
应用CUDA的数字全息三维粒子位移场并行重建及实现
2018-05-10 09:19:24朱岗,杨岩
重庆理工大学学报(自然科学) 2018年4期
朱 岗,杨 岩
(重庆理工大学 机械工程学院, 重庆 400054)
传统并行计算需要使用者有较高的专业素质,多数是命令行的操作,不适宜于普通研究人员的开发。2006年,英伟达公司推出了统一计算设备架构CUDA(compute unified device architecture),它是以GPU(graphics processing unit)作为数据并行计算设备的软硬件体系。与传统的网格和集群等并行架构相比,GPU的并行不仅表现出节能、体积小、性价比高等优势,而且加速比更优。目前,CUDA已广泛应用于科研和工程应用等领域,包括视频与音频处理、医学成像、物理效果模拟、流体力学模拟、光线追踪、CT图像重组、石油天然气勘探、产品设计、计算生物学和地震分析等[1~7]。
在数字全息测量中,对特定平面波前的重建是通过计算机对光波的模拟衍射来实现的,特别是在如流场分析等多焦平面对象的重建过程中,必须对每个不同记录距离的平面进行计算。重建平面越多,其轴向分辨率越高,计算结果越准确,但是整个计算过程也更加耗时。为了提高计算速度,使重建过程能达到实时重建的目标,国内外研究人员已经采用了多种手段来提高计算速度。在单平面重建方面,Shimobaba等[8]利用GPU进行单平面的实时重建,获得一幅512像素×512像素全息图的重建像的时间为41.6 ms。朱竹青等[9]构建了实时数字全息再现系统,以旋转的骰子为对象,实时拍摄全息图,并进行单平面重建,重建帧速为20帧/s,重建图大小为512像素×512像素。
在多平面快速重建方面,Abe等[10]采用16个FPGA实现全息图的快速重建,其系统能在3.3 s时间内对1 024像素×1 024像素全息图进行100个平面的重建。Cheong等[11]通过硬件加速与软件优化相结合的方法来优化系统,重建一副200像素×200像素的图像仅需要3 ms,若采用3个独立的计算线程则处理速度可以达到8 帧/s。
本研究的目标是利用GPU的并行计算能力开展数字全息中多焦平面目标的快速重建,并将其应用于流体流场的实际测试中。
1 基本原理
1.1 数字全息基本原理
数字全息包括光学记录和数字再现2个阶段。数字全息光学记录是利用CCD记录参考光波与通过物体的反射或透射物光波干涉形成的全息图。在光学重建中,若采用参考光的共轭光波照射全息图,则实像出现在原物体的位置,而虚像出现在CCD相反方向的相同距离处。菲涅尔-基尔霍夫衍射实像平面的光场分布为[12]
O(ξ,η)=
(1)
(2)

重建平面与全息平面位置关系如图1所示。
在数字重建中有菲涅尔衍射重建算法、卷积重建算法、角谱重建算法和小波重建算法等多种方法。卷积重建算法由于分辨率与全息图相同,无衍射距离限制,计算速度快,因此受到广泛应用。
令:
g(ξ,η,x,y)=
(3)
那么,式(1)则变为
O(ξ,η)=
(4)
在数字重建中,数字脉冲响应函数为
g(k,l)=

(5)
这样,利用卷积的性质有:
(6)
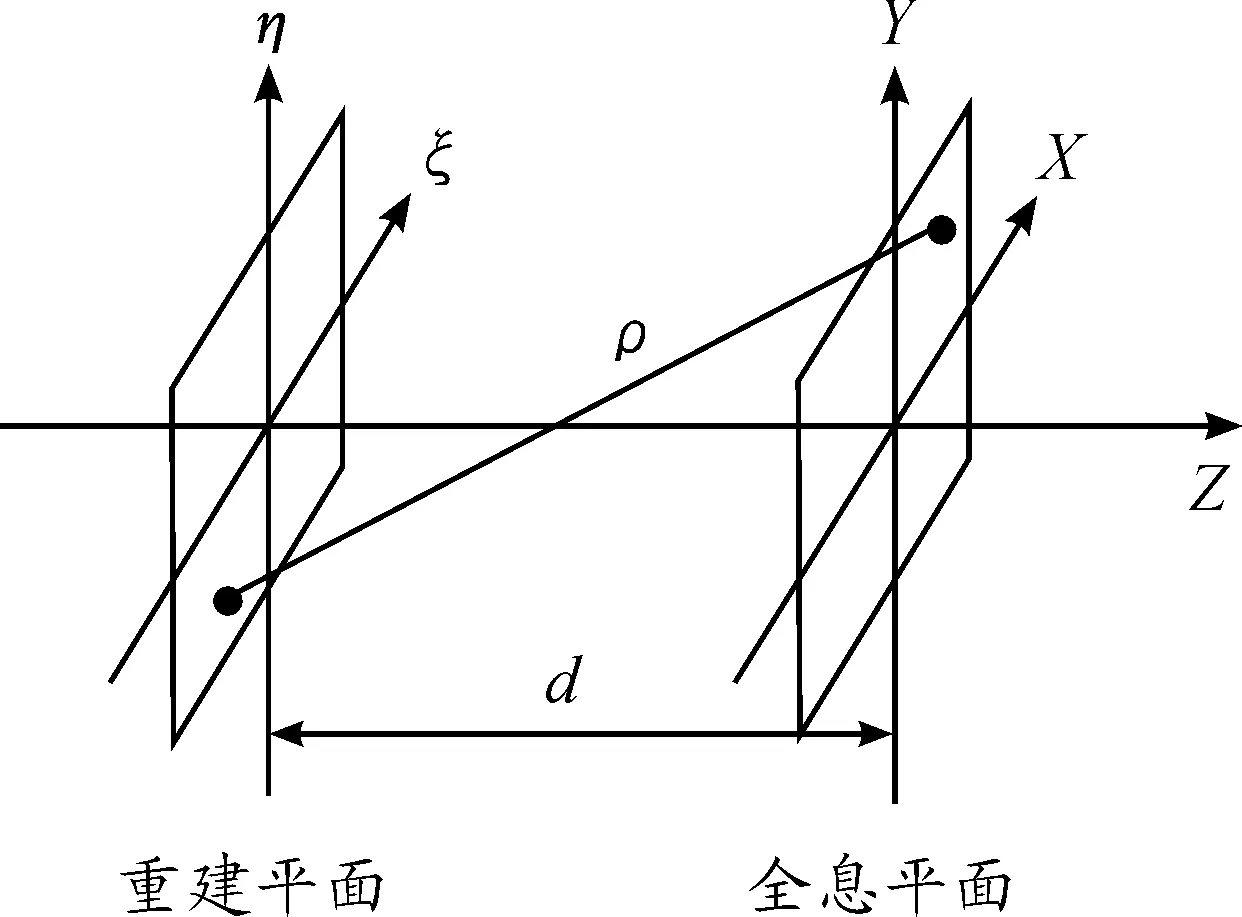
图1 重建平面与全息平面位置关系
1.2 并行计算
CUDA 是一种基于新的并行编程模型和指令集架构的通用计算架构,其结构上包括主机端与设备端。CPU被称为主机端,GPU被称为设备端,GPU作为CPU的协处理器。在计算任务分配中,在CPU上执行逻辑性强的串行计算任务,在GPU上执行大量的并行计算任务。
设备代码在设备端GPU上执行,被称为内核(kernel),内核不是一个完整的程序,而是任务中能分解为并行执行的步骤的集合。每个内核函数包括2个层次的并行,即网格中线程块间的并行和线程块内线程间的并行。当运行至设备代码时,调用内核函数,启动多个线程。每个线程块都包括多个线程,对不同的数据并行执行同一指令(SIMD),实现线程块内的并行。同时,在每个线程网格中,不同线程块间也并行执行。每个线程具有私有的寄存器和板载局部存储器,同一线程块内线程具有片内共享储存器。所有线程均能访问全局、常量和纹理存储器。GPU包括多个流多处理器(SM),每个流多处理器又包含大量的流处理单元(SP)。线程以块为单位分配到流多处理器上,随后线程块内的线程又被发送到流处理单元。线程调度器可以自动根据线程块的数量和每个线程块的线程数将1个或多个线程块分配到1个流多处理器(SM)中。流多处理器(SM)中以32个线程组成一个warp作为最小的调度和执行单位。CUDA编程模型如图2所示。
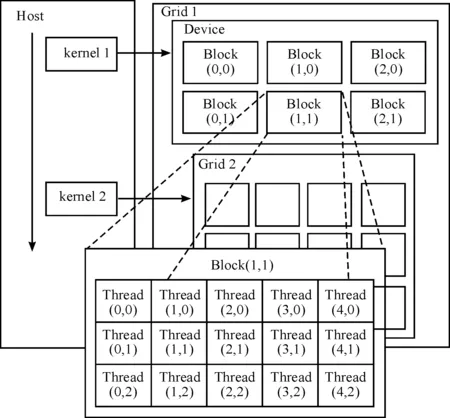
图2 CUDA编程模型
2 实现方法
2.1 三维粒子位移场串行计算
利用CPU进行流体位移场计算的基本步骤如下:① 在获得了t1时刻的全息图之后,需要在光轴方向进行多个平面的数值重建,对每个重建像均需要进行图像滤波、二值化、粒子三维空间位置提取。同时,在完成多个平面的粒子提取之后,还要进行重复粒子删除处理,以获得t1时刻粒子三维空间位置。② 对t2时刻的全息图进行相同的处理,获得t2时刻粒子三维空间位置。③ 对相邻2个时刻的2幅全息图所提取的粒子进行粒子配对,获得t1和t2时刻粒子的位移矢量场。通过除以拍摄间隔时间,还可以获得三维速度矢量场。具体流程如图3所示。从该流程中可以发现整个处理过程是利用CPU串行执行的,这样将会花费大量的计算时间,无法达到程序的实时处理要求。

图3 位移矢量场获取流程
2.2 利用GPU实现程序并行化
在流体的位移矢量场计算过程中,在获得某时刻的全息图后,需要利用数值计算程序对不同重建距离的图像进行数字聚焦。不同距离的多个重建图像的数值计算过程相互独立,为并行计算的开展提供了可行性。为了实现流体中位移场的快速并行计算,除了需要采用GPU硬件之外,还需要对原有Matlab程序进行并行化处理,以便发挥GPU的并行计算能力。整个并行计算过程主要包括执行粗粒度的并行与细粒度的并行2个层次。
2.2.1 粗粒度的并行化
粗粒度的并行主要包括1张全息图多个不同位置的图像并行处理与2个连续全息图序列执行的并行。如果计算卡具有多个GPU,则可以利用多线程技术控制多个GPU,每个GPU又分别设置多个流。即利用状态机实现多个流同时进行不同距离的多个平面的数据处理,实现三维粒子速度场并行重建。具体执行过程如下:
1) 利用第1个线程的hallo流在第1个GPU上对t1时刻所获得的全息图进行二维离散傅里叶变换等预处理。
2) 将结果以异步方式发送给其他线程控制的GPU。
3) 多个流在多个GPU上进行多个不同位置的图像并行处理(包括图像重建、滤波、二值化、连通域处理等)。
4) 各个流等待同步。
5) 利用第1个GPU的hallo流对t2时刻所获得的全息图进行二维离散傅里叶变换等预处理。同时,利用第2个GPU的“0”号流完成t1时刻全息图的重复非聚焦粒子删除、粒子配对等后处理。
6) 第1个线程的hallo流,将t2时刻全息图的预处理结果以异步方式发送给其他线程控制的GPU。
7) 各个GPU的多个流(除第2个GPU上的“0”号流外)进行多个不同位置的图像并行处理。
8) 第2个GPU上的“0”号流完成t1时刻的后处理后,首先查询t2时刻的多个不同位置的图像并行处理是否完成。如果完成,则所有流同步;如果未完成,则转入查询t2时刻全息图的预处理结果是否收到。如果t2时刻的预处理尚未收到,则等待;如果预处理已收到,但是多个不同位置的图像的并行处理尚未完成,则其加入图像的并行处理。
9) 各个流等待同步。
10) 利用第1个GPU的hallo流对t3时刻所获得的全息图进行二维离散傅里叶变换等预处理。同时,利用第2个GPU的“0”号流完成t2时刻全息图的重复非聚焦粒子删除、粒子配对等后处理。
11) 重复执行上述步骤,完成全息图序列的处理。
具体流程如图4所示。

图4 利用状态机实现位移场重建程序设计
2.2.2 细粒度的并行化
细粒度的并行主要是指将核函数分为多个Block处理,利用大量的核并行计算。细粒度的并行化需要将滤波、二值化、连通域提取、删除非聚焦重复粒子等多个原有串行执行的程序进行并行处理,以便能在GPU上运行。
这里,以删除非聚焦重复粒子为例,说明如何对串行程序进行并行化处理。利用CPU从tn时刻全息图提取到粒子位置及大小信息,这些粒子既包括了聚焦粒子,也包括了离焦粒子。为了将离焦粒子删除掉,按照粒子重建图像的规律,以二值化后获得的粒子大小信息为判断准则。如果2颗粒子的三维空间位置的欧式距离小于3倍粒子直径,则认为它们是同一颗粒子的聚焦像或者离焦像,并认为粒子面积较大的粒子为聚焦粒子,而面积较小的粒子为非聚焦粒子,此时保留聚焦粒子的信息,删除非聚焦粒子的信息。如果采用CPU对重复粒子进行删除,那么串行算法是从第1颗粒子开始,往后进行逐一比较,直到与最后一颗粒子进行比较,完成第1颗粒子的比较循环,然后继续从第2颗粒子开始依次跟后面的粒子进行比较。如果获得了n颗粒子,若利用CPU串行计算,其循环次数为M,其计算效率非常低。
M=(n-1)·(n-2)·(n-3)…3·2·1=
(n-1)!
(7)
如果采用GPU进行并行计算,可以将n颗粒子分为J组,每组有N颗粒子。这样每一组的粒子序号分别为1~N,N+1~2N,…(J-1)N~JN。将粒子序号按组从左向右排列,同时将粒子序号从上往下排列,形成一个二维矩阵,如图5所示。这样横坐标中任意一组(第x组)便可以跟纵坐标中的任意一组(第y组)同时进行比较。具体运行中将其化为一个Block块,其总的Block块数为
B=J+(J-1)+(J-2)…+3+2+1=
(8)
在一个Block内,横坐标为第x组,其粒子序号为(x-1)N~xN,纵坐标为第y组,其粒子序号为(y-1)N~yN,能分别进行同时比较。具体在GPU运行中,可以利用一个SM中的多个ALU进行并行计算。这样可以大大提高计算效率。

图5 删除重复粒子并行计算模型
3 实验
为了分析重建平面数量、分辨率对重建速度的影响,分别配置了基于CPU和GPU的3种硬件系统,以比较其计算速度。具体实验装置配置如下:
1) Window7系统,Matlab r2014a软件(用于CPU测试),CPU型号为Inter(R) Core(TM) i7 CPU 930(多核并行),48G内存;
2) 1片Nvidia Tesla 40C;
3) 1片Nvidia Tesla K80。
K40C具有1个开普勒架构核心(GK110),开启了15组流多处理器,具有2 880个流处理器,专用存储器总容量为12 GB,显存带宽为288 GB/s,其单精度计算能力可达4.29万亿次/s,而双精度计算能力可达1.43万亿次/s。K80采用了2个开普勒架构核心(GK210),每一个核都只开启了15组流多处理器阵列中的13组,即K80具有4 992个流处理器,显存是2组384位的GDDR5,容量为24 GB,其单精度计算能力可达8.74万亿次/s,而双精度计算能力可达2.91万亿次/s。
实验主要从重建平面数的变化及重建像分辨率的变化2方面进行。
3.1 重建平面数对重建速度的影响
固定分辨率为512像素×512像素,重建平面数从500幅开始,每次增加100幅,直到1 000幅。通过CPU与GPU分别进行多焦平面重建,分别获取其运行时间,得出GPU的加速效果,即加速比。运行时间如表1所示。运行时间曲线如图6所示。

表1 不同重建平面数量3种系统运行时间对比 s
由表1可知:在不同的重建平面数时,采用GPU并行计算的效率均远高于CPU,特别是在重建平面数为1 000时,K80、K40C和CPU930的重建时间分别0.866、1.8和180.733 s。随着重建幅数的增加,K40C加速比从84倍增加到100倍,而K80含2片GPU,对K40C的加速比维持在2倍左右。每增加100幅,CPU运算时间延长20~30 s,而K40C在大约200 ms以内,K80在大约100 ms以内,差异浮动比较小。

图6 3种系统运行时间与重建平面数的关系
3.2 重建像分辨率对重建速度的影响
重建平面数取为512幅,实验采用的全息图分辨率为1 296像素×966像素,故实验选择从512像素×512像素分辨率开始,每次增加128像素×128像素,直到896像素×896像素。不同分辨率对重建时间的影响如表2所示。运行时间曲线如图7所示。

表2 不同分辨率对重建时间的影响 s
由表2可知:随着全息图的分辨率大小的增加,CPU运算时间急剧增加;GPU相对变化差异小,尤其是K80。
综上所述,GPU相对于CPU来说,不仅运算速度快,并且运算性能更平滑,时间范围更具可控性。
3.3 维粒子位移场并行计算测试
实验光路如下:氦氖气体连续激光器发出波长为632.8 nm的激光(索雷博HNL210L-EC),通过针孔滤波器进行滤波,再通过准直镜(西格玛 DLB-30-300PM)形成平行光,通过装有纯净水的样品池,其光程为10 mm,在其中散布有直径为51.7 μm的三聚氰胺甲醛树脂微粒(武汉华科微科)。其同轴全息图被CCD(BOBCAT ICL-B1310)接收,CCD的分辨率为1 296像素×966像素,像元3.75 μm,其记录距离为21.5~31.5 mm。图8为拍摄的三聚氰胺甲醛树脂微粒的同轴全息光路示意图,图9为某时刻拍摄到的三聚氰胺微粒的数字全息图。

图7 3种系统运行时间与重建分辨率的关系

图8 同轴粒子场光路示意图

图9 三聚氰胺全息图
将并行程序用于实际三维流体的全息图的快速重建实验中。利用个人笔记本电脑进行计算,其处理器为Core i5-4210U@1.7 GHz,内存为8 GB,操作系统为Windows 10,软件为Matlab(r2014a)。截取512像素×512像素的全息图,完成512个重建平面的速度场计算需要10.9 s。为了实现快速计算,利用计算统一设备架构,将工作站作为主机,选用K80作为设备端,其处理器为Xeon E5-2630@2.3 GHz,内存为64 GB,操作系统为Windows 7,软件为Visual studio 2014。采用单线程单GPU计算时间需要0.46 s,而采用双线程双GPU则其计算时间为0.268 s。运行时间如表3所示,获得的位移场分布如图10所示,高度方向已折算为10 mm粒子深度范围所对应的像素数量。

表3 个人电脑与带GPU的工作站计算时间比较 s

图10 微粒的位移矢量图
通过以上结果可知:利用并行重建方法能正确获得流体中示踪微粒位移矢量场;在图像分辨率为512像素×512像素、重建512个平面时,利用K80采用双线程双GPU的速度比采用CPU的速度快40倍,其全息图的处理速度达到3.7帧/s。
4 结束语
利用基于CUDA的架构将原有串行的重建步骤进行二级并行化处理。同时结合多线程技术实现数字全息图粒子3维位移场的快速重建。并将其应用到实际获得的全息图序列中,其处理的单幅全息图为512像素×512像素,重建512个平面的时间为268 ms,即3.7帧/s,运算速度为采用CPU进行串行计算的40.6倍。
通过测试发现,每个GPU设置不同的流的数量对实验结果也有影响。分别将流的数目设置为4、8和16,发现当流的数目设置为8时,其运算速度最快。另外,如果减少重建平面的数量,增加GPU的数量或者采用更高性能的计算卡,那么其处理全息图的帧率可以得到进一步提升,完全可能达到对全息图进行实时处理的要求。
参考文献:
[1] 卢文龙,王建军,刘晓军.基于CUDA的高速并行高斯滤波算法[J].华中科技大学学报(自然科学版),2011,39(5):10-13.
[2] 朱奭,常晋义.基于CUDA的数字化放射图像重建算法[J].计算机应用研究,2014,31(5):1577-1580.
[3] 江顺亮,黄强强,董添问,等.基于CUDA的离散粒子系统模拟仿真及其实现[J].南昌大学学报(工科版),2011,33(3):290-294.
[4] 周煜坤,陈清华,余潇.基于CUDA 的大规模流体实时模拟[J].计算机应用与软件,2015,32(1):143-148.
[5] 岳田爽,赵怀慈,花海洋.基于CUDA的光线追踪优化算法研究与实现[J].计算机应用与软件,2015,32(1):161-162.
[6] 王珏,曹思远,邹永宁.利用CUDA技术实现锥束CT图像快速重建[J].核电子学与探测技术,2010,30(3):315-320.
[7] 刘金硕.基于CUDA的并行程序设计[M].北京:科学出版社,2016.
[8] SHIMOBABA T,SATO Y,MIURA J,et al.Real-time digital holographic microscopy using the graphic processing unit[J].Opt Express,2008,16(16):97035.
[9] 朱竹青,孙敏,聂守平,等.基于GPU 的数字全息实时再现系统设计及实验研究[J].光电子·激光,2012,23(3):325-329.
[10] ABE Y,MASUDA N,WAKABAYASHI H,et al.Special purpose computer system for flow visualization using holography technology[J].Opt Express,2008,16(11):94254.
[11] CHEONG F C,SUN B,DREYFUS R,et al.Flow visualization and flow cytometry with holographic videomicroscopy[J].Opt Express,2009,17(15):109416.
[12] ULF S,WERNER J.Digital Holography[M].Heidelberg:Springer,2005.
猜你喜欢
军事文摘(2022年8期)2022-05-25 13:29:10
少儿美术(2019年11期)2019-12-14 08:09:12
环球市场(2017年36期)2017-03-09 15:48:21
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:43
发明与创新·中学生(2015年9期)2015-09-05 10:58:36
发明与创新(2015年34期)2015-02-27 10:40:21
中国记者(2014年9期)2014-03-01 01:45:37
河南科技(2014年8期)2014-02-27 14:07:49
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
物理与工程(2010年2期)2010-03-25 10:02:00
