
美团外卖自动化业务运维系统建设
2018-05-03 10:01刘宏伟
信息通信技术 2018年1期
刘宏伟
美团北京102208
引言
美团外卖业务在互联网行业是非常独特的,其定位是“围绕在线商品交易与及时送达的O2O电商交易平台”。不仅流程复杂,历经用户下单→系统发给商家→商家准备外卖→配送,到最后用户收到商品(比如热乎乎的盒饭),整个过程的时间需要控制在半小时之内,而且压力和流量在午、晚高峰时段非常集中。在这背后,整个产品线上还会涉及很多数据分析、统计、结算、合同等各个端的交互,对一致性的要求高。同时,外卖业务的增长非常迅猛,自2013年11月上线到最近峰值突破1 600万,还不到4年。在这种情况下,一旦出现事故,单纯靠人工排查解决问题,存在较多的局限性。为了提升效率需要尽可能自动化,而自动化的前提需要有足够准确的检测与诊断结果,检测与诊断结果又需要有贴近真实业务场景的工具不断验证。
1 需要解决的问题
系统在日常的业务运维工作中经常会碰到一些问题困扰着开发人员,如图1所示。
1)各种维度的事件通知、报警事件充斥着开发人员的IM,需要花很多精力去配置和优化报警阈值、报警等级才不会出现很多误报。希望可以将各种服务的报警指标和阈值标准化、自动化,然后自动收集这些事件进行统计。一方面可以帮助开发人员提前发现问题潜在的风险,另一方面为能够找出问题的根本原因提供有力的数据支持。
2)公司有多套监控系统,它们有各自的职责定位,但是互相没有关联,所以开发人员在排查问题时需要带着参数在不同的系统之间切换,这就降低了定位的效率。
3)项目代码中会有大量的降级限流开关,在服务异常时进行相应的保护操作。这些开关随着产品快速地迭代,并不能确定它们是否还有效。另外,需要较准确地进行容量规划以应对快速增长的业务量。这些都需要通过全链路压测进行不断地验证,并发现性能瓶颈,有效地评估服务容量。
4)开发人员收到各种报警之后,通常都会根据自己的经验进行问题的排查,这些排查经验完全可以标准化(比如对某个服务的平均耗时异常,需要进行的排查操作),问题排查流程标准化之后,就可以通过计算机自动化。为了提高诊断的准确度,就需要将这个流程更加智能化,减少人为参与。
2 核心目标
公司希望通过一些自动化措施提升运维效率,从而将开发人员从日常的业务运维工作中解放出来,先来看一个用户使用场景,如图2所示,触发服务保护有两条路径。

图2 自动化业务运维系统核心建设目标
1)第一条,当用户在前期接收到诊断报警后,直接被引导进入该报警可能会影响到业务大盘。这时要查看业务图表,如果影响到业务,引导用户直接进入该业务图表对应的核心链路,定位出问题的根本原因,进而再判断是否要触发该核心链路上对应的服务保护开关或预案。
2)第二条,用户也可以直接通过诊断报警进入对应的核心链路,查看最终引起异常的根本原因,引导用户判断是否需要触发相应的服务保护预案。
发现问题→诊断问题→解决问题,这个过程每一步都需要不断地提升准确度,具体数据可以通过全链路压测来获得,当某些场景准确度非常高的时候,就可以变为自动化方案;因此,核心目标是,当整个方案可以自动化进行下去之后,对于用户来说的使用场景就变成了:收到异常报警→收到业务服务恢复通知。随着自动化方案越来越完备,开发人员可以更加关注业务逻辑的开发。
3 重点系统体系建设
3.1 体系架构
如图3所示,在自动化业务运维系统中,业务大盘与核心链路作为用户使用的入口,一旦用户查看业务指标出现问题,就需要快速定位该业务指标异常的根本原因。系统通过对核心链路上服务状态的分析,帮助开发人员定位最终的问题节点,并建议开发人员需要触发哪些服务保护预案。业务大盘的预测报警、核心链路的红盘诊断报警以及已经收集到各个维度的报警事件,如果能对它们做进一步的统计分析,可以帮助开发人员从更加宏观的角度提前发现服务可能存在的问题,相当于提前对服务做健康检查。开发人员需要定期通过全链路压测来不断验证问题诊断和服务保护是否有效,在压测时可以看到各个场景下的服务健康状态,对服务节点做到有效的容量规划。

图3 业务监控运维体系架构
3.2 业务大盘
外卖业务会有非常多的业务指标进行监控,业务指标和系统指标、服务指标不同,需要业务方根据不同的业务自行上报监控数据[1]。业务大盘作为业务运维系统的使用入口,可以让开发人员快速查看自己关心的业务指标的实时状态以及最近几天的走势。
如图4所示,业务大盘不光需要展示业务监控指标,还需要有很强的对外扩展能力。

图4 业务监控大盘及拓展能力
1)当出现业务指标异常时,根据后台的监控数据分析,可以手动或自动进行事件标记,告知开发人员是什么原因引起业务指标的波动,做到用户信息快速同步。
2)可以带着时间戳与类型快速引导开发人员进入其它监控系统,提高开发人排查问题的效率。该系统会定期进行全链路压测,同时为了压测数据不污染真实的业务数据,会对压测流量监控进行隔离。外卖业务场景使大多数业务监控数据都呈现出很强的周期性,针对业务数据可以利用历史数据使用Holt-Winters等模型进行业务数据预测,当实际值与预测值不在置信区间内将直接进行告警。因为是更加偏向业务的运维系统,项目针对敏感的业务指标进行了相应的权限管理。为了增加系统使用场景,需要支持移动端,使用户可以在任何地方通过手机就可以查看自己关心的监控大盘并触发服务保护预案。
3.3 核心链路
核心链路也是系统主要的使用入口,用户可以通过核心链路快速定位是哪一个调用链出现了问题。如图5所示,这里会涉及两个步骤。

图5 核心链路产品建设路径
1)需要给核心链路上的服务节点进行健康评分,根据评分模型来界定问题严重的链路。这里会根据服务的各个指标来描绘一个服务的问题画像,问题画像中的指标也会有权重划分[2],比如:当服务出现了失败率报警、平均耗时报警、大量异常日志报警则会进行高权重的加分。
2)当确认完某条链路出现了问题,在链路上越往后的节点越可能是引起问题的根节点,系统会实时获取该节点更多相关监控指标来进行分析诊断,这里会融合开发人员日常排查问题的标准流程,最终可能定位到是这个服务节点某些服务器的磁盘或者CPU等问题。
系统最终会发出问题诊断结果,这个结果在发出之后,还需要收集用户的反馈,判断诊断结果是否准确,为后续优化评分定位模型与诊断模型提供有力的数据支持[3]。在核心链路建设前期,系统会建议开发人员进行相应的服务保护预案触发,当诊断结果足够准确之后,可以针对固定问题场景自动化触发服务保护预案,以缩短解决问题的时间。
3.4 服务保护&故障演练
服务保护&故障演练模块是让该业务运维体系形成闭环的重要部分,该模块需要具备的核心功能如图6所示。针对不同的保护需求,会有不同类型的服务保护开关,这里主要有如下3种。
1)降级开关。由于业务快速发展,在代码中会有成百上千的降级开关。在业务出现异常时需要手动进行降级操作。
2)限流开关。有些特定业务场景需要有相应的限流保护措施。比如针对单机限流主要是对自身服务器的资源保护,针对集群限流主要是针对底层的DB或者Cache等存储资源进行资源保护,还有一些其他限流需求都是希望可以在系统出现流量异常时有效地进行保护。
3)服务自动熔断。可以通过监控异常数、线程数等简单指标,快速保护服务健康状态不会急剧恶化。
根据以往的运维经验,在出现生产事故时可能会涉及到多个开关的切换,这里就需要针对不同的故障场景预先设置服务保护预案,可以在出现问题时通过一键操作对多个服务保护开关进行预设状态的变更。既然有了应对不同故障场景的服务保护预案,就需要时不时来验证这些服务保护预案是否真的可以起到预期的效果。
生产对应的事故不常有,肯定也不能只指望生产真的出现问题才进行预案的验证,还需要针对不同的故障进行模拟。当生产服务出现问题时,不管是因为网络原因还是硬件故障,大多数表现在服务上的可能是服务超时或者变慢、抛出异常。针对这几点,做到可以对核心链路上任一服务节点进行故障演练,生产故障可能会同时多个节点出现故障,所以需要故障演练也支持预案管理。
服务保护是业务运维终端措施,需要在软件上可以让用户很方便地直达对应的服务保护,可以很容易地将服务保护与业务大盘、核心链路进行整合,在开发人员发现问题时可以方便地进入对应的服务保护预案。有了这些保护措施与故障演练功能,结合与核心链路的关系,就可以与故障诊断与全链路压测进行自动化方面的建设了。
图6 服务保护&故障演练模块的核心功能
3.5 整合全链路压测
目前,对外卖全链路的定期压测每次都会涉及很多人的配合,如果可以针对单一压测场景进行压测将会大大缩短组织压测的成本。如图7所示,在全链路压测的时候,针对压测流量进行不同场景的故障演练,在制造故障的同时,验证服务保护预案是否可以像预期那样启动以达到保护服务的目的。

图7 全链路压测带来的收益
4 自动化路程
前面主要介绍了开发基于业务的运维系统时需要的各个核心功能,下面重点介绍一下在整个系统建设中自动化方面的建设主要集中在什么地方。
4.1 异常点自动检测
进行核心链路建设的时候,需要收集各个服务节点的报警事件,这些报警事件有服务调用时端到端的监控指标,还有服务自身SLA的监控指标。通过跟开发人员进行沟通了解到他们平时配置这些监控指标的时候耗费了大量的人力,每个指标的报警阈值都需要反复调整才能达到一个理想状态,基于这些监控痛点,希望可以通过分析历史数据来自动检测出异常点,并自动计算出应有的报警阈值并进行设置。如图8所示,根据不同监控指标的特点,选择不同的基线算法,并计算出其置信区间,用来帮助系统更加准确地检测异常点。比如业务指标周期性比较强,大多数监控指标都是在历史同期呈现出正太分布,这个时候可以拿真实值与均值进行比较,其差值在N倍标准差之外,则认为该真实值是异常点。

图8 异常点自动检测
4.2 自动触发服务保护
系统的服务保护措施有一部分是通过自动熔断框架Hystrix进行自动熔断,另外一部分是已经存在的上千个降级、限流开关,这部分开关平时需要开发人员根据自己的运维经验来手动触发。如果能够根据各种监控指标准确地诊断出异常点,并事先将已经确定的异常场景与服务保护预案进行关联,就可以自动进行服务保护预案的触发,如图9所示。
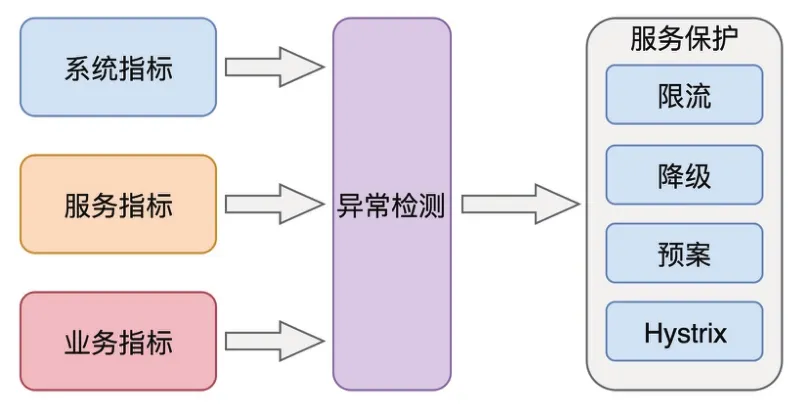
图9 异常检测与服务保护联动
4.3 压测计划自动化
定期进行的外卖全链路压测,需要召集相关业务方进行准备和跟进,这其中涉及的数据构造部分会关联到很多业务方的改造、验证、准备工作[4]。如图10所示,需要通过压测计划串联整个准备、验证过程,尽量减少人为活动参与到整个过程中。这其中需要进行如下工作的准备。

图10 压测计划自动化
1)针对真实流量的改造,基础数据构造、数据脱敏、数据校验等尽可能通过任务提前进行。
2)进入到流量回放阶段,可以针对典型的故障场景进行故障预案的触发(比如:Tair故障等)。
3)在故障演练的同时,可以结合核心链路的关系数据准确定位出与故障场景强相关的问题节点。
4)结合典型故障场景事先建立的服务保护关系,自动触发对应的服务保护预案。
5)在整个流程中,需要最终确认各个环境的运行效果是否达到了预期,就需要每个环节都有相应的监控日志输出,并自动化产出最终的压测报告[5]。
整个压测计划的自动化进程中,将逐渐减少系统运行中人为参与的部分,逐步提升全链路压测效率。最终希望用户点击一个开关开始压测计划,然后等待压测结果就可以了。
5 结语
在整个业务运维系统建设中,只有更加准确定位问题根节点,诊断出问题根本原因才能逐步自动化去做一些运维动作(比如:触发降级开关、扩容集群等)。如图11所示,项目会在这些环节的精细化建设上进行持续投入,希望检测到任意维度的异常点,向上推测出可能会影响哪些业务指标,影响哪些用户体验;向下依托于全链路压测可以非常准确地进行容量规划,节省资源。
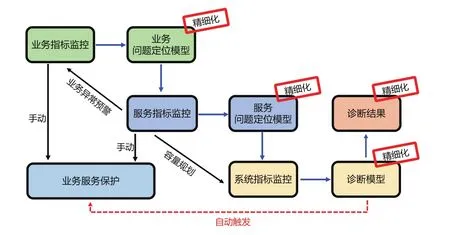
图11 自动化建设后期发力点
[1]侯明,李书领.智能监控网络的系统集成及其应用[J].电子技术与软件工程,2014(05):25
[2]田新广,孙春来,段洣毅,等.基于机器学习的用户行为异常检测模型[J].计算机工程与应用,2006,42(19):101-103
[3]左申正.基于机器学习的网络异常分析及响应研究[D].北京:北京邮电大学,2010
[4]李杰,屈玉贵,张英堂.一种自适应的Web压力测试模型[J].计算机工程与应用,2006,42(02):90-92
[5]马琳,罗铁坚,宋进亮,等.Web系统性能测试及优化[J].计算机工程,2005,31(12):229-231
猜你喜欢
移动通信(2021年5期)2021-10-25
空间科学学报(2020年3期)2020-07-24
中国交通信息化(2019年5期)2019-08-30
中国信息化周报(2019年18期)2019-06-09
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
山东工业技术(2016年15期)2016-12-01
电脑爱好者(2015年6期)2015-04-03
中国交通信息化(2014年3期)2014-06-05
自动化与仪表(2014年10期)2014-02-26
