
基于OpenCV的算式批改系统设计
2018-04-26 08:51山东科技大学电气与自动化工程学院田振东王珍珍林建慧杨瑞东
电子世界 2018年7期
山东科技大学电气与自动化工程学院 田振东 王珍珍 林建慧 孙 博 杨瑞东
0 引言
老师每天要花大量的时间在数学算式题的批改上,而对于复杂的运算工作耗费巨大的精力,家长每天帮孩子检查作业也花费大量的时间。本文研究的算式批改系统可以应用在教育实践中可以把老师和家长从高度重复、低价值的工作任务中解脱出来,老师和家长可以通过本文设计的系统迅速完成作业批改,学生也可以独立完成作业批改。
本文的基本内容是在VS2013环境下设计了基于OpenCV函数库的算式批改系统,介绍了系统每个关键步骤的技术实现。主要针对混合字符识别问题进行了介绍,通过字符识别技术对作业中的印刷体算式题目和手写体书写结果进行字符识别。采用支持向量机(SVM)分类器作为字符识别分类器,着重研究设计SVM分类器以及参数的选取,获得较高的字符识别准确率。
1 系统的工作流程
本文实现设计的算式批改系统,是一个基于图像处理,机器视觉,模式识别等技术的高度智能化的综合集成系统。首先进行图像采集,通过摄像头提取作业中的算式图像,对获取的算式字符图像进行预处理。再进行特征提取,提取字符图像的特征向量,为后续的识别做好准备。最后利用SVM分类器进行字符识别,得到识别结果,通过公式计算器判断解答的正误,输出判断结果。本文研究基于OpenCV的算式批改系统,其系统流程如图1所示。
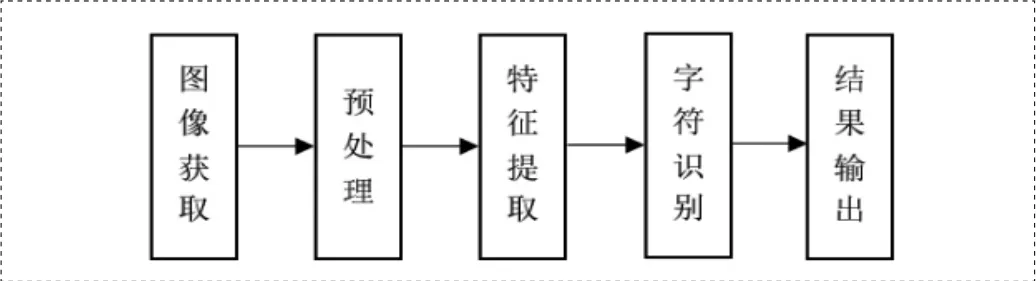
图1 系统流程
在字符识别过程中,首先要对其字符图像进行预处理,其目的是为了突出字符区域和信息,为后期的字符识别做准备。图像预处理一般包括图像二值化、形态学处理、字符分割、归一化等操作。
预处理首先对获取的图像进行灰度二值化处理。灰度化处理就是把获取的彩色图像转换成灰度图像,而二值化处理是对灰度图像进行阈值操作从而能够去除噪声,提高识别效率。本文采取全局阈值法,通过分析图像的整体灰度空间的分布特征,提取出单一阈值,再用该阈值对图像进行二值化处理。经过灰度二值化处理后的图像,内部一般还存在一些干扰因素,要对图像进行形态学处理,通过闭运算使区域内的间断变成连通区域和消除图像毛刺、去除噪声。处理效果如图2所示:
图2 形态学处理后的图像
一组算式中多个字符的图像根据字符间隙,进行字符分割,分割成单个字符进行识别。其基本思想是利用字符间隔的特点,统计图像中每一行每一列的投影直方图,然后根据波形确定间隙的位置,就可以得到单个字符。为了便于对任意字符的特征提取具有可比性,还要对字符进行归一化处理,采用线性插值法将图像按比例缩放至分类器统一的尺寸,这样像素在整个图像中的分布达到均衡。本系统最终预处理后得到大小为128*128像素的图片。如图3所示为预处理后的手写字符图像样本。

图3 预处理后的字符图像
为了便于分类,利用基于统计特征的原理采用逐像素提取法。通过图像进行逐行扫描,从图像的像素中直接提取特征构成特征向量,这种方法运行速度快,提取信息量大。因此在字符识别中己经取得了很好的效果。最终提取的字符特征输入到SVM分类器中进行字符的训练及识别过程。
2 支持向量机分类器
2.1 SVM算法理论
SVM是基于统计学习理论的模式识别方法,主要应用于模式识别领域。在小样本问题、非线性及高维模式的识别问题中取得了较明显的优势,在处理其他分类问题有很大帮助。SVM分类器的算法是先把数据变换到一个高维空间,在这个高维空间中形成一个区域标识相应的类,然后在空间中获取最优的线性分类面,在最优化问题的求解过程和判别函数的计算过程并不要对非线性函数进行计算,只需计算核函数。由于它可以够吸收字符的变形,因此在字符识别具有较好的泛化性和准确性。SVM分类器中少量的支持向量就能得到最终的决策函数,所以该方法不需要太多的样本,在小样本学习中能够达到很高的准确率。本文采用支持向量机算法对手写字符进行识别。
2.2 分类器设计
SVM是二分类器,设计中通过循环将其转化为一个多分类器。多分类器一般通过构造一系列的两类分类器组合设计。针对手写与印刷体字符,采用二叉分类树设计的分类器首先根据字符特性分为两类,接下来采用同样的方式将子类进一步划分成两个次级子类。在此基础上循环,取得所有类别均成为二叉树的叶节为止,这样就将原有的多类问题变为求解一系列的两类分类问题。通过在各决策节点进行训练支持向量机分类器,对样本的识别进行分类。由于开始的分类阶段已经减少参与分类的类别数量,因此采用二叉分类树分类的多分类方法性能较优。
SVM的各参数对实验结果有很大的影响,通过CvSVMParams函数进行分类器内参数设计。首先要进行核函数的选取,再完成对核函数下参数的选取。对于核函数的选取,针对不同的核函数采用相同的样本进行训练测试,根据得到的实验数据进行对比,结果表明不同的核函数对SVM性能的影响其实不大,本文选取径向基核函数作为核函数。
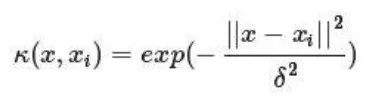
径向基核函数与其他核函数相比参数的选择,直接关系到最终的分类器的样本训练效果和学习能力,其中两个重要的参数C与σ²。惩罚因子C的作用是调节训练置信范围和经验风险的比例,以使得训练分类的效果最好,推广能力更强。C过大或过小,泛化能力变差,选择合适的C值,对样本训练结果的好坏十分重要。σ²参数决定了数据映射到新的特征空间后的分布,σ²参数越大,支持向量越少,σ²参数值越小,支持向量越多。支持向量的个数影响训练与预测的速度。选取K折交叉验证法找到最佳的参数,将原始训练样本随机等分成K个集合,将其中一组每个子集数据分别做测试样本,其余K-1组集合来训练分类器。每组样本进行一次测试样本产生K个结果,取得每次的测试误差的平均值。根据检验结果来评估分类器的性能,并调整分类器的相关参数。
2.3 字符识别
本文采用林智仁教授开发的LibSVM工具箱。首先对处理后的样本字符进行标记,将贴过标签的样本进行训练,生成支持向量模型。最后通过SVM模型对训练集之外随机选取的测试集进行预测分析产生预测标签,通过预测标签与实际标签的误差统计识别的准确率。
对10个手写体字符、10个印刷体字符、5个印刷体运算符建立各个字符的样本库。通过训练阶段对字符的训练过程,建立每一类别字符类别的标准样本库,样本数为20,以便在识别阶段使用。测试阶段,采用将每一类测试样本200个样本进行预测分析,最终得到识别结果。然后对所有的样本用SVM方法训练。本文结合K最近邻(KNN)分类器进行比较,统计识别准确率,得到识别结果如表1所示:

表1 不同分类方法识别率
实验结果表明SVM在训练样本较少时进行字符识别具有较高的准确性,但是增加训练样本对识别率没有太大的提升。相比KNN在特征空间中的K个最相邻的样本中的大多数属于某一个类别的分类方式,基于SVM的字符识别在在噪声环境下影响较小,识别准确率较高,在字符识别有较明显的优势。相比核函数,参数C与σ²对分类器的影响更为直接,选取最优的参数组合,对测试结果又较高的改善。
3 实验结果
建立MFC框架完成整个系统实现与实验结果的验证过程,截取实验结果如图4所示。在软件界面的左侧显示作业图像信息;界面的右侧显示字符预处理和分割结果;下框中显示算式字符识别结果和正确的计算结果,同时根据公式计算器判断解答正误得到输出结果。对程序进行运行调试验证了算式批改系统的可行性。
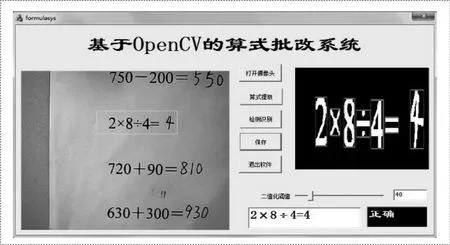
图4 实验识别结果
本实验中采用10组不同书写,共1000个数学算式样本进行实验测试,其中100道为错误解答算式。本实验所采用的方法对测试样本的识别率达到86.5%。另外,在图像包括不同的光照条件,距离和一定的倾斜角度进行测试,都表现出了较为良好的效果。通过对系统的实验仿真,实现了对数学算式进行实时、有效的批改。
4 结论
本文主要介绍了算式批改系统的设计流程,针对手写字符的识别问题,采用了一种基于OpenCV库运用SVM分类器进行字符识别的方法。通过OpenCV的图像处理函数对图像进行预处理,再利用支持向量机算法对混合字符进行识别。从测试结果可以看出,本文采用的字符识别方法达到了设计要求的较高识别率,在算式批改实验过程中系统运行效果令人满意。本系统能够可靠的完成算式批改任务,在教育领域将有更好的应用前景。
[1]柳回春,马树元,吴平东,等.手写体数字识别技术的研究[J].计算机工程,2003,29(4)∶24-25.
[2]刘瑞祯,于仕琪.OPENCV教程基础篇[M].北京∶北京航空航天大学出版社,2007∶1-276.
[3]邓乃扬,田英杰.支持向量机∶理论、算法与拓展[M].科学出版社,2009∶1-155.
[4]刘志刚,李德仁,秦前清,等.支持向量机在多类分类问题中的推广[J].计算机工程与应用,2004,40(7)∶10-13.
[5]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1)∶32-42.
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
小学生学习指导(低年级)(2019年11期)2019-11-25
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
小学生学习指导(低年级)(2018年9期)2018-09-26
成都信息工程大学学报(2017年3期)2017-11-09
作文周刊·小学一年级版(2017年5期)2017-07-29
作文周刊·小学一年级版(2017年5期)2017-07-29
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
