
基于空间投影和关系路径的地理知识图谱表示学习
2018-05-04 06:46:19段鹏飞熊盛武毛晶晶
中文信息学报 2018年3期
段鹏飞,王 远,熊盛武,毛晶晶
(1. 武汉理工大学 计算机科学与技术学院,湖北 武汉 430070;2. 武汉理工大学 交通物联网湖北省重点实验室,湖北 武汉 430070;3. 南京大学 计算机科学与技术系,江苏 南京 210023)
0 引言
随着大数据技术的发展,得益于Linking Open Data等公共数据集项目的展开,互联网也从文档万维网向数据万维网发展。在此背景下,Google为了改善搜索结果,于2012年重新提出了知识图谱(Knowledge Graph)[1]。随后,其他搜索引擎公司也开始构建知识图谱,例如,国内搜狗提出的“知立方”和百度的“知心”。知识图谱除了应用在搜索引擎中,还是自动问答等智能应用的基础,例如IBM公司开发的Watson系统和日本的高考机器人Todai Robot。
传统的知识图谱一般采用<实体1,关系,实体2>三元组的方式来表示知识。该种方法可以较好地表示事实性知识,但对很多模糊知识和复杂形式知识,则表现出能力不足。以地理知识图谱为代表的特定领域知识图谱,实体间往往有很强的语义关联,以网络形式来组织知识图谱中的知识,当进行知识推理和知识融合的时候需要设计特定的图算法,计算效率低;而且三元组的知识表示形式无法有效地度量和利用实体间的语义关联关系。
以深度学习[2]为代表的表示学习[3],最近在自然语言处理、图像分析和语音识别等领域取得极大进展。在自然语言处理方面,基于深度学习的词向量表示模型—word2vec模型[4]的提出,掀起了学者对知识表示学习的研究热潮。其中,最引人注目的要属Bordes受到word2vec模型中的词向量在语义空间的平移不变现象的启发而提出的TransE模型[5]。TransE模型由于其在构建大规模知识图谱时表现出了简单、高效等特点,自提出以来,许多研究者都尝试在TransE模型的基础上做进一步地扩展和应用。由于TransE方法无法很好地处理1对多、多对1及多对多类型的关系,安波等提出了一种特征融合的方法TCSF[6],通过综合利用三元组的距离、关系的先验概率及实体与关系上下文的拟合度进行三元组分类;Lin等人提出了TransR模型[7],基于空间投影来对TransE进行扩展,提高复杂关系建模能力,但该模型只学习了三元组结构信息;针对这种情况,Lin等人提出了PTransE模型[8],基于关系路径对TransE进行扩展,用来对知识图谱中的关系进行推理。本文考虑结合TransR模型在处理复杂关系时的能力和PTransE模型充分利用了关系路径中语义信息的优势,建立了一个新的基于空间投影和关系路径的知识表示学习算法,提升知识图谱中知识表示的区分能力。
1 翻译模型及其扩展
1.1 TransE模型
以TransE模型为代表的知识表示学习模型已经在实体链接、关系抽取和知识推理等知识图谱应用中,取得了瞩目的效果[9]。TransE模型将知识图谱中的关系看作是在语义空间中实体间的平移向量[4]。

图1 TransE模型简单原理图
对于三元组(h,r,t),TransE模型将关系r定义为一个平移向量r∈Rk(k为语义空间维度),嵌入到语义空间的实体向量h,t可以通过关系向量r连接。TransE模型的损失函数定义为式(1)。
fr(h,t)=||h+r-t||L1/L2
(1)
TransE模型参数少、复杂度低并且在构建大规模知识图谱中表现出了简单、高效的特点。但也正是由于TransE模型的简单,从而导致了它在复杂关系建模、多源信息融合、关系路径建模等方面的局限性。
1.2 基于空间投影的翻译模型
针对TransE模型在处理知识图谱中复杂关系能力缺失的问题,Lin等人提出了TransR模型[7],将实体看成多种属性的综合,不同关系将专注不同的属性,将实体、关系分别嵌入实体空间Rm、关系空间Rn(m,n均表示空间的维度,并且在TransR模型中m和n可以相同)。
对于每一个三元组(h,r,t),TransR模型设置实体向量h,t∈Rm,关系向量r∈Rn。先将位于实体空间Rm的头、尾实体,通过投射矩阵Mr(Mr∈Rm×n)投射到关系空间Rn,得到位于关系空间的头实体hr、尾实体tr。然后在关系空间中平移,使hr+r≈tr。
其中,被投射到关系空间中得到的实体向量被定义为式(2)。
hr=hMr,tr=tMr
(2)
相应的损失函数被定义为式(3)。
fr(h,t)=||hr+r-tr||L1/L2
(3)
TransR模型采用空间投影在TransE模型的基础上进行扩展,使模型处理复杂关系的能力得到显著提高。
1.3 基于关系路径的翻译模型
针对这种情况,Lin等对TransE模型进行扩展,提出了基于关系路径的PTransE模型[8]。
(4)

PTransE模型通过寻找实体对间的关系路径,并通过计算关系路径的可信度和对关系路径进行表示,来利用蕴含在关系路径的语义信息,在关系路径方面对TransE模型进行了扩展,为知识表示学习的研究打开了新的方向。
2 基于空间投影和关系路径的翻译模型
TransR模型将实体看作属性的综合体,不同关系专注实体的不同属性。通过采用空间投影的方式,使模型处理复杂关系的能力得到显著提高。PTransE模型试图解决TransE和TransR等模型只局限于学习三元组结构信息的缺陷。通过寻找实体对间的关系路径,并且将关系路径也嵌入到语义空间中,利用关系路径中存在的语义信息,在学习三元组中直接关系的同时,也对关系路径进行学习。TransR模型和PTransE模型是在两个不同的方面对TransE模型进行扩展。
因此,本文考虑结合TransR模型在处理复杂关系时的能力和PTransE模型充分利用了关系路径中语义信息的优势,建立一个新的模型PTransW(Path-based TransE and Considering Relation Type by Weight),提升知识图谱中知识表示的区分能力。并且在TransR模型中,三元组的关系嵌入到同一语义空间中,对于关系路径的寻找、可信度计算和关系路径的表示提供了条件。
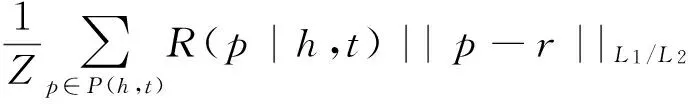
结合TransR模型和PTransE模型两者优势的新模型损失函数定义为式(5)。
(5)
h,t在从实体空间Rm经过投射矩阵Mr∈Rm×n投射到关系空间Rn时,投射矩阵Mr依赖于关系r,同一个实体在不同的关系上时,因为所表现的属性不同,将会被投射到关系空间中的不同位置。关系r分为四种类型,为了让h,t在投射时考虑到所属关系的关系类型,在同一种关系类型上的实体更可能被投射到同一区域,将引入一个与关系类型相关的权重ωr。权重ωr与变量hrptr(对于关系r,数据集中每个尾实体对应的头实体平均个数)和trphr(对于关系r,每个头实体对应的尾实体平均个数)相关,参考Fan等在TransM模型[10]中的做法,将权重ωr定义为式(6)。
(6)
则h,t在从实体空间Rm经过投射矩阵Mr投射到关系空间Rn时变为hr=ωrhMr,tr=ωrtMr。
再结合式(5),PTransW模型的损失函数则定义为式(7)。
G(h,r,t)=||ωrhMr+r-ωrtMr||L1/L2
(7)
其中,R(p|h,t)是实体对(h,t)间的关系路径p的可信度;Mr是将实体从实体空间Rm投射到关系空间Rn的投射矩阵,Mr∈Rm×n;p是关系路径的嵌入向量表示;
在训练过程中,对h、t和r对应的嵌入向量h、r和t进行约束。∀h,r,t,有||h||2≤1,||r||2≤1,||t||2≤1,||ωrhMr||2≤1以及||ωrtMr||2≤1。
PTransW模型同样需要计算关系路径的可信度及对关系路径进行表示。关系路径的可信度计算可以采用PTransE提出的PCRA算法[8]。PTransE的数据实验结果也已经表明采用相加的语义组合方式来表示关系路径取得的效果比按位相乘和循环神经网络要好,所以PTransW模型将采用相加方式来表示关系路径。并且在训练时,因为运算时间,本文只考虑两步关系路径。
训练时,将采用随机梯度下降来最小化目标函数。根据式(7),将PTransW模型的优化目标形式化表示为式(8)。

(8)
与TransE一样,在实际训练过程中,采用最大间隔法来对知识表示的区分能力进行提升。L(h,r,t),L(h,P,t)分别表示为式(9)和式(10)。
(9)
(10)
其中,[x]+=max(0,x)表示返回0和x之间较大的值;γ为正确三元组损失函数值与错误三元组损失函数值之间的间隔距离;S是正确三元组所属集合,S-为错误三元组所属集合(负样本)。错误三元组是通过替换正确三元组的头实体、尾实体或关系得到,S-={h′,r,t}∪{h,r′,t}∪{h,r,t′}。
3 实验对比分析
3.1 数据集
本文采用FB15K和GEOGRAPHY数据集对模型进行验证。
FB15K: Freebase是一个由元数据组成的大型知识图谱,整合了网上大量的资源,目前包含了12亿个三元组和超过8千万的实体。文献[5]从Freebase中抽取了一个稠密子图FB15K用于TransE模型的实验,该数据集包含有592 213个三元组、14 951个实体和1 345条关系。
GEOGRAPHY: 地理数据集是本课题组从基础教育地理学科的网络文本资源中,通过信息抽取等技术构建得到的三元组集合。地理数据集包含有99 063个三元组、69 123个实体和6 961条关系。

表1 数据集的统计
3.2 基于FB15K数据集的链接预测实验
实验前,对hrptr和trphr进行统计,然后根据hrptr、trphr计算关系r的权重ωr,FB15K数据集中共有1 345条关系,则对应着1 345个权重,但是由于关系类型只有四种,权重的分布也依据所属关系类型,如图2所示。
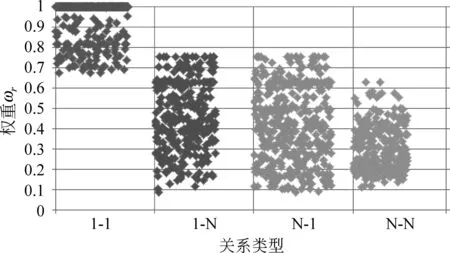
图2 关系权重ωr分布图
3.2.1 参数调节
我们根据前人的经验,将PTransW模型在数据集FB15K上的步长α范围设定为{0.1,0.01,0.001};间隔γ设定为{1,2,4};为了便于计算,实体空间的维度m和关系空间的维度n相同,设定范围为{20,50,100},模型运用随机梯度下降优化时总共迭代500次。通过在验证集上作实体预测实验来确定参数。

表2 不同参数在验证集上的实体预测结果表
即使将参数设定了范围,对每一组训练/验证集也有3×3×3×2=54种情况需要考虑。由于数据集规模较大和受限于模型本身的复杂度,将54种情况都训练、验证一遍需要极大的计算工作。因此,我们采用控制变量的思想来确定参数,再在验证集上进行验证。但有可能出现两个或多个参数相互作用影响结果的情况,为了避免该种情况,再对参数进行随机替换并在验证集上验证。最终,确定了PTransW模型在数据集FB15K上的参数组合为:α=0.001,γ=1,m=n=20,采用L2范式。
3.2.2 实体预测
为了便于比较,我们采用文献[5]和文献[8]中所用的方法作为基准线。由于都是基于数据集FB15K进行实验,并且采用相同的评估指标,所以直接参考论文数据,结果如表3所示。

表3 FB15K数据集实体预测计算结果
从表中可以看出PTransW模型相比于其他模型,Mean Rank指标和Hits@10指标的效果远优于其他模型(包括TransR 和PTransE),说明我们将根据关系类型进行空间投影和利用关系路径语义信息相结合是成功的。
在实验过程中,我们发现测试集的59 071个三元组中,有2 230个三元组的头、尾实体对间不存在关系路径,那些不包含关系路径的三元组的预测得到的排名都很靠后,从而将测试集中所有三元组的平均排名拉高。因此,我们剔除了那2 230个不存在关系路径的三元组,对剩余的56 841个三元组的排名重新进行了统计,统计结果为表3中PTransW(only-path)所在行。从结果可以得知,剔除了2 230个不存在关系路径的三元组后,Mean Rank的值降低很明显。对于有关系路径的三元组,PTransW模型预测的结果更准确。
为了进一步观察PTransW模型在复杂关系建模时的能力,我们按关系类型做了统计,结果如表4所示。
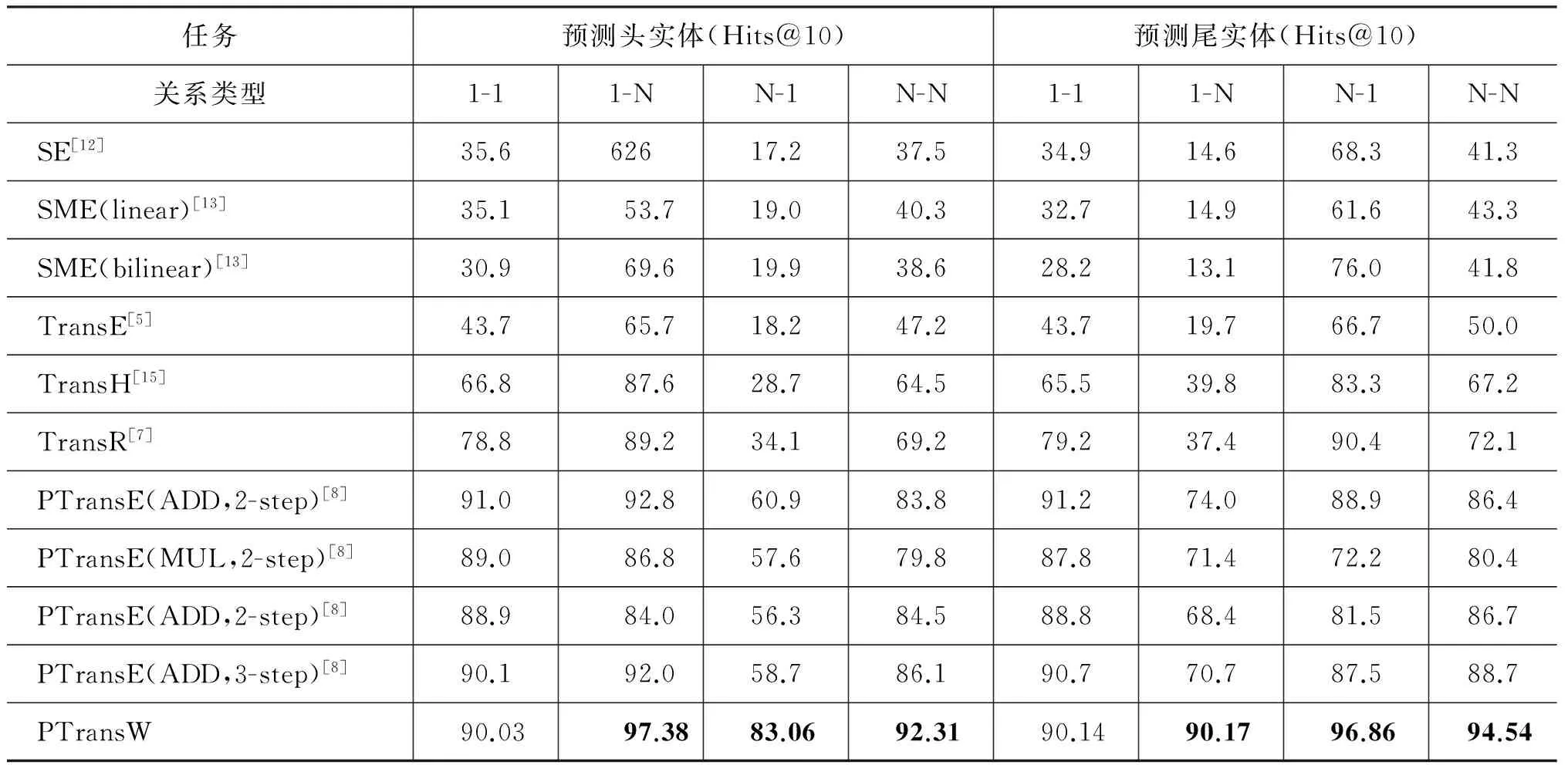
表4 FB15K数据集上基于关系类型的计算结果
从表4中可以看出PTransW模型在1-N、N-1和N-N复杂关系建模方面,Hits@10指标明显优于其他模型;在1-1关系上,也与表现最好的模型PTransE(ADD,2-step)的结果接近。PTransW模型对比TransE、TransR和PTransE等模型,在复杂关系建模的能力上得到了显著的提高。
3.2.3 关系预测
关系预测,是通过给定(h,t)来预测关系r。我们采用文献[8]中所用的方法作为基准线,与PTransW模型作比较。由于都是基于FB15K数据集进行实验,并且采用相同的评估指标,所以直接参考它们的数据结果,整理为表5所示。
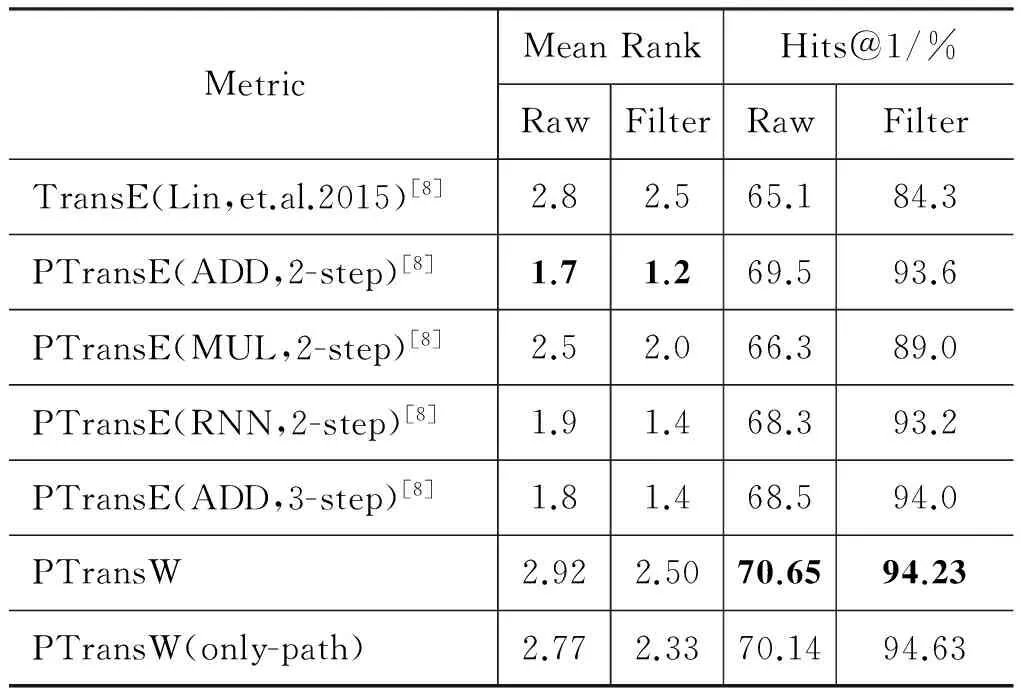
表5 FB15K数据集关系预测计算结果
表中的Hits@1是指测试集中排名在第一的三元组占整个测试集的比例。从表中可以看出,PTransW模型和其他模型相比,Mean Rank这项指标要比PTransE(ADD,2-step)差,在测试集中有小部分三元组的排名极靠后,所以导致平均排名较差。而Hits@1这项指标则比其他模型稍高。我们同样将2 230个不存在关系路径的三元组剔除,得到PTransW(only-path),发现与不剔除的结果相比,差别并不明显。
在算法复杂度方面,PTransW相较于PTransE增加了投射矩阵M,运行时间略有增加,但增加的时间相较于PTransE原始运行时间小很多,所以该方法不会增加过高的时间开销。
3.3 基于GEOGRAPHY数据集的链接预测实验
3.3.1 参数调节
在GEOGRAPHY数据集上,不仅需要对PTransW模型进行训练并做链接预测实验,还需要用TransE模型、TransR模型和PTransE模型在GEOGRAPHY数据集上进行训练,并将链接预测实验的结果与PTransW模型做对比分析。
因此,设置TransE在GEOGRAPHY数据集中的参数范围为随机步长α设定的范围{1,0.1,0.01};间隔γ设定为{1,2,4};语义空间维度k的范围为{20,50,100},正则化方式为L1/L2。经过在验证集上采用与前面3.2.1相同方法进行参数调节,确定参数组合为:α=0.01、γ=1、k=100以及采用L1正则化方法,并且随机梯度下降时迭代1 000次。对于TransR模型,其确定参数组合为α=0.001、γ=1、m=n=100以及采用L1正则化方法,迭代1 000次。对于PTransE模型,最后确定参数组合为α=0.001、γ=1、k=100以及采用L1正则化方法,迭代1 000次。对于PTransW模型,最后确定参数组合为α=0.001、γ=1、m=n=100以及采用L1正则化方法,迭代500次。
3.3.2 实体预测
实体预测实验中,与上文一致通过给定(h,r)来预测t以及给定(r,t)来预测h。将TransE、TransR、PTransE模型的结果进行比较,如表6所示。

表6 GEOGRAPHY数据集实体预测计算结果
从表6中可以看出,之前在FB15K数据集上表现较好的PTransE模型和PTransW模型在GEOGRAPHY数据集上,实体预测结果反而不如TransE模型和TransR模型。我们分析,可能是由于GEOGRAPHY数据集训练规模较小。数据集FB15K包含14 951个实体和1 345条关系,有592 213个三元组;反观数据集GEOGRAPHY,有69 123个实体和6 961条关系,却只包含有99 063个三元组。所以,相对复杂的PTransE模型和PTransW模型在数据集GEOGRAPHY上训练不够充分,并不能发挥它们的优势。
3.3.3 关系预测
在关系预测子实验中,也是通过给定(h,t)来预测关系r。将TransE、TransR、PTransE模型在数据集GEOGRAPHY上做关系预测实验,并将所求结果进行对比分析,如表7所示。
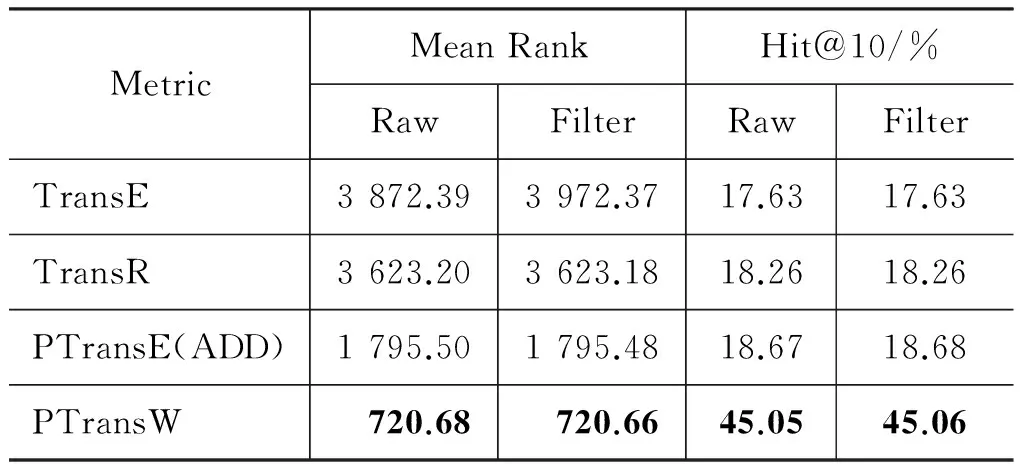
表7 GEOGRAPHY数据集关系预测计算结果
从表7中可以看出,考虑了关系路径和反向关系的PTransE模型和PTransW模型取得的效果明显比TransE和TransR要好,其中,PTransW的效果尤为突出。
4 总结
针对TransE模型在处理知识图谱中复杂关系能力缺失及只局限地使用三元组结构信息的问题。我们将TransR模型和PTransE模型进行结合,并对结合后的模型做了进一步地改进。在空间投影时考虑关系类型,通过加入关系类型的权重,使实体在投射时能在不同关系类型上有所区别。未来需要对知识图谱中的知识类型进行更具体地划分,并对不同类型的知识表示进行研究。除了链接预测,将知识表示学习应用到关系抽取、实体消歧、实体识别等更多任务中,来进一步地探究以及验证知识表示学习的有效性。
[1] Singhal A. Introducing the knowledge graph: things, not strings[EB/OL]. http: //googleblog.blogspot.co.uk/2012/05/introducing-knowledge-graph-things-not.html, 2012.
[2] Bengio Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127.
[3] Bengio Y, Courville A, and Vincent P.Representation learning: A review and new perspectives [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013.35(8): 1798-1828.
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26: 3111-3119.
[5] Bordes A, Usunier N, Garcia-Duran A, Weston J, Yakhnenko O. Translating embeddings for modeling multi-relational data[C]//Proceedings of In Advances in Neural Information Processing Systems 26. Curran Associates, Inc. 2787-2795.
[6] 安波, 韩先培, 孙乐,等. 基于分布式表示和多特征融合的知识库三元组分类[J]. 中文信息学报, 2016, 30(6): 84-89.
[7] LinY, Liu Z, Sun M, Liu Y, Zhu X. Learning Entity and Relation Embeddings for Knowledge Graph Completion[C]//Proceedings of the 29th AAAI Conference on Artificial Intelligence.
[8] LinY, Liu Z, Luan H, Sun M, Rao S, Liu S. Modeling Relation Paths for Representation Learning of Knowledge Bases[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), 2015.
[9] 刘知远, 孙茂松, 林衍凯, 谢若冰. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 1-2.
[10] Fan M, Zhou Q, Chang E, et al. Transition-based knowledge graph embedding with relational mapping properties[C]//Proceedings of the 28th Pacific Asia Conference on Language, Information, and Computation. 2014: 328-337.
[11] Nickel M,Tresp V, Kriegel H. A three-way model for collective learning on multi-relational data[C]//Proceedings of ICML. New York: ACM, 2011: 809-816.
[12] Bordes A, Weston J, Collobert R, et al. Learning structured embeddings of knowledge bases[C]//Proceedings of AAAI. Menlo Park, CA: AAAI, 2011: 301-306.
[13] Bordes A, Glorot X, Weston J, et al. Joint learning of words and meaning representations for open-text semantic parsing[C]//Proceedings of AISTATS. Cadiz, Spain: JMLR, 2012: 127-135.
[14] Jenatton R, Roux N L, Bordes A, et al. A latent factor model for highly multi-relational data[C]//Proceedings of NIPS. Cambridge, MA: MIT Press, 2012: 3167-3175.
[15] Wang Z, Zhang J, Feng J, Chen Z. Knowledge graph embedding by translating on hyperplanes[C]//Proceedings of AAAI, 2014: 1112-1119.
[16] Bollacker K, Evans C, Paritosh P, et al. Freebase: A collaboratively created graph database for structuring human knowledge[C]//Proceedings of KDD, New York: ACM, 2008: 1247-1250.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
