
基于词语关联的散文阅读理解问题答案获取方法
2018-05-04 07:26王素格谭红叶王元龙
中文信息学报 2018年3期
乔 霈,王素格,2,陈 鑫,谭红叶,陈 千,王元龙
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
随着国内外越来越多的机构投入到问答系统的研究中,使得自动问答技术取得了很大的进展。问答系统,即利用自然语言处理技术理解用户所提出的问题,再返回给用户正确的答案[1]。阅读理解属于问答任务中的一个重要分支,又与传统的问答存在区别,它是通过机器理解一篇文章,再根据文中信息对所提的问题做出回答,主要侧重于问题与阅读材料的语义相关性。面向高考散文阅读理解问答题,按照问题的提问方式我们将其归纳为特点(特色)类、感受类、认识(态度)类、原因类、列举类、其他类共六类。为了解答这些问题,首先需要理解题干的相关信息,然后从阅读材料中获取与题干中信息相关的词语或短语,最后将阅读材料中与词语或短语相关的句子作为答案句。表1所示为阅读理解中问答题的问题、答案示例。

表1 阅读理解中问答题的问题、参考答案示例
表1中问题的关键词为“特色”,描述对象为鲁迅的故乡环境,理解“特色”一词的抽象语义,需要从阅读材料中寻找鲁迅的故乡环境与“特色”相关联的词语,构成答案句。
针对散文阅读理解类问题中的词语较为抽象,在语义上难以与阅读材料中的信息联系,需要将问题中具有抽象含义的词语扩展为与其关联的具体词语,再进一步与阅读材料中的句子进行联系。
本文利用LDA方法将问题库中的问题词语与阅读材料涉及的内容进行主题聚类,然后按照词性、词频特征筛选出每个主题下相关的词语作为问题词语的主题关联词,再利用Word2Vec训练散文语料,将得到的主题关联词语进一步扩展为语义关联词语。通过获取语义关联词语,使问题关键词语与阅读材料中句子之间建立联系,从而丰富问题关键词语,提高问题答案句的抽取性能。
1 相关工作
自从1999年TREC(text retrieval conference)会议[2]开设QA Track以来,自动问答及阅读理解的研究就备受关注。早期问答系统的研究主要有以下三个方面: (1)基于统计方法是从文本集中抽取答案返回给用户。例如,IBM开发的基于统计的问答系统主要应用统计翻译、词汇模式等抽取方法。(2)基于知识库的方法是从知识库中抽取问题的答案。例如,芝加哥大学开发的FAQFinder[3],用于解决一些地理、历史、文化等方面的简单问题。(3)基于语义的方法是通过计算词语间的语义相似度获得答案句。例如,台湾Sheng-YuanYang开发的FAQ-master[4]。目前阅读理解方面的研究大多针对简单文本和简单问题,例如,微软建立的一套面向儿童的开放域阅读理解数据集MCTest[5],Smith等[6]针对此数据集提出了在文本上设置滑动窗口来与问题答案对中的词汇匹配打分的方法,引用一种基于RTE的方法将问题与答案按照启发式规则进行拼接,然后计算上述拼接结果与原文信息之间的相关性。Facebook的bAbI项目仿真生成了20个任务用于测试文本理解和推理[7],Sukhbaatar等[8]提出端到端的记忆网络模型,用于解答上述20个任务中的短文本问题。由于问题和文本是自动生成,相应的数据简单,使得结果准确率高,但是该实验侧重信息推理,未考虑文本的语义信息,因此,难以应用到中文阅读理解任务中。王智强等[9]提出一种基于篇章框架语义分析的答案抽取方法,并将其应用于解答中文阅读理解问题。该方法主要依赖框架结构,而散文本身用词广泛,隐含语义丰富,且问题中的词语较抽象,框架关系中目前还未覆盖散文领域的抽象词语,因此,还难以利用框架关系建立问题中词语与文章之间的关系。
对于机器阅读理解问题,现有研究者的主要工作集中于问题分析、答案抽取及生成[10]。然而,由于问题中的关键词与答案句中的词语在表达方式上存在差异,导致问题中词语未能与文章中的词语相联系,这将影响答案句抽取的准确性,因此,在散文问答题中有必要进行词语关联方法研究。
词语关联,即寻找词语的潜在语义,解决词语的一词多义、多词同义现象,用于提高检索的准确率。目前,问答系统中采用的词语关联方法主要包括基于统计的方法和基于语义词典或特定扩展词表的方法。
基于统计的词语关联方法通常利用词语之间的共现概率或互信息等统计信息来选取关联词,该方法并没有深入分析原查询词与候选关联词间的语义关系。例如,Jones[11]提出词的聚类算法,根据词与词之间在语料库中的共现程度实现词聚类,并将查询词所在簇中的其他词作为关联词语。丁立恺[12]提出词关联度的概念,通过对文本语料库中词语出现的频率,以及任意两个词语共同出现的频率进行统计,获得各个词语之间的关联度。
基于语义词典的方法,需要借助词典中的词建立与查询词之间的语义关联。张华平等[13]通过使用WordNet的语义体系对词语进行语义关联性的扩展。Rothe等[14]结合深度学习方法以WordNet作为语义资源提出自动扩展的方法,构造了一个使用词嵌入扩展同义词集和语义嵌入的系统。史俊冰等[15]建立了同义词词典,并在此基础上实现了词语扩展。万静等[16]通过构建领域知识词典的方法扩展用户输入的关键词。以上基于词典的扩展方法依赖于完备的语义体系,而目前并没有散文领域的相关体系。另外,基于语义词典的方法不依赖语料集,难以联系阅读理解的文本内容的特性。陈建超等人[17]通过建立包含上下文信息的同义词集解决文本中的一词多义和多词同义问题。他将词语的上下文信息视为特征词,根据特征词之间存在的关联性特点建立了一个评分机制,提取分数最高的特征词集对应的词汇作为一个同义词集,该方法比直接提取近义词或提取上下文相关词的准确率有所提高,但是考虑阅读材料中大多采用含蓄、隐式的词语来表达作者的情感,因此,难以直接将该方法应用于阅读理解当中。
上述研究主要侧重将词语扩展为与其表层语义相近的词,从而忽略了词语在特定语境和不同主题下的潜在语义信息。
LDA(latent dirichlet allocation)是Blei等[18]2003年提出的一种被广泛使用的主题模型,能够从海量语料库中获取核心语义或特征并对主题进行建模,它是一个离散数据集生成概率模型的过程[19],其工作原理是将语料库中的每一个文档与一组潜在主题的概率分布进行对应,而每一个潜在主题同时与文档中词语的概率分布相对应。该模型基于三点假设[20]: (1)词袋模型,LDA认定每篇文档是由一组词汇构成,且词汇之间无先后顺序关系,词语集合W={w1,w2,…,wn};(2)训练集中的文档顺序也是随意的,无指定顺序,因此,每篇文档可以表示成一个词频向量关系集合di=
2 面向问题解答的词语关联方法
考虑到问题与答案集、问题与阅读材料中词语间具有主题相关性和语义相关性,我们利用LDA主题聚类方法,确定各类别问题词语的主题,再利用词语重要度选择各类别相应主题下重要度高的词语作为该问题类别的主题关联词语。在此基础上,利用Word2Vec对主题关联词语与材料中词语进行向量表示,用于度量词语间的语义相关性。最后利用上述两种方法,扩展问题的抽象词语,建立问题与散文材料中的词语联系。
2.1 基于LDA的问题主题词语扩展
为了获取主题相关的词语,以散文阅读理解为背景,从所有的阅读材料—问题—答案集中整理出抽取类问答题(抽取类,即答案句是从文中摘取的句子),以这些问题-答案集为数据,通过LDA聚类方法将数据集下的词语聚集在不同的主题之下,使各类别问题词语对应各自的主题。例如,文本“作者故乡植物的生命具有哪些特点?”其示意图如图1所示。
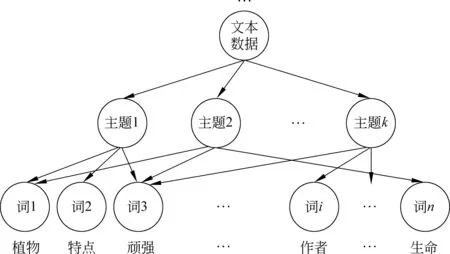
图1 LDA聚类主题—词汇分布举例
通过LDA主题聚类,可以计算各数据(一条数据指的是一个问题—答案对)在每个主题下的概率,计算方法如式(1)、式(2)所示。
其中,Wi表示第i条数据的词集,TWj表示主题j中的词集,N(Wi,TWj)为第i条数据与主题j中共同出现的词语,R(i,k)表示第i条数据对应的主题为k。
针对上文引言中提到的阅读理解中六类问题所关联的词语,可以确定各数据所属的类别,利用各类别数据在不同主题下的比例可以获取类别为tyn对应的最优主题k(tyn),如式(3)所示。
(3)
其中,n(tyn)是tyn类的数据总数,m(k,tyn)表示tyn类中的主题为k的数据个数。
根据式(3),可将各类问题与主题对应,然而通过对大量数据考察,发现各主题下的部分词语集与该类问题中词语关联性不强,例如,各类问题的描述性词语一般多为名词和形容词,而动词“分析”“具有”“选择”等为不具有特定意义的词语。因此,需要进一步对六类问题中的词语进行筛选。各类问题的形容词和名词部分描述如表2所示。

表2 各类问题的部分描述性词语
为了准确地获得与解题相关的关联词语,分别统计六类问题中的词语对应的主题下的名词和形容词出现的次数。按照高频词数均值法确定主题中抽取词语的数量tn,计算方法如式(4)所示。
(4)
其中,m表示问题类别总数,ftyn表示tyn类问题对应的主题中频次高于l的词语集。
由于每类词语中名词和形容词的重要度不同,进一步设置参数α和1-α分别代表名词和形容词在每类问题词中所占的比重,以此获得每个类别中名词和形容词保留的个数,计算方法如式(5)所示。
(5)
其中,N′(tyn,wn.)为tyn类下名词的数量,N′(tyn,wadj.)为tyn类下形容词的数量。
2.2 基于Word2Vec的问题语义词语扩展
由于高考阅读材料的有限性,仅仅利用2.1节中方法获得每类词语的主题关联词语不能满足问题解答的要求,需要进一步获取与散文领域中词语语义相关联的词语。Word2Vec是2013年由Google公司开发的将词表示为向量形式的工具[22],这些向量中含有潜在丰富的语义信息。本文将散文阅读材料与主题相关的词语通过Word2Vec训练,使它们转化为特定维度的向量表示,然后再计算词语间相关性,该方法记为TWE。
假设PC为散文材料库,T为主题词语集合。
词语相似度计算过程: 利用Word2Vec,将词语p∈PC和主题关联词语q∈T分别表示成向量w(p),w(q),PC中所有词语的向量集合记为PC′。通过计算w(p)与w(q)之间的余弦夹角,可获得w(p)与w(q)的相似度矩阵{cos(w(p),w(q)}|T||PC|。
词语关联度排序函数: 为了获取PC中与q语义相似度高的词语,我们定义w(p)与w(q)余弦值的排序函数Rank,具体如式(6)所示。
(6)
这里Top-h(w(q))为余弦值排序在前h个对应的词语序列。
3 散文问答题答案抽取方法
根据高考语文相关专家分析,通常阅读理解问答题的得分是按照给出的答案要点进行评判。因此,针对散文问答题的答案抽取任务,需要计算词语间的相关性。通常采用词语的词形匹配和语义相似计算,而词形匹配一般使用词语匹配的句子相似度计算方法[23],语义相似计算采用HowNet的句子相似度计算[24]方法。
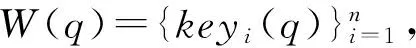
(1) 词语的词形匹配计算方法sim1
问题句q与阅读材料中句子s的相似度算法如式(7)所示。
(7)
(2) 词语的语义相似计算方法sim2
对于问句q与阅读材料中句子s的相似度计算,如式(8)所示。
(8)
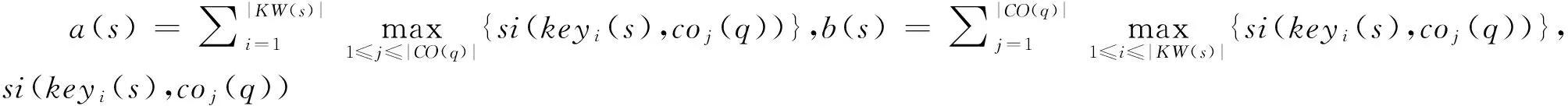
(3) 词语的词形匹配与语义相似混合计算方法sim
对于词语的词形匹配,仅利用词语的表层信息,而词语的语义相似计算方法考虑词语的深层语义信息,因此,本文将两者有机结合。利用式(7)和式(8),获得问句q与阅读材料中句子s的词语的词形匹配与语义相似混合计算方法sim=sim1(q,s)+sim2(q,s),选择问句q与阅读材料中句子相似度高的N个句子作为答案句。
4 实验结果与分析
4.1 实验数据及评价指标
本文的实验数据分为训练数据和测试数据。
训练数据: 主题聚类所用的数据集是从人工整理的各省高考题(不包含北京卷)共1 647篇文章,包含6 117个问题—答案集中的约600个抽取类试题的问题—答案集;内容关联词语扩展所用的数据集是从网络爬取的近七万篇文学作品的阅读理解,规模大约320 MB。
测试数据: 选择北京市近12年的高考题和网上收集的1 000套高考模拟题作为方法验证,其中抽取类问答题有400个。
评价指标: (1)本文采用信息熵来度量聚类结果对各类问题的影响;(2)根据题目所给的参考答案人工从材料中寻找对应的句子,并记为答案句集合A,T为使用本文方法得到的答案句子集合,按如下公式计算准确率(P)、召回率(R)和F值。其中,
(9)
4.2 参数设置
4.2.1 主题个数的选择
利用2.1节中介绍的方法进行聚类,实验分别选择主题数k=5,7,10,用于比较聚类结果中六类问题词语在不同主题下的分布比例,实验结果如表3~表5所示。
根据表3~表5,获得六类问题在不同主题下聚类结果。首先,计算各类问题在各主题中的信息熵,然后加和取平均作为该主题数聚类下的整体信息熵值,最终得到主题数k=5,7,10时信息熵值分别为H(k=5)=2.14、H(k=7)=2.35,H(k=10)=2.94。熵值越小,说明聚簇结果越好。因此,选择主题数k=5最佳。下面的实验主题数均为k=5。
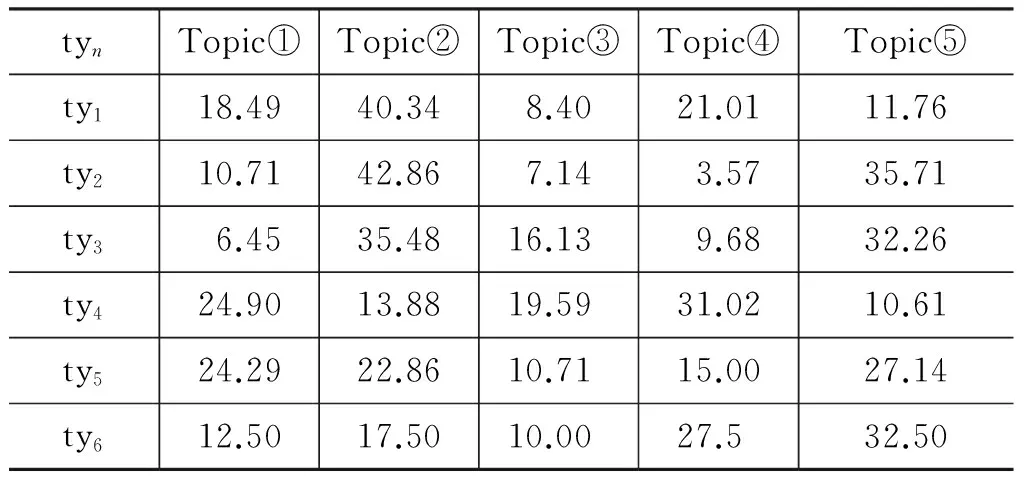
表3 各类问题在主题数k=5的聚类结果的分布比例/%
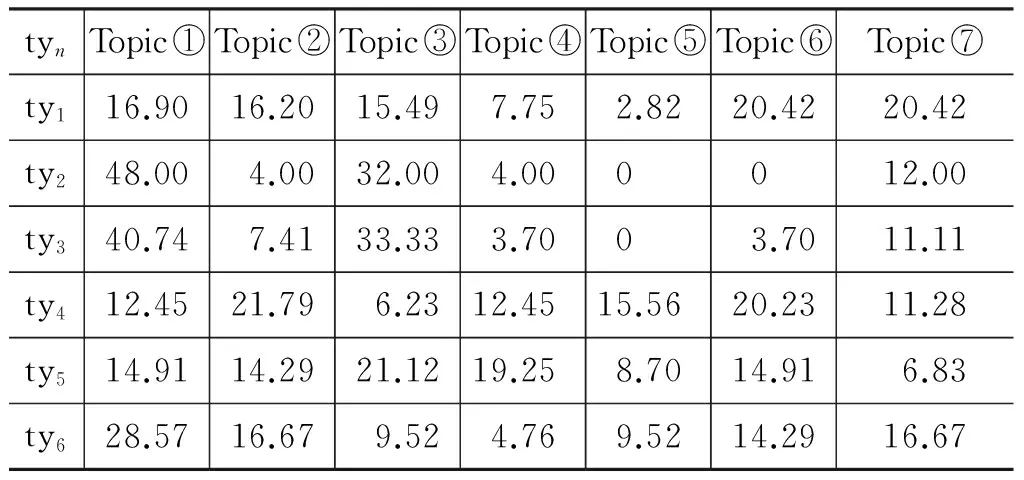
表4 各类问题在主题数k=7的聚类结果的分布比例/%

表5 各类问题在主题数k=10的聚类结果的分布比例/%

续表
4.2.2 词语筛选
考虑词语的覆盖度,本实验设置主题下高频词阈值l=6, 4, 2三组实验,利用2.1节中式(4)获得主题关联词语数tn=13,24,60,而实验中主题关联词语的数量tn=24时答题效果最好,因此,本实验将高频词的阈值设置为l=4。
当tn确定后,利用2.1节中式(5)确定每类问题中名词和形容词的比例,本实验取α= 0,0.1,0.2,…,0.9,1,共11组实验,针对每类问题的答题准确率,选择各类别主题下名词和形容词的最优个数,结果如图2所示。
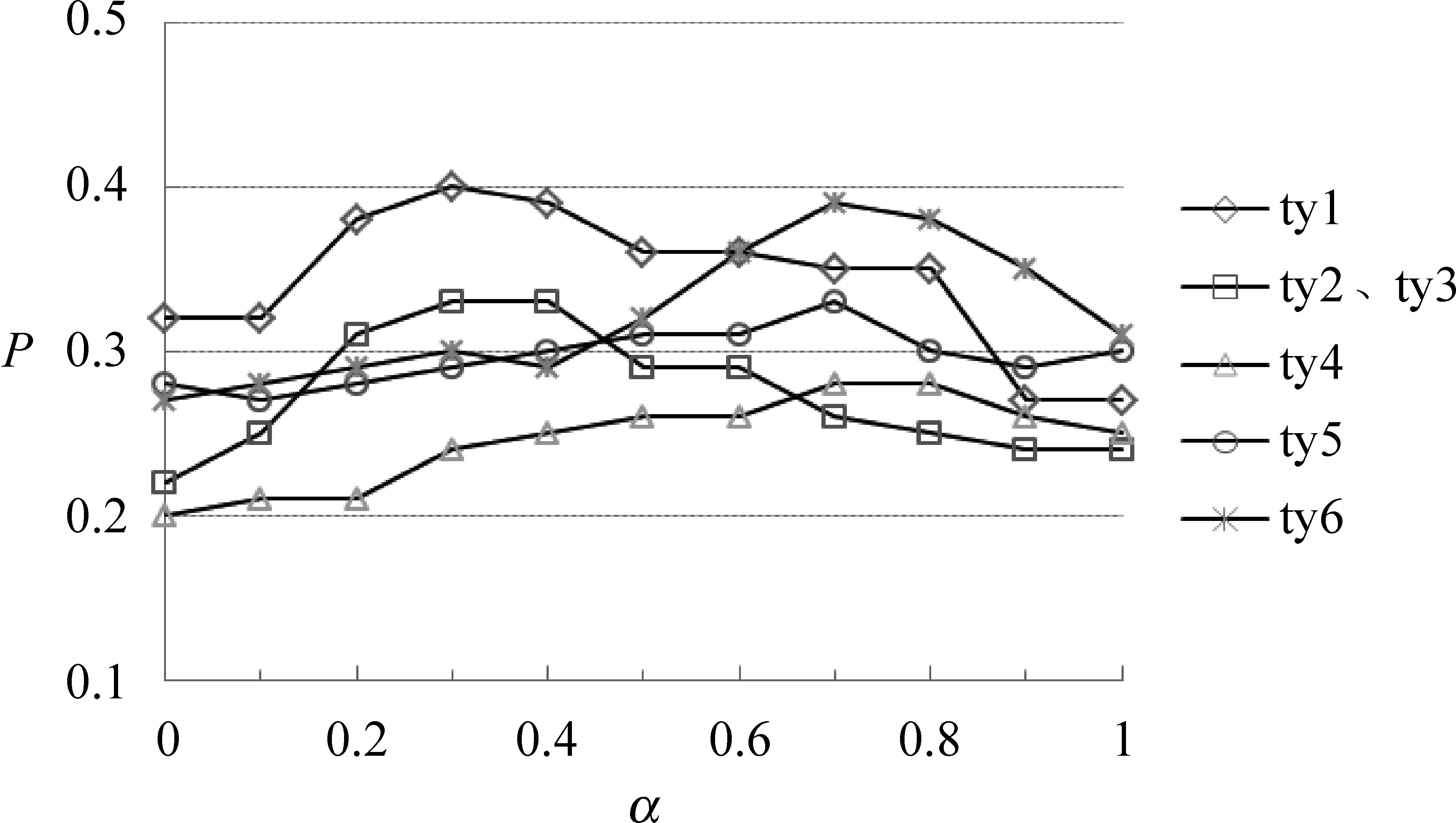
图2 词语重要度参数α选择实验结果
从图2可以看出ty1、ty2、ty3的问题在α=0.3时效果最好,ty4、ty5和ty6在α=0.7时效果最好。
4.2.3 语义关联词语Top-h(w(q))中h的选择
散文语料中词向量的训练选取了Word2Vec的Skip-gram模型[25],参数设定为默认值,即文本窗口为5,向量维度为300维。训练后得到80 000多个词向量。
利用2.2节中介绍的方法扩展词语,词汇的数量h分别取5,10,15,20,25,30,方法验证时答案句的个数取N=4,6,8,通过测试,得到最好结果为N=6。因此,抽取答案句子数N=6计算准确率,结果如图3所示。
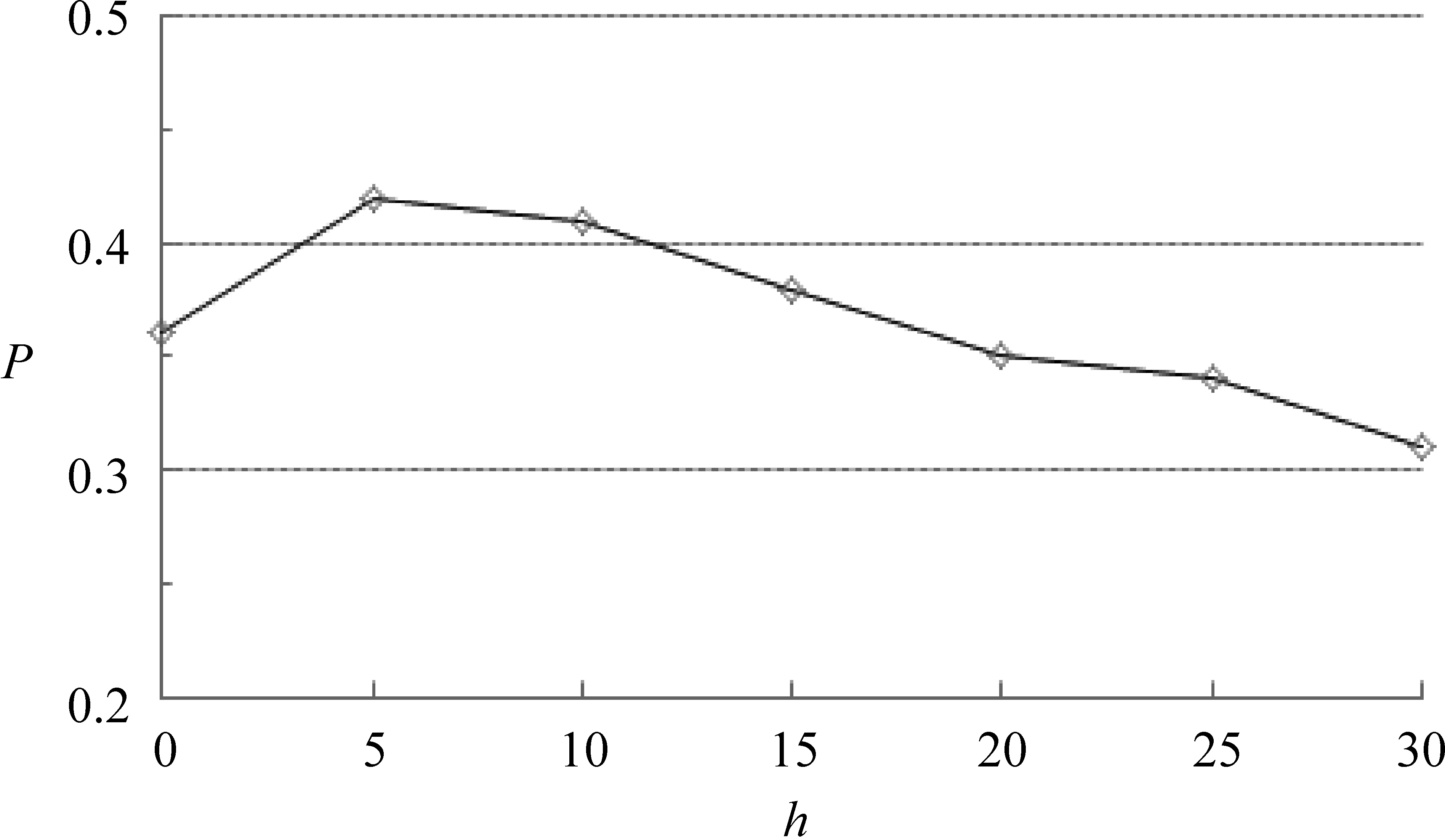
图3 扩展词汇数量h的选取
由图3可知,当最终确定扩展词汇数量h=5时,实验结果较好。
4.3 答案句抽取实验结果与分析
为了验证本文扩展词语对答案句抽取的有效性,设置了三个Baseline方法进行对比。
(1) 直接抽取答案句(DE): 即问题中的关键词不进行词语扩展。
(2) 基于Word2Vec的词语关联抽取答案(WE): 将问题词集W(q)直接利用Word2Vec余弦相似度得到扩展词集WV(q),不进行主题聚类。
(3) 基于同义词词林的词语关联抽取答案句(SE): 将问题词集W(q)利用同义词词林扩展词集SW(q)。
利用DE、WE、SE以及本文方法TWE获取关联词语,再分别使用第三节的三种答案抽取方法获得前六个答案句子数,得到不同词语关联方法和不同的答案抽取方法间的比较结果,如表6所示。
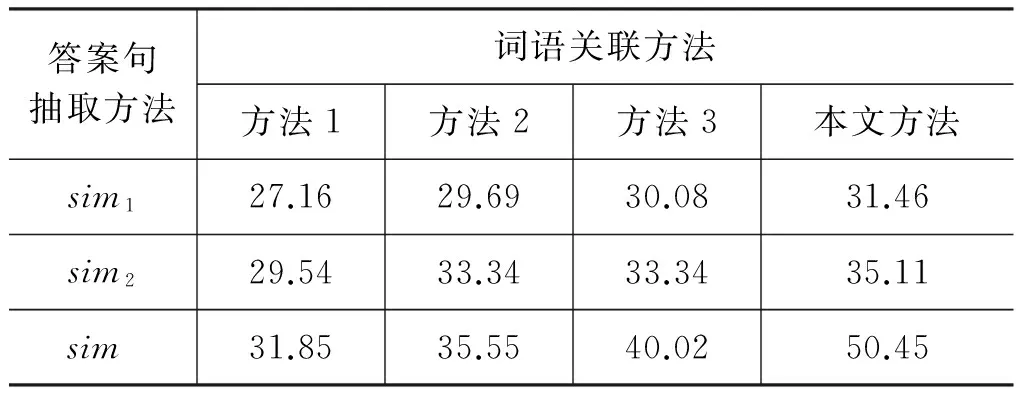
表6 不同词语关联与不同的答案句抽取方法的F值结果比较/%
由表6中结果可知:
① 词语的词形匹配方法sim1抽取答案句的F值比词语语义相似方法sim2抽取答案句的F值低,主要原因是由于散文问答题的特殊性,它更强调抽象词语的语义。
② 词语的词形匹配与语义相似混合计算方法sim,得到的结果比单独的方法sim1(sim2)抽取答案句的F值高,主要原因是同时考虑了词语的词形和语义。因此,本文答案句抽取方法选择sim方法。在此基础上,不同词语关联方法在抽取前六句答案句时的准确率、召回率和F值如表7所示。
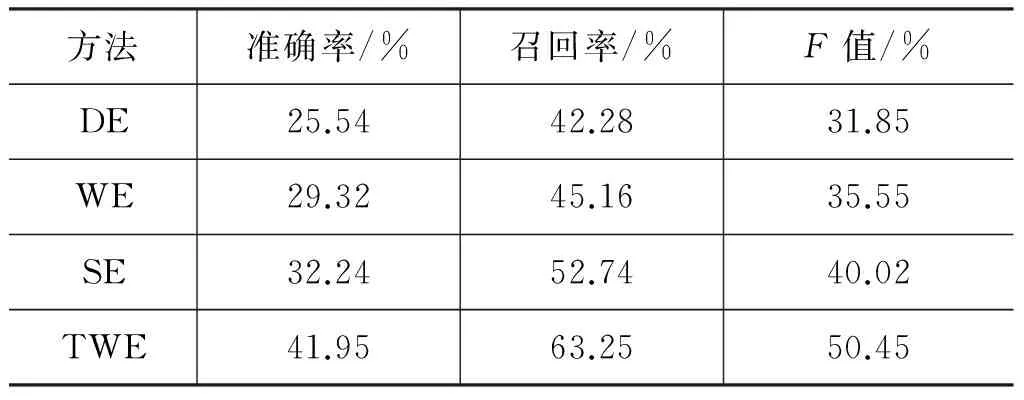
表7 不同词语关联方法抽取答案句的结果比较
由表7中实验结果可知:
(1) 本文方法TWE比Baseline方法在答案句抽取的三项指标结果均好。方法DE没有对问题中的关键词扩展,使问题与阅读材料中相关句子难以联系。方法WE和方法SE虽然对解题起到一定作用,但是问题中抽象词语扩展为其抽象的近义词,未从根本上解决抽象词与具体词之间的语义鸿沟,导致准确率不及方法TWE。
(2) 与方法DE、WE、SE相比,本文方法TWE从主题角度扩展抽象词的关联词语,使得答题准确率和召回率有了显著提升,说明词语关联方法对散文抽取类问题的解答确实起到了作用。
(3) 为了验证方法TWE的显著性,从统计学角度分析,采用配对样本的t检验方法衡量数据的统计意义,当p小于0.05时,说明两组数据的平均值在小于5%的概率上是相等的,在大于95%的几率上不相等,两组实验存在显著性差异。将方法DE、WE、SE与TWE对比,分别获得的概率值为:
p(1)=0.012<0.05
p(2)=0.036<0.05
p(3)=0.043<0.05
由于三组数据的概率p均小于0.05,因此,方法TWE的实验结果具有统计显著性。
4.4 高考题答题结果及分析
对于引言中表1的高考题,利用TWE方法,可以获得问题的解答结果,如表8所示。

表8 本文方法解答问答题示例
由表8结果可知,利用本文方法TWE扩展问题词语,再抽取答案句,可以获得“空间……;物件……”两句正确答案。
如果采用方法DE解答本题,未能获得正确答案句。方法WE和方法SE均获得一句正确答案。因此,本文方法TWE在一定程度上提高了散文阅读理解的答题准确率。
5 总结
散文阅读理解问题中的关键词具有抽象含义,导致问题与答案句之间具有较大的语义鸿沟,为了解决该类问题,本文提出词语关联方法。首先基于LDA聚类的主题—词汇分布,确定各数据的主题,然后根据各类数据在主题下的分布比例为每类数据分配最优主题,对该主题下的词语重要度进行选择,得到各问题类别的主题关联词语;接着,利用Word2Vec相似度方法将主题关联词语扩展为语义关联词语,最后利用词形匹配和语义相似混合计算方法抽取答案句。方法TWE有效提高了散文问答题的答题准确率和召回率。另外,方法TWE不仅适用于高考阅读理解的问题解答,也可以应用于信息检索任务中。
由于散文阅读材料往往带有作者的情感信息,因此在未来工作中,将考虑情感词的重要性,结合句子中的情感信息进一步获得词语的关联词语。
备注本文使用了哈尔滨工业大学计算与信息检索中心研发的LTP进行分词及词性标注;使用了知网提供的语义相似度计算方法。
[1] 张宁, 朱礼军. 中文问答系统问句分析研究综述[J]. 情报工程, 2016, 2(1): 32-42.
[2] Katz B. Annotating the World Wide Web using natural language[C]//Proceedings of Computer-Assisted Information Searching on Internet,1997: 136-155.
[3] Hammond K, Burke R, Martin C, et al. FAQ Finder: A case-based approach to knowledge navigation[C]//Proceedings of Conference on Artificial Intelligence for Applications,1995: 80-86.
[4] Yang S Y. An ontological multi-agent system for web FAQ query[C]//Proceedings of the 2007 International Conference on Machine Learning and Cybernetics,2007: 2964-2969.
[5] Matthew R, Christopher J C Burges, Eric Renshaw. MCTest: A challenge dataset for the open-domain machine comprehension of Text[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,2013: 193-203.
[6] Smith E, Greco N, Bosnjak M, et al. A strong lexical matching method for the machine comprehension test[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015: 1693-1698.
[7] Weston J, Bordes A, Chopra S, et al. Towards ai-complete question answering: A set of prerequisite toy tasks[J]. arXiv preprint arXiv: 1502.05698, 2015.
[8] Sukhbaatar S, Weston J, Fergus R. End-to-end memory networks[C]//Proceedings of Advances in Neural Information Processing Systems,2015: 2440-2448.
[9] 王智强, 李茹, 梁吉业,等. 基于汉语篇章框架语义分析的阅读理解问答研究[J]. 计算机学报, 2016, 39(4): 795-807.
[10] 吴友政, 赵军, 段湘煜,等. 问答式检索技术及评测研究综述[J]. 中文信息学报, 2005, 19(3): 1-13.
[11] Jones S. Automatic keyword classification for information retrieval[J]. The Library Quarterly: Information, Community, Policy, 1971, 25(4): 33-98.
[12] 丁立恺. 基于词关联度的信息检索系统[D]. 上海: 复旦大学硕士学位论文, 2010.
[13] 张华平. 语言浅层分析与句子集新信息检测研究[D]. 北京: 中国科学院研究生院博士学位论文, 2005.
[14] Rothe S, Schütze H. Autoextend: Extending word embeddings to embeddings for synsets and lexemes[J]. arXiv preprint arXiv: 1507.01127, 2015.
[15] 史俊冰.问答系统中词义消歧与关键词扩展研究[D].太原: 太原理工大学硕士学位论文,2011.
[16] Wan J, Wang W C, Jun-Kai Y I. Semantic extended search approach based on ontology in knowledge base[J]. Computer Engineering, 2012, 38(6): 19-24.
[17] 陈建超, 郑启伦, 李庆阳,等. 基于特征词关联性的同义词集挖掘算法[J]. 计算机应用研究, 2009, 26(7): 2517-2519.
[18] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3): 993-1022.
[19] Blei D, Carin L, Dunson D. Probabilistic topic models[J]. IEEE Signal Processing Magazine, 2010, 27(6): 55-65.
[20] 魏强, 金芝, 许焱. 基于概率主题模型的物联网服务发现[J]. 软件学报, 2014(8): 1640-1658.
[21] 董婧灵. 基于LDA模型的文本聚类研究[D].武汉: 华中师范大学硕士学位论文, 2012.
[22] 宁建飞, 刘降珍. 融合Word2Vec与TextRank的关键词抽取研究[J]. 现代图书情报技术, 2016(6): 20-27.
[23] 王荣波, 池哲儒, 常宝宝,等. 基于词串粒度及权值的汉语句子相似度衡量[J]. 计算机工程, 2005, 31(13): 142-144.
[24] 刘青磊,顾小丰.基于《知网》的词语相似度算法研究[J]. 中文信息学报, 2010, 24(6): 31-37.
[25] Mikolov T, Chen K, Corrado G, et al.Efficient estimation of word representations in vector space[J]. arXiv: 1301.3781.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2019年6期)2019-10-08
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
互联网天地(2016年1期)2016-05-04
