
一种多列特征图融合的深度人群计数算法
2018-05-10 01:47唐斯琪张梁梁潘志松
郑州大学学报(理学版) 2018年2期
唐斯琪, 陶 蔚, 张梁梁, 潘志松
(中国人民解放军陆军工程大学 指挥控制工程学院 江苏 南京 210007)
0 引言
随着城市人口的急剧膨胀,“超级城市”的数量日益增加,大型高密度集会场景日益增多,人群的聚集行为呈现出频率越来越频繁、规模越来越大的特点,对城市安防系统带来巨大的困难与挑战.为及时有效地处理海量监控数据,预防事故发生,降低公共场所安全隐患,人群密度估计技术已经成为智能安防领域的研究热点[1].人群密度估计算法的目标就是通过一定技术手段,估计出整个图像范围内人群中的个体数目.其主要有两个基本框架:全局人数回归框架和密度图回归框架.文献[2-6]采用全局人数回归框架,其中影响人群密度估计精确度的主要因素在于特征提取方法与回归模型的选取.不同特征例如像素特征[3]、集成特征[5]、LBP特征[6]等,以及不同的回归模型例如线性模型、岭回归、 高斯过程回归[5]、神经网络[7]等都取得了较好效果.虽然整体回归框架简单方便且有利于隐私保护,但由于没能充分利用人群空间信息,其在密集场景下的估计准确性难以满足需要.为利用人群空间结构信息,文献 [8]提出密度图回归框架,将物体计数问题转化为密度图的回归问题.文献[9-10]延续这一思路,利用随机森林模型提升估计准确性.卷积神经网络模型以其高度的非线性表达能力有效提高了分类、检测、分割等传统任务的效果.文献[11]首次利用卷积神经网络模型(Patch CNN)进行密度图回归,有效提高了人群密度估计任务的准确性.在此基础上,文献[12]构建端到端的密度图回归网络,并利用三列具有不同大小卷积核的卷积神经网络(MCNN)提升了人群密度估计算法的效果.文献[13]利用长短不同的2个网络将浅层特征与深层特征进行融合,有效提高了网络应对多尺度问题的能力.
人群密度估计在本质上是行人目标的感知与检测问题.为解决遮挡问题,本文采用基于行人头部的密度图回归方式.为解决投影效应造成的多尺度目标问题,需要模型具备感知多尺度目标的能力.因此,开放场景下的人群密度估计需要解决的核心问题在于多尺度目标和小目标的感知.针对多尺度、小目标的感知问题,本文提出了一种基于特征图融合的卷积神经网络(feature map fusion convolutional neural network, FMFCNN)的人群密度估计算法.特征图融合能够将底层的细节信息更好地保留到高层,有利于对人头这类小目标进行感知.同时,特征图融合有效丰富了信息流动的路线,通过等效集成更多网络以感知多尺度目标.实验结果表明,该算法有效提高了密集开放场景中人群计数的准确性.
1 三列卷积神经网络
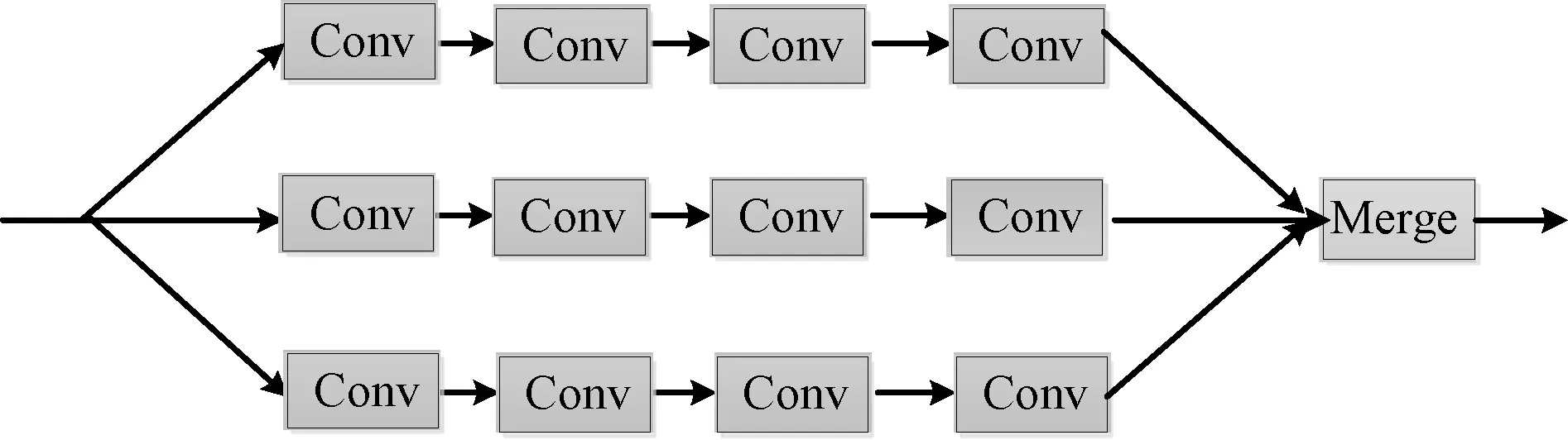
图1 三列卷积神经网络结构Fig.1 Structure of three-column convolutional neural network
为应对人群密度估计问题中的多尺度问题,文献[12]首次提出将具有不同感受野的三列网络的特征进行融合,三列卷积神经网络结构如图1所示.由于每个感受野能够感知一定尺度范围内的目标,因此将3个网络得到的结果通过卷积层进行融合,能够有效扩展网络感知目标的尺度范围.在此基础上,本文不仅考虑到人头目标具有的多尺度特点,同时考虑到人头目标的小目标感知问题.由于三列卷积神经网络中经过非线性变换后得到的高层特征图包含更多的语义信息,却在一定程度上损失了细节信息,不利于对小目标的准确感知.因此,本文提出运用特征图融合的方式,综合利用底层特征图与高层特征图,一方面可以保留更多细节信息以实现对小目标的感知,另一方面也可以潜在集成更多网络以应对目标多尺度问题.
2 特征图融合的多列卷积神经网络
2.1 网络结构
网络的输入为图片帧,监督信息即为通过标注目标位置计算得到的密度图.网络通过综合特征图后连接的具有1×1×1卷积核的卷积层,实现从综合特征图到人头密度图的回归,得到一副灰度图作为网络输出的估计密度图.直接对估计密度图上各处的值进行积分,即可以得到整幅图片中的人数,其网络结构如图2所示.
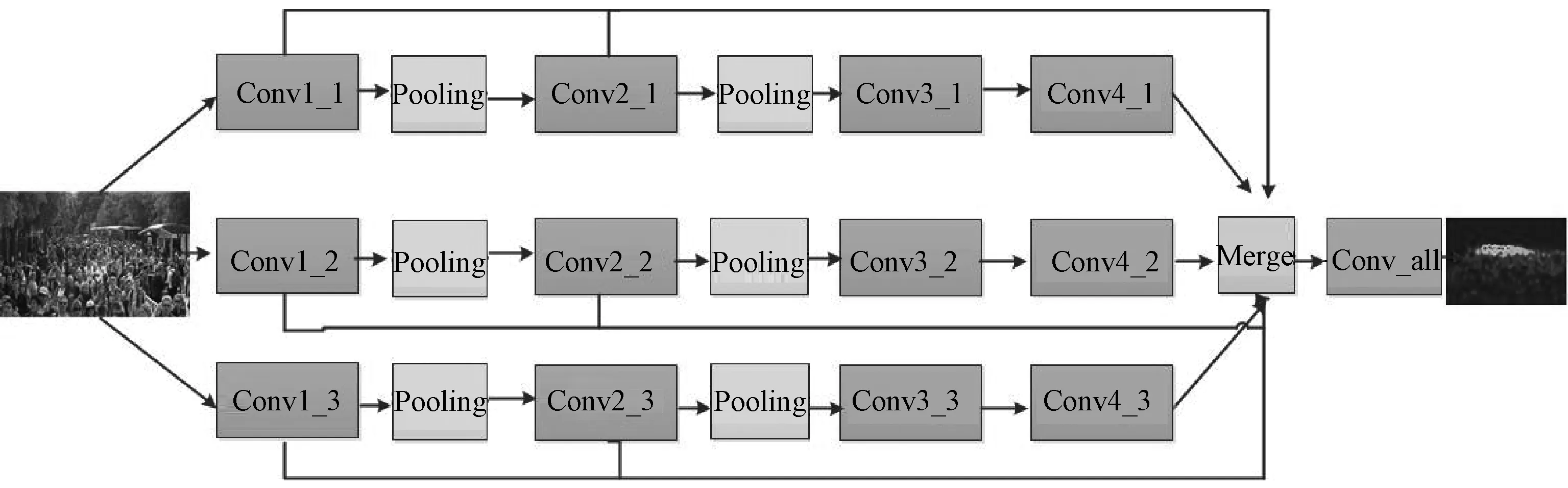
图2 特征图融合的三列卷积神经网络结构Fig.2 Structure of feature map fusion three-column convolutional neural network
由于任意密集开放场景中,摄像机高度不同、角度不同以及摄像过程中的透视效应,行人目标尺度差异较大且目标往往较小.因此,感知多尺度的小目标是任意场景人群密度估计要解决的重点问题.首先,为应对小目标感知问题,本文利用特征图融合的方法,丰富高层特征图中的细节信息,提升人头目标的感知效果.其次,单一的网络结构往往只能有效感知处于某一尺度范围内的目标,三列网络也往往只能感知有限的几类尺度的目标.本文通过对多列网络中的底层特征图与高层特征图的融合,成倍提高潜在集成的基础网络个数,从而提高对多尺度目标的感知效果.网络的激活函数采用修正线性单元(Relu)函数,并选择最大下采样机制,网络中各卷积层配置情况如表1所示.
2.2 特征图融合
在卷积神经网络中,下采样层的存在与逐层抽象的网络结构,使底层特征图主要感知图像的边缘、角点等细节局部信息,高层特征图主要反映对整个目标的感知信息,从而由底层到高层逐步建立起对目标从局部到整体的感知.但对于小物体检测[14]、语义分割等对空间位置敏感且细节要求较高的任务,由于高层特征的细节信息保留不足,会导致识别精度较低、分割边缘粗糙等问题.在基于卷积神经网络的人群密度估计中,存在以下问题:① 高层神经元的感受野一般范围较大,高层特征图包含更多粗糙语义信息,但缺乏细节信息,导致模型对较小人头目标感知能力较差.② 模型集成数量不足,难以解决由于透视效应造成的人头目标多尺度问题.因此,本文将每列网络的第一、二个特征图进行拼接融合,并利用融合后的总体特征图进行密度图回归.进行特征图融合后,分析网络的信息流动方式可以发现,每列网络潜在集成了3个网络(例如第一列网络集成了Conv1_1->Conv2_1->Conv3_1->Conv4_1,Conv1_1->Conv2_1和Conv1_1),集成的模型数量是文献[12]三列网络的3倍.

表1 卷积层结构配置
综上,通过特征图融合,一方面可以兼顾高层语义信息与底层细节信息,使融合的特征包含更加丰富的信息;另一方面可以有效提升模型集成效率,使模型集成更多子模型,从而更好地涵盖目标可能的尺度,提升模型对多尺度目标的感知效果.
2.3 密度图的计算
由于高密度场景中行人躯干存在严重的遮挡,而人的头部不容易发生重叠.因此,头部比躯干更适合作为网络卷积核识别的目标.本文采用基于人头的密度图作为网络的监督信号,密度图中每个人头目标用一个圆形高斯核表示,高斯核的中心位于人头目标的中心位置,将图片中所有人头目标对应的高斯核按此方法叠加在一起即可得到整幅图片的密度图.若整幅图像上的目标集合为T={t1,t2,…,tN},目标ti的头部中心坐标为(xi,yi),用来代表人头的高斯函数为
(1)
式中:σi为目标ti对应的高斯核参数.在密度图上可以用一个冲击响应函数与高斯核函数的乘积代表此目标,即
P(ti)=δ(x-xi,y-yi)Gσi(ti).
(2)
则具有N个目标的图片对应的密度图可以表示为
(3)
式中:δ(x,y)为二维冲击函数.本文选择全局统一的高斯核参数对密度图进行计算.
3 实验结果与分析
3.1 评价指标
选择平均绝对误差(MAE)、平均相对误差(MRE)、均方根误差(MSE)作为模型的评价指标.
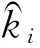
3.2 数据集
在Shanghaitech[10]和WorldExp10[11]这2个大规模开放密集场景人群计数数据集上测试本文提出的方法.Shanghaitech数据集是任意场景人群数据集,共有标注了330 165个人的1 198张图片,它由 Part A和Part B两个部分构成,其中Part A来自互联网图片,Part B来自上海街头的监控视频帧.WorldExp10数据集收集自上海世博会园区内的108个监控摄像头,共有标注了199 923个人的3 980张图片.
3.3 对比实验
为比较本文提出的基于特征图融合的多列卷积神经网络(FMFCNN)模型对复杂开放环境下人群密度估计的效果,利用全局人数回归算法、基于卷积神经网络的密度图回归算法这两类算法进行对比实验.全局人数回归算法分别采用LBP特征、HOG特征和Gabor特征,并利用最小二乘支持向量机(LSSVM)非线性回归模型训练.基于卷积神经网络的密度图回归算法分别参考文献[11]和[12]中提出的网络模型.
3.4 网络收敛效果
为研究特征图融合对网络收敛效果的影响,本文也训练了不融合特征图的三列网络.在Shanghaitech数据集Part A部分中,特征图融合对测试损失、训练误差的影响结果如图3所示.
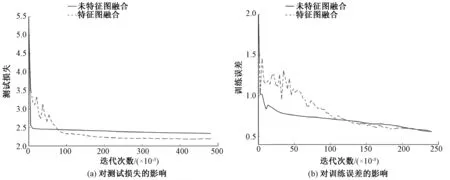
图3 特征图融合对测试损失、训练误差的影响Fig.3 Effect of feature map fusion on test loss and train loss
从图3可以发现,不进行特征图融合的网络收敛更早.图3(a)显示其收敛后的测试损失比进行特征图融合的网络约高12.5%,相比不进行特征图融合的网络结构,特征图融合的网络能收敛到更好的局部最优点.另外,观察图3(b)可以发现,特征图融合的网络在前50 000次迭代过程中,训练误差下降不稳定,这是由于在网络收敛的早期,特征图融合的网络全卷积层有更多参数尚未学习完成,综合特征中掺杂了较多无用的细节信息,使未完全收敛的模型受到误导.随着迭代次数的增加,两个网络训练误差趋于同一趋势,表明融合特征图的网络已经能够有效学习到融合不同阶段的特征图的参数.
3.5 人群计数准确性分析
不同算法在Shanghaitech数据集上评价指标的对比结果如表2所示.在该数据集Part A部分中,本文提出的FMFCNN算法,对比同样基于卷积神经网络的密度图回归框架的文献[11]的Patch CNN算法和文献[12]的MCNN算法,平均相对误差(MRE)分别降低了20.55%和8.92%.在该数据集Part B部分中,本文提出的FMFCNN算法,对比Patch CNN算法和MCNN算法,MRE分别降低了57.94%和16.35%.
不同算法在WorldExp10数据集上评价指标的对比结果如表3所示.可以看出,对比同样基于卷积神经网络的密度图回归框架的3种算法,本文算法将已有算法的MRE误差降低了15.73%,有效提高了人群密度估计的准确性.
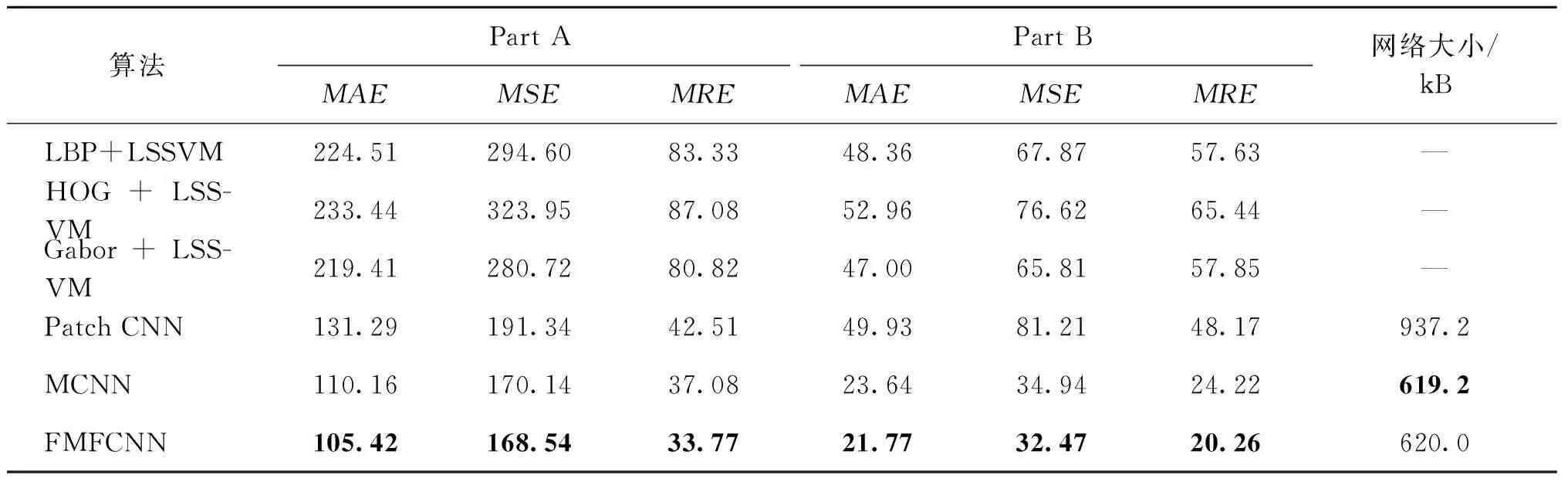
表2 不同算法在Shanghaitech数据集上评价指标对比
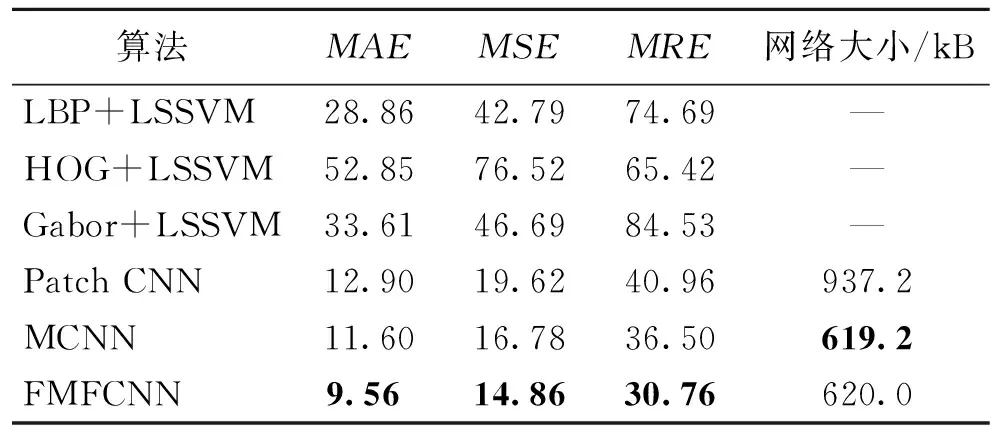
表3 不同算法在WorldExp10数据集上评价指标对比
从表2和表3中3种基于卷积神经网络的密度图回归方法的网络大小可以发现,传统的LSSVM方法效果较差,可能是由于手工提取特征表达能力较差造成的.虽然FMFCNN网络结构由于包含Merge层对特征图进行融合,但并没有使网络结构和网络中的参数量发生大幅度的增加,其原因在于Merge层后面连接的是具有1×1卷积核的卷积层.因此,网络增加的参数量仅仅为1×1全卷积层增加的参数量.特征图融合前此层输入特征图数目为36个,进行特征图融合后输入特征图数目为252个,特征图的数量增加了216个.因此,整个网络参数的增加量也为216个特征图对应的参数量.相对于MCNN网络,通过增加0.12%的网络参数,实现了在Shanghaitech数据集的Part A和Part B部分以及World Exp10数据集中将MRE分别降低8.92%、16.35%和15.73%的准确性提升.
3.6 密度图回归准确性分析
3种基于卷积神经网络的密度图估计方法估计出的人群密度图效果如图4所示.其中图4(a)为数据集中的测试图片,图4(b)为通过标注信息按照2.3节方法计算得到的密度图,图4(c)为Patch CNN[11]估计的密度图,图4(d)为MCNN[12]估计的密度图,图4(e)为本文所提FMFCNN估计的密度图.通过观察可以发现,Patch CNN和MCNN估计的密度图相对粗糙模糊,主要是由于对背景中的建筑物、树木等结构存在一定程度的误判.而本文所提FMFCNN网络结构估计的密度图能够有效区分前景行人目标和背景区域,密度图回归更加准确.
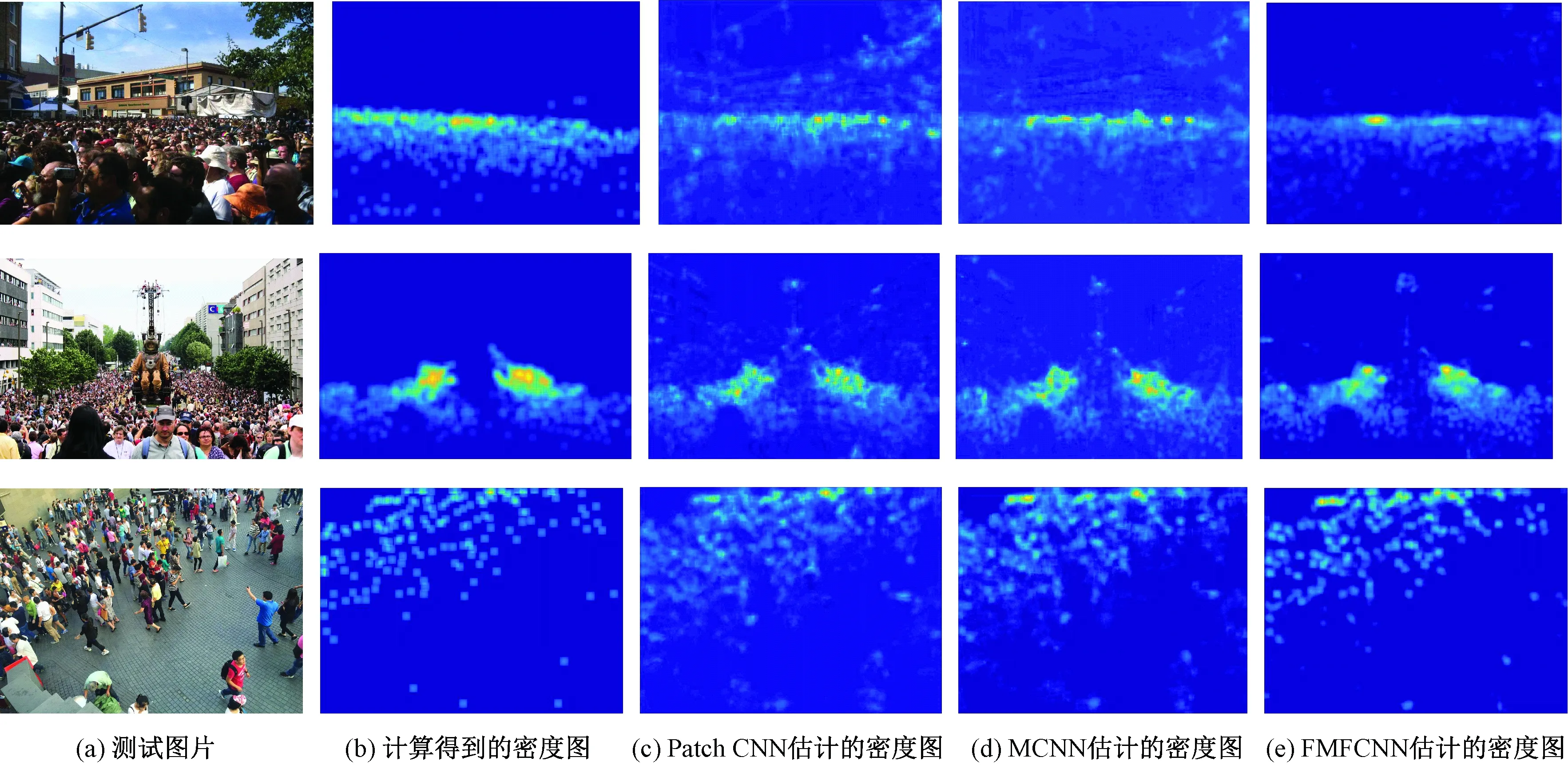
图4 3种基于卷积神经网络的密度图估计方法估计出的人群密度图效果Fig.4 The estimated density maps of the three estimation methods based on convolutional neural networks
4 小结
人群密度估计技术对密集人群的感知与管控具有重要意义.针对开放密集场景中的小目标与多尺度问题,提出了基于特征图融合的多列卷积神经网络模型.特征图融合方式利用了高层语义特征与底层细节特征,同时大幅提高了基础网络集成数量,从而提高了人群密度估计的准确性.实验结果表明,所提出的网络模型有效提高了现有人群密度估计算法的准确性.
参考文献:
[1] SALEH S A M, SUANDI S A, IBRAHIM H. Recent survey on crowd density estimation and counting for visual surveillance[J]. Engineering applications of artificial intelligence, 2015, 41:103-114.
[2] 麻文华,黄磊,刘昌平. 基于置信度分析的人群密度等级分类模型[J]. 模式识别与人工智能, 2011, 24(1): 30-39.
[3] 赵晓焱, 陶雪丽. 安防监控系统的研究与实现[J]. 郑州大学学报(理学版), 2012, 44(4):59-62.
[4] DAVIES A C,YIN J H,VELASTIN S A. Crowd monitoring using image processing[J]. Electronics and communication engineering journal, 1995, 7(1): 37-47.
[5] LIANG Z S J, CHAN A B, VASCONCELOS N. Privacy preserving crowd monitoring: counting people without people models or tracking[C]//IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, 2008:1-7.
[6] 覃勋辉, 王修飞, 周曦,等. 多种人群密度场景下的人群计数[J]. 中国图象图形学报, 2013, 18(4):392-398.
[7] MARANA A, COSTA L D, LOTUFO R, et al. On the efficacy of texture analysis for crowd monitoring[C]//Proceedings of International Symposium on Computer Graphics, Image Processing, and Vision. Rio de Janeiro, 1998:354-361.
[8] LEMPITSKY V, ZISSERMAN A. Learning to count objects in images[C]//Proceedings of the 23rd International Conference on Neural Information Processing Systems.Vancouver, 2010:1324-1332.
[9] FIASCHI L, NAIR R, KOETHE U, et al. Learning to count with regression forest and structured labels[C]//Proceedings of the 21st International Conference on Pattern Recognition. Tsukuba, 2012:2685-2688.
[10] PHAM V Q, KOZAKAYA T, YAMAGUCHI O, et al. COUNT forest: co-voting uncertain number of targets using random forest for crowd density estimation[C]//IEEE International Conference on Computer Vision. Santiago, 2015:3253-3261.
[11] ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Boston, 2015:833-841.
[12] ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 589-597.
[13] BOOMINATHAN L, KRUTHIVENTI S S S, BABU R V. CrowdNet: a deep convolutional network for dense crowd counting[C]//Proceedings of the ACM on Multimedia Conference. Amsterdam, 2016:640-644.
[14] KONG T, YAO A, CHEN Y, et al. HyperNet: towards accurate region proposal generation and joint object detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016: 845-848.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
科技视界(2021年4期)2021-04-13
现代信息科技(2021年17期)2021-04-05
农业机械学报(2021年1期)2021-02-01
恋爱婚姻家庭(2020年27期)2020-10-09
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
百花洲(2018年1期)2018-02-07
