
基于表示学习的开放域中文知识推理
2018-05-04 06:46:19姜天文
中文信息学报 2018年3期
姜天文,秦 兵,刘 挺
(哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
0 引言
在过去的十几年里,大规模的知识库构建已经有了很好的进展。现有的知识库包括普林斯顿大学设计的覆盖范围宽广的语言知识库WordNet[1];知识条目由用户添加并共享的世界知识库FreeBase[2]以及国内哈尔滨工业大学社会计算与信息检索研究中心设计构建的开放域中文知识图谱《大词林》等。这些知识库通常以网络的形式被组织起来,网络中每个节点代表实体,而每条连边则代表实体间的关系。因此,大部分知识往往可以用三元组(头实体,关系,尾实体)来表示,其中最具代表性的就是万维网联盟发布的资源描述框架技术标准[3]。
随着知识库的知识规模不断扩大,这种网状的表示形式目前存在以下两个问题: 计算效率问题[4]和无法很好应对数据稀疏的问题[4]。以符号为基础的网状形式的知识库无法应对连续空间里的数值计算。单纯的符号和逻辑的表示使得知识库中的知识越来越离散化,知识之间无法很好整合在一起,无法有效应对长尾问题。这也就使得智能系统无法更加灵活地使用知识库,比如进行知识推理。
表示学习[5]旨在将网状的语义信息表示为稠密低维的实值向量,在低维空间中两个对象距离越近语义相似度越高,正是这一点有望解决别名问题。在这种低维空间中有望高效计算实体和关系的语义联系。另外,由于每个对象的向量均为稠密有值的,因此可以度量任意对象之间的语义相似度,并且将大量对象投影到统一空间的过程,能够将高频对象的语义信息用于帮助低频对象的语义表示,从而提高低频对象的精确性。由此可知这种知识表示学习可以有效解决数据稀疏问题。基于以上叙述的特点,这种知识的分布式表示最终可以使得知识的获取、推理的性能显著提升。
本文使用Bordes等人于2013年提出的TransE模型[6],同时对模型的代价函数进行改进以用于开放域中文知识库的表示学习。相比于传统知识库,开放域知识库使用关系指示词代替关系类型,且实体更为丰富,粒度更加细腻。本文主要研究对开放域中文知识库基于表示学习的知识推理方法,包括对实体关系三元组中关系指示词和尾实体的推理。
1 基于翻译模型的知识库表示学习方法
目前国内外的知识表示工作主要针对传统的非开放域的英文知识库。其主要思路是把知识库嵌入到一个连续的向量空间中,并保留原始知识库的某些特性。这些知识表示的方法通过最小化全局损失函数来获得实体和关系的表示,而且这个全局损失函数涉及到所有知识图谱中的实体和关系,这也就意味着实体或关系的表示是编码了全局的信息所得到的。
早期在知识表示方面主要有以下几个模型: 距离模型[7]、能量模型[8-9]、张量模型[10]。早期的这种知识表示的方法中,大多数关注于提高表现力和模型的普遍性,而越来越高的表现力随之而来的是模型的复杂度增加、参数增加,以及训练的花销巨大。不仅如此,由于高能力的模型正则项较难设计,所以存在潜在的过拟合的情况。另外,由于非凸最优化问题有很多局部的极小值,使得训练难度增加,导致模型无法拟合数据[6]。
近年来提出的翻译模型[6]简单有效,在大规模知识图谱上效果明显,自提出以来大量研究工作[11-14]都对其进行扩展和展开,可以说翻译模型已经成为知识表示的代表模型,其中Bordes等人于2013年提出的TransE模型[6]简单可行,完全适合大规模知识库的表示学习。近年来提出的一系列模型都是以TransE模型为蓝本,本文的研究主要基于TransE模型,同时对模型的训练方法进行改进,以用于开放域中文知识库的表示学习。
1.1 表示学习概念以及理论基础
表示学习概念表示学习是指,通过使用机器学习的方法将研究对象的语义信息表示为低维稠密的实值向量。在该低维稠密的向量空间中,我们可以通过余弦距离或欧氏距离等方式计算任意两个对象之间的语义相似度,进而应用于一些传统的自然语言处理问题[15]。
除了表示学习之外,实际上还有更简单的数据表示方案,称其为“one-hot” 表示[16]。这种方案也是将对象表示为实值向量,只不过向量中只有某一维度为非零,其余维度的值均为0,这也正是“one-hot”一词的由来。 “one-hot”无需学习过程,正是由于其简单而高效,在信息检索和自然语言处理中得到广泛应用。但“one-hot”的缺点在于,它认为所有表示对象是相互独立的,即在这个表示空间中所有对象的向量都是正交的,从而使得通过余弦距离或是欧式距离计算的语义相似度均为0。这一点是不符合实际情况的,会丢失大量信息。例如,“哈尔滨”和“长春”虽然是两个不同的词汇,但由于他们都是省会城市,因此应当具有较高的语义相似度。可是“one-hot”无法有效利用这些对象间的语义相似性来表示对象。与“one-hot”不同,表示学习维度较低,从而有助于提高计算效率,同时也能够充分利用对象间的语义信息。
表示学习理论基础我们所处的世界是离散的,每个物体具有明确的界限。当人们观察这个世界时,大脑中相应的大量神经元会产生抑制或者激活的信号,这些信号的状态构成大脑中的内部世界。在这个内部世界中,外界事物对于它变成了众多神经元共同产生的一系列抑制或激活信号。单纯看一个神经元的状态,并没有明确的含义,无法通过它来区分不同的事物,但是众多神经元产生的状态集合在一起却可以表示世间的万物。
通过表示学习得到的低维稠密向量表示是一种分布式表示。向量的每一维并没有明确的含义,但综合各维度构成的向量却能够表示对象的语义信息。分布式表示的向量可看作大脑中众多的神经元,每一维对应于单独的一个神经元,而每一维度值代表该神经元抑制或激活状态。
1.2 TransE模型的改进
TransE模型的表示学习对象是知识库中的实体关系三元组。TransE模型将实体间的关系看作一种两个实体间的翻译操作,关联着两个实体。本文中,我们使用h代表头实体*本文中,我们考虑实体关系三元组的方向性。例如,对于知识“黑龙江的省会城市是哈尔滨”,那么三元组(哈尔滨,省会,黑龙江省)是不正确的表述,而(黑龙江省,省会,哈尔滨)才是正确的,所以对于关系“省会”: “黑龙江省”就是头实体,“哈尔滨”是尾实体,反过来是不正确的。、h表示头实体的向量表示、r代表关系、r表示关系的向量表示、t代表尾实体、t表示尾实体的向量表示,TransE模型的核心思想是: 如果(h,r,t)成立,那么,认为尾实体t的向量表示应该和头实体h的向量表示加上某个由关系r决定的向量表示结果相接近。基于这个核心思想,TransE优化的目标是对于满足关系的(h,r,t),有:h+r≈t,如图1所示。也就是说,当(h,r,t)成立时,在向量空间中t应该是向量h+r最近的邻居;当(h,r,t)不成立时,在向量空间中t应远离向量h+r。
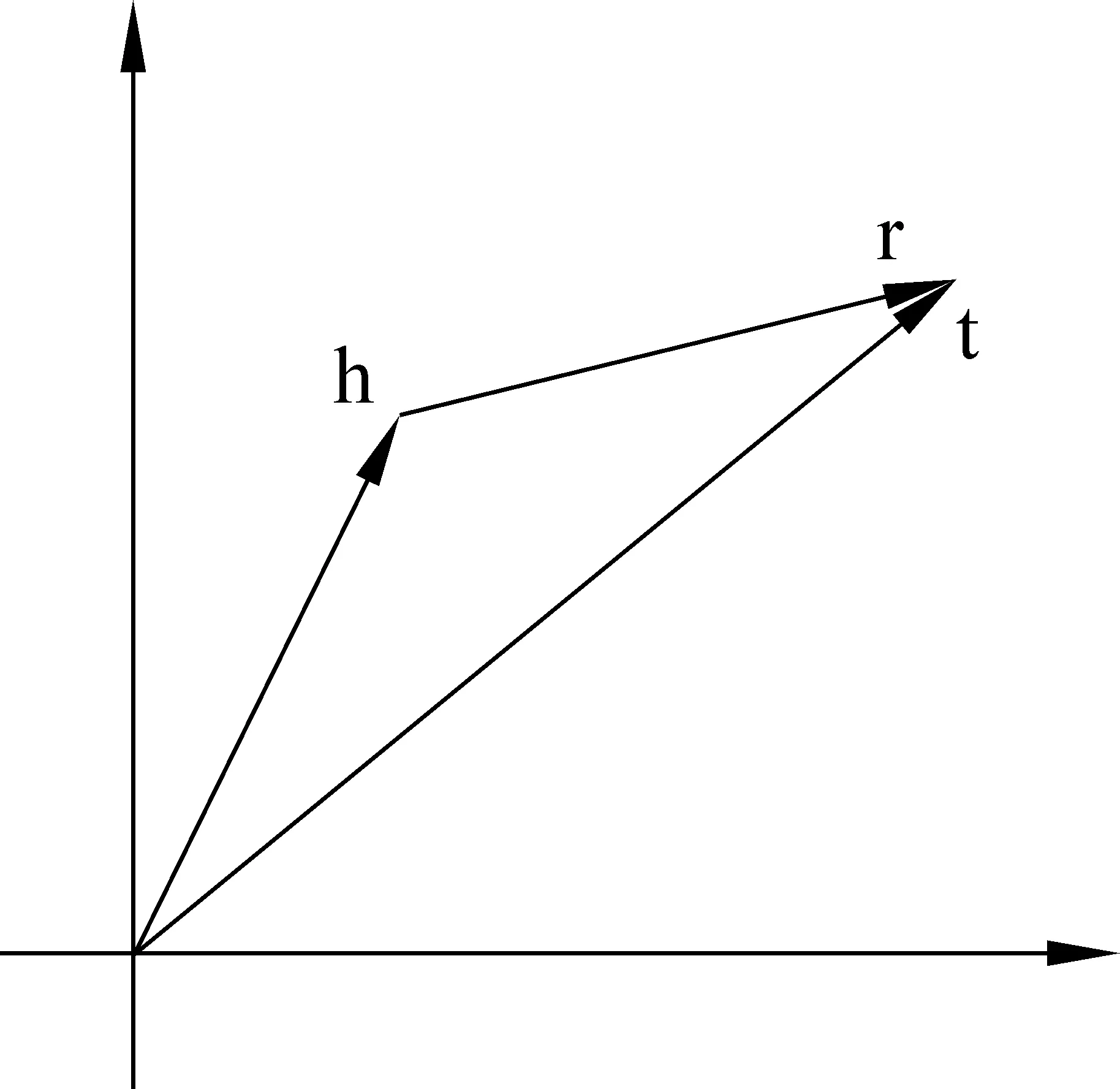
图1 TransE模型的核心思想
使用d(h+r,t)表示向量h+r到t的距离,可以使用L1或L2范式计算距离。模型的代价函数如式(1)所示。
(1)
其中[x]+代表x的正数部分,γ>0是一个边界值,另外,
∪{(h,r,t′)|t′∈E}
(2)
其中E代表实体集合。模型训练过程中所需的负例三元组是通过式(2)构造的,即替换正确三元组的头尾实体。实体和关系的向量表示都是随机初始化的,训练的过程就是不断减小正例三元组的距离d(h+r,t),并使它尽可能地小于所有它对应的负例三元组的距离d(h′+r,t′)。
通过观察式(1),可以发现TransE方法在构建负例三元组的时候只对头尾实体进行替换。其原因在于传统的知识库中的关系是由关系类型代替,而关系类型的数量较少且相互的区分性较大,所以在构造负例三元组时替换关系的意义不大。但对于开放域实体关系三元组,其关系用关系指示词表示,关系指示词的数量较大且相比关系类型区分性并不大,例如,关系指示词“董事长”和“校长”在传统三元组中都会使用“雇佣关系”代替,但在开放域三元组中使用不同的关系指示词代替。由此可见,在面向开放域知识库的研究中,关系指示词对于训练过程的影响不容忽视。
基于以上的原因,我们对原始TransE模型的代价函数进行改进以更好地适用于开放域中文知识库的研究工作。为了进行区别以便后续比较,将改进后的TransE模型命名为TransE_ipv(ipv为improve简写),TransE_ipv的训练过程中的代价函数如式(3)所示。
(3)
其中[x]+代表x的正数部分,γ>0是一个边界值,另外,
(4)
其中E代表实体的集合,R代表关系指示词的集合。主要的改进在于在构造负例三元组的时候不仅替换头尾实体,而且替换关系指示词,使得训练出来的关系指示词更具有区分性。
2 实验
由于国内没有适合本文研究并且公开数据的开放域中文知识库,我们从结构化的百度百科结构化数据“infobox”中抽取获得大量开放域实体关系数据进行实验。本节中,我们提出了应用知识表示学习的关系指示词推理方法,以及尾实体推理方法。实验结果显示,应用知识分布式表示的关系指示词推理准确率可以达到80%以上。在进行应用知识分布表示的尾实体推理测试中,准确率在20%左右,和关系指示词推理相比效果较差。我们对其原因进行分析并验证,使用增加训练过程中负例三元组方法可以将准确率提升7%。
2.1 实验数据的获取
由于国内没有适合本文研究并且公开数据的开放域中文知识库,我们决定从互联网中抽取开放域实体关系三元组作为实验数据。通过观察,我们发现百度百科有一部分被称为“infobox”描述词条属性的结构化内容,该部分包含大量潜在的实体关系信息,我们希望从中获取实体关系三元组作为实验使用的实体关系三元组数据。
“infobox”*https: //en.wikipedia.org/wiki/Infobox一词源于维基百科,是一种包含属性—值对结构化文档。作为全球最大的中文百科网站,百度百科也借鉴了这一设计,在大部分词条页面中都设有“infobox”,用于记录该词条的重要属性—值对信息,如图2所示。

图2 百度百科中“哈尔滨工业大学计算机科学与技术学院”一词的infobox
“infobox”中包含的是与词条相关的众多“属性—值”对。这些“属性—值”对与词条可以组成三元组,但这种三元组并不都是我们要找的实体关系三元组,因为“属性—值”对中的值并不一定是实体,如“规格严格,功夫到家”,而“周玉院士”就是一个实体,所构成的即为实体关系三元组。
通过观察发现,词条的百科页面中存在很多的具有链接的词汇,这部分文本一般称为锚文本。而百科页面中的这些锚文本是指向另一个百科词条页面的。如果我们假设百度百科中收录的词汇全部为实体词(百科中记录的一般是现实世界中的概念,可以认为其大部分是实体),那么百科页面中的锚文本也即是实体词汇。
我们可以认为在“infobox”中含有锚文本的“属性—值”对为实体关系。如图2中属性“知名校友”以及“专职院士”,这两个属性值都是锚文本,由此我们可以获取三个实体关系三元组:
(哈尔滨工业大学计算机科学与技术学院,知名校友,王天然)、(哈尔滨工业大学计算机科学与技术学院,知名校友,怀进鹏)、(哈尔滨工业大学计算机科学与技术学院,专职院士,方滨兴)。
据此方法,我们从百度百科的“infobox”中共获取2 438 145条开放域实体关系三元组*Code: https: //github.com/twjiang/baike_crawler。虽然可能存在一些噪声数据,但就像知识库允许存在少量噪声数据一样,这些噪声数据对实验结果并无太大影响。
将获得的三元组数据集作为规模最大的“all数据集”,另从其中抽取50余万的三元组组成“small数据集”。设置不同规模的数据集原因在于使用小规模数据集进行课题研究前期的快速实验测试,以快速改进模型,设置合适的测试实验并记录结果。
将三元组数据集划分为两个集合: 训练集、测试集,并需要使得两个集合满足独立同分布条件,以用于模型的训练和测试。除独立同分布外,两个集合需满足以下三个条件。
1) 测试集中的实体集合为训练集中实体集合的子集,即测试集中所有三元组涉及到的实体在训练集中都有出现,其目的在于防止测试时实体词存在未登录,从而找不到对应的实体向量。
2) 测试集中的关系指示词集合为训练集中关系指示词集合的子集,即测试集中所有三元组涉及到的关系指示词在训练集中都有出现,其目的在于防止测试时出现未登录的关系指示词,导致找不到对应的关系指示词向量。
3) 训练集和测试集的三元组交集为空,即不存在既在训练集中出现又在测试集中出现的三元组。
获得的两个不同规模的实验数据集如表1所示。
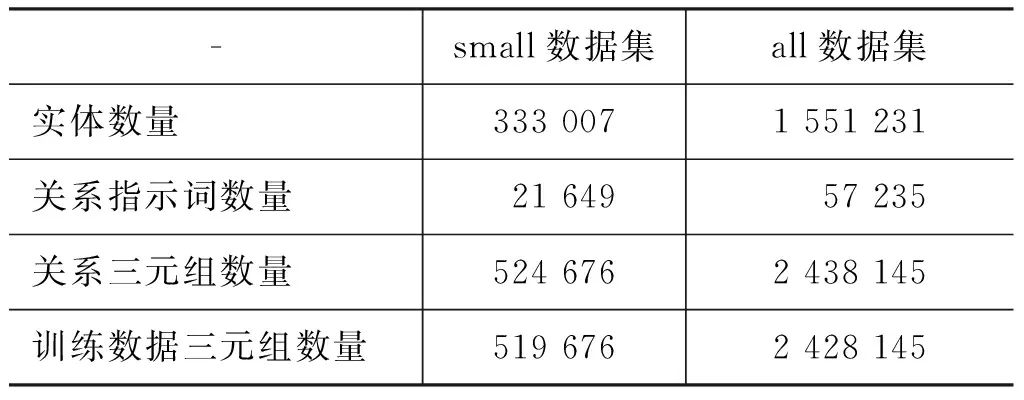
表1 实验用到的两个不同规模的数据集
2.2 关系指示词推理
为何要进行关系指示词推理?在此之前,我们需要引出一个概念——“知识库关系补全”。知识库关系补全是指: 对于现有知识库中有潜在关系但未在知识库中标明的两个实体进行关系推理。如知识库中有以下两个实体关系三元组:
(泰坦尼克号,主要角色,杰克),(莱昂纳多,饰演,杰克)
那么,我们希望推理出如下关系以补全到现有知识图谱中:
(泰坦尼克号,主演,莱昂纳多)
总结下来,知识库关系补全需要两个阶段: 存在潜在关系实体对的发现、对潜在关系进行推理。本实验假设已经识别出存在潜在关系的实体对,主要任务是测试通过表示学习得到的向量空间中的知识库,是否可以对这个潜在关系进行推理,并给出较为准确的答案抑或包含答案的候选集合。
我们将测试数据中的三元组的关系指示词“挖空”,基于已训练好的实体和关系指示词的向量表示对关系指示词进行推理,并和标准答案进行对比,以计算准确率。
具体的测试方法: 对于每一对实体,遍历所有的关系指示词组合成一个三元组,对每个这样的三元组,计算头实体与关系指示词相加得到的向量到尾实体向量在空间中的距离d,距离d越小说明三元组成立的可能性越大。设定一个距离阈值,对距离d小于阈值的三元组按照距离d升序排列(过程简图见图3)。对每一对实体记录排名前十的三元组的关系指示词,记录正确关系指示词的排名在前十名的比例,以及排名为第一的比例分别作为准确率,并分别记录召回率,计算F值。

图3 关系指示词推理方法简图
这里我们需要对阈值进行确定。在确定阈值的实验中,不同阈值的结果如表2、表3所示。其中threhold表示阈值的取值,“--”表示未设定阈值;@hit_10和@hit_1分别表示正确关系指示词的排名在前十名的比例和排名为第一的实体对数目占所有存在d小于阈值的关系指示词的实体对数目的比例;recall_hit_10和recall_hit_1表示正确关系指示词的排名在前十名的比例和排名为第一的实体对数目占所有测试集中实体对数目的比例。

表2 测试不同阈值对关系指示词推理实验结果(small数据集)

表3 测试不同阈值对关系指示词推理实验结果(all数据集)
表2记录在small数据集中测试不同阈值对关系指示词推理实验结果。通过表2中的数据,首先可以发现TransE_ipv的效果明显优于原始TransE的训练方法,无论是准确率还是召回率都有大幅度的提升,究其原因在于TransE_ipv在构造负例三元组的时候考虑到了关系指示词,不仅仅是替换头尾实体。这对于开放域知识库中关系指示词数量较大的特点极为重要。另外,通过表 2可以发现,在TransE_ipv中随着阈值的增加召回率随之增加,但准确率却在下降。由于在本实验中我们更关注于准确率,所以最佳阈值锁定在0.7和1.0,观察发现在阈值从0.7过渡到1.0时,虽然准确率有所下降,但召回率却翻倍增长,所以将最佳阈值定为1.0。
表3记录在all数据集中测试不同阈值对关系指示词推理实验结果。同样,我们将阈值定为1.0,另外,很容易发现在all数据集中的各项数据相比small数据集中有所下降,其原因是由于硬件条件限制导致两者的训练方式不同造成的。
综合上述实验结果并选取最佳的阈值,得到表4所示的本实验在small数据集和all数据集的最终结果,其中F1_hit_10和F1_hit_1表示对应的F1值。相比于符号化的网状知识库表示,使用表示学习得到的实体分布式表示可以通过计算高效地推理出实体对中潜在的关系,召回率可以达到40%左右,准确率高达80%左右。

表4 关系指示词推理测试的实验结果
2.3 尾实体推理
有些情况下,我们希望获取某个实体具有特定关系的实体,比如给定实体A和关系B,我们希望找到和实体A具有关系B的实体,我们称这个实体为C。当三元组(A,B,C)不存在于知识库中时,我们希望通过简单的计算即可得到较为准确的C,抑或得到一个候选序列且C存在于这个候选序列中。
本实验的目的就是当(A,B,C)不存在于知识库中时,测试通过表示学习得到的向量空间中的知识库是否可以推理出尾实体,给出较为准确的答案抑或包含答案的候选集合。
我们将三元组的尾实体“挖空”,基于已训练好的实体和关系指示词的向量表示对测试集三元组中的尾实体进行推理,并和标准答案进行对比,以计算准确率。
具体的测试方法和关系推理相似,对于每一对头实体、关系指示词组合,遍历所有的实体作为尾实体组合成一个三元组,对每个这样的三元组计算头实体与关系指示词相加得到的向量到尾实体向量在空间中的距离d,距离d越小说明三元组成立的可能性越大。之后的步骤设置了两种方法。
方法一设定一个距离阈值,对距离d小于阈值的三元组按照距离升序排列,对每一对实体记录排名前十的三元组的尾实体(方法一简图见图4),记录正确尾实体的排名在前十名的比例,以及排名为第一的比例作为准确率,并分别记录召回率。
方法二设定一个距离阈值,对距离d小于阈值的三元组取出其头实体和尾实体,其中头实体即为A,尾实体即为要推理的目标实体(记为C’),然后利用A和C’对关系进行推理,记录正确关系B的排名,使排名和距离d相乘作为对C’的打分,认为分数越少越有可能是正确实体。方法二是将方法一和关系指示词推理相结合,利用关系指示词推理的结果反馈指导实体推理。
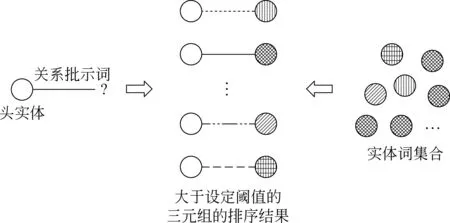
图4 尾实体推理方法一简图
对比方法一、方法二的测试结果如表5所示。实验结果显示方法二的效果更好。本实验也存在阈值的选择问题,由于1.0是关系推理时的最佳阈值,这里只增加了一组阈值为1.3的对比实验,实验结果如表6所示。综合来看阈值为1.0时的F值较高,选择1.0为最佳阈值取值。综合上述实验结果并选取最佳的阈值,得到表7所示的本实验在small数据集和all数据集的最终结果。
通过观察发现尾实体推理的准确率远不如关系推理,分析可能是实体具有长尾分布的特点造成的。这是很多大规模数据具有的。这些长尾部分的实体和其他实体有极少的关系联系,从而导致这部分实体涉及的三元组较少,进而导致无法充分对其进行训练。

表5 利用方法一、二做尾实体推理测试的实验结果(small数据集)

表6 阈值为1.0、1.3的尾实体推理测试的实验结果(small数据集)

表7 尾实体推理测试的实验结果(TransE_ipv)
为了验证可能是实体的数据的长尾无法充分训练,进而影响准确率,我们设计实验进行研究。在之前的训练中每次迭代为每个训练三元组构造一个负例三元组进行训练。为了缓解训练不充分的问题,改进算法在每次迭代中对每个训练三元组构造50个负例三元组进行训练(标记为TransE_ipvn),使用相应的测试集进行尾实体推理测试,最后在small数据集上得到的实验结果如表8所示。

表8 尾实体推理测试的实验结果(small数据集)
实验结果显示@hit_1和recall_hit_1都有显著提升,可见尝试增加负例三元组的数量对尾实体推理有较好的影响。当增加大量负例三元组时,尾实体推理效果可能会得到大幅度提升,但限制于训练时间原因,本实验未继续增加负例三元组数量进行测试。
3 结束语
基于传统网状结构的知识库无法有效地进行知识推理,尤其当知识库的知识规模不断扩大,基于网状结构知识库的推理很难较好地满足实时计算的需求。因此,本文使用TransE模型对开放域中文知识库进行表示学习,并对模型的代价函数进行改进,主要研究基于知识库表示学习的知识推理,包括对实体关系三元组中关系指示词和尾实体的推理。实验结果显示,基于知识库表示学习的关系指示词推理准确率可以达到80%以上,且无需设计复杂的算法。在进行应用知识分布表示的尾实体推理测试中,准确率和关系指示词推理相比效果较差,我们对其原因进行分析并验证,使用增加训练过程中负例三元组的方法可以将准确率提升7个百分点,同样无需设计复杂算法即可实现对尾实体的推理。
[1] Miller G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
[2] Bollacker K, Evans C, Paritosh P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. ACM, 2008: 1247-1250.
[3] Miller E. An introduction to the resource description framework[J]. Bulletin of the American Society for Information Science and Technology, 1998, 25(1): 15-19.
[4] 刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016,53(2): 247-261.
[5] Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2013, 35(8): 1798-1828.
[6] Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]//Proceedings of International conference on Neural Information Processing Systems. 2013: 2787-2795.
[7] Bordes A, Weston J, Collobert R, et al. Learning structured embeddings of knowledge bases[C]//Proceedings of the Conference on Artificial Intelligence. 2011(EPFL-CONF-192344).
[8] Bordes A, Glorot X, Weston J, et al. A semantic matching energy function for learning with multi-relational data[J]. Machine Learning, 2014, 94(2): 233-259.
[9] Bordes A, Glorot X, Weston J, et al. Joint learning of words and meaning representations for open-text semantic parsing[C]//Proceedings of International Conference on Artificial Intelligence and Statistics. 2012: 127-135.
[10] Socher R, Chen D, Manning C D, et al. Reasoning with neural tensor networks for knowledge base completion[C]//Proceedings of International conference on Neural Information Processing Systems. 2013: 926-934.
[11] Wang Z, Zhang J, Feng J, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of AAAI. 2014: 1112-1119.
[12] Lin Y, Liu Z, Sun M, et al. Learning Entity and Relation Embeddings for Knowledge Graph Completion[C]//Proceedings of AAAI. 2015: 2181-2187.
[13] Ji G, He S, Xu L, et al. Knowledge Graph Embedding via Dynamic Mapping Matrix[C]//Proceedings of ACL. 2015: 687-696.
[14] 安波,韩先培,孙乐,等. 基于分布式表示和多特征融合的知识库三元组分类[J]. 中文信息学报,2016,30(06): 84-89,99.
[15] 来斯惟,徐立恒,陈玉博,等. 基于表示学习的中文分词算法探索[J]. 中文信息学报,2013,27(05): 8-14.
[16] Turian J, Ratinov L, Bengio Y. Word representations: a simple and general method for semi-supervised learning[C]//Proceedings of the 48th Annual meeting of the Association for Computational linguistics. Association for Computational Linguistics, 2010: 384-394.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
制造技术与机床(2019年6期)2019-06-25 10:17:46
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
