
基于TF-GSC的多通道后置滤波语音增强算法*
2018-04-27 01:35马子骥
传感器与微系统 2018年5期
马子骥, 倪 忠, 余 旭
(湖南大学 电气与信息工程学院,湖南 长沙 410000)
0 引 言
与单麦克风降噪算法在时域和频域处理相比,基于多麦克风阵列的降噪算法可以充分利用空间滤波技术,对其他方向的噪声进行滤波处理,从而获得更好的降噪效果。Griffiths L J和Jim C W在文献[1]中提出了广义旁瓣对消器(generalized sidelobe canceller,GSC)方法,Gannot S在此基础上提出了基于传递函数(transfer function,TF)的GSC方法[2]。在处理平稳噪声时的效果很好,但在处理非平稳噪声时表现欠佳。文献[3,4]针对非平稳噪声,在后置滤波段利用最小控制递归平均(minima controlled recursive averaging,MCRA)算法估计。Israel Cohen对MCRA进行了改进,提出了一种改进的最小控制递归平均算法(improved MCRA,IMCRA)[5],可在复杂环境,比如非平稳噪声、低信噪比条件下估计噪声。Cohen I 和 Berdugo B在文献[6]中将GSC和最佳修正对数谱幅度估计算法(optimally modified log spectral amplitude estimator,OM-LSA)结合,利用GSC的输出信号和参考噪声的相互关系进行后置滤波。Gannot S在此基础上进一步改进,用TF-GSC替代GSC,更好地适应复杂变换的噪声环境[7]。
本文算法在此基础上进一步改进,提高了语音存在概率估计的准确性,从而能更准确地更新噪声功率谱估计,提高了对噪声的抑制能力,并减少了语音损失。
1 基于TF-GSC的多麦克风后置滤波算法
多通道后置滤波的主要思想是利用TF-GSC自适应波束输出信号与参考噪声信号之比估计目标语音缺失概率,并更新噪声功率谱估计,最终通过OM-LSA方法获得较为纯净的目标语音信号。多通道后置滤波方法的结构框图如图1所示。

图1 多通道后置滤波算法原理框图

SY(t,ejω)=αs·SY(t-1,ejω)+(1-αs)·
(1)

ψ(t,ejω)=
(2)
式中M为文献[5,8]提出的非平稳噪声功率谱密度的最小控制递归平均(minima controlled recursive averaging,MCRA)估计。定义自适应波束输出信号的后验信噪比
γs(t,ejω)|Y(t,ejω)|2/MY(t,ejω)
(3)

(4)
利用文献[9]方法求出语音存在概率
p(t,ejω)=
(5)
式中ξ(t,ejω)E{|S(t,ejω)|2}/λ(t,ejω);υ(t,ejω)γ(t,ejω)ξ(t,ejω)/(1+(t,ejω));γ(t,ejω)|Y(t,ejω)|2/λ(t,ejω)。
利用“直接判决”法[10]求得
(1-α)max{γ(t,ejω)-1,0}
(6)
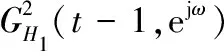
噪声功率谱估计为
(7)
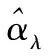

(8)
求解目标语音信号的短时傅里叶变换
(9)
式中G(t,ejω)为OM-LSA增益函数
2 改进的多麦克风后置滤波算法
从上述原理可知多通道后置滤波算法的关键在于先验语音缺失概率q(t,ejω)估计和噪声功率谱密度估计的准确性。本文通道后置滤波算法进行改进。
由式(4)可知,先验语音缺失概率q(t,ejω) 结合γs(t,ejω) 和ψ(t,ejω)求取,γs(t,ejω)用于判断TF-GSC输出波束信号是否变化,TBRR判断该变化是由目标语音信号引起还是由噪声引起。假设目标语音信号与噪声信号不相关,当瞬时信号变化主要由目标语音信号引起时,TBRR一般比较大[12];反之,当信号瞬时变化由噪声引起时,参考噪声变化大于输出波束变化,此时TBRR小于1。含噪语音信号在经过TF-GSC处理之后被抑制了一部分噪声[7],在长弱语音段且噪声变化比较大的情况下,经过TF-GSC处理之后的输出信号变化可能小于参考噪声的变化,此时,ψ(t,ejω)的值小于ψlow,从而将含目标语音信号误判为不含目标语音信号,导致语音失真。因此,结合文献[5~7]的求先验语音缺失概率的方法,得到新的求先验语音缺失概率的公式
(10)
由式(10)知,当在TBRR小于阈值ψhigh,且γs(t,ejω)≤γlow和ζ<ζ0时将信号判断为目标语音缺失信号,防止在长弱语音强噪声段因TBRR小于1时,将语音信号误判成噪声。当ψ(t,ejω)>ψhigh,γs(t,ejω)和ζ<ζ0任意一个条件成立时,即确定目标语音信号存在。在不能确定语音信号是否存在时,用γs(t,ejω)的一次线性函数求先验语音不存在概率[5]。
3 实验结果与分析
为了验证本文算法的性能,通过麦克风阵列采集实际语音信号,并利用MATLAB软件对算法进行了仿真测试。并与文献[8]中提出的MCRA算法、文献[7]中提出的基于TF-GSC的多通道滤波方法进行了比较分析。实验设置如下:麦克风阵列由4个麦克风组成间距为0.8 cm的均匀线性阵列,目标声源为正对阵列中间位置,距离2 m处的录音,噪声为与阵列成50°处的录音,如图2所示。

图2 阵列麦克风示意
麦克风采样频率为64 kHz,采样精度为24 bit。实验中相关参数设置如下:加窗为Hamming窗,窗长1 024,帧长取窗长,帧移为帧长的1/2。实验时将一段数据分成5部分,每部分500帧。其他实验参数设置情况参照文献[7],α=0.9,αs=0.92,αλ=0.85,β=1.47,ψlow=1,ψhigh=3.6,γlow=1,γhigh=4.6,b=[0.25 0.5 0.25],ε=0.01,Gmin=20 dB。
3.1 分段信噪比分析
将目标语音信号和噪声信号按不同比例线性相加,生成5种的信噪比:9.482 8,4.968 6,3.331 5,0.860 5,-3.494 4 dB。在以上5种信噪比条件下,对含噪语音信号分别采用TF-GSC+MCRA和本文算法进行语音增强实验,实验结果如表1所示,可以看出:相比于TF-GSC+MCAR算法,本文算法能进一步提高信噪比,尤其是在高输入信噪比段,效果更明显。

表1 不同信噪比下算法性能比较 dB
3.2 语谱图分析
图3(a)、图3(b)分别为上述实验条件下最左边位置的麦克风接收到的目标语音信号和带噪语音信号的语谱图。图2(c)为带噪语音信号经过TF-GSC增强后的语音信号语谱图。可以看出:TF-GSC算法对非平稳噪声抑制有比较明显的效果,但仍残留了部分噪声。图3(d)、图3(e)分别为利用文献[7]中提出的TF-GSC+OM-LSA算法和本文算法增强后的语音信号语谱图,经过对比可知:TF-GSC+OM-LSA算法虽然能有效抑制噪声,但造成了大量的语音失真,而本文算法能有效抑制语音失真,同时保留了目标语音信号。

图3 信号处理前后语谱
4 结束语
以麦克风阵列为例,对传统的多通道后置滤波算法进行了改进,提高了先验语音存在概率估计的准确性,从而能更准确地更新噪声功率谱估计,减少了噪声过估计和噪声估计不足的情况。实验结果表明:相对传统的多通道后置滤波语音增强算法,新算法对非平稳噪声,尤其是当噪声为语音时具有较好的抑制能力,并且能有效减少语音失真,提高了信噪比,改善了语音质量。
参考文献:
[1] Griffiths L J,Jim C W.An alternative approach to linearly constrained adaptive beamforming[J].IEEE Trans on Antennas Propagat,1982,30:27-34.
[2] Gannot S,Burshtein D,Weinstein E.Signal enhancement using beamforming and nonstationarity with application to speech[J].IEEE Trans on signal Processing,2001,49:1614-1626.
[3] Cohen I.On speech enhancement under signal presence un-certainty[C]∥The 26th IEEE International Conference on Speech Signal Process,2001:167-170.
[4] Cohen I,Berdugo B.Spectral enhancement by tracking speech presence probability in subbands[C]∥IEEE Workshop on Hands Free Speech Communication,2001:95-98.
[5] Cohen I.Noise spectrum estimation in adverse environments:Improved minima controlled recursive averahinging[J].IEEE Trans on Speech and Audio Processing,2003,11:466-475.
[6] Cohen I,Bedugo B.Microphone array postfiltering for nonstationary noise suppression[C]∥Proc of International Conference on Acoustics and Speech Signal Process,Orlando,FL,2002:901-904.
[7] Cohen I,Gannot S.Speech Enhancement based on the general transfer function GSC and postfiltering[J].IEEE Trans on Speech and Audio Processing,2004,12(6):561-571.
[8] Cohen I,Bedugo B.Microphone array post-filtering for nonstationary noise suppression[C]∥Proc of International Conference on Acoustics and Speech Signal Process,Orlando,2002:901-904.
[9] Cohen I,Berdugo B.Noise estimation by minima controlled recursive averaging for robust speech enhancement[J].IEEE Trans on Signal Processing,2002,9:12-15.
[10] Ephraim Y,Malah D.Speech enhancement using a minimum mean square error short-time spectral amplitude estimator[J].IEEE Trans on Acoust,Speech and Signal Processing,1984,32:1109-1121.
[11] Cohen I,Berdugo B.Speech enhancement for nonstationary noise environments[J].IEEE Trans on Signal Processing,2001,81(11):2403-2418.
[12] Ephraim Y.Speech enhancement using a minimum mean spuare error log spectral amplitude estimator[J].IEEE Trans on Acoust,Speech and Signal Processing,1985,33:443-445.
[13] Cohen I.Multi-channel post-filtering in noise environments[J].IEEE Trans on Signal Processing,2004,52:1149-1160.
猜你喜欢
电子测试(2022年3期)2023-01-14
现代仪器与医疗(2022年1期)2022-04-19
制造技术与机床(2019年12期)2020-01-06
北京航空航天大学学报(2019年9期)2019-10-26
复旦学报(自然科学版)(2019年3期)2019-07-19
雷达学报(2017年3期)2018-01-19
小学科学(2016年12期)2017-01-06
环境科技(2016年4期)2016-11-08
国际感染病学(电子版)(2016年2期)2016-03-09
做人与处世(2015年19期)2015-09-10
