055年实现自动化。随着时代的不断进步和发展,尤其是人工智能的出现,技术将逐渐取代一些需要思考能力和创造能力的高级人力劳动。
叙事科学(Narrative Science)是美国一家自然语言处理(NaturalLanguage Processing,NLP)服务提供商(公司Logo见图1),但它并不只是为客户提供简单的自动化写作服务。目前,计算机强大的运算能力可以将许多复杂的数据图形化,却很难将数据以自然语言输出一篇人性化的故事呈现在人们眼前。Narrative Science所提供的服务是将海量数据或图表输出为生动有趣且极富洞察力的故事内容,其首席技术官克里斯蒂安·哈蒙德(Kristian Hammond)始终强调:“Narrative Science是在进行真正的创作,绝不是基于文本库的生搬硬套。”毫无疑问,Narrative Science正在重新設定人们对于人工智能的期望,其先进的自然语言处理技术也意味着机器已经开始深度学习更多人脑思考的领域。
一、Narrative Science的成长与扩张
2010年,Narrative Science正式成立,其创办灵感来源于美国西北大学创新实验室里一项有趣的人工智能技术——统计猴(StatsMonkey)。和当下流行的写作机器人小冰一样,Stars Monkey可以自动撰写报道,从网页中抓取棒球比赛的数据信息,并在12秒内生成一篇生动的新闻故事传达赛况、比赛得分和胜率概率等。同年,Narrative Science的创始人斯图尔特·弗兰克尔(Stuart Frankel)联合哈蒙德共同研发出同名人工智能写作软件后,在美国中央情报局的相关机构如In-Q-Tel(美国非营利性质的风险投资机构,专门投资高新技术公司,旨在推动最新信息技术的应用以支持美国的情报处理能力)的大力支持下,公司正式开始商业运作。
Narrative Science起初只被应用于美国西北大学棒球比赛等体育赛事的即时报道,后来逐渐开展财经报道业务。2011年,NarrativeScience先后被《纽约时报》等知名媒体所报道,在科技创意公司中崭露头角。2014年,它获得1000万美元融资,投资方包括联合服务汽车协会(Tlle United Services AutomobileAssociation)和巴特利风险投资公司(BatteryVentures)等。截至2017年4月,该公司共完成6轮3240万美元的融资,与瑞士信贷、福布斯(Forbes)以及美国政府部门在内的机构建立了合作关系。Narrative Science最有力的竞争对手自动洞察公司( Automatedlnsights)因自感无法与Narrative Science直接展开竞争,将服务目标客户定位于小型报刊。短短几年,Narrative Science迅速扩张业务版图,客户范围囊括北美、欧洲等全球各大地区的金融服务公司、互联网企业和政府机构,一跃成为业界的领军者(见图2)。
1.技术核心:将数据变成可读的人性化文本
数据已经渗透到当今的每一个行业和业务职能领域,并成为重要的生产因素。但是,如果数据没有得到充分的智能化处理,人们无法有效吸收大量数据中所包含的信息和知识,那么这些数据就是无用的。目前,大多数知识工作者和消费者都面临着处理海量数据并做出正确决策的挑战。NarrativeScience希望借助计算机技术帮助用户解读数据,并将之转化为可读性较强的文字传递给用户;即使是一些不熟悉高等数学和逻辑结构等数据分析知识的客户,也能迅速地获得数据中隐藏的关键信息。哈蒙德表示:“凡是数据存在的地方就应该有故事,写作机器人的价值在于充当数字与故事之间的中介。”
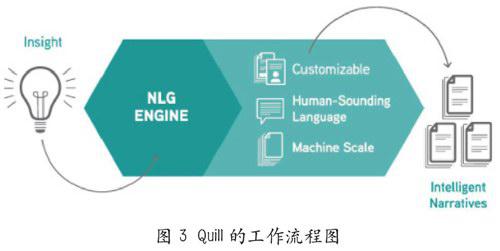
“鹅毛笔(Quill)”是Narrative Science旗下的主要产品,具备强大的读写和叙事功能,可以自动将大量复杂的数据或图表转化为凝练且富有洞察力的自然语言,还允许客户定制叙述故事的语气。Quill采写故事的过程分为四步(见图3):首先,搜集大量高品质数据以建立一个庞大的数据库,例如财经领域所涉及的每股收益、股价变化等数据。其次,在海量数据中借助算法筛选出具备讲述价值的数据,即一些偏离常态的“异常数据”。Narrative Science内部有一个能进行编辑判断的系统,将许多写作的价值都内置于系统的算法中。再者,选择故事的叙事结构,Quill会根据数据的重要性对各种可能的叙事角度进行排序,形成文章的整体架构。最后,把要描述的数据嵌入到系统提供的“元模板”中。“元模板”是由Narrative Science雇用一批训练有素的文字工作者创造的写作风格和手法,联合计算机工程师一起“培训”机器写作能力而形成的。在利用“元模板”组织文章时,机器通过词汇库组建句子得到最后的故事。例如,Quill在分析一组有关易贝(Ebay)集团投资收益下降的数据时,生成的报道包含如下文本: “该公司的整体会计风险评估为业内平均水平以下,股价在过去的一个月里持续下跌,但对投资收益未来的调整可持乐观态度。”这让投资者可以避开那些晦涩难懂的数据和图表,直接从Quill提供的文字中了解Ebay在会计层面的细微变化趋势。机器擅长分析数据,人类则更擅长阅读。Narrative Science的独特之处就在于满足了人们倾向于阅读故事的心理。
2.市场定位:超越媒体市场,聚焦多领域大数据业务
好的技术本身并不足以成就一家成功的公司,它必须根植于适当的市场土壤中。Narrative Science在刚起步时致力于开拓媒体业务,和其他提供自动化写作服务的公司一样,专门为一些媒体机构和内容出版机构提供产品和服务。对于初创时的Narrative Science而言,出版传媒行业就是一个现成的市场,报纸新闻、杂志甚至是在线出版物都需要自然语言处理工具,尤其是体育和财经报道,Narrative Science可以将记者从单调且重复的工作中解放出来。目前,包括福布斯网站、专门出版建筑类杂志的汉利伍德出版社( HanleyWood)以及體育新闻网站美国十大联盟(The Big TenNetwork)在内的多家知名媒体都选择使用NarrativeScience的产品。福布斯还在网站上专门设置了由NarrativeScience所生成的新闻网页。
在掌握新闻报道的写作艺术之后,Narrative Science意识到他们的技术在其他行业能拥有更大的机会。事实也是如此,任何需要分析和理解大量数据的公司都有可能是它的目标客户。随着一些金融服务公司和政府情报机构频频抛出橄榄枝,Narrative Science改变了战略方向,将业务重心从出版传媒市场转移到各个领域的大数据业务。Quill所使用的自然语言处理技术依赖于大量高质量数据,而金融服务公司和政府情报机构拥有丰富的数据资源,以及改善与客户沟通的迫切愿望。2017年2月,美国财务信息服务公司辉盛(FactSet)将Quill工具整合到其客户报告的分析平台中。作为一家金融服务提供商,FactSet为金融专业人士如投资银行家等提供金融数据和分析服务。Quill的加入使其客户端在季度财务报告发出的第一天就可以自动生成点评报告,所覆盖的报告规模有望呈指数型增长,报告的客观性和风格的一致性得到了很大提升。如今,Narrative Science的产品被许多国家和地区的数据服务提供商采用,其中包括业界领军的大数据咨询公司厄耐勒迪斯额( Analytics8)和商业智能服务提供商比茨数据( BizData)等。Narrative Science成功地从一家面向出版传媒市场提供服务的“长尾媒体”公司转型为一家编写和销售商业软件的技术提供商,聚焦金融等领域的大数据业务,为用户提供自然语言处理方面的创新性服务。
3.产品形态:不断更新,提供丰富的产品服务
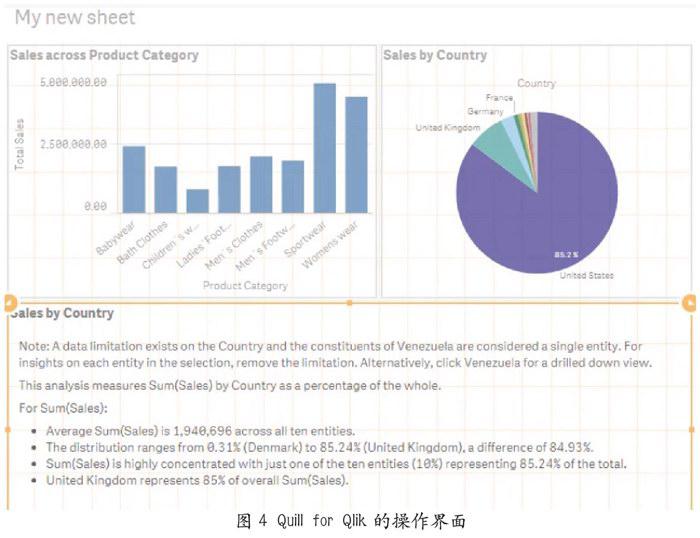
在扩大市场的同时,NarrativeScience也不断创造和优化面向大数据服务的软件工具,以满足不同客户的需求。Quill是它的第一代主流产品。2014年3月,Narrative Science在Quill的基础上推出Quill Engage。这是一款免费的谷歌分析(Google Analytics,GA)软件,可以简单凝练地表达被分析对象的关键指标和业绩表现,如网站内容的关注度、网络访问量等,还可以通过分析历史数据预测行业的走向和趋势。2016年,Narrative Science与视觉分析软件供应商柯利克(Qlik)进行合作,推出Quill系列的第三代产品——Quill for Qlik。行业分析师塞斯·格里姆斯(Seth Grimes)表示: “这是一次商业智能领域突破性的创新。”Quillfor Qlik可以弥补可视化工具在解释大量数据之间复杂关系时的不足,通过自然语言文本让终端客户更容易识别不同数据集之间的关系(见图4)。图4是Quill for Qlik分析各国销售总额占比的饼状图。文字中条列的数据包括各类产品的销售总额、销售总额占比的最小值、销售总额占比的最大值、极差和集中度等。其中,销售总额直接反映各国的消费需求,极差反映各国销售总额的离散幅度和波动范围,而相对集中度则折射出各国与相对规模的差异。这些极具说服力的数据被转化为平白浅近的文字。此外,用户可与Qilk可视化工具生成的图表进行交互,选择特定的数据范围进行重点分析。其次,这款工具可以减少原先负责生成报告和向客户解释数据的中层管理人员人数,让高层管理人员直接与客户进行互动,有利于实现公司的扁平化管理。
除了对旗下的主打产品Quill进行升级改造,Narrative Science还借助Quill的高级自然语言处理平台推动其他面向不同客户需求的软件开发。微软的PowerBI(Business Intelligence,商业智能)是一套用于分析数据和共享见解的商务分析工具,包括各种可拓展的可视化图表。2016年,Narrative Science和微软合作推出Narrative for Power BI。它可以从一系列数据源(包括Salesforce、Github和Adobe Analytics)中提取有效信息,自动生成书面语言。微软PowerBI总经理尼克·卡德维尔(Nick Caldwell)认为: “Narrative for Power BI符合微软对BI的期望,它兼具强大的数据分析和可视化功能,同时更易于理解。”2017年9月,Narrative Science与智能工具开发公司画面软件(TableauSoftware)联合推出Narrative for Tableau。这是一款免费的谷歌Chrome扩展程序,可自动创建Tableau图形的叙述性书面说明。此外,Narrative Science旗下的产品还包括服务于BI领域的套件产品等。由此可见,Narrative Science利用自然语言处理技术为各个行业中需要和数据打交道的人群提供了有力的工具。
二、自然语言处理工具的发展趋势
通过Narrative Science的发展可以看出,自然语言生成技术已经渗透到多个领域中,孵化出诸多新形态的产品和服务。自然语言处理技术属于人工智能的一个分支,包括自然语言理解和自然语言生成两个方面。目前的自然语言处理工具还达不到完全取代人工的水平,人们也还不能准确预测其最终发展态势和结果,但仍可以对其发展趋势有一个简单的判断。
(1)在文本理解方面,从浅层分析迈向深度理解。由于算法的局限,机器人暂不能对文本进行准确又深入的分析。此外,不是所有文化现象都能像物理科学那样在算法中被规则量化,即使是以挖掘最具洞察力数据闻名的Narrative Science,也不能保证每一次的文本分析都是有足够深度的。随着算法的不断迭代和数据库的不断扩大,计算机基于深度神经网络强大的“记忆力”以及提取复杂特征的能力,可以得出更精准的判断。谷歌等科技巨头也已经开始对机器人进行“阅读理解”培訓,以深入探索自然语言理解技术,促进自然语言理解工具从浅层分析迈向深度理解。
(2)在文本生成方面,由事实性文本到情感文本。现在的自然语言生成工具大多被用来生成一些事实性的新闻报道或文字报告,因此许多自然语言处理工具背后的科学都被认为是非人性的和机械的。工程师试图让自动化文本变得更加人性化,就像Narrative Science的初衷——旨在利用自然语言处理工具等先进的技术来缩小人类和机器之间的交流缺口(communication gap)。一些学者在研究时,尝试将人文主义方法和计算机算法整合为一种新的文本生成方法,将语调和情绪等交流元素与自然语言处理工具相结合,让机器人不仅拥有推理和归纳能力,还具有明确的态度和立场,从而实现从事实性文本向富含情感、体现人性的文本转变。
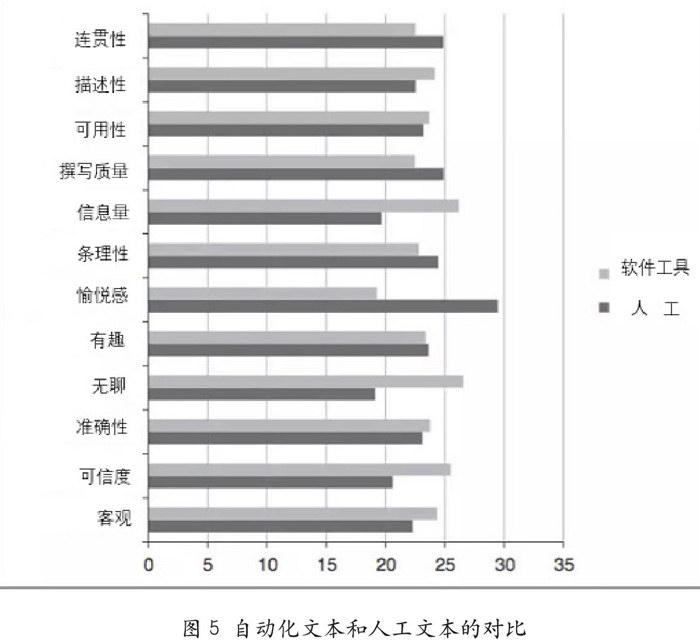
(3)人机协作将成为业界未来的发展趋势。瑞士卡尔斯塔德大学的研究表明,自动化文本更具描述性,信息量较大且更客观可信。但是,在可读性方面不如人类所写的文章质量高,阅读的愉悦感较弱(见图5)。虽然自然语言处理工具的进步一定会推动自动化文本朝人工文本的水准逼近,但完全替代并不是短期内能够实现的。人工参与必不可少;而智能工具的存在,也并不完全是对人工的威胁。找到人工和机器的平衡点,两者相互配合,才能从一个“弱人工智能时代”进入“强人工智能时代”。自然语言处理工具已经成为一种有效的信息表达手段。由计算机撰写的文章逐渐从原先的边缘化位置抵达各个领域的数据分析场域,即由为传统媒体机构和出版商提供简单重复劳动转向社交媒体和其他领域的大数据业务。正如Narrative Science -直在做的两件事:了解数据中的信息,并为特定受众提供有用的可读性文本。自然语言处理技术将越来越能胜任需要认知能力的活动。
参考文献: 1. Narrative
Science [EB/OL]. [2017-10-22].https://narrativescience. com/.
2.Mckinsey Global Institute. A futurethat works: Automation, employment, andproductivity [EB/OL]. [2017-10-22]. https://www.mckinsey.com/.
3.Alex Woodie.Your Big Data Will Read ToYou Now[EB/OL].[2017-10-23].https://www.datanami. com/2014/10/28/big-data-will-readnow/.
4.霍伊特·朗,苏真.文学模式识别:文本细读与机器学习之间的现代主义[J].林懿,译.山东社会科学,2016 (11):34-53.
5.Mike Pham.AI needs a human touch tofunction at its highest level[EB/OL]. [2017-10-23].https://venturebeat .com/2 01 7/09/21/ai-needsa -human-to uch-to-function-at-its-highestlevel/.
6.唐伟胜.认知叙事学视野中的叙事理解[J].外国语,2013 (4):28-36.
7.慧博.深度学习成NLP发展新引擎,深层次认知将是未来突破方向[EB/OL]. [2017-1031]. http://pg.jrj.com.cn/acc/Res/CN_RES/INDU S/2 017/10/31/eb94785f-92b4-448d-b2446220cef9b332.pdf.
8.李阳辉,谢明,易阳.基于深度学习的社交网络平台细粒度情感分析[J].计算机应用研究,2017,34(03):743-747.
猜你喜欢
民用飞机设计与研究(2020年4期)2021-01-21
小太阳画报(2020年11期)2020-12-10
小太阳画报(2020年10期)2020-10-30
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
电子制作(2018年18期)2018-11-14
读者(2017年18期)2017-08-29
山东工业技术(2016年15期)2016-12-01
小学教学参考(2015年20期)2016-01-15
语文知识(2014年1期)2014-02-28
