
基于卷积神经网络的情感分析算法
2018-05-03 06:14李佳丽封化民徐治理
计算机应用与软件 2018年4期
李佳丽 封化民, 潘 扬 徐治理 刘 飚
1(西安电子科技大学 陕西 西安 710071)2(北京电子科技学院 北京 100070)
0 引 言
文本情感分析是指通过对文本内容的解读,判断出句子、段落以及篇章所要表达的情感倾向性的过程。情感倾向性可以简单划分为正面、中性以及负面极性。到目前为止,已经提出了很多方法用于文本情感分析中。这些方法主要可以分为三类:关键词发现、统计自然语言处理(NLP)和基于语义的方法。每种方法都有各自的优点和缺点,此外,这些方法之间没有任何僵化的界限。关键词识别易于实现,基于预定的词汇集将文本分类为不同的情感类别。尽管简单,但创建一个有效的词汇集也是困难的,据统计只有4%的文字中使用的词语具有情感价值[1]。由于这些原因,它不适合广泛的领域。第二类是基于统计NLP方法,这种方法类似于利用词汇间的亲和力求出词语之间的相关性。在词汇相关性的情况下,词语具有表示特定情感类的亲和性的一些概率值。然而,它需要高质量、大规模的训练数据集才能更好地分类。第三类是基于语义的方法,大量使用语义网络如英文的WordNet-Affect[2]和中文的HowNet[3],但是语义网络常常识别不了未登录词。
通过对以上三类文本情感分析优缺点的研究,本文提出了一种新的基于卷积神经网络的情感分析模型。
1 相关工作
自从Pang等[4]使用朴素贝叶斯分类和最大熵等方法来研究语句情感以来,机器学习技术已被广泛应用于情感分析中。传统的机器学习方法着重于人工特征的选取[5-6],并使用传统分类器比如支持向量机(SVM)等完成情感分类任务。特征表示是许多机器学习系统的关键组成部分,因为机器学习系统的表现在很大程度上取决于它[7]。除了纯粹的机器学习方法,基于词典的方法即依靠手动或算法计算出词语的情感类别,已经成为一大趋势[8-9]。
一种被广泛使用的词袋模型可以对句子进行表示,其中向量的每个维度对应于不同的词语[4]。该模型在各种任务上实现了非常好的性能,但它失去了对于语义分析至关重要的单词顺序的问题。例如,“张三喜欢李四”和“李四喜欢张三”具有完全相同的表示,而两个表述具有不同的含义。针对以上问题,人们提出了一种n-gram模型,在短距离内考虑单词顺序,但是它具有高维数和数据稀疏性。近年来,词汇嵌入因其能同时捕捉语义和句法信息而受到广泛关注。词嵌入的思想具有非常悠久的历史,但真正流行起来是因为Bengio等[10-11]的工作。从那时起,许多研究人员开始探讨使用神经网络对词向量进行计算。当下最受欢迎的神经网络语言模型架构由Milkov等[12-13]提出。他们提出了两个有效的词汇表示估计模型,即CBoW和skip-gram模型,将所产生的词向量映射到一个向量空间的话,则相似语义的词汇会彼此靠近。
深度学习模型可以自动从数据中学习数据特征,有效地解决了特征表示问题。自从卷积神经网络出现以来[14],由于CNN变体的出色表现使得常规方法逐渐过时。基于CNN的模型与早期方法不同,它们不依赖于费力的特征工程。CNN在许多文本分类数据集中显示出优秀的结果[15],从而触发了在情感分析中使用CNN的第一次成功。虽然情感分析任务已经得到很好的探索,但由于从原始文本中提取人类情感的复杂性,仍然非常具有挑战性。在情感分析任务中,深度学习明显地提高了这一任务的表现,但还有更多的改进空间。
2 情感词典的构建
在情感分析任务中,利用情感词典以及词语的情感分数对文本进行情感分析表现出很好的效果,这些情感词提供了可能无法从训练数据集中获取的特征。但是情感词典的领域相关性很强,不同的训练语料可能会分布有不同的情感词,因此单纯靠现有情感词典对未知的语料进行特征预提取是不可靠的。
由于网上大量新词汇的出现,单纯地利用现有语义知识网络无法识别出未登录词语。用基于统计的方法获得的情感词很容易识别出未登录词语,但得到的结果与语料库中词语是否合理分配有很大关系。有些具有情感倾向性的词语由于在语料库中出现的次数少,则可能被误判为不含有情感倾向性。因此,本文采用HowNet与Word2Vec相结合的方法来生成语料库的情感词典,既可以识别出未登录情感词,也可以避免因为出现次数少的情感词被误判。
2.1 HowNet
常用的中文的情感极性计算有基于HowNet的计算方法[16]。 HowNet把概念与概念之间的联系以及概念的属性与属性之间的联系作为基本设计原理,继而形成一个网状的知识系统。其中概念用“义原”来描述,并把它作为最小的意义单位,义原的选取与考核在此知识系统中是至关重要的。对于两个义原s1和s2,记其相似度为sim(s1,s2)。其词语距离为dis(s1,s2),可以定义s1与s2之间的相似度公式为:
(1)
式中:α是一个可调节的参数。α的含义是:当相似度为0.5时,义原之间的距离值。对于汉语词语来说,某个词语w可能会有多个义原。对于任意两个词语w1,w2,假设w1有个n义原:s11,s12,…,s1n,w2有m个义原s21,s22,…,s2m,则w1和w2的相似度是各个义原的相似度最大值,即:
(2)
这样,求两个词语之间的相似度问题变成了求两个义原之间的相似度问题。
2.2 Word2Vec
Word2Vec是Google在2013年开源的一款将词汇表征为实数值向量的高效工具。其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为k维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。Word2Vec输出的词向量可以被用来做很多自然语言处理相关的工作,比如聚类、找同义词、词性分析等。将一个语料库经过预处理输入到Word2Vec模型中,可以得到每个词w的词向量表达式。假设规定词语的维度为k维,则词语w1可以被定义为:w1={l11,l12,…,l1k},w2可以被定义为:w2={l21,l22,…,l2k}。采用欧氏距离作为相似度公式,那么词语w1和w2之间的相似度为:
(3)
2.3 HowNet与Word2Vec相融合的情感词典构建方法
本文对于情感词典的构建,分为以下几个步骤:
1) 选取褒贬义情感色彩明显的词语各k个作为种子词,其中正面情感种子词集合为pos={p1,p2,…,pk},其情感为+1;负面情感种子词集合为neg={n1,n2,…,nk},其情感值为-1。
2) 理论上与种子词距离越近的词语它所表达的情感极性越强烈,反之其情感极性则越不明显。分别对HowNet和Word2Vec计算出的词w与各个种子词之间的距离进行归一化处理并取其平均值,则某个词语w的情感分数表达式为:
(4)
式中:sim(w,pi)为词语w与某个正面情感词的相似度,sim(w,ni)为词语w与某个负面情感词的相似度,函数average是词语w与所有正面或者负面种子词相似度的平均值。根据HowNet计算得出词语w的情感分数记为score1(w),根据Word2Vec计算得出词语w的情感分数记为score2(w)。
3) 构建词语-情感分数键值对。对使用HowNet和Word2Vec计算得出的词语情感分数进行排序,分别选取前k个作为正向情感词,后k个作为负向情感词。HowNet与Word2Vec的情感词集合分别记为A,B,则最终的词语w的情感分数为:
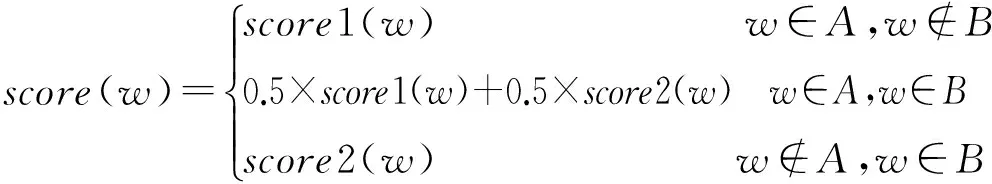
(5)
式中,对于只被word2vec识别出来的,而没有被HowNet识别出来的情感词,一般为未登录词,取其score值为score2。相应地,在语料库中出现频率低的只被HowNet识别出的情感词,取其score值为score1。每个词典数据集由键值对组成,其中键是一个词语w,该键的值是该词语的情感分数score,score∈[-1,1],其中-1和1分别表示最负的和最正的。对于没有在词典中出现的词语,令其score=0。
经过以上几个步骤,具有情感分数的情感词典被构建了出来。
3 情感分析模型
在基于稀疏特征的传统统计模型环境中,由词语组成的词典和词语的情感极性评分在情感分析任务中非常有效。然而,自从词向量出现以来,对于词典的使用正在逐渐消失。很显然,尽管使用词向量可以避免人工挑选特征,但对于一个句子情感倾向性的判断很大程度上还是根据句子中词语的情感倾向性综合考虑得出来的结果。因此,将情感词典与词向量相结合,可以在一定程度上提高情感分析的准确率。
3.1 基本模型
本文的基本方法是使用预训练的词向量和单层CNN模型,这是对Kim介绍的CNN模型[15]的一个微调和修改。令s∈n×d是表示输入文档的矩阵,其中n是单词的数量,d是单词嵌入的维数,每行对应于一个词语的词向量,wi∈d,其中wi表示文档中第i个词。该文档矩阵s被送到卷积层并且被权重c∈l×d卷积,其中l是滤波器的长度。
卷积层可以采用m个长度为l的滤波器。每个卷积产生向量vc∈n-l+1,其中vc中的元素在整个文档中传送l-gram特征。最大化池化层从滤波器产生的每m个向量中选择最显著的特征,该池化层的输出空间大小为vm∈(n-l+1)×m。最后,所选择的特征被传递到softmax层,其用来优化每个情感类标签的得分。
3.2 词向量与情感词典相结合
3.2.1 朴素连接
将情感词典嵌入到其对应的词向量中的最简单的方法是将其附加到词向量的尾部(见图1)。此时,文档矩阵的大小变为s∈n×(d+1),后续过程与基本模型相同。

图1 词的情感分数向量连接到词向量尾部输入到CNN网络
3.2.2 独立卷积
向CNN模型嵌入情感词典的另一种方法是分别用各自独立的卷积处理词向量和情感词向量(见图2)。在这种情况下,使用词向量和情感词向量这两个单独的概念,通过卷积层和池化层以后,将它们的输出特征合并在一起输入到softmax层。令lw,lx分别为词向量和情感词向量的过滤器长度,mw和mx分别为词向量和情感词向量的过滤器的数量,则最大化池化层的输出空间大小为[(n-lw+1)×mw]+[(n-lx+1)×mx]。
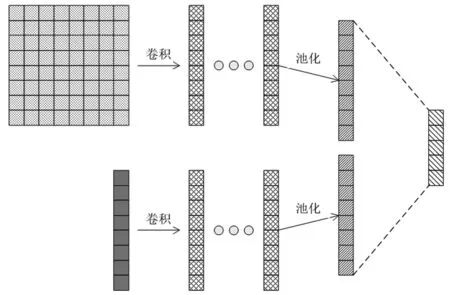
图2 词的情感分数向量和词向量分别输入到CNN网络
4 实 验
4.1 数据集
为验证本文所提出的模型在情感分析任务上的有效性,从豆瓣上爬取了一千多部电影的十几万多条短评。通过筛选无效和重复数据,把其中十万条短评作为此次实验的数据集。数据集的分布如表1所示。每条短评都有与之对应的评分,分别为一星至五星,对应的支持程度也相应地被划分为五个等级,分别为:很差、较差、一般、推荐和力荐。由于情感分析的复杂性以及主观性,将短评的情感倾向性划分为三类,“推荐”和“力荐”统一标为支持,“很差”和“较差”统一标为反对,“一般”标为中立。

表1 实验数据集样本分布
4.2 实验设置
实验首先对数据集进行预处理,包括分词、去掉停用词等。种子词的选取对情感词典的构建十分重要,通过人工选取了情感极性强烈的正负面词汇各40个,如表2所示。为了验证种子词的选取对实验结果的影响,从上述80个正负面种子词中分别选取10个、20个、30个和40个正负面词汇作为种子词进行实验。根据2.3节提出的方法,分别选取排序后的前后各500个词语构建出情感词典。
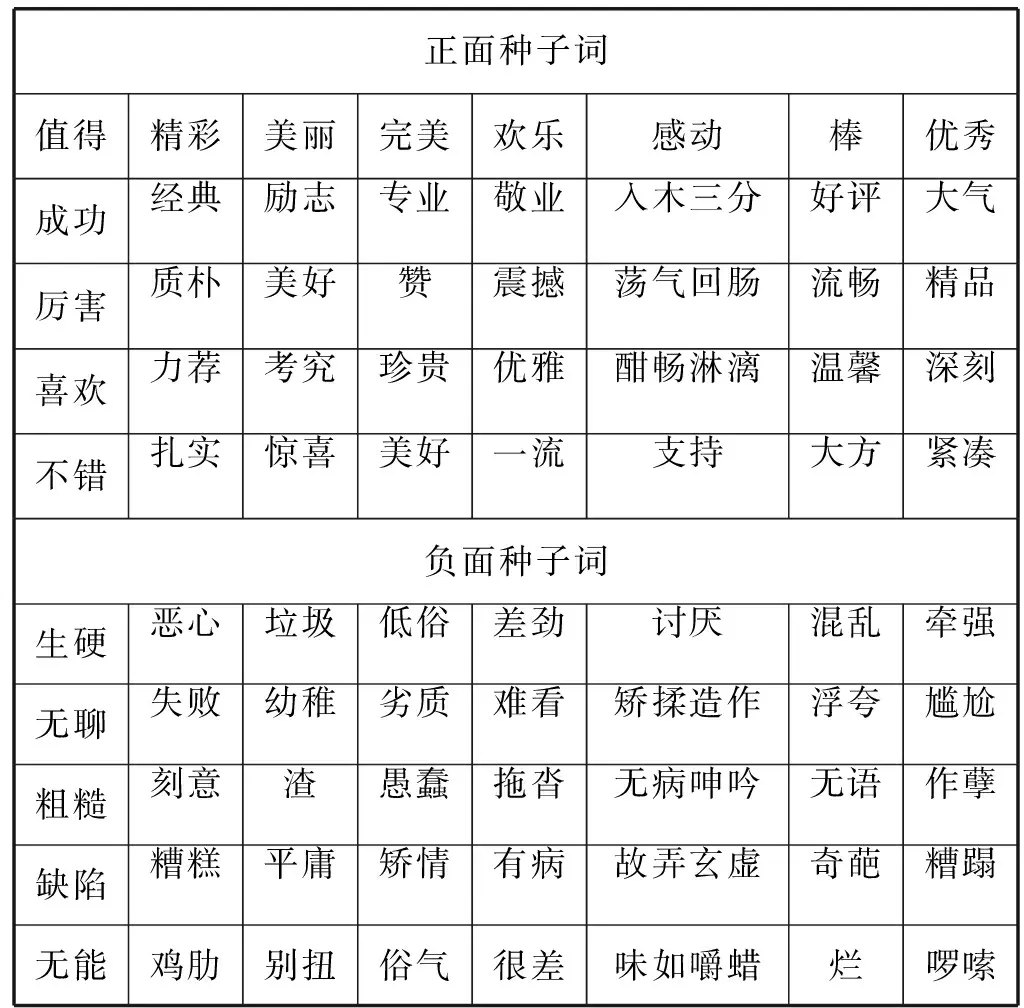
表2 种子词列表
本文采用Google开源的Word2Vec原始模型中的 skip-gram和negative sampling对语料中的词语进行训练进而产生词向量。一般来说,词向量的取100~400个维度,本次实验设置其维度为100维。豆瓣电影短评的最高字数限制为140个字,因此,对于字数不够的短评以100维的0补足。实验分为两个部分:
1) 传统机器学习模型。为了验证基本模型CNN在情感分类任务上的有效性,首先使用传统的机器学习模型对此数据集进行实验。为了排除由于特征构建方式的不同而导致实验结果的无法比较,传统模型的特征构建方式同样基于Word2Vec。由于传统的机器学习方法特征输入是一维的,每条样本的特征取该样本中所有词向量的均值[17]。
2) 本文提出的模型。实验中设置,卷积核的大小为5,共用100个卷积核来抽取数据特征。从10万条短评中随机抽取9万条短评作为训练集样本,剩下的一万条短评作为测试集样本。采用十折交叉验证的方法分别进行了两组实验:第一组是传统的不需要情感词典的方法;第二组是将情感词典与词向量结合的方法。其中情感词典与词向量结合的方法又分为两种:第一种方法为3.2.1 提出的朴素连接方法,第二种方法为3.2.2 节提出的独立卷积方法。
4.3 实验结果与分析
传统的机器学习模型与CNN在此数据集上的结果比较如表3所示。
可以看出,相比于传统的机器学习方法,单层CNN仅靠自身的特征提取就能够达到79.78%左右的正确率,超出了表现最好的Random forest约8个百分点。这是因为语言是序列性的,需要考虑词语之间的顺序,而传统机器学习方法采用的基本模型都是基于无序的思想。因此CNN对于自然语言处理相对于传统机器学习方法有本质上的优势。
表4列出了在基本的CNN模型下,不使用情感词典得到的情感倾向性识别结果。表5和表6分别列出了使用朴素连接法和独立卷积法进行情感倾向性预测时,使用不同数量的种子词所得到的实验结果。

表5 朴素连接法情感倾向性识别结果

表6 独立卷积法情感倾向性识别结果
以上实验结果表明,加入情感词典的CNN网络对于文本分类问题的整体准确率上有了十个点左右的提高。特别是对于具有情感极性的样本,正确率提升得更为明显。这显然是十分具有现实意义的,因为现实中我们关注最多的可能是样本的正负面情绪,而对于中立情绪关注度相对较少。
从表5和表6可以看出,加入情感词本身作为特征,可以有效地提高情感分类的准确率。这一结果充分验证了在情感分类任务中,情感词对于整个句子情感倾向性判别的重要作用。
同时可以看到模型对于具有情感极性的句子识别的正确率高,但召回率相对较低。分析可知,出现这种情况主要是两种原因:一是有些句子没有出现所谓的情感词,比如:“买了大桶爆米花,每一颗我都当成牛轧糖在咬”这一句影评,评论者表达出的是负面情绪,但模型会误判为中性;二是由于情感词的覆盖率不足,评论语句虽然是极性的,但第2节构建出的情感词典没覆盖到句子中的情感词,导致结果误判。
另外,随着种子词数量的增加,两种模型在测试集的分类正确率上基本呈上升趋势,这体现了种子词的数量对于模型正确分类的积极作用。在此影评数据集上,实验结果显示独立卷积法略优于朴素连接法。分析两种模型可知,独立卷积相对于朴素连接赋予了情感词更高的权重, 因此进一步验证了情感词典对于情感分析任务的重要性。
本文在蔡慧苹等[17]的研究基础之上提出的情感词典与CNN相结合的模型,结果明显优于不使用情感词典的CNN模型。虽然本文目前最好的结果准确率比Deriu 等[18]最好的结果要低几个百分点,但是考虑到他们的模型使用五个嵌入通道和双层卷积,而本文的模型使用单一通道和单层连接,换句话说,本文的模型更加紧凑,且训练速度更快。总体而言,使用情感词典与CNN相结合的方法比不使用情感词典的方法在准确率上有了一定程度的提高,因此本文提出的模型具有一定的应用价值。
5 结 语
本文提出了针对于当前语料库进行情感词典构建的一种方法,并且提出了在基本CNN模型下对情感词典和词向量进行融合的两种方式。实验结果表明该模型可以提高情感分析的准确率。但本文情感词典的构建需要人工选取种子词,种子词的好坏对实验结果的影响较大。下一步考虑无监督的学习方法构建领域相关情感词典并优化,提高极性样本的召回率。另外本文只是简单地设置了一层CNN网络,并且只考虑了短距离的上下文,设置多层CNN网络以及考虑长距离的上下文将是下一步的研究工作。
[1] Pennebaker Francis J W. Linguistic Inquiry and Word Count[M]. Lawrence Erlbaum Associates Mahwah Nj, 2012.
[2] Strapparava C, Valitutti A. WordNet-Affect:an affective extension of WordNet[C]// Proceedings of the 4th International Conference on Language Resources and Evaluation, Lisbon, May(2004):1083-1086.
[3] 董强, 董振东. 知网简介[EB/OL]. [2017-04-24]. http://www.keenage.com/.
[4] Pang B, Lee L, Vaithyanathan S. Thumbs up? : sentiment classification using machine learning techniques[C]// EMNLP '02 Proceedings of the ACL-02 conference on Empirical methods in natural language processing, 2002,10:79-86.
[5] Qu L, Ifrim G, Weikum G. The Bag-of-Opinions Method for Review Rating Prediction from Sparse Text Patterns[C]// COLING 2010, International Conference on Computational Linguistics, Proceedings of the Conference, 23-27 August 2010, Beijing, China. DBLP, 2010:913-921.
[6] Mullen T, Collier N. Sentiment analysis using support vector machines with diverse information sources[C]//Conference on Empirical Methods in Natural Language Processing, Doha, Qatar. 2014:412-418.
[7] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553):436-444.
[8] Hu M, Liu B. Mining and summarizing customer reviews[C]// Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, Usa, August. DBLP, 2004:168-177.
[9] Taboada M, Brooke J, Tofiloski M, et al. Lexicon-based methods for sentiment analysis[J]. Computational Linguistics, 2011, 37(2):267-307.
[10] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6):1137-1155.
[11] Bengio Y, Schwenk H, Senécal J S, et al. Neural Probabilistic Language Models[M]// Innovations in Machine Learning. Springer Berlin Heidelberg, 2006: 1081-1088.
[12] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013, arXiv:1301-3781.
[13] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]// NIPS'13 Proceedings of the 26th International Conference on Neural Information Processing Systems, 2013, 2:3111-3119.
[14] Collobert R, Weston J, Karlen M, et al. Natural Language Processing (Almost) from Scratch[J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[15] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014, arXiv:1408.5882gl.
[16] 刘群, 李素建. 基于《知网》的词汇语义相似度计算[C]//第三届汉语词汇语义学研讨会论文集. 台北:[出版者不详],2002:59-76.
[17] 蔡慧苹, 王丽丹, 段书凯. 基于word embedding和CNN的情感分类模型[J]. 计算机应用研究, 2016, 33(10):2902-2905.
[18] Deriu J, Gonzenbach M, Uzdilli F, et al. Swisscheese: Sentiment classification using an ensemble of convolutional neural networks with distant supervision[C]// Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, June 16-17, 2016:1124-1128.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
魅力中国(2018年11期)2018-08-06
高中生学习·高三版(2016年9期)2016-05-14
