
Hadoop异构集群下的负载均衡算法研究
2018-04-26 01:47:10陈林
现代计算机 2018年5期
陈林
(四川大学计算机学院,成都 610065)
0 引言
Hadoop是一个开源的分布式处理系统,当用户提交一个作业后,Hadoop会将该作业分成若干个task任务,然后分配到多个节点并行执行,最后返回结果。
在Hadoop集群中,移动数据块的性能消耗要高于移动计算任务的性能消耗,数据负载均衡可以提高本地化的task任务次数,从而可以减少集群中的数据传输,从而提高集群性能。
1 HDFS默认的负载均衡算法
HDFS默认的负载均衡算法是基于同构的集群环境,该算法的目标是把各个节点的存储空间利用率尽量保持在同一水平。当机器中的某个或者某几个节点空间利用率过高时,那么我们可以通过执行start-balancer.sh来启动负载均衡程序。Balancer负载均衡器是根据用户给定的阈值threshold,以及平均空间利用率avg来把节点分为四组:overUtilizedDatanodes、bove-AvgUtilizedDatanodes、belowAvgUtilizedDatanodes、underUtilizedDatanodes,分组过程是通过 avg+threshold、avg、avg-threshold这三个值来进行划分的。分好组后,就进行移动数据,不停地将前两组过载节点的数据移动到后两组节点中,直到所有节点与avg的差值不超过threshold阈值。
2 异构集群的负载均衡算法分析
2.1 相关概念定义
配置的存储空间(Sconf(i)):节点i分配给hdfs使用的磁盘空间容量。
已用空间(Sused(i)):节点i中hdfs已经使用的磁盘空间容量。
节点i的CPU性能(Fcpu(i)):对于多核CPU的情况,每个核的性能为单核的 0.8~0.9,这里我们取∂=0.85,该节点的CPU性能为:
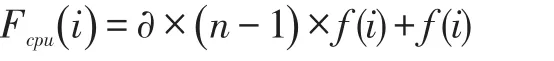
其中∂表示转化率,f(i)表示CPU频率(GHz),n是核数。
节点内存性能(Fmem(i)):内存性能的度量是使用该节点内存的大小。
节点剩余空间(Sremain(i)):节点i中hdfs剩余的空间容量大小。
定义1节点相对性能:
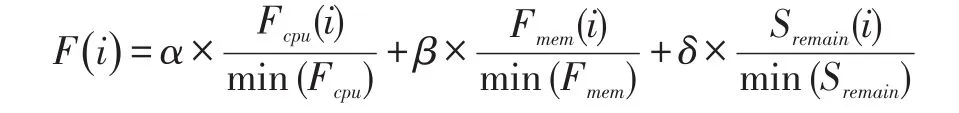
其中α,β,δ表示CPU相对性能以及内存相对性能和节点相对剩余空间大小的权重,由于节点剩余空间有可能在均衡的过程中动态变化,从而影响迭代的收敛,所以对于剩余空间的权重设置相对要小一点。所有结点相对性能之和为性能总和:
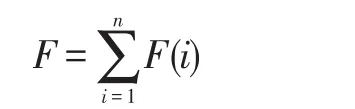
定义2集群的平均空间利用率:
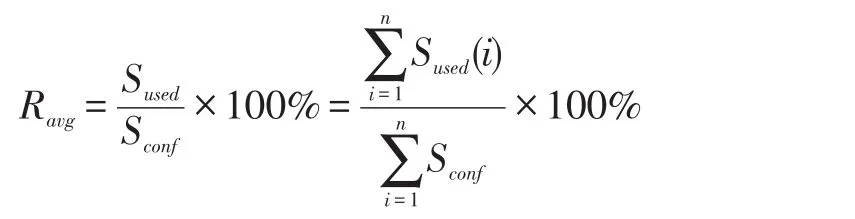
定义3各个结点基于性能和剩余空间容量的理论空间使用量和空间使用率:
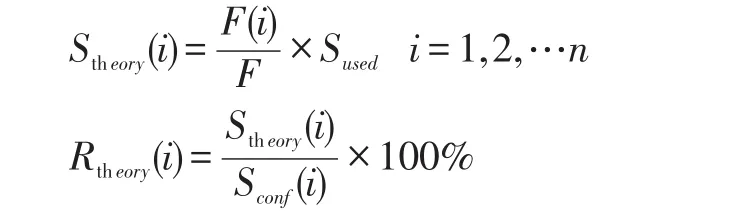
定义4每个节点的最大空间负载:
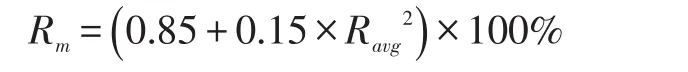
因为在异构集群环境中每个结点的磁盘空间是不同的,因此计算出来的每个结点的理论使用空间量可能会大于该结点的最大负载量,这个时候我们需要将多余出来的部分占用空间分给其他结点,这里我们提出了一个迭代算法,计算理想均衡状态。
金,因为品质而尊贵;梦,因为绚丽而多彩。这座北方小城,正一步步践行着自己的“黄金梦”,正用自己手中的颜色描绘着未来的美好蓝图。
2.2 算法整体介绍
该算法的详细步骤如下:
(1)通过计算CPU、内存、以及剩余空间大小来计算节点的相对性能F(i),集群总的性能F以及集群空间的平均使用率Ravg;
(2)然后通过每个结点的性能占总性能F的百分比来计算出理论空间使用量,进而计算出理论空间使用率,每个结点计算出的理论空间使用率组合成一个“理论的负载均衡理想状态”数组;
(3)计算各个结点最大的空间负载率,并由此找出理论空间使用量超过最大负载量的结点,计算超出量,并将超出空间分别放置为超出的结点上,每个结点放置的存储空间占用量为:

其中Sconf(i)和Rtheory(i)为被放置结点的分配的空间和理论空间使用率,当这样放置后,多余的空间被分配完,那么迭代结束,否则继续迭代计算,最终得到一个理想的均衡状态数组,里面存放了各个结点的不大于最大空间负载率Rm的理想空间占用率:
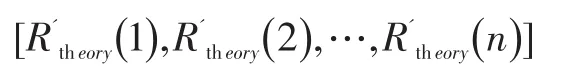
(4)进行分组,其中 R(i)表示结点 i存储空间使用率:

表1
(5)计算各个结点需要移动的数据量然后进行移动数据。
3 实验和结果分析
实验环境由五台台式机组成,分别通过一个路由器连接成一个局域网,网络拓扑图如下:
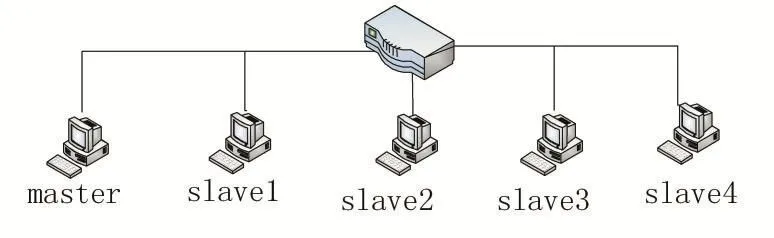
图1 网络拓扑图
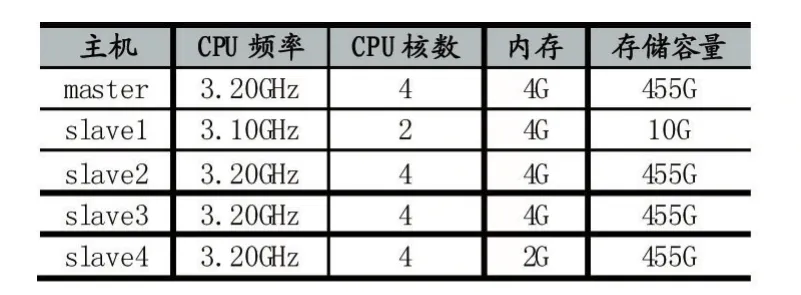
表2
为了对比本文提出的算法和hdfs默认的负载均衡算法,我们做如下操作来导致集群出现负载不均衡现象:
(1)将所有文件的副本数设为2;
(2)将其中某几台作为客户端进行上传文件;
(3)添加一台新结点,然后再上传文件;
然后分别运行默认的负载均衡算法和本文提出的负载均衡算法,对比均衡效果,其中阈值threshold我们设置为6%,实验的对比结果如下:
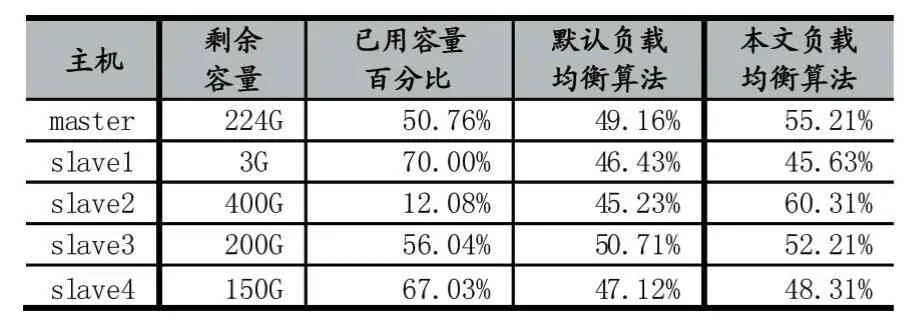
表3
由上面的结果对比,可以知道:对于CPU和内存性能高的并且剩余容量多的主机,通过本文负载均衡算法后可以存储更多的数据,而默认负载均衡算法,只是让每个节点的占用比尽量趋近于一致。
参考文献:
[1]张松.Hadoop异构环境中数据副本动态管理研究[D].南京航空航天大学,2015.
[2]武娟,黄海,钱锋,李拥军,寿质彬.基于多变量动态算法的Hadoop负载均衡优化与实现[J].电信科学,2012,28(12):83-87.
[3]刘琨.云计算负载均衡策略的研究[D].吉林大学,2016.
[4]刘琨,肖琳,赵海燕.Hadoop中云数据负载均衡算法的研究及优化[J].微电子学与计算机,2012,29(09):18-22.
[5]康承昆,刘晓洁.一种基于多衡量指标的HDFS负载均衡算法[J].四川大学学报(自然科学版),2014,51(06):1163-1169.
[6]Kun Liu,Gaochao Xu,Jun'e Yuan.An Improved Hadoop Data Load Balancing Algorithm[J].Journal of Networks,2013,8(12).
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17 00:56:36
综艺报(2020年21期)2020-11-30 08:36:49
电脑爱好者(2019年17期)2019-10-30 03:34:48
数学物理学报(2018年1期)2018-03-26 08:16:42
中国社区医师(2015年10期)2015-01-27 06:41:56
电子设计工程(2014年12期)2014-02-27 11:58:23
初中生学习·低(2012年4期)2012-04-29 04:29:50
初中生学习·低(2012年7期)2012-04-29 00:44:03
中国建设信息化(2011年2期)2011-09-22 01:09:22
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
