
基于Redis的海量智慧医疗小文件存储架构设计
2018-05-03 06:07汪学明
计算机应用与软件 2018年4期
程 晗 汪学明
(贵州大学计算机科学与技术学院 贵州 贵阳 550025)
0 引 言
近年来,贵州省依托大数据产业作为智慧医疗先行的领导者,带动了全国医疗智慧化进程。智慧医疗数据量目前呈几何级增长,预计到2025年,智慧医疗数据量将急剧增长到40 ZB,相当于目前的51倍[1]。如何利用HDFS高效存储访问这些海量小文件数据是个严重问题。
由于HDFS本身是针对大文件进行设计,针对海量小文件存储会消耗大量NameNode内存,同时读写效率低下。Hadoop虽然本身也针对海量小文件提供了改良方案,如SequenceFile[2]、HAR[3]、MapFile[4]。这些解决方案虽然能够解决NameNode高内存占用,但是无法满足快速访问和高并发读写需求。
同时,科技公司和学者也纷纷提出了针对海量小文件的改进的存储与读写方案。如淘宝的TFS[5]是为淘宝页面商品信息和图片信息等提供分布式存储方案。Facebook的Haystack[6]是针对海量照片文件提出的存储方案。李孟等[7]针对教育资源小文件的关联关系等特点,提出了针对该领域资源小文件的存储改进方案。Li等[8]根据一段时间内小文件读写频率,提出动态副本复制策略,提高HDFS小文件读写效率。谭台哲等[9]设计了针对海量图像的小文件处理系统。王鲁俊等[10]通过设计一个低延时高可靠的小文件SFFS系统,解决TFS系统中小文件存储存在的高延迟问题。这些方案都是针对其他领域小文件特点进行针对性的优化和设计,无法满足贵州省海量智慧医疗小数据高效存储及高并发低延迟访问要求。
本文基于贵州省海量智慧医疗数据特点,以及移动互联下对数据的高响应高并发存储访问要求,结合Redis内存数据库优秀读写性能等特点,设计Hash-B+树两级元数据索引和分布式局部索引相结合模式,通过改进的AHP算法进行负载预测判断,提出了基于Redis的海量智慧医疗小文件存储架构。
1 相关知识
1.1 Redis内存数据库
Redis[11]是一种基于内存的高性能Key-Value数据库。对比类似产品memcache而言,它的数据可以持久化,而且支持的数据种类丰富,包括链表(List)、字符串(String)、集合(set)和有序集合(zset)。同时支持在服务前端计算集合的并、交和补集等,并支持多种排序。Redis的所有数据都是保存在内存中,通过不定期半持久化模式(过异步方式保存到磁盘上)和持久化模式操作(把每一次数据变化都写入到一个append only file里面)。这对单点故障和减轻负载压力有很大作用。同时它提供了Java、Python、Ruby、PHP、Erlang客户端,使用很便捷。在Redis3.0版本中,增加了对集群的原生支持,解决了内存容量限制通过客户端分片搭建集群带来的诸多问题和隐患。
1.2 层次分析法AHP
目前工程领域采用的性能效率评价方法有很多,包括层次分析法AHP(Analytic Hierarchy Process)、数据包分析法DEA(Data Envelopment Analysis)、人工神经网络分析法ANN(Artificial Neural Network )等。其中,AHP[12]是美国运筹学家T·L·Saaty提出的一种对于定性问题进行科学定量分析的灵活高效的多准则决策方法策略,应用甚广。
2 基于Redis的海量智慧医疗小文件存储架构设计
根据贵州省智慧医疗数据特点,本文按照不同科室不同类型文件对数据进行分类,对同一类型文件数据集中依次合并成数个block块大小的文件。在基于Redis的海量智慧医疗小文件存储架构中,使用高性能Redis集群对上传的文件进行缓冲合并,满足数据高并发获取的快速访问要求。当合并成的文件块大小达到预定阈值并且系统均衡负载尚可时写入HDFS,并且在此文件块头部生成局部索引文件,同时更新Redis集群中元数据索引信息。整体存储架构图如图1所示。
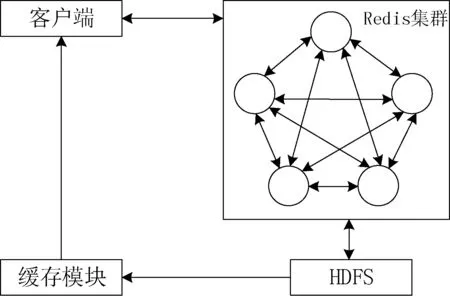
图1 整体存储架构图
其中Redis集群采用无中心存储架构,各节点间使用Gossip协议进行通信,解决了单点故障问题,同时保证了数据并发分布式读写的效率。
2.1 上传归并服务策略
在Redis集群缓冲池中,设置了三类队列,等待队列WQ(Wait queue),合并队列MQ(Merge queue),暂缓队列PQ(Postpone queue)。上传的文件默认直接转入到等待队列WQ中。每个队列默认操作优先级从大到小依次是MQ>PQ>WQ,每个存入缓存的文件设置初始获取频数为0,在文件未进行合并操作时,用户终端每请求读取该文件一次,该文件的获取频数就加1,并且将该文件转入隶属队列的末尾。这样可以最大程度保证用户终端实时快速访问要求。
文件归并操作逻辑如下:
(1) 当合并操作队列MQ中文件总大小低于合并阈值x倍时(x通过实验测得,为保证系统效率的最优值),判断优先级别次高的暂缓队列PQ是否为空,若不是为空,则从PQ中取出适量文件转入合并队列MQ;若为空,则从等待队列WQ中取出适量文件转入合并队列MQ。
(2) 当合并队列MQ中文件大小达到合并阈值时候,此时系统会利用改进的AHP算法,通过基于过去连续时间段的系统负载情况,对将来时段的系统负载进行预测。如果预测值小于设定好的最佳阈值,那么就对文件进行合并写入HDFS中;否则等待下一合适时刻进行合并写入操作。
(3) 当等待队列WQ为满并有文件继续上传时,从队头依次取适量文件转入暂缓队列PQ合适位置。
2.2 动态混合索引机制
由于海量智慧医疗小文件一般都是几十到几百KB大小级别同时要满足快速查询要求,平均一个block中文件索引项达到214个,直接集中线性索引到到Redis中的量是非常大的,大大影响查找效率。为此Redis集群中利用Hash索引快速查找和B+树索引搜索效率高的特点,融合成Hash-B+树分层元数据索引机制。其元数据索引逻辑结构如图2所示。

图2 元数据索引逻辑结构
其中,HashKey由序列号与科室名组成的全局唯一值,占6个字节。type表示文件类型,使用2个字节。idNum使用18位身份证标识(18 B)。blockId为文件从HDFS根路径下所属的全局block编号,占用4个字节。Offset为偏移量,占用4个字节。flag为文件删除标志符,默认值为1,表示未删除,占用1个字节。共占用35 B,8 GB内存可以放2.45亿个索引文件。由于上传的数据都是按照科室和文件类型不同进行分类依次上传,在一级Hash索引中按照文件类型type分类索引,弥补了传统Hash索引随机散列的弊端,大大提高了查找命中率和节省了Redis集群的内存空间,使得更多的空间为二级B+树索引来映射更多的存储在DataNode中的小文件。同时在block头部生成属于该block的局部索引blockIndex,如图3所示。
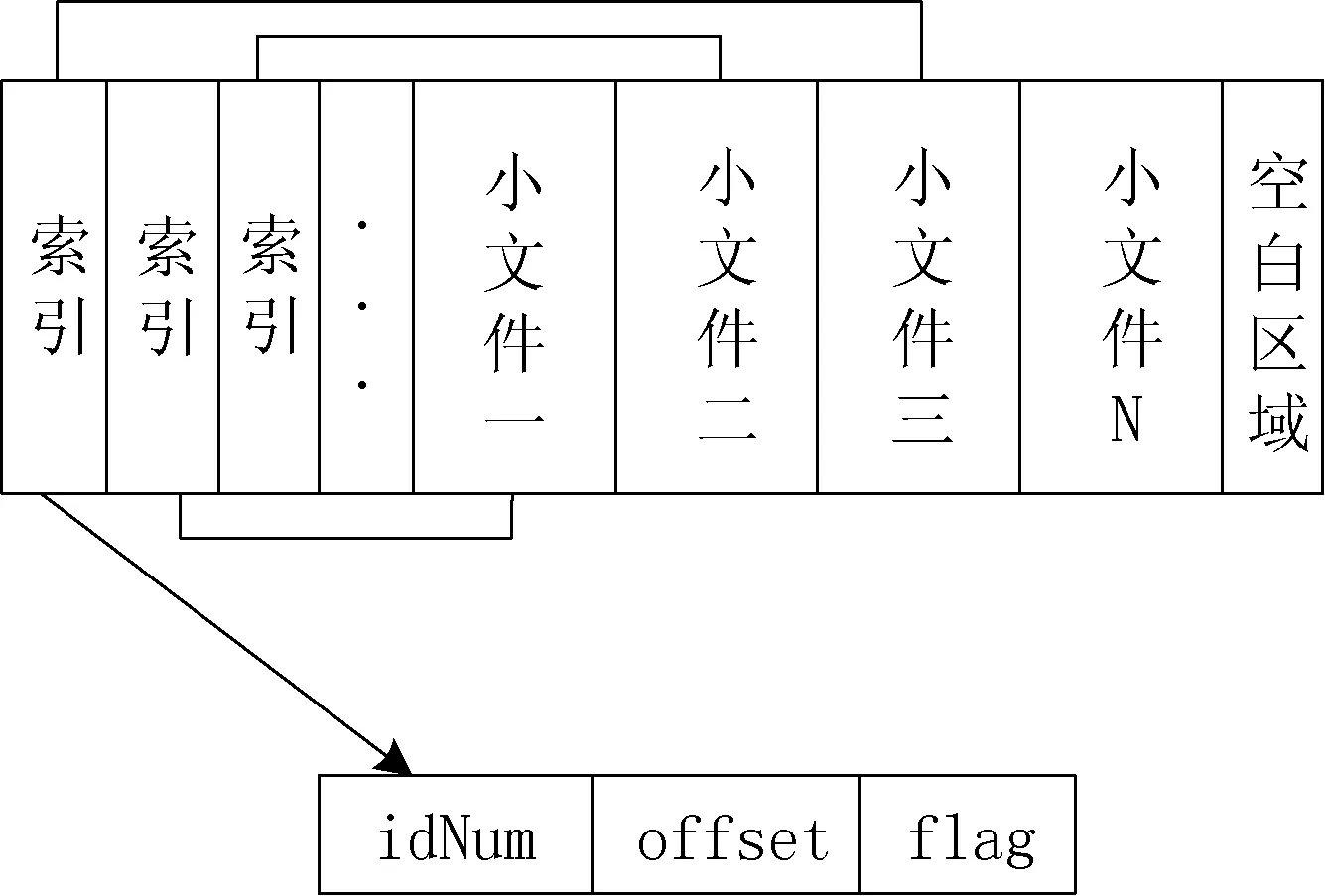
图3 块内结构
基于海量智慧医疗数据访问特点,通常对于一个月内的新数据访问需求很大,因此将一个月时间称为活跃期。在活跃期内,对于Redis中元数据,block的局部索引对于Redis集群是不可见的;在非活跃期,对每个块的数据部分进行压缩,同时更新局部索引blockIndex,此时局域索引blockIndex对Redis服务器为可见状态。这样当访问非活跃期数据时,可以通过元数据定位到具体DataNode的block上,调回这个block块的blockIndex,通过在缓存中遍历查找,快速从DataNode上取到该数据,同时更新元数据的对应的offset,保证了高并发、高响应读写要求。
2.3 文件读取及缓存预取机制
传统采用Redis的Hadoop存储系统中,通常是采用SequenceFlie的block压缩,这样在读取时候,只能从block头遍历获取,获取文件时磁盘I/O次数与遍历文件数正相关。
由于本系统对于活跃期文件采用不压缩block机制,当获取文件时,首先检查Redis集群缓存中是否有该文件,若没有可以通过元数据快速定位到文件内容,只需1次磁盘I/O,同时根据局域性原理和智慧医疗数据同一区域连续访问的特点,进行预取该文件前后的同一数据块上的关联文件到缓存中。缓存采用IBM研究院提出的ARC[13](Adaptive Re-placement Cache)缓存替换算法,提高了缓存空间利用率和增加了访问命中率。
当访问非活跃期数据时,当缓存中没有该文件时,需要通过元数据集中索引定位到block块,再通过块内局部索引检索到要获取的小文件,预取关联文件到缓存中,同时更新元数据信息。
2.4 基于改进AHP系统负载预测算法
系统负载[14]预测定义为基于CPU使用率、内存占用率、磁盘I/O和带宽利用率等基本系统硬件运行指标进行的改进的多属性决策。
在系统均衡负载计算问题上,都是按照文献[15]方式直接采用AHP进行均衡估值预算,没有考虑到同一层次因素之间是存在某种程度关联和影响的,严重影响了判断结果的准确性[16]。为此,加入了系统属性间各自影响量化因子对AHP中关系矩阵进行修正,提出了改进的AHP系统负载预测算法,以提高系统负载预测的科学性和准确性。
步骤1计算决策属性值
(1) 利用层次分析法AHP构建判断矩阵A,A中元素 为系统属性重要性比较关系,判断矩阵A中元素定义如表1所示。

表1 标度及其含义
(2) 对上述判断矩阵A利用式(1)和式(2)进行计算,得到初始权重特征向量Wa及最大特征根λmax,并根据Satty理论对其进行矩阵一致性检验:
(1)
(2)
初始权重Wa=[W1,W2,…,Wn]T。
(3) 构造各属性之间直接影响矩阵B,定义影响度评价集合为V={v1,v2,…,vn},其中vk(k=1,2,…,n)表示不同的评价等级。则:
(3)
式中:Bij为第i个属性对第j个属性直接影响程度。
(4) 对上影响矩阵B进行规范化得到规范化矩阵C,通过对C计算得出影响权重Wb,从而得出最终权重W:
(4)
式中:(tij)n×n=C+C2+…+Cn(1≤i,j≤n)。

(5)
步骤2预测系统负载
通过系统均衡负载定义的属性构造比较判断矩阵A,按步骤1中的式(2)-式(5)计算系统该时刻之前一段时间内的决策属性值d1,d2,…,dn对应的权重Wi(i=1,2,…,n),从而预测即将时刻的系统负载:
(6)
通过加入属性之间影响量化因子改进的AHP系统负预测算法,更加科学准确地实现系统负载预测,为海量智慧医疗小文件的高效存储和访问提供了有力保障。
3 实 验
3.1 实验环境
实验采用4台普通PC作为Hadoop集群,其中1台作为NameNode,其他3台作为DataNode。硬件配置为:酷睿i5四核,500 GB HDD,4 GB内存。采用5台普通PC搭建Redis服务器集群,硬件配置同上,单台内存改为8 GB。 操作系统均为64位CentOS Linux release 7.1.1503,Redis版本为3.2.8(当前stable版本),jdk版本为1.8.0_131。HDFS的数据块大小设为64 MB。
从贵州省海量医疗数据中随即选取10个不同科室的数据,共计约100万个小文件数据。 每一项实验进行4次再取平均值,以减少各种偶然误差造成的结果不准确。
在本实验中,针对本文的方案分别与原始HDFS方案、HAR方案进行效果对比。选用HAR是因为其相对于MapFile或者SequenceFile在小文件读取效率上更优,因而最具对比和参照价值。
3.2 实验测试与分析
3.2.1 内存占用对比
由图4可知,原始HDFS在存储海量小文件时,NameNode内存占用非常高,而且随着小文件量的激增,内存占用上涨的非常快。而HAR方案虽然通过小文件合并成数据块大文件存储,内存占用有所改观,但是依然很大。而采用本文方案的NameNode内存占用最终分别只是原始HDFS和HAR的1/30和1/15,因为小文件合并大文件后采用Hash-B+两级索引将元数据信息存储在Redis中,在NameNode中无元信息。大大节约了NameNode宝贵的内存空间。

图4 NameNode内存使用对比
由图5可知,本文方案相比原始HDFS,通过文件合并,极大减少了DataNode内存索引占用空间,比原始方案减少了2/3的内存占用。但是比HAR方案多占用10 MB左右内存,这点增加忽略不计,因为索引机制的不同,HAR需要两级索引,本文是采用块内集中索引。
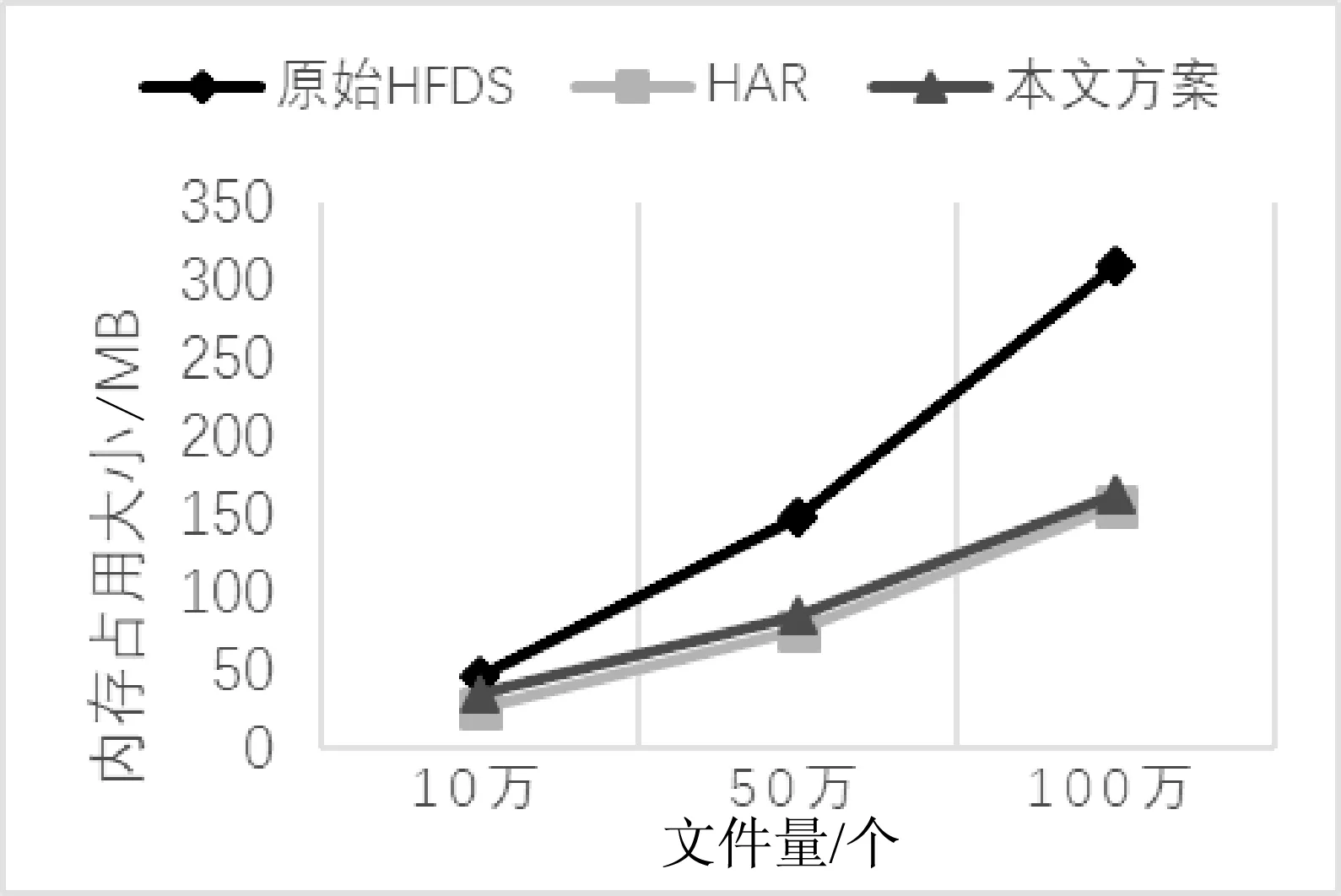
图5 DataNode内存使用对比
3.2.2 上传存储时间对比
从数据样本集中随机选取4组文件,每组文件数分别为:1、4、7、10万,对应大小为:986 MB、2.3 GB、5.2 GB、8.9 GB,分别使用不同方案进行上传写入测试。对应时间如图6所示。

图6 上传存储时间对比
由图6可知,原始HDFS方案针对小文件的写入十分缓慢,而HAR方案虽然大幅度减少写入时间,但是随着文件数目增加,写入时间和文件数量呈递增正相关关系。在10万个小文件写入中,本文方案所需用时非常低,仅为HAR的1/7。由于采用Redis集群缓存上传数据,取代传统由HDFS内存接收合并再写入硬盘的过程,并且基于改进的AHP算法进行负载均衡动态预测,同时集群的使用增加了并发存储效率,上传时间稳定而且很低。
3.2.3 随机读取时间对比
从上面上传的10万个活跃期内小文件中按照不同方案依次读取1个、4个、7个、10 KB个文件,时间耗费如图7所示。
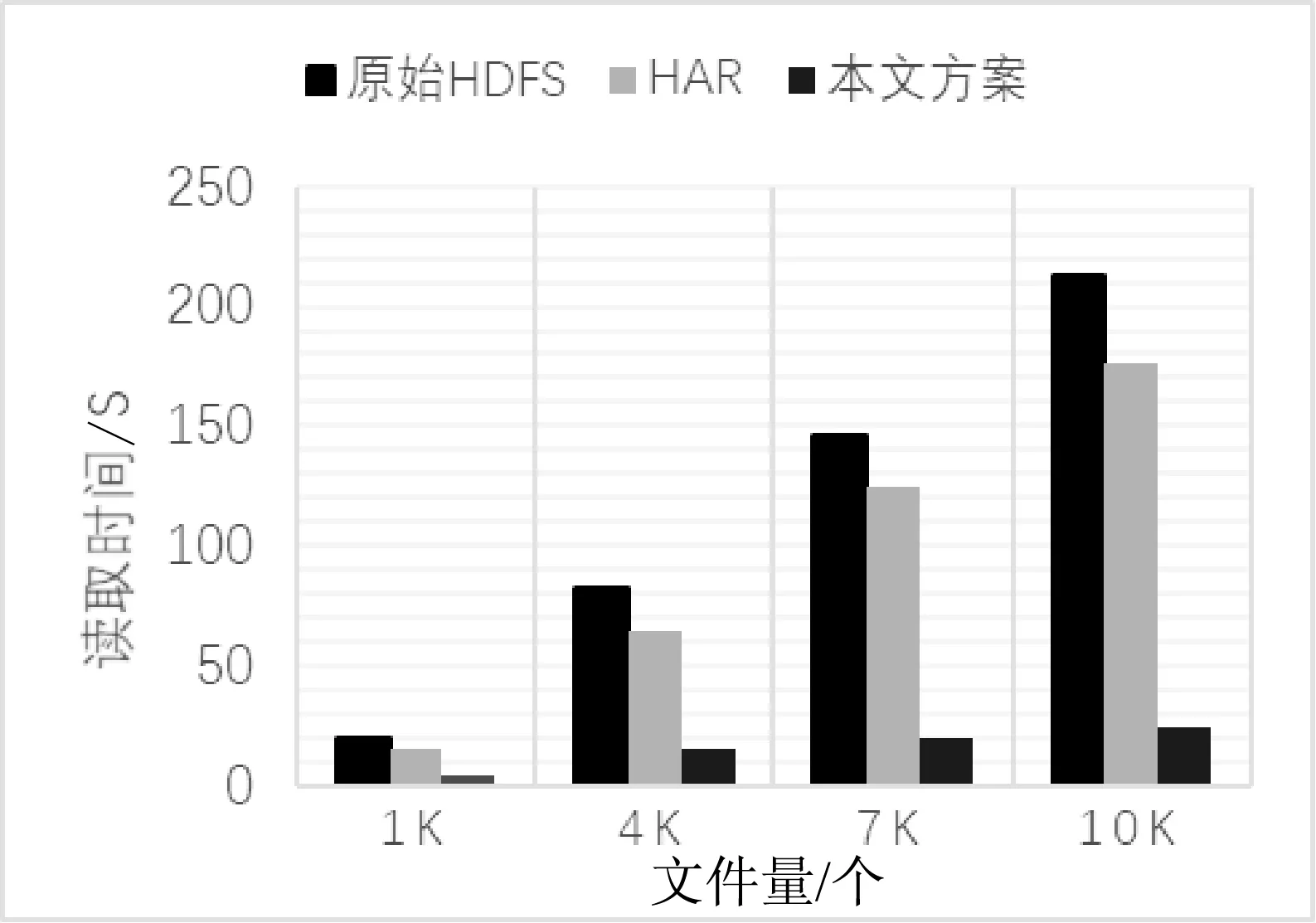
图7 随机读取文件时间对比
由图7可知,在文件检索读取速度上,本文方案远远优于原始HDFS和HAR方案。随机读取文件上,相比原始HDFS需要多次I/O,HAR最快要3次I/O,而本文方案对于活跃期的文件只需要1次I/O就可以,完全满足了海量智慧医疗数据快速访问响应要求。
3.2.4 并发读取效率对比
如图8所示,采用腾讯WeTest性能测试工具进行并发测试实验,模拟1、10、20、40个客户端分别同时请求访问2 000个小文件的应用场景。随着同时请求数据的客户端增多,本文方案访问耗时仅仅上涨了5秒、6秒和3秒,原始HDFS方案耗时增加最大达到71秒,而HAR方案耗时更高。这得益于本文方案中Redis集群缓存和混合两层索引结构的设计。

图8 并发读取小文件时间对比
4 结 语
本文针对贵州省海量智慧医疗小文件分布式存储和读取问题,基于HDFS分布式架构,利用Redis集群缓存合并小文件、保存元数据信息,同时建立Hash-B+两级索引与分布式块内集中索引机制等,以及通过改进的AHP算法进行系统均衡动态调节。实验证明,该架构能够保证贵州省海量智慧医疗小文件快高效存储访问,解决了传统HDFS针对小文件处理先天不足的诟病,同时满足了移动互联网下数据高并发读取需求。未来,将该架构拓展到普通海量小文件存储上去。
[1] 杨刚,杨彦荣,王远白,等.智慧医疗:大数据助力大健康[J].当代贵州,2016(35):19-20.
[2] quenceFileWiki[OL].https://wiki.apache.org/hadoop/Sequ enceFile.
[3] Hadoopar-chives[OL].http://hadoop.apache.org/common/d ocs/cur rent/hadoop_arch.
[4] Map-files[OL].http://hadoop.apache.org/common/docs/cu rrent/api/org/apache/had.
[5] Taobao File System[OL].http://tfs.taobao.org/.
[6] Beaver D,Kumar S,Li H C,et al.Finding a needle in Haystack:facebook’s photo storage[C]//Usenix Conference on Operating Systems Design and Implementation.USENIX Association,2010:47-60.
[7] 李孟,曹晟,秦志光.基于Hadoop的小文件存储优化方案[J].电子科技大学学报,2016,45(1):141-145.
[8] Li M,Ma Y,Chen M.The Dynamic Replication Mechanism of HDFS Hot File based on Cloud Storage[J].International Journal of Security & Its Applications,2015,9(8):439-448.
[9] 谭台哲,向云鹏.Hadoop平台下海量图像处理实现[J].计算机工程与设计,2017,38(4):976-980.
[10] 王鲁俊,龙翔,吴兴博,等.SFFS:低延迟的面向小文件的分布式文件系统[J].计算机科学与探索,2014,8(4):438-445.
[11] Redis[OL].https://redis.io/community.
[12] Tam M C Y,Tummala V M R.An application of the AHP in vendor selection of a telecommunications system[J].Omega,2001,29(2):171-182.
[13] Huang S,Wei Q,Feng D,et al.Improving Flash-Based Disk Cache with Lazy Adaptive Replacement[J].Acm Transactions on Storage,2016,12(2):8.
[14] Godfrey B,Lakshminarayanan K,Surana S,et al.Load balancing in dynamic structured P2P systems[C]//Joint Conference of the IEEE Computer and Communications Societies,March.2004:68-79.
[15] Osman T,Divigalpitiya P,Arima T.Driving factors of urban sprawl in Giza Governorate of Greater Cairo Metropolitan Region using AHP method[J].Land Use Policy,2016,58:21-31.
[16] Ishizaka A.Comparison of fuzzy logic,AHP,FAHP and hybrid fuzzy AHP for new supplier selection and its performance analysis[J].International Journal of Integrated Supply Management,2014,9(1/2):1.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
电脑报(2019年31期)2019-09-10
当代陕西(2019年14期)2019-08-26
当代陕西(2019年13期)2019-08-20
军营文化天地(2018年2期)2018-12-15
消费导刊(2018年10期)2018-08-20
中学数学杂志(初中版)(2016年5期)2016-11-01
